文章目录
- 一、类
- 二、python异常处理
- 三、自定义模块
- 3.1 保留模块测试代码
- 3.2 添加模块使用说明
- 四、内置模块
- 4.1 os标准库
- 4.2 os.path类
- 4.3 sys库
- 4.4 platform库
- 4.5 glob库
- 4.6 random库
- 4.7 subprocess库
- 4.8 pickle库
- 4.9 JSON库
- 4.10 time库
- 4.11 datetime库
- 4.12 urllib库
- 4.12.1 request类
一、类
面向对象编程&面向过程编程概念:
- 面向过程编程:是一种以过程为中心的编程思想。这些都是以什么正在发生为主要目标进行编程。比如前面的定义函数就是面向过程编程,代码是从上往下一行行执行,可以看到整个过程。
- 面向对象编程:是一种计算机编程架构,以对象为中心的编程思想,对现实世界理解和抽象的方法。比如把作用相似的函数规划到一起创建一个类,是从对象来考虑代码结构的。
类&对象之间的关系:
- 类:类是对现实生活中一类具有共同特征的事物的抽象描述。例如电脑类、空调类、人类。
- 对象:类的实体,实际存在的事物,例如电脑类的“主机”、“显示器”。
- 类是由对象来定,这个过程叫做抽象化。用类创建对象,这个过程称为实例化
类的特点:
- 封装:把相同对象的功能(函数)、属性(变量)组合在一起。
- 方法:对象的功能(例如电脑能上网、看片),实际在类里面就是函数,称为成员函数,也可以称为方法。
- 属性:对象的特征(例如电脑都有主机、显示器)。
- 实例化:用类创建对象,这个对象具体是什么东西,例如你用的电脑、我这个人。
定义方法:
- 使用class关键字定义类。
类的书写规范:
- 类一般采用大驼峰命名,例如MyClass。
- 类注释,用于说明该类的用途,提高可阅读性。
- 类中只存在两种数据:属性和方法。
- 声明属性必须赋值。
- 声明方法的第一个参数必须是self,其他与普通函数一样。
- 一般会使用__init__方法给类指定的初始状态属性。
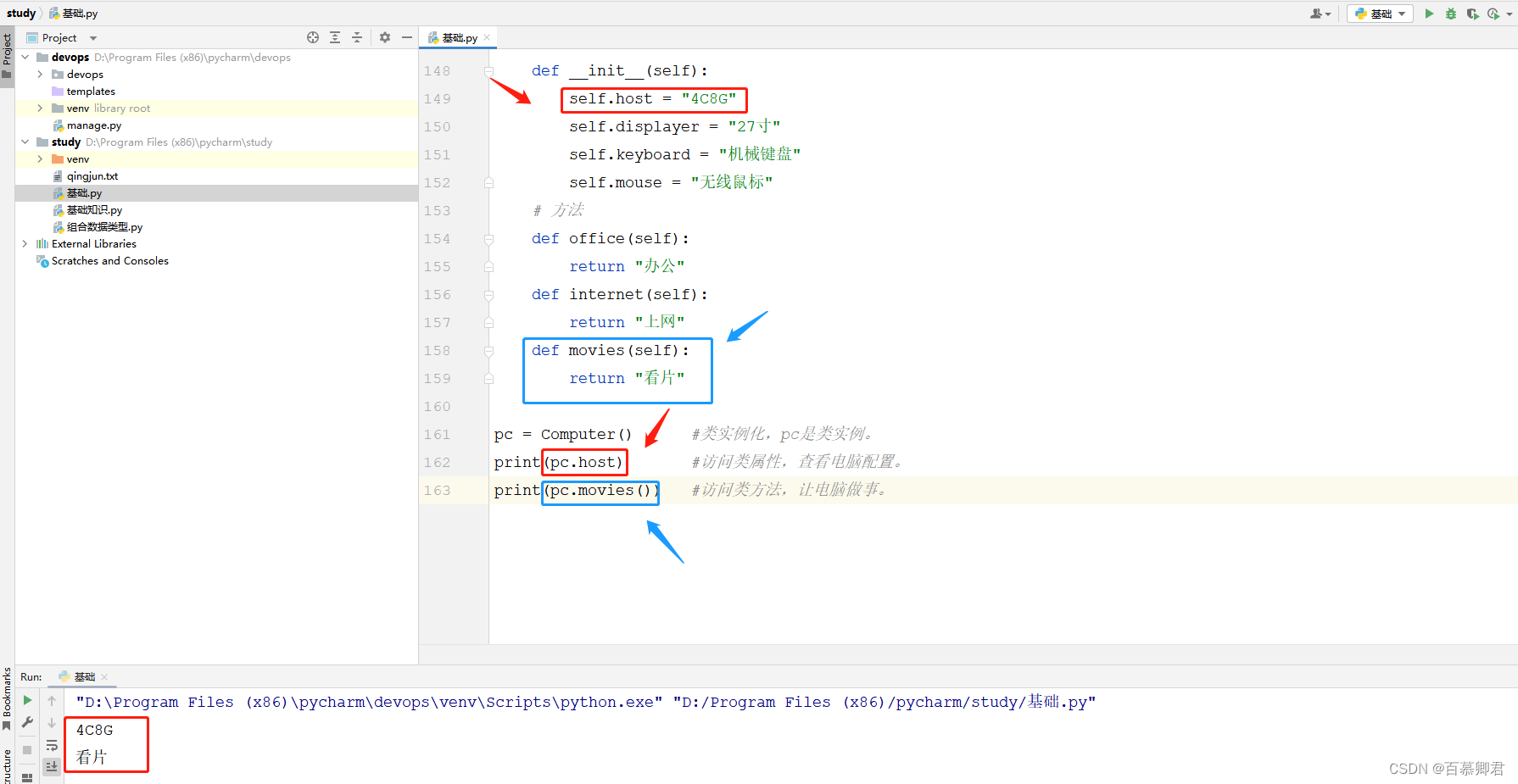
1.类的定义和使用。
#######################################################
##定义类。
class Computer(): ##类的名称为Computer
'''
电脑类
'''
#定义属性,相当于变量。
def __init__(self):
self.host = "4C8G"
self.displayer = "27寸"
self.keyboard = "机械键盘"
self.mouse = "无线鼠标"
#定义方法,相当于函数。后续通过引用函数名称调用类的哪个函数功能。
def office(self):
return "办公"
def internet(self):
return "上网"
def movies(self):
return "看片"
#######################################################
##类的实例化。
##实例化:用类创建对象的过程。
##类实例:用类创建对象。
##实例属性:对象的属性。
##实例方法:对象调用的方法。
pc = Computer() #类实例化,pc是类实例。
print(pc.host) #访问类属性,查看电脑配置。
print(pc.movies()) #访问类方法,让电脑做事。
2.例一,让某个人使用电脑做事。
class Computer():
'''
电脑类
'''
# 属性。
def __init__(self, name): ##传入一个参数name。
self.host = "4C8G"
self.displayer = "27寸"
self.keyboard = "机械键盘"
self.mouse = "无线鼠标"
self.name = name
# 方法。
def office(self):
return "%s在办公" %self.name
def internet(self):
return "%s在上网" %self.name
def movies(self):
return "%s在看片" %self.name
zhangsan = Computer("张三")
print(zhangsan.office())
lisi = Computer("李四")
print(lisi.movies())

3.例二,初始化函数。
class Calc():
'''计算器类'''
def __init__(self, num1, num2):
self.num1 = num1
self.num2 = num2
def jia(self):
return self.num1 + self.num2
def jian(self):
return self.num1 - self.num2
def cheng(self):
return self.num1 * self.num2
def chu(self):
return self.num1 / self.num2
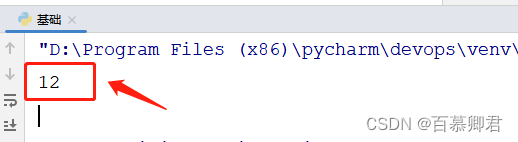
calc = Calc(6, 6)
print(calc.jia())
二、python异常处理
捕获异常的原因:
- 异常是指程序因为某种原因无法正常工作了,比如代码缩进错误、缺少软件包、环境错误、连接超时等都会引发异常。
- 一个健壮的程序应该把所能预知的异常都应做相应的处理,保障程序长期运行。
捕获异常方法:
- 如果在执行 try 块里的业务逻辑代码时出现异常,系统会自动生成一个异常对象,该异常对象被提交给 Python 解释器,这个过程被称为引发异常。
- 当 Python 解释器收到异常对象时,会寻找能处理该异常对象的 except 块,如果找到合适的 except 块,则把该异常对象交给该 except 块处理,这个过程被称为捕获异常。如果 Python 解释器找不到捕获异常的except 块,则运行时环境终止,Python 解释器也将退出。
| 异常类型 | 释义 |
|---|---|
| SyntaxError | 语法错误 |
| IndentationError | 缩进错误 |
| TypeError | 对象类型与要求不符合 |
| ImportError | 模块或包导入错误;一般路径或名称错误 |
| KeyError | 字典里面不存在的键 |
| NameError | 变量不存在 |
| IndexError | 下标超出序列范围 |
| IOError | 输入/输出异常;一般是无法打开文件 |
| AttributeError | 对象里没有属性 |
| KeyboardInterrupt | 键盘接受到Ctrl+C |
| Exception | 通用的异常类型;一般会捕捉所有异常 |
| UnicodeEncodeError | 编码错误 |
1.语法。
try:
<代码块>
except [异常类型]:
<发生异常时执行的代码块>
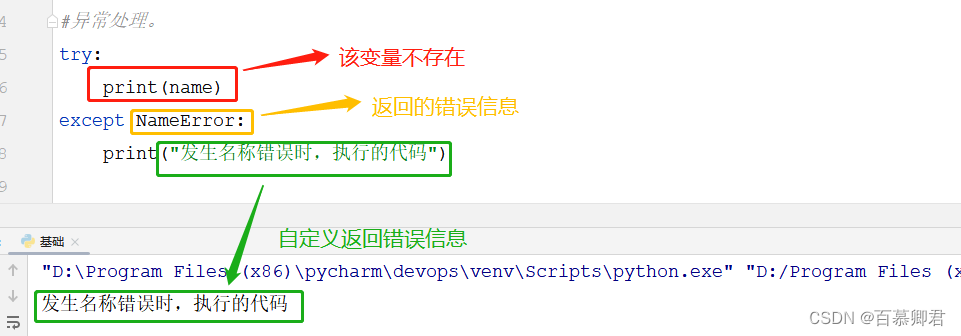
2.例一,打印一个没有定义的变量。
try:
print(name)
except NameError:
print("发生名称错误时,执行的代码")
3.例二,当不确定异常类型时,可以使用通用异常类型。
try:
print(name)
except Exception: ##Exception指通用类型。
print("发生名称错误时,执行的代码")
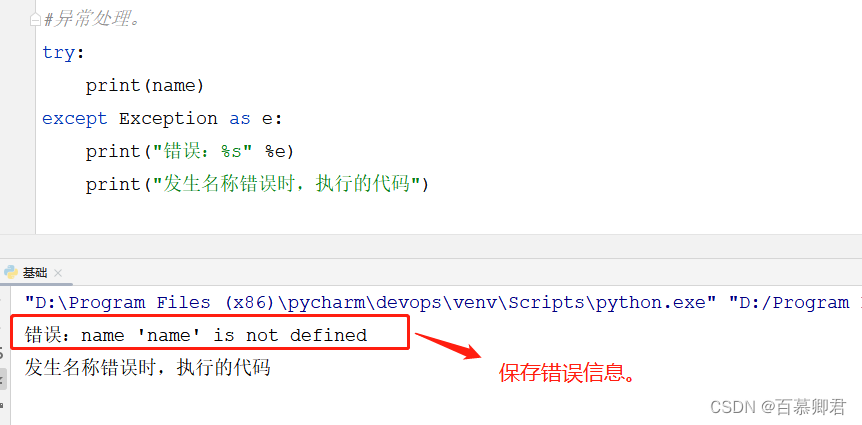
4.例三,保存异常信息。
try:
print(name)
except Exception as e:
print("错误:%s" %e)
print("发生名称错误时,执行的代码")
三、自定义模块
模块是什么?
- 一个较大的程序一般应分为若干个程序块,这些程序块称为模块,每个模块用来实现一部分特定的功能。这样可以方便管理和重复使用。
- python中有很多别人已经定义好的模块,我们可以直接拿来使用。我们也可以根据项目情况去自定义模块使用。
- python中的模块定义就是写一个py文件,然后导入这个py文件就代表引用该模块了。
使用模块的方法:
import <模块名称> from <模块名称> import <方法名> import <模块名称> as <别名>
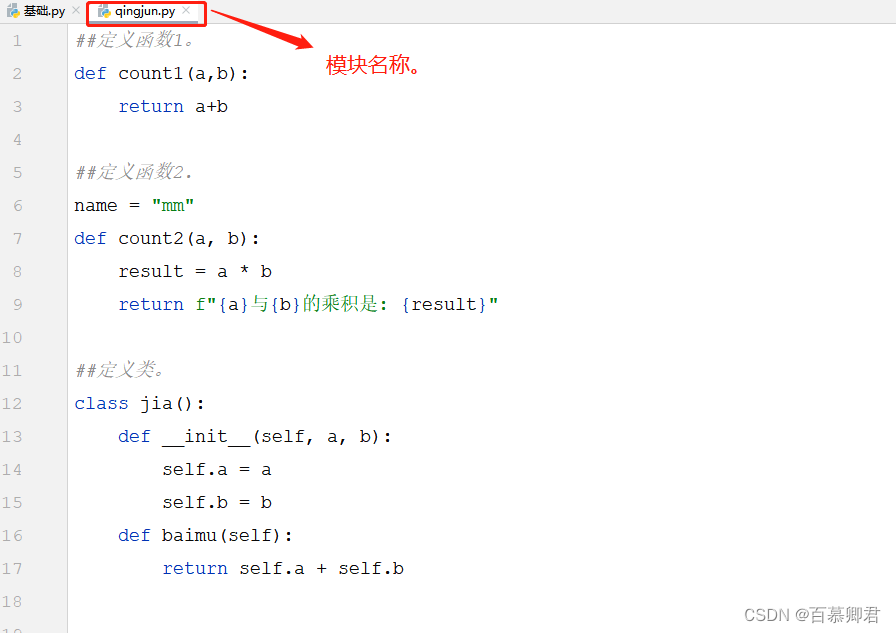
1.定义模块,写一个py文件,我这里就命名为qingjun.py,qingjun为模块名。
##定义函数1。
def count1(a,b):
return a+b
##定义函数2.
name = "mm"
def count2(a, b):
result = a * b
return f"{a}与{b}的乘积是: {result}"
##定义类。
class jia():
def __init__(self, a, b):
self.a = a
self.b = b
def baimu(self):
return self.a + self.b
2.导入模块,方式一。
import qingjun
##调用qingjun模块中的一个名为jia的类。
c = qingjun.jia(10, 5)
print(c.baimu())
##调用qingjun模块中的一个名称conut1的函数。
print(qingjun.count1(1,6))
3.导入模块并重命名,方式二。
import qingjun as a
##调用qingjun模块中的一个名为jia的类。
c = a.jia(10, 5)
print(c.baimu())
##调用qingjun模块中的一个名称conut1的函数。
print(a.count1(1,6))
4.导入模块某个功能,方式三。
from qingjun import jia
##调用qingjun模块中的一个名为jia的类。
c = jia(10, 5) ##这种方法可以不跟模块名称。
print(c.baimu())
3.1 保留模块测试代码
- 保留模块py文件中的测试代码,可以方便他人查阅使用模块。我们自定义好一个模块时,常常在后面写一小段代码进行测试,但又不想让他人使用该模块时导入我这段测试代码,这时可以用Python文件的内置属性__name__实现。
- 若直接运行Python文件,__name__的值是"main";若import一个模块,那么模块的__name__的值是"文件名"。
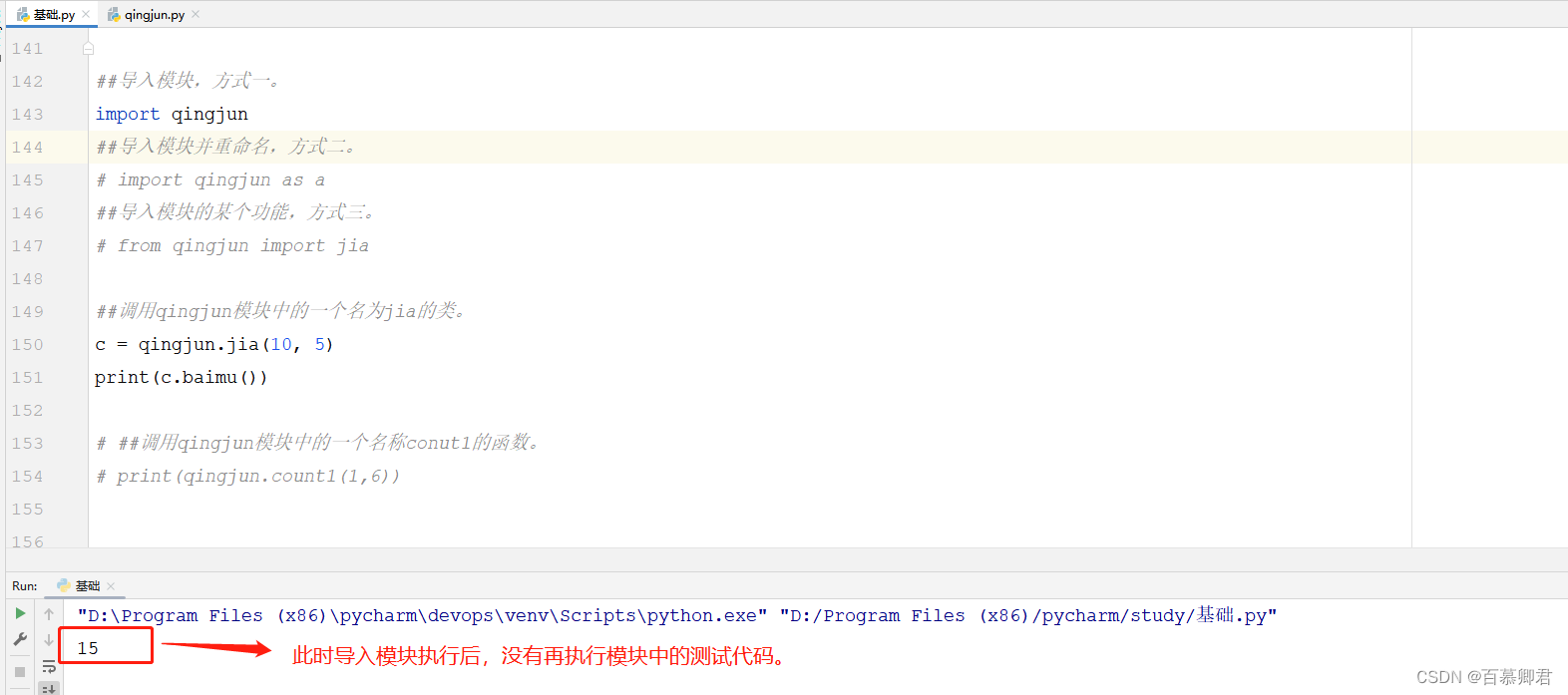
1.在模块py文件中添加“__name__”,执行模块文件返回的是“__main__”。
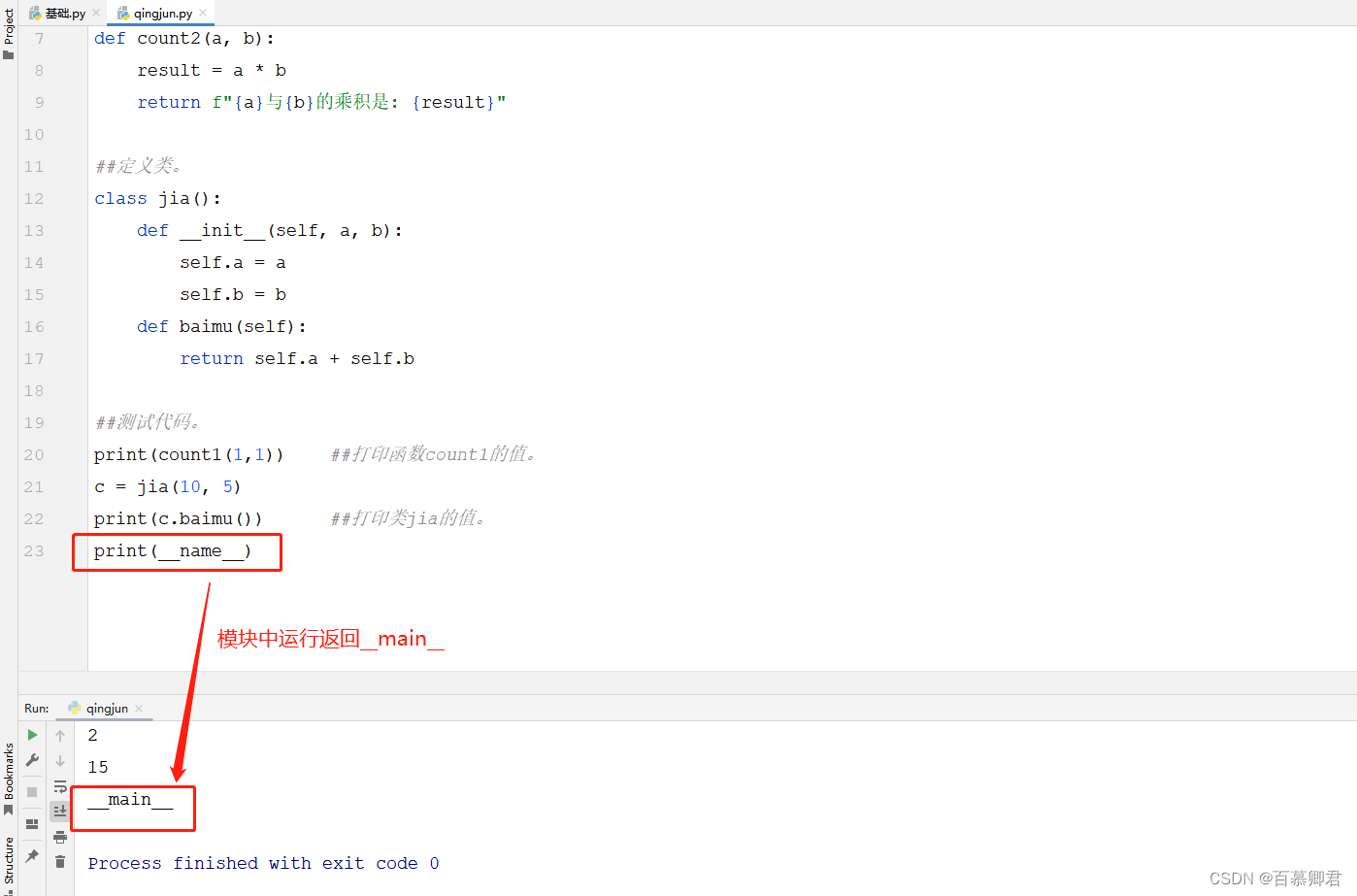
2.在模块py文件中添加“__name__”,引用模块执行返回的是“__main__”。
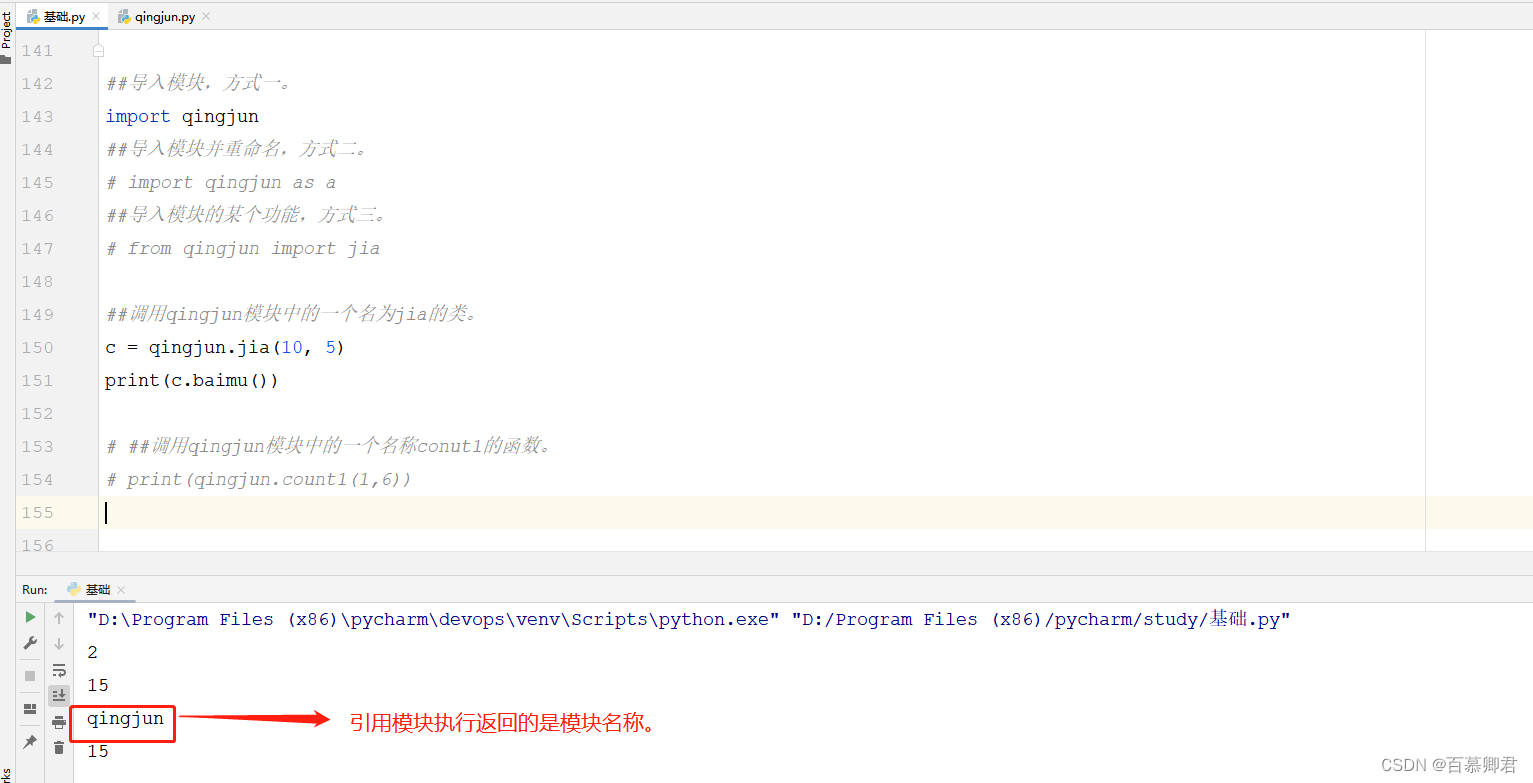
3.所以常常在模块的测试代码中添加if判断,这样可以防止别人引用模块时也把测试代码执行了。
##测试代码。
if __name__ == "__main__":
print(count1(1,1)) ##打印函数count1的值。
c = jia(10, 5)
print(c.baimu()) ##打印类jia的值。
3.2 添加模块使用说明
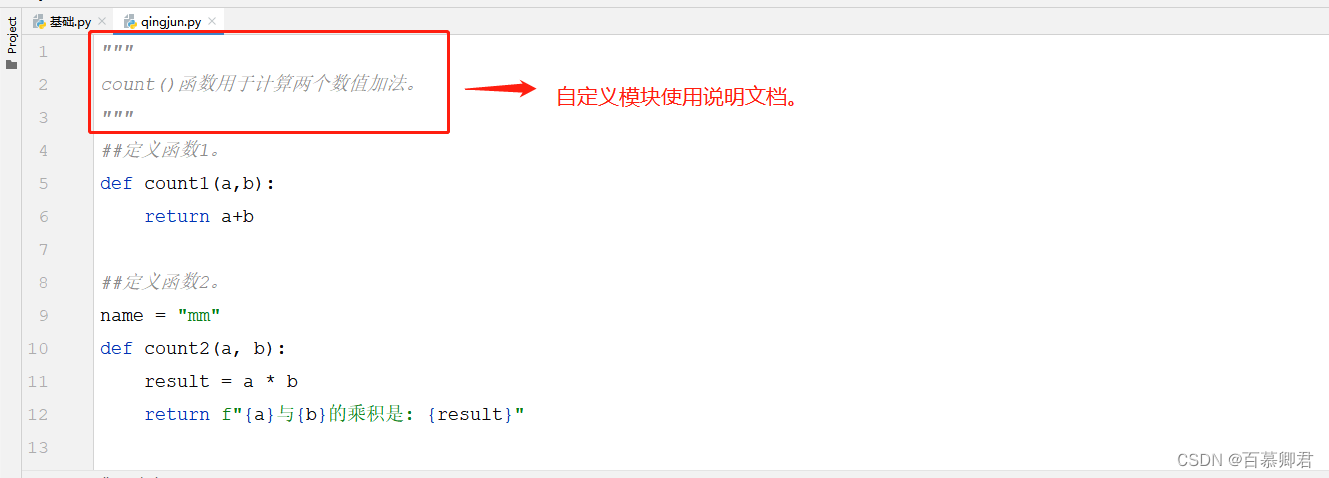
- 自定义模块也可以添加说明文档,方便他人使用。与函数或类的添加方法相同,即只需在模块开头的位置定义一个字符串即可。
1.定义模块说明文档。
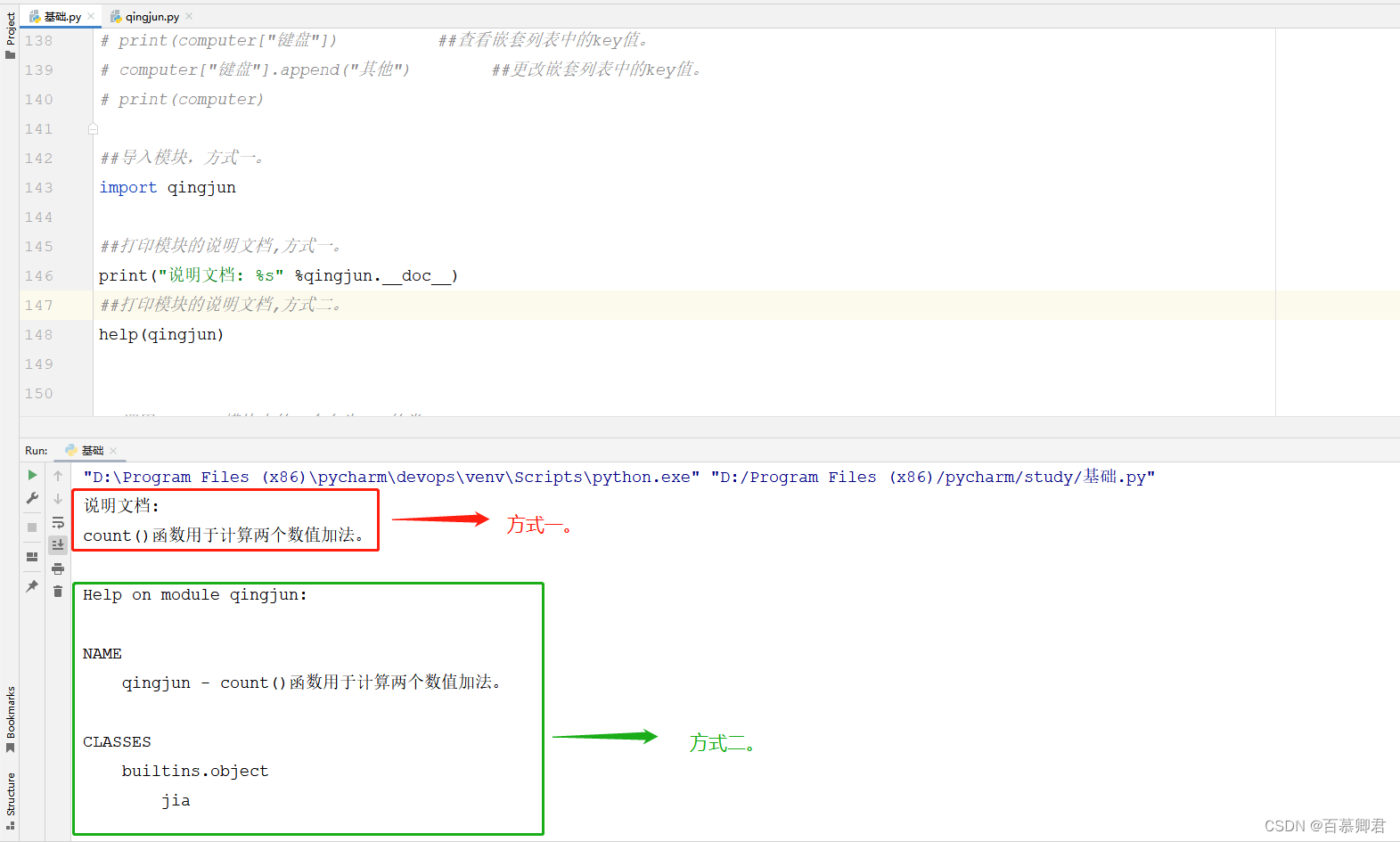
2.引用模块后,可以打印模块说明文档。
##导入模块。
import qingjun
##打印模块的说明文档,方式一。
print("说明文档: %s" %qingjun.__doc__)
##打印模块的说明文档,方式二。
help(qingjun)
3.查看效果。
四、内置模块
- 官方文档。
| 常用内置模块 | 作用 |
|---|---|
| os | 操作系统管理 |
| sys | 解释器交互 |
| platform | 操作系统信息 |
| glob | 查找文件 |
| shutil | 文件管理 |
| random | 随机数 |
| subprocess | 执行Shell命令 |
| pickle | 对象数据持久化 |
| json | JSON编码和解码 |
| time | 时间访问和转换 |
| datetime | 日期和时间 |
| urllib | HTTP访问 |
4.1 os标准库
- os库主要对目标和文件操作。
| 方法 | 作用 |
|---|---|
| os.name | 返回操作系统类型 |
| os.environ | 以字典形式返回系统变量 |
| os.putenv(key, value) | 改变或添加环境变量 |
| os.listdir(path=’.’) | 列表形式列出目录下所有目录和文件名 |
| os.getcwd() | 获取当前路径 |
| os.chdir(path) | 改变当前工作目录到指定目录 |
| os.mkdir(path [, mode=0777]) | 创建目录 |
| os.makedirs(path [, mode=0777]) | 递归创建目录 |
| os.rmdir(path) | 移除空目录,不能删除有文件的目录 |
| os.remove(path) | 移除文件 |
| os.rename(old, new) | 重命名文件或目录 |
| os.stat(path) | 获取文件或目录属性 |
| os.chown(path, uid, gid) | 改变文件或目录所有者 |
| os.chmod(path, mode) | 改变文件访问权限 |
| os.symlink(src, dst) | 创建软链接 |
| os.unlink(path) | 移除软链接 |
| os.getuid() | 返回当前进程UID |
| os.getlogin() | 返回登录用户名 |
| os.getpid() | 返回当前进程ID |
| os.kill(pid, sig) | 发送一个信号给进程 |
| os.walk(path) | 目录树生成器,生成一个三组 (dirpath, dirnames, filenames) |
| os.system(command) | 执行shell命令,不能存储结果 |
| os.popen(command [, mode=‘r’ [, bufsize]]) | 打开管道来自shell命令,并返回一个文件对象 |
1.可以使用ipython进入,获取当前操作系统类型。

2.列出当前目录下的文件和目录。

3.获取目录树生成树。
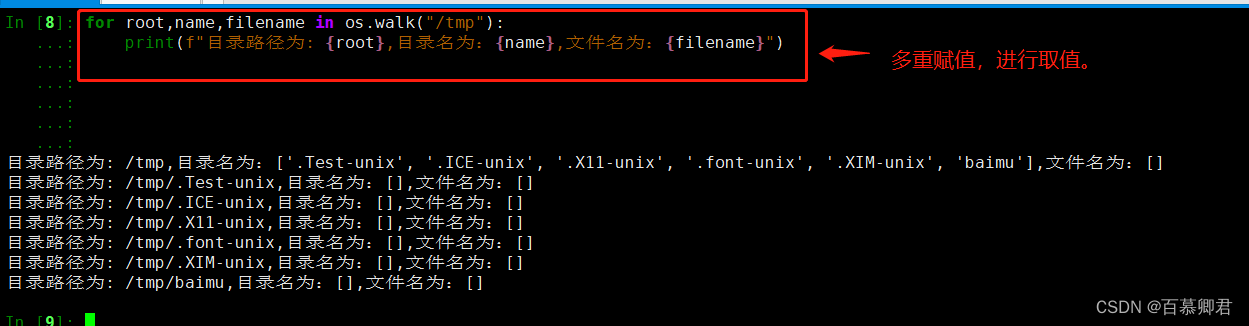
4.2 os.path类
- 用于获取文件属性。
| 方法 | 作用 |
|---|---|
| os.path.basename(path) | 返回最后一个文件或目录名 |
| os.path.dirname(path) | 返回最后一个文件所属目录 |
| os.path.abspath(path) | 返回一个绝对路径 |
| os.path.exists(path) | 判断路径是否存在,返回布尔值 |
| os.path.isdir(path) | 判断是否是目录 |
| os.path.isfile(path) | 判断是否是文件 |
| os.path.islink(path) | 判断是否是链接 |
| os.path.ismount(path) | 判断是否挂载 |
| os.path.getatime(filename) | 返回文件访问时间戳 |
| os.path.getctime(filename) | 返回文件变化时间戳 |
| os.path.getmtime(filename) | 返回文件修改时间戳 |
| os.path.getsize(filename) | 返回文件大小,单位字节 |
| os.path.join(a, *p) | 加入两个或两个以上路径,以正斜杠"/"分隔。常用于拼接路径 |
| os.path.split(path) | 分隔路径名 |
| os.path.splitext(path) | 分隔扩展名 |
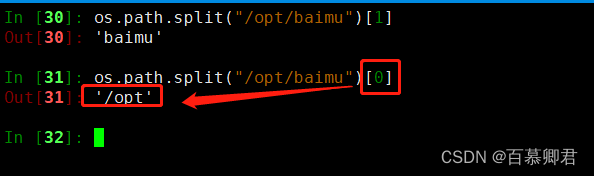
1.分隔路径名。
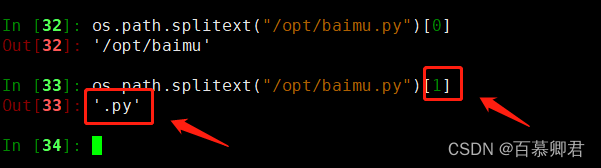
2.分隔扩展名。
4.3 sys库
- 用于与Python解释器交互。
| 方法 | 作用 |
|---|---|
| sys.argv | 从程序外部传递参数 argv[0] #代表本身名字 argv[1] #第一个参数 argv[2] #第二个参数 argv[3] #第三个参数 argv[N] #第N个参数 argv #参数以空格分隔存储到列表 |
| sys.exit([status]) | 退出Python解释器 |
| sys.path | 当前Python解释器查找模块搜索的路径,列表返回。 |
| sys.getdefaultencoding() | 获取系统当前编码 |
| sys.platform | 返回操作系统类型 |
| sys.version | 获取Python版本 |
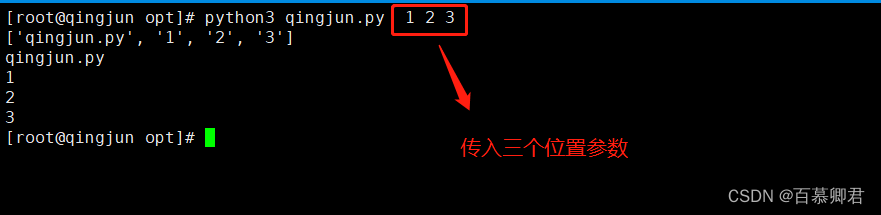
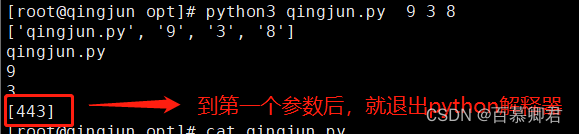
1.写一个python脚本,执行并传入参数。
[root@qingjun opt]# cat qingjun.py
import sys
print(sys.argv)
print(sys.argv[0])
print(sys.argv[1])
print(sys.argv[2])
print(sys.argv[3])
2.退出python解释器,可以添加退出状态码。
[root@qingjun opt]# cat qingjun.py
import sys
print(sys.argv)
print(sys.argv[0])
print(sys.argv[1])
print(sys.argv[2])
sys.exit([443])
print(sys.argv[3])
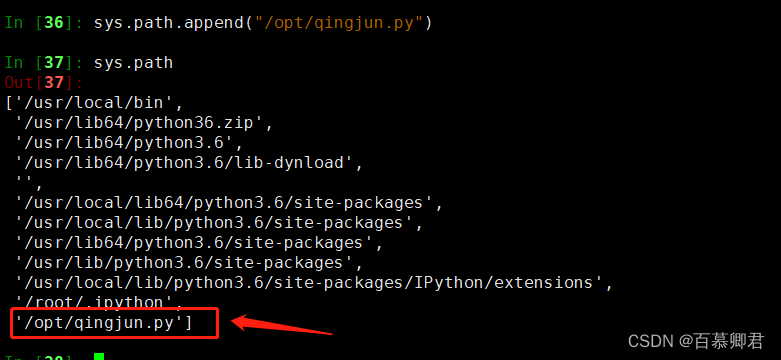
3.添加自定义模块路径。
##追加自定义模块路径。
sys.path.append("/opt/qingjun.py")
4.查看操作系统类型,与os.name作用相似。

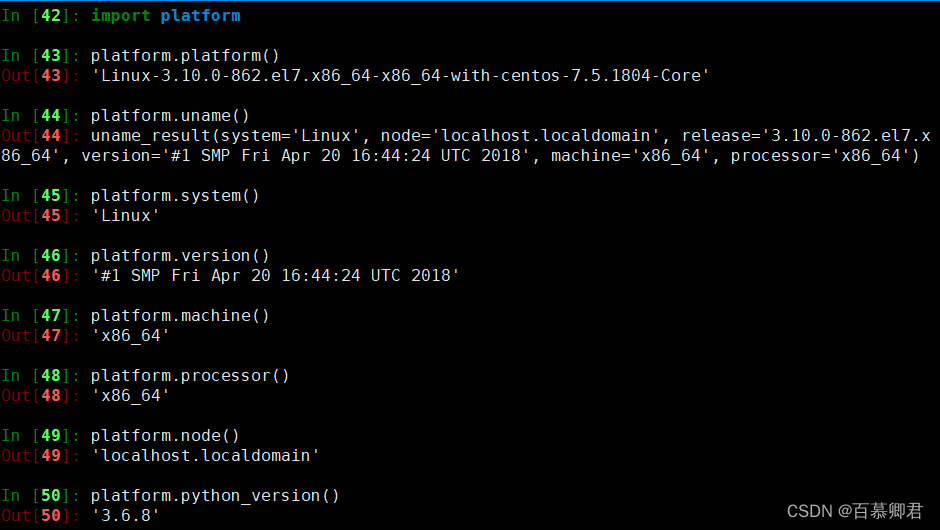
4.4 platform库
- 用于获取操作系统详细信息。
| 方法 | 作用 |
|---|---|
| platform.platform() | 返回操作系统平台 |
| platform.uname() | 返回操作系统信息 |
| platform.system() | 返回操作系统平台 |
| platform.version() | 返回操作系统版本 |
| platform.machine() | 返回计算机类型 |
| platform.processor() | 返回计算机处理器类型 |
| platform.node() | 返回计算机网络名 |
| platform.python_version() | 返回Python版本号 |
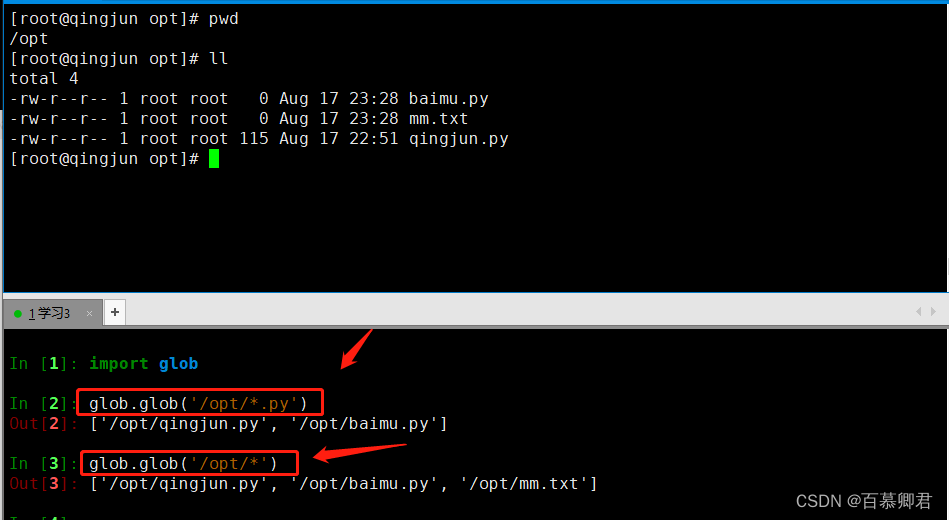
4.5 glob库
- 用于文件查找,支持通配符(*、?、[])
1.查找/opt/目录中所有以.py为后缀的文件。
glob.glob('/opt/*.py') ##查找以py结尾的文件。
glob.glob('/opt/*') ##查找所有文件。
##对返回的元组进行取值。
glob.glob('/opt/*')[0]
glob.glob('/opt/*')[1]
glob.glob('/opt/*')[2]
2.通配符?的用法,一个?代表一个字符。
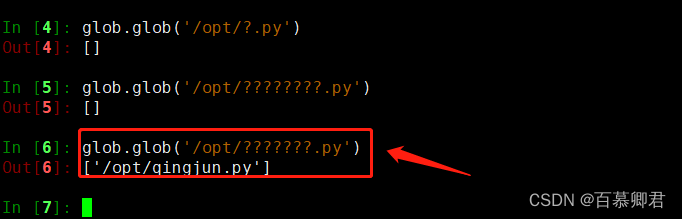
glob.glob('/opt/???????.py')
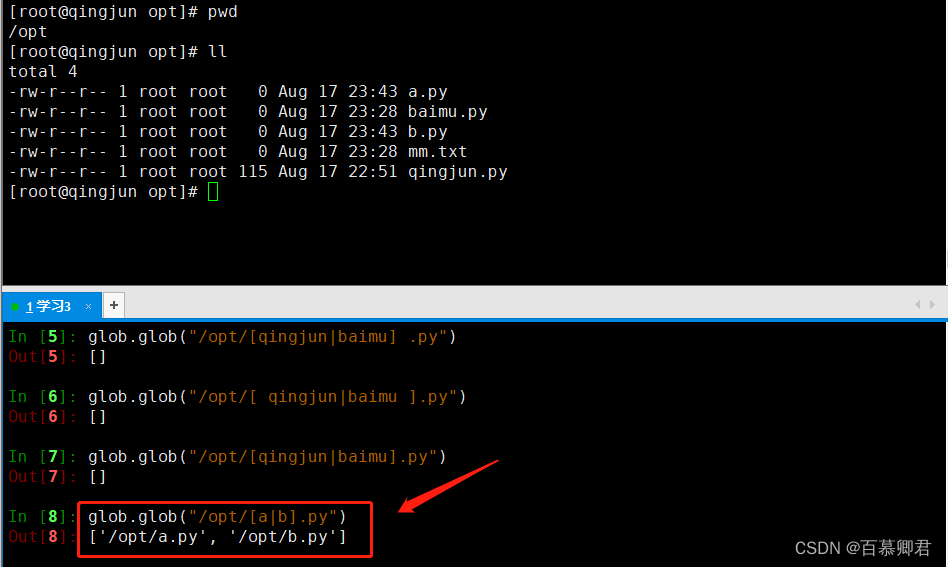
3.查找目录中出现a.sh或b.sh的文件。
glob.glob("/opt/[a|b].py")
4.6 random库
- 用于生成随机数。
| 方法 | 作用 |
|---|---|
| random.randint(a,b) | 随机返回整数a和b范围内数字 |
| random.random() | 生成随机数,它在0和1范围内 |
| random.randrange(start, stop[, step]) | 返回整数范围的随机数,并可以设置只返回跳数 |
| random.sample(array, x) | 从数组中返回随机x个元素 |
| random.choice(seq) | 从序列中返回一个元素 |
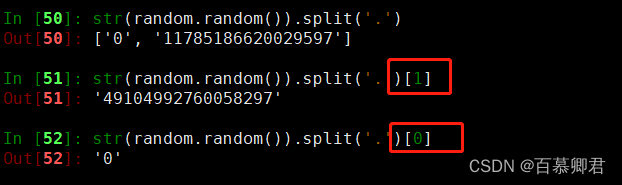
1.对生成的随机数进行切割,并取值。
##先转换数据类型为str,在进行切片取值。
str(random.random()).split('.')[1]
str(random.random()).split('.')[0]
4.7 subprocess库
作用:
- 用于执行Shell命令,工作时会fork一个子进程去执行任务,连接到子进程的标准输入、输出、错误,并获得它们的返回代码。
- 该模块将取代os.system、os.spawn*、os.popen*、popen2.* 和commands.*。
subprocess的主要方法:
- subprocess.run(),推荐使用。
- subprocess.Popen(),老版本使用。
- subprocess.call,偏底层。
语法:subprocess.run(args, *, stdin=None, stdout=None, stderr=None, shell=False, cwd=None, timeout=None, check=False, encoding=None)
| 参数 | 说明 |
|---|---|
| args | 要执行的shell命令,默认是一个字符串序列,如[‘ls’, ‘-al’]或(‘ls’, ‘-al’); 也可以是一个字符串,如’ls -al’,同时需要设置shell=True。 |
| stdin stdout stderr | run()函数默认不会捕获命令运行结果的正常输出和错误输出, 可以设置stdout=PIPE, stderr=PIPE来从子进程中捕获相应的内容; 也可以设置stderr=STDOUT,使标准错误通过标准输出流输出。 |
| shell | 如果shell为True,那么指定的命令将通过shell执行。 |
| cwd | 改变当前工作目录 |
| timeout | 设置命令超时时间。如果命令执行时间超时,子进程将被杀死,并弹出TimeoutExpired 异常。 |
| check | 如果check参数的值是True,且执行命令的进程以非0状态码退出,则会抛出一个CalledProcessError的异常,且该异常对象会包含参数、退出状态码、以及stdout和stderr(如果它们有被捕获的话)。 |
| encoding | 如果指定了该参数,则 stdin、stdout 和 stderr 可以接收字符串数据,并以该编码方式编码。否则只接收 bytes 类型的数据。 |
1.在python脚本中导入subprocess模块,执行正确命令示范。
import subprocess ##导入模块。
cmd = "pwd" ##要执行的命令。
result = subprocess.run(cmd, shell=True, timeout=3, stderr=subprocess.PIPE,stdout=subprocess.PIPE) ##run方法返回CompletedProcess实例,可以直接从这个实例中获取命令运行结果。
print(result)
print(result.returncode) ##获取状态码。
print(result.stdout) ##标准输出。
print(result.stderr) ##错误输出。

2.在python脚本中导入subprocess模块,执行错误命令示范。
import subprocess ##导入模块。
cmd = "pwdd" ##错误命令。
result = subprocess.run(cmd, shell=True, timeout=3, stderr=subprocess.PIPE,stdout=subprocess.PIPE)
print(result)
print(result.returncode) ##获取状态码。
print(result.stdout) ##标准输出。
print(result.stderr) ##错误输出。

4.8 pickle库
- 可以实现对一个Python对象结构的二进制序列化和反序列化。
- 主要用于将对象持久化到文件存储,方便把数据文件给别人使用,适用于小型数据(几兆、几十兆)。
两个函数:
- dump() 把对象保存到文件中(序列化),使用load()函数从文件中读取(反序列化)。
- dumps() 把对象保存到内存中,使用loads()函数读取。
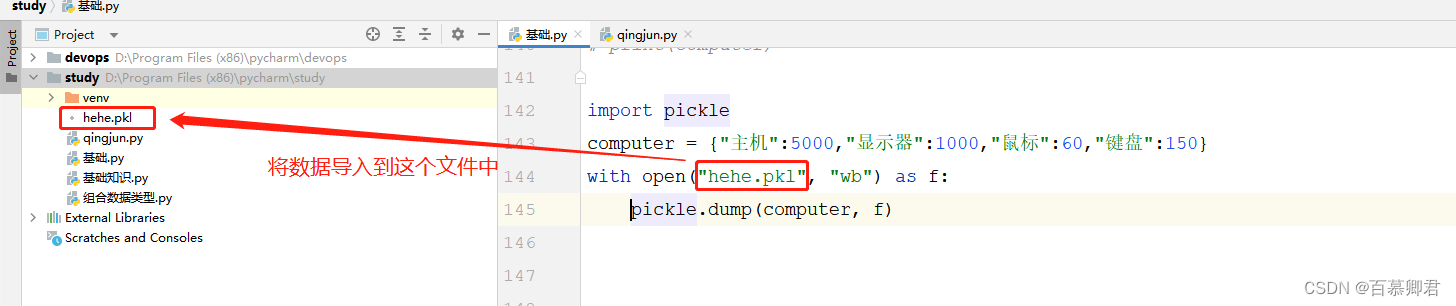
1.将数据对象保存到文件中,文件名自定义,一般使用pkl作为后缀名。
import pickle
computer = {"主机":5000,"显示器":1000,"鼠标":60,"键盘":150}
##导出数据到文件中。
with open("hehe.pkl", "wb") as f:
pickle.dump(computer, f)
2.读取文件中的数据。
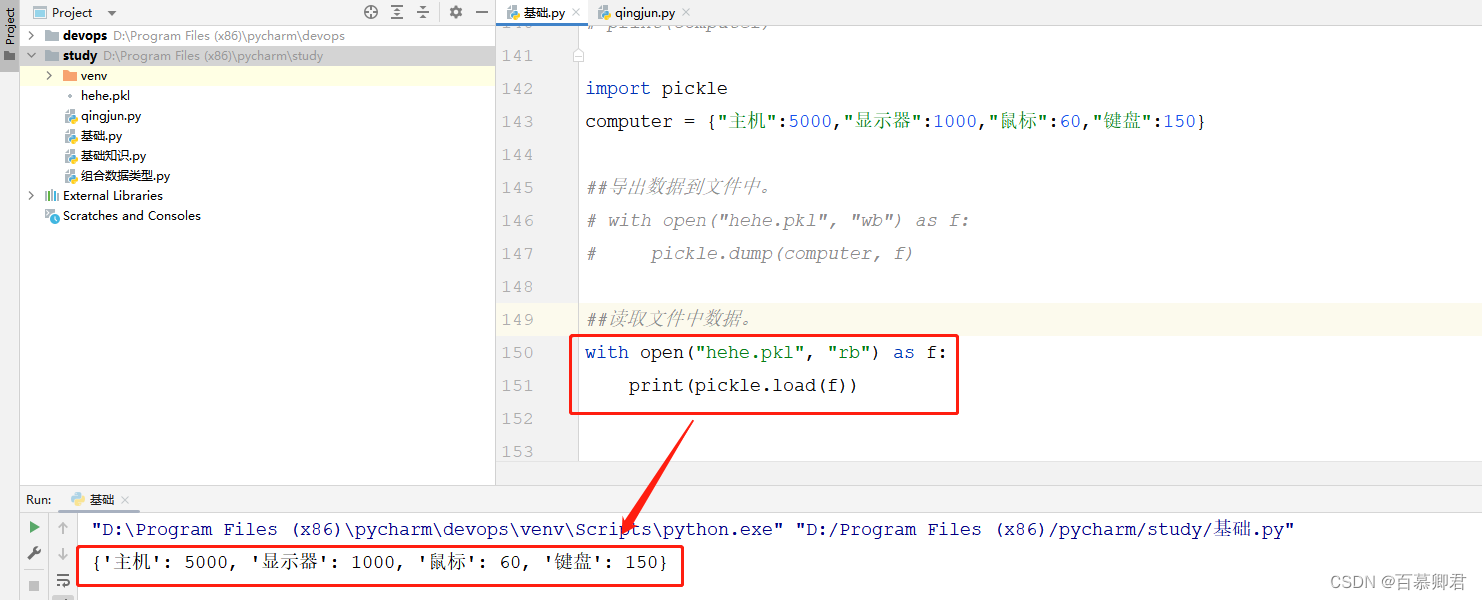
import pickle
computer = {"主机":5000,"显示器":1000,"鼠标":60,"键盘":150}
##读取文件中数据。
with open("hehe.pkl", "rb") as f:
print(pickle.load(f))
4.9 JSON库
- 用于数据格式转换,一般API返回的数据大多是JSON、XML,如果返回JSON的话,需将获取的数据转换成字典,方便在python程序中处理。
两个函数:
- dumps() 对数据进行编码。
- loads() 对数据进行解码。
1.将字典类型转换为JSON对象,方便将我的python数据给其他人使用。
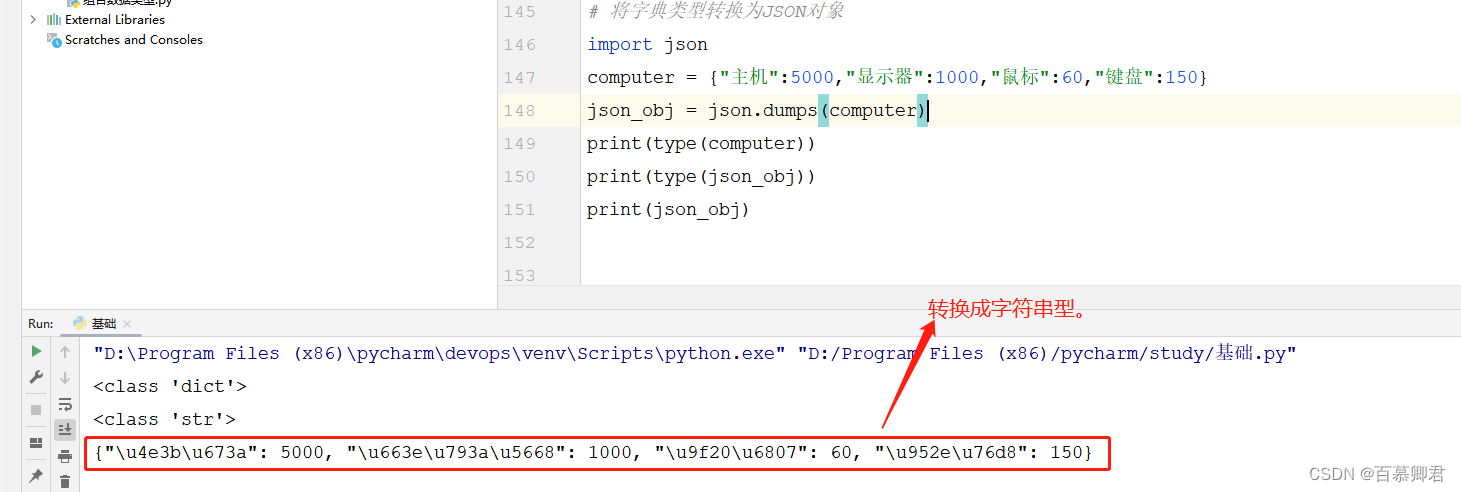
import json
computer = {"主机":5000,"显示器":1000,"鼠标":60,"键盘":150}
json_obj = json.dumps(computer)
print(type(computer))
print(type(json_obj))
print(json_obj)
2.将JSON对象转换为字典,方便将别人的数据拿到我的python中使用。
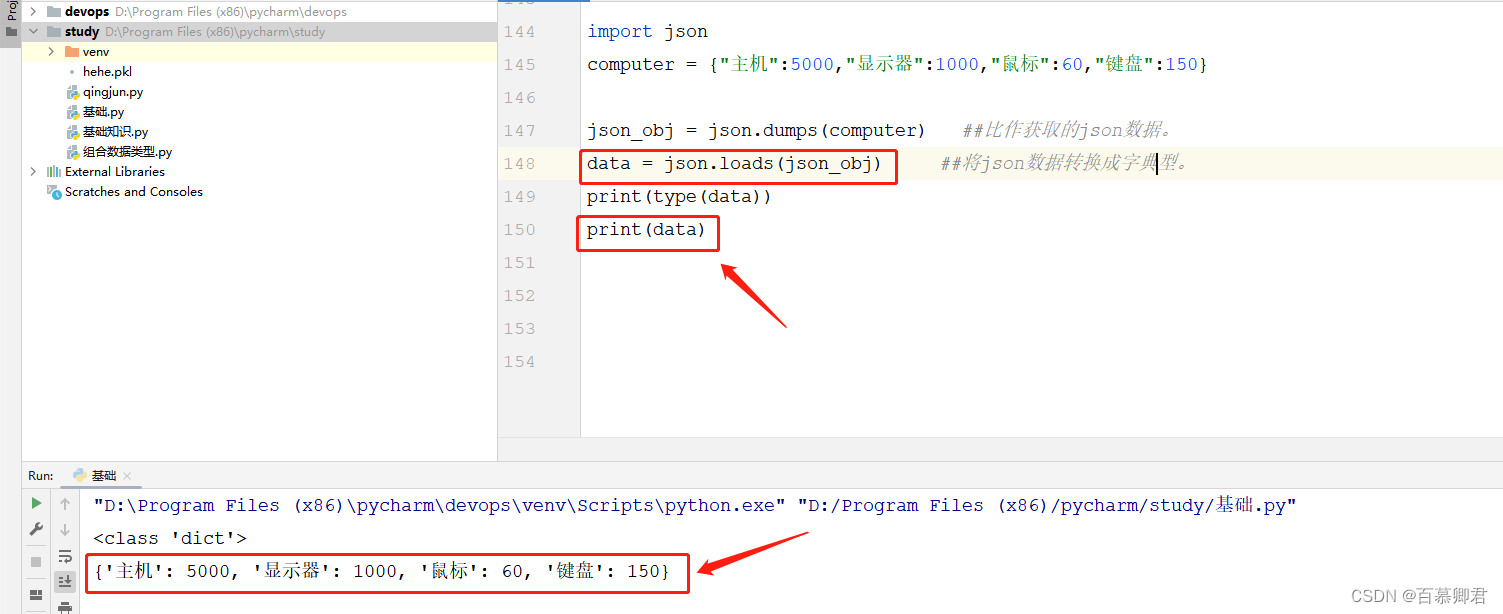
import json
computer = {"主机":5000,"显示器":1000,"鼠标":60,"键盘":150}
json_obj = json.dumps(computer) ##比作获取的json数据。
data = json.loads(json_obj) ##将json数据转换成字典型。
print(type(data))
print(data)
4.10 time库
- 用于满足简单的时间处理,例如获取当前时间戳、日期、时间、休眠。
| 方法 | 描述 |
|---|---|
| time.ctime(seconds) | 返回当前时间时间戳 |
| time.localtime([seconds]) | 当前时间,以stuct_time时间类型返回 |
| time.mktime(tuple) | 将一个stuct_time时间类型转换成时间戳 |
| time.strftime(format[, tuple]) | 将元组时间转换成指定格式。[tuple]不指定默认是当前时间 |
| time.time() | 返回当前时间时间戳 |
| time.sleep(seconds) | 延迟执行给定的秒数 |
1.获取当前时间。
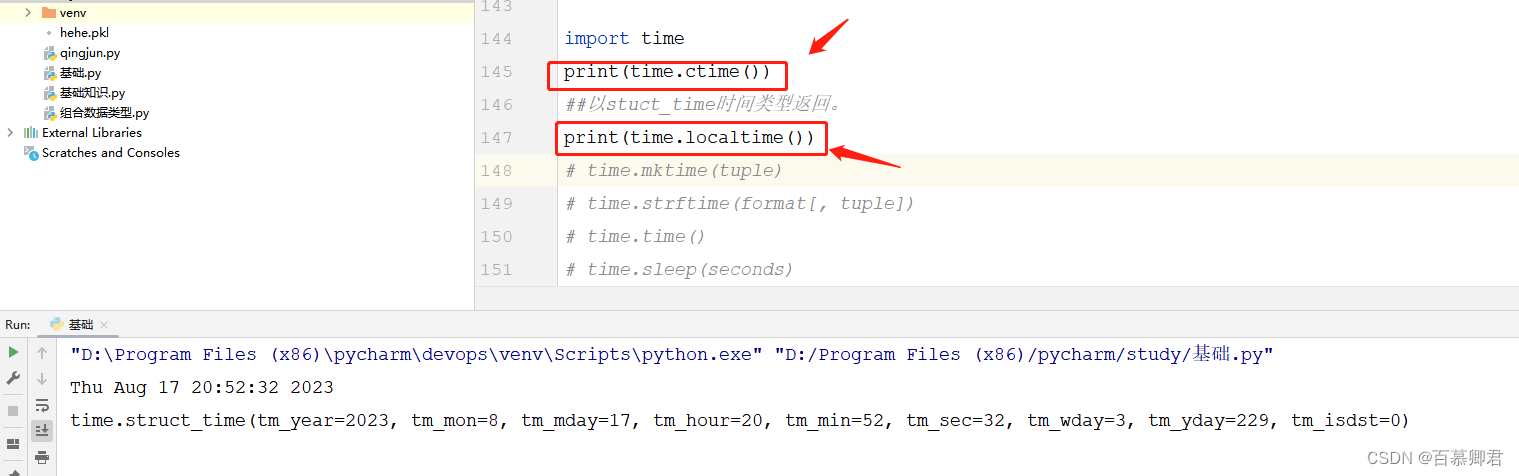
import time
print(time.ctime())
##以stuct_time时间类型返回。
print(time.localtime())
2.获取时间戳。
import time
##以stuct_time时间类型返回时间戳。
print(time.localtime())
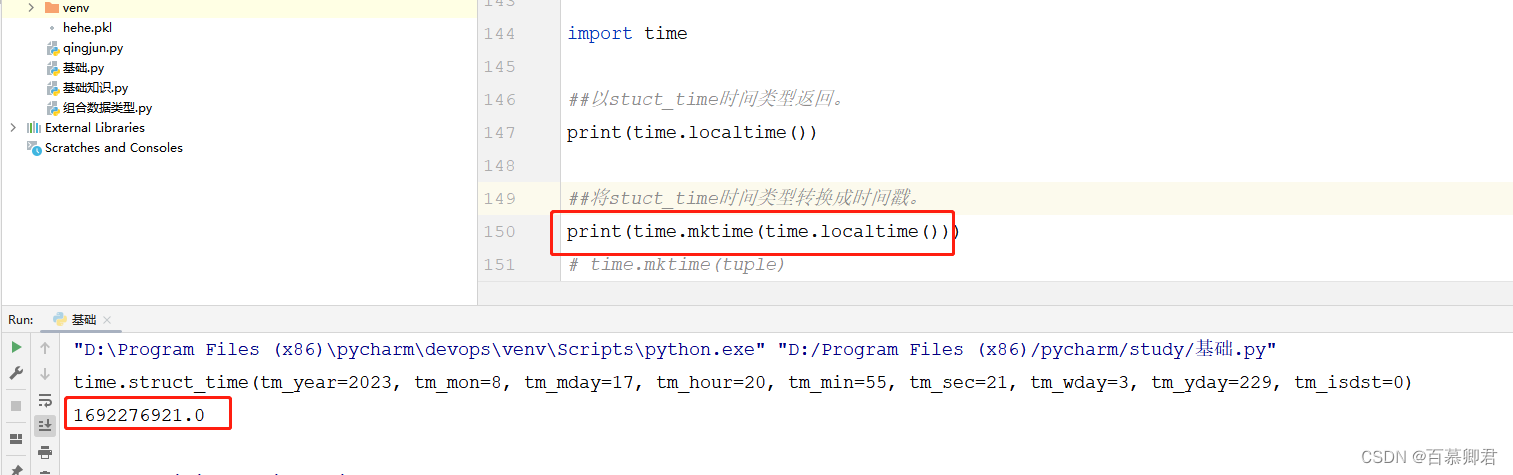
##将stuct_time时间类型转换成时间戳。
print(time.mktime(time.localtime()))
##获取时间戳,方式二。
print(time.time())
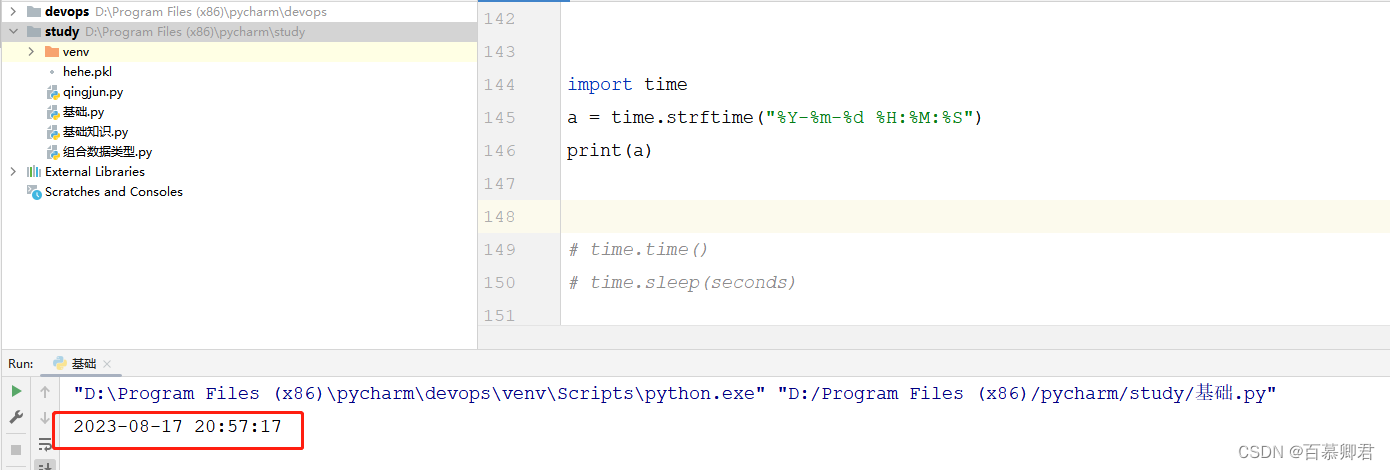
3.自定义时间格式。
import time
time.strftime("%Y-%m-%d %H:%M:%S")
##睡眠3秒。
time.sleep(3)
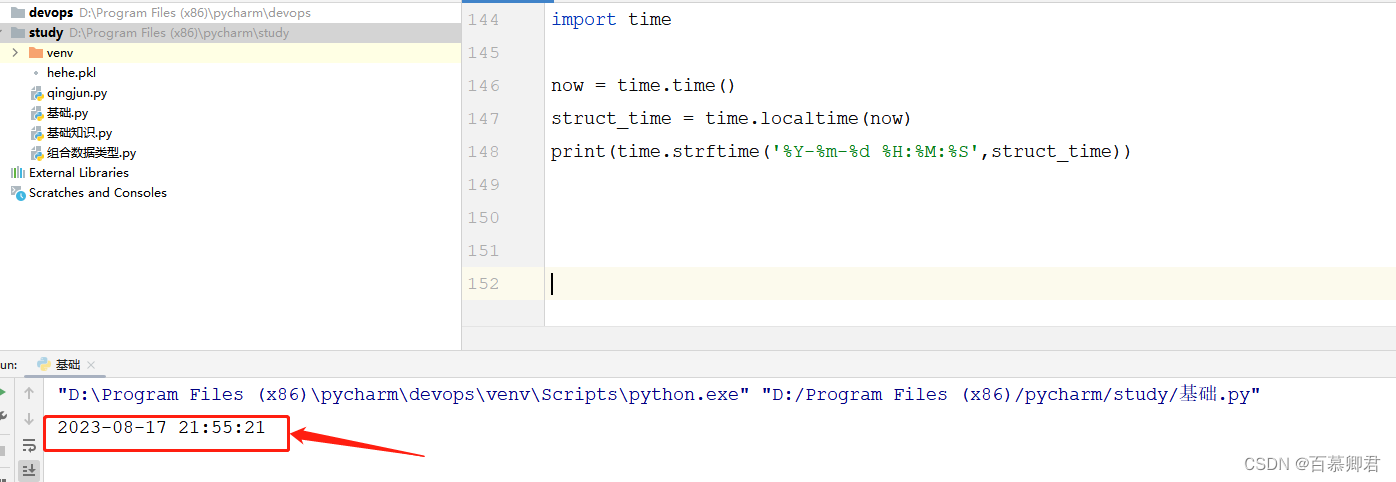
4.将时间戳转换指定格式。
now = time.time()
struct_time = time.localtime(now)
print(time.strftime('%Y-%m-%d %H:%M:%S',struct_time))
4.11 datetime库
- 用于处理更复杂的日期和时间。
| 类 | 作用 |
|---|---|
| datetime.date | 日期,年月日组成 |
| datetime.datetime | 包括日期和时间 |
| datetime.time | 时间,时分秒及微秒组成 |
| datetime.timedelta | 时间间隔 |
| datetime.tzinfo | 时区信息对象 |
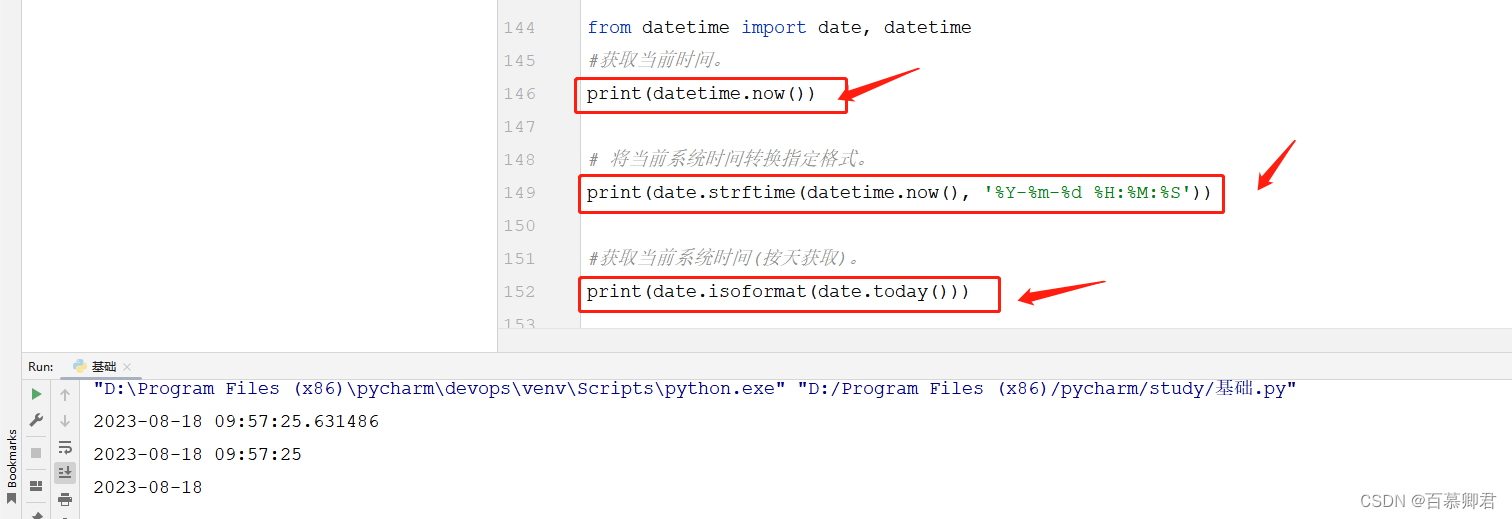
1.获取系统时间。
from datetime import date, datetime
#获取当前系统时间。
print(datetime.now())
# 将当前系统时间转换指定格式。
print(date.strftime(datetime.now(), '%Y-%m-%d %H:%M:%S'))
#获取当前系统时间(格式化,按天获取)。
print(date.isoformat(date.today()))
2.获取时间戳。
import time
from datetime import date, datetime
##获取时间戳。
date_array = datetime.fromtimestamp(time.time())
print(date_array)
#将时间戳转换指定格式。
print(date_array.strftime("%Y-%m-%d %H:%M:%S"))
3.获取昨天、明天的时间。
#获取昨天日期。
from datetime import date, timedelta
yesterday = date.today() - timedelta(days=1)
yesterday = date.isoformat(yesterday)
print(yesterday)
#获取明天日期。
tomorrow = date.today() + timedelta(days=1)
print(tomorrow)
#将时间对象格式化。
tomorrow = date.isoformat(tomorrow)
print(tomorrow)
4.12 urllib库
- 用于访问URL。
- 用的最多是urllib.request 类,它定义了适用于在各种复杂情况下打开 URL,例如基本认证、重定向、Cookie、代理等。
| 常用的类 | 作用 |
|---|---|
| urllib.request | 打开和读取 URL。 |
| urllib.error | 包含 urllib.request 抛出的异常。 |
| urllib.parse | 用于解析 URL。 |
| urllib.robotparser | 用于解析 robots.txt 文件。 |
4.12.1 request类
| 方法 | 描述 |
|---|---|
| getcode() | 获取响应的HTTP状态码。 |
| geturl() | 返回真实URL。有可能URL3xx跳转,那么这个将获得跳转后的URL。 |
| headers | 返回服务器header信息。 |
| read(size=-1) | 返回网页所有内容。size正整数指定读取多少字节。 |
| readline(limit=-1) | 读取下一行。size正整数指定读取多少字节。 |
| readlines(hint=0, /) | 列表形式返回网页所有内容,以列表形式返回。sizehint正整数指定读取多少字节。 |
1.自定义用户代理。
from urllib import request
##要请求的url。
url = "http://www.baidu.cn"
##浏览器信息。
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
header = {"User-Agent": user_agent}
req = request.Request(url, headers=header)
res = request.urlopen(req) ##打开url。
print(res.getcode()) ##获取访问url的状态码。
2.向接口提交用户数据。
from urllib import request, parse
url = "https://passport.jd.com/new/login.aspx?ReturnUrl=https%3A%2F%2Fwww.jd.com%2F"
post_data = {"username":"user1","password":"123456"}
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
header = {"User-Agent": user_agent}
#将字典转为URL查询字符串格式,并转为bytes类型
post_data = parse.urlencode(post_data).encode("utf8")
req = request.Request(url, data=post_data, headers=header)
res = request.urlopen(req)
print(res.read())