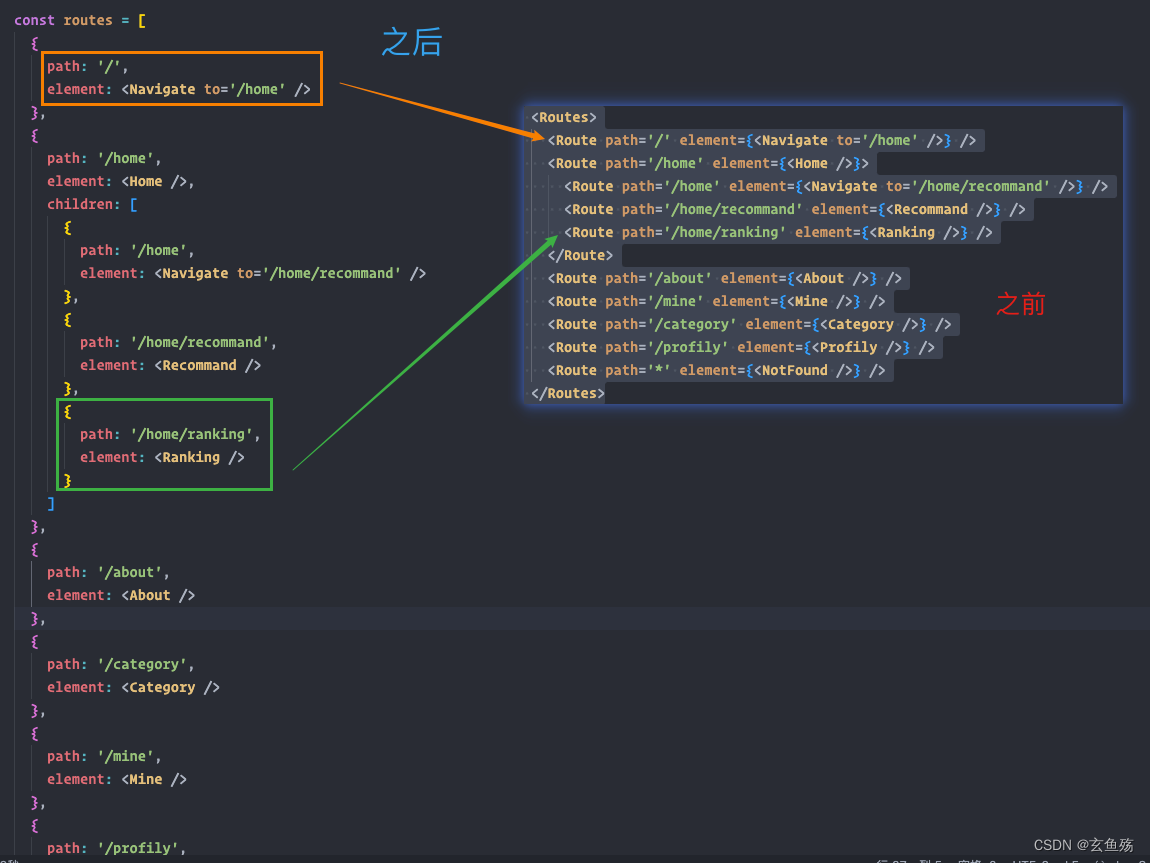
Unity Android 之 使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理
目录
Unity Android 之 使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理
一、简单介绍
二、实现原理
三、注意事项
四、效果预览
五、实现步骤
六、关键代码
附录:在 HanLP 中,Term 对象的 nature 字段表示词性
一、简单介绍
Unity Android 开发上会用到的技术简单整理,方便自己日后查看,能帮助到大家就更好了。
本节介绍,Unity 开发中,把从 Android 封装HanLP 的分词功能,在 Unity 中进行调用的方法整理封装给Unity调用,方法不唯一,欢迎指正。
在 Android 平台上,除了 HanLP,还有其他一些可以用于中文分词处理的算法和工具。以下是一些常见的中文分词算法,以及 HanLP 在分词中的一些优势:
常见的中文分词算法和工具:
ansj_seg: ansj_seg 是一个基于 CRF 和 HMM 模型的中文分词工具,适用于 Java 平台。它支持细粒度和粗粒度的分词,并具有一定的自定义词典和词性标注功能。
jieba: jieba 是一个在 Python 中广泛使用的中文分词库,但也有其 Java 版本。它采用了基于前缀词典的分词方法,并在速度和效果方面表现出色。
lucene-analyzers-smartcn: 这是 Apache Lucene 项目中的一个中文分词器,使用了基于规则的分词算法。它在 Lucene 搜索引擎中被广泛使用。
ictclas4j: ictclas4j 是一个中科院计算所开发的中文分词工具,基于 HMM 模型。它支持自定义词典和词性标注。
HanLP 分词的优势:
多领域适用性: HanLP 被设计为一个面向多领域的中文自然语言处理工具包,不仅包括分词,还支持词性标注、命名实体识别、依存句法分析等多种任务。
性能和效果: HanLP 在多个标准数据集上进行了训练和优化,具有较好的分词效果和性能。
灵活的词典支持: HanLP 支持自定义词典,你可以根据需要添加专业领域的词汇,以提升分词效果。
开放源代码: HanLP 是开源的,你可以自由使用、修改和分发,有利于定制和集成到你的项目中。
多语言支持: HanLP 不仅支持中文,还支持其他语言,如英文、日文等,为跨语言处理提供了便利。
社区活跃: HanLP 拥有活跃的社区和维护团队,有助于解决问题和获取支持。
总之,HanLP 是一个功能丰富且性能优越的中文自然语言处理工具,适用于各种应用场景,特别是在多领域的文本处理任务中表现出色。然而,最终的选择取决于你的具体需求和项目背景。
HanLP 官网:HanLP | 在线演示
HanLP GitHub:GitHub - hankcs/HanLP: 中文分词 词性标注 命名实体识别 依存句法分析 成分句法分析 语义依存分析 语义角色标注 指代消解 风格转换 语义相似度 新词发现 关键词短语提取 自动摘要 文本分类聚类 拼音简繁转换 自然语言处理
二、实现原理
1、在 Android 端 使用 StandardTokenizer.segment(text) 传入文本 Text 内容进行分词,使用 Term.word; 获取分词内容,Term.nature.toString() 获取分词的属性
2、把安卓端封装的功能接口暴露给 Unity 调用
/**
* 开始分词
* @param wordsContent
* @return 返回分词结果,和此属性
*/
public String segmentWork(String wordsContent)3、在 Unity 端获取 Android 端的对象接口,并简单处理信息,使之更适合在Unity端使用
MAndroidJavaObject.Call<string>("segmentWork", wordsContent)三、注意事项
1、中文的词会有对应较为准确的此属性,英文可能没有
2、Android 与 Unity 交互一般只能传递基础数据类型,列表对象的高级对象可能传递不了,这里把列表对象数据组装成字符串进行传递给 Unity ,Unity 在根据 string 解析拆出对应信息
四、效果预览
(这里词性只做了简单的对应,需要更多对应可以参见附录词性信息)

五、实现步骤
HanLP 包(hanlp-portable-1.7.5.jar ) 获取可以在这里直接在 Android Studio 中下载
Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理
1、打开 Android Studio ,创建一个模块工程,添加 hanlp-portable-1.7.5.jar 包
注意:记得添加为库
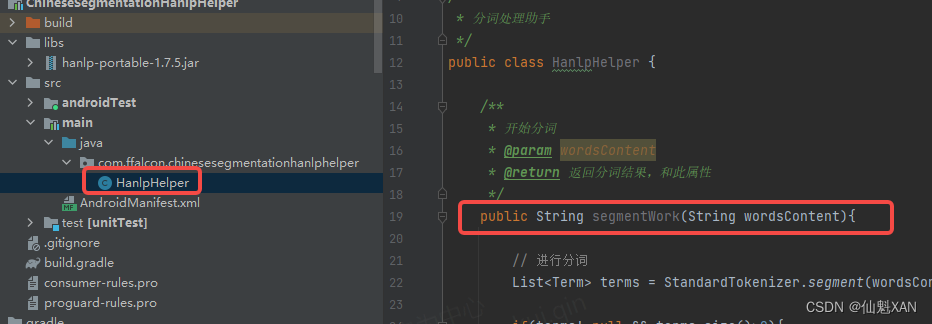
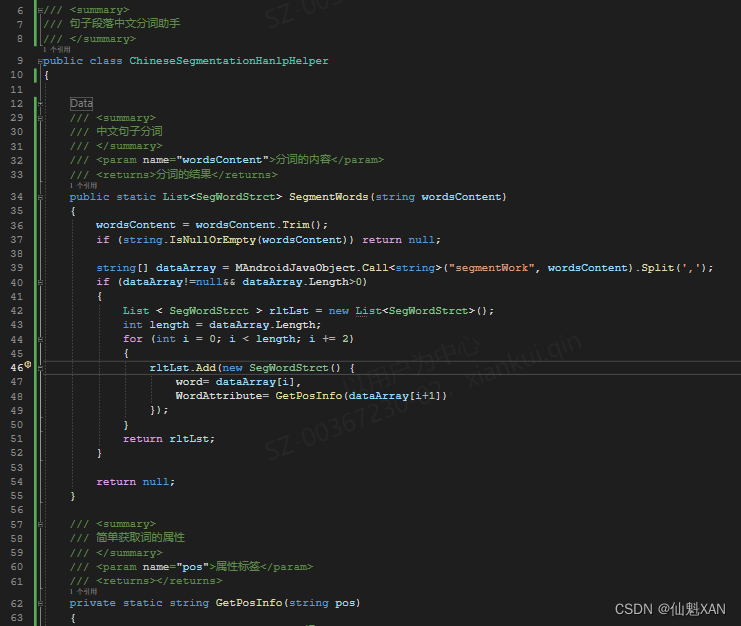
2、创建脚本,添加分词功能
3、创建一个 Unity 工程,把编译生成的 aar 给添加到 Unity 中
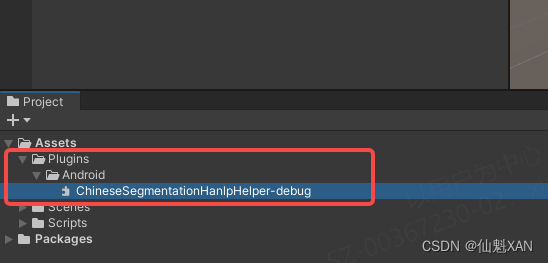
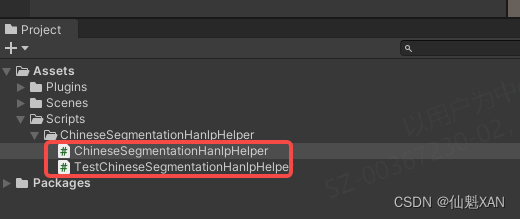
4、 在 Unity 中创建脚本,调用 Android 中封装的接口,并编写脚本测试功能

5、把测试脚本添加到场景中
6、打包,安装到机子上运行,效果如上
六、关键代码
1、TestChineseSegmentationHanlpHelper.cs
using System.Collections.Generic;
using UnityEngine;
public class TestChineseSegmentationHanlpHelper : MonoBehaviour
{
// Start is called before the first frame update
void Start()
{
List<SegWordStrct> segWordStrcts = ChineseSegmentationHanlpHelper.SegmentWords("今天深圳的天气如何");
foreach (var word in segWordStrcts)
{
Debug.Log($"{word.word},{word.WordAttribute}");
}
}
}2、ChineseSegmentationHanlpHelper.cs
using System.Collections.Generic;
using UnityEngine;
/// <summary>
/// 句子段落中文分词助手
/// </summary>
public class ChineseSegmentationHanlpHelper
{
#region Data
static AndroidJavaObject _mAndroidJavaObject;
protected static AndroidJavaObject MAndroidJavaObject
{
get
{
if (_mAndroidJavaObject == null)
{
_mAndroidJavaObject = new AndroidJavaObject("com.ffalcon.chinesesegmentationhanlphelper.HanlpHelper");
}
return _mAndroidJavaObject;
}
}
#endregion
/// <summary>
/// 中文句子分词
/// </summary>
/// <param name="wordsContent">分词的内容</param>
/// <returns>分词的结果</returns>
public static List<SegWordStrct> SegmentWords(string wordsContent)
{
wordsContent = wordsContent.Trim();
if (string.IsNullOrEmpty(wordsContent)) return null;
string[] dataArray = MAndroidJavaObject.Call<string>("segmentWork", wordsContent).Split(',');
if (dataArray!=null&& dataArray.Length>0)
{
List < SegWordStrct > rltLst = new List<SegWordStrct>();
int length = dataArray.Length;
for (int i = 0; i < length; i += 2)
{
rltLst.Add(new SegWordStrct() {
word= dataArray[i],
WordAttribute= GetPosInfo(dataArray[i+1])
});
}
return rltLst;
}
return null;
}
/// <summary>
/// 简单获取词的属性
/// </summary>
/// <param name="pos">属性标签</param>
/// <returns></returns>
private static string GetPosInfo(string pos)
{
// 这里你可以根据需要添加更多的判断逻辑来确定词性属性
if (pos.Equals("n"))
{
return WordAttributeStrDefine.Noun;
}
else if (pos.Equals("v"))
{
return WordAttributeStrDefine.Verb;
}
else if (pos.Equals("ns"))
{
return WordAttributeStrDefine.PlaceName;
}
else if (pos.Equals("t"))
{
return WordAttributeStrDefine.Time;
}
else
{
return WordAttributeStrDefine.Other;
}
}
}
/// <summary>
/// 数据分词结构
/// </summary>
public struct SegWordStrct
{
public string word;
public string WordAttribute;
}
/// <summary>
/// 此属性文字定义
/// 较多,这里只定义了部分
/// </summary>
public class WordAttributeStrDefine {
public const string Noun ="名词";
public const string Verb ="动词";
public const string PlaceName ="地名";
public const string Time ="时间";
public const string Other ="其他";
}
3、HanlpHelper.java
package com.xxxx.chinesesegmentationhanlphelper;
import com.hankcs.hanlp.seg.common.Term;
import com.hankcs.hanlp.tokenizer.StandardTokenizer;
import java.util.ArrayList;
import java.util.List;
/**
* 分词处理助手
*/
public class HanlpHelper {
/**
* 开始分词
* @param wordsContent
* @return 返回分词结果,和此属性
*/
public String segmentWork(String wordsContent){
// 进行分词
List<Term> terms = StandardTokenizer.segment(wordsContent);
if(terms!=null && terms.size()>0){
List<String> rltWordAttr = new ArrayList<>();
// 遍历分词结果,判断词性并打印
for (Term term : terms) {
String word = term.word;
String pos = term.nature.toString();
String posInfo = getPosInfo(pos); // 判断词性属性
System.out.println("Word: " + word + ", POS: " + pos + ", Attribute: " + posInfo);
rltWordAttr.add(word);
rltWordAttr.add(pos);
}
String[] dataArray = rltWordAttr.toArray(new String[0]);
return String.join(",", dataArray);
}
return null;
}
/**
* 判断词性属性
* @param pos
* @return
*/
public String getPosInfo(String pos) {
// 这里你可以根据需要添加更多的判断逻辑来确定词性属性
if (pos.equals("n")) {
return "名词";
} else if (pos.equals("v")) {
return "动词";
} else if (pos.equals("ns")) {
return "地名";
}else if (pos.equals("t")) {
return "时间";
}
else {
return "其他";
}
}
}
附录:在 HanLP 中,Term 对象的 nature 字段表示词性
在 HanLP 中,Term 对象的 nature 字段表示词性(Part of Speech,POS)。HanLP 使用了一套标准的中文词性标注体系,每个词性都有一个唯一的标识符。以下是一些常见的中文词性标注及其含义:
名词类:
n:普通名词
nr:人名
ns:地名
nt:机构名
nz:其他专名
nl:名词性惯用语
ng:名词性语素时间类:
t:时间词动词类:
v:动词
vd:副动词
vn:名动词
vshi:动词"是"
vyou:动词"有"形容词类:
a:形容词
ad:副形词副词类:
d:副词代词类:
r:代词
rr:人称代词
rz:指示代词
rzt:时间指示代词连词类:
c:连词助词类:
u:助词数词类:
m:数词量词类:
q:量词语气词类:
y:语气词叹词类:
e:叹词拟声词类:
o:拟声词方位词类:
f:方位词状态词类:
z:状态词介词类:
p:介词前缀类:
h:前缀后缀类:
k:后缀标点符号类:
w:标点符号请注意,上述只是一些常见的词性标注及其含义,实际情况可能更复杂。你可以根据需要调查 HanLP 的文档来了解更多词性标注的详细信息。根据这些词性标注,你可以编写代码来判断词的属性(如动词、名词、地名等)并进行相应的处理。