Boost 库是一个由C/C++语言的开发者创建并更新维护的开源类库,其提供了许多功能强大的程序库和工具,用于开发高质量、可移植、高效的C应用程序。Boost库可以作为标准C库的后备,通常被称为准标准库,是C标准化进程的重要开发引擎之一。使用Boost库可以加速C应用程序的开发过程,提高代码质量和性能,并且可以适用于多种不同的系统平台和编译器。Boost库已被广泛应用于许多不同领域的C++应用程序开发中,如网络应用程序、图像处理、数值计算、多线程应用程序和文件系统处理等。
- Boost库官网:https://www.boost.org/
读者可自行去官方下载对应特定编译器的二进制文件,在官方网站页面中选中More Downloads... (RSS)下载页面,并点击Prebuilt windows binaries则可打开二进制预编译版本的对应页面。
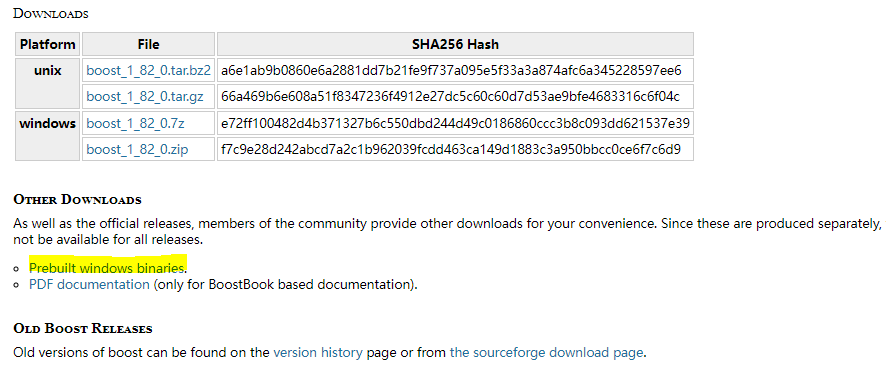
此时读者可根据自己编译器的版本选择适合于自己的库,此处笔者使用的是Visual Studio 2013编译器,所以此处选中的是1.82.0目录下的boost_1_82_0-msvc-12.0-32.exe安装包,下载好以后读者可将该库安装到自定义目录下,此处笔者就安装在默认路径下,当安装成功后读者可看到如下图所示的输出信息,至此安装结束;

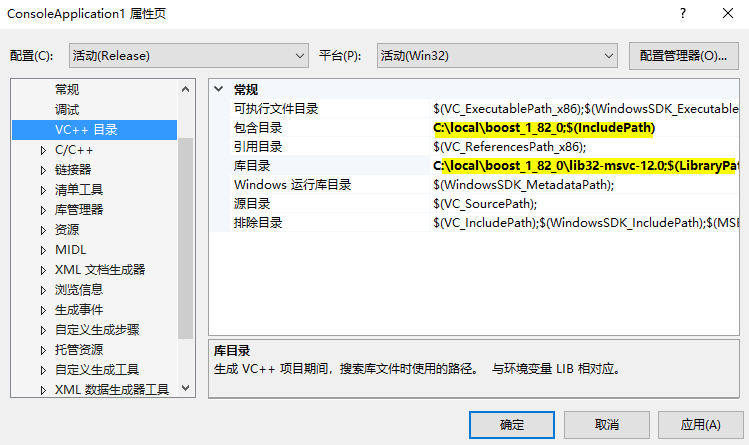
在安装完成后,读者可自行打开安装目录,该目录中我们所需要配置的选项只有两个,首先读者需要在VS中引入boost_1_82_0目录,并在类库选项上引入lib32-msvc-12.0即可,如下图所示则是正常引用后的配置参数;
在C语言的早期版本中,对于字符串和文本的处理一直都是最为薄弱的,直到C++98规范的推出才勉强增加了一个std::string的类,虽然在一定程度上弥补了字符串处理的不足,但仍然缺少一些更为强大和丰富的字符串处理和操作工具。
随着Boost库的推出和广泛应用,该库内置了多种用于字符串和文本处理的强大工具,为C程序员提供了强大的库和更全面的支持。Boost库中的字符串处理工具包括字符串分割、替换、转换、截断以及正则表达式等功能。使用Boost库,C程序员现在可以轻松地处理字符串和文本数据,开发更加高效和强大的C应用程序。
1.1 字符串格式转换
lexical_cast是Boost库中用于类型转换的一种强大的工具。它可以将一个类型的对象转换为另一个类型,例如将字符串类型的数据转换为数字类型的数据。它简化了类型转换的代码,并提供了一些错误检查,以确保转换的安全性。在使用lexical_cast时,程序员只需指定需要转换的源数据类型和目标数据类型即可,在大多数情况下,可以自动完成转换,lexical_cast是字符串格式转换的一个重要工具,非常适用于将字符串和数字类型之间进行快速而安全的转换。
但读者需要注意,lexical_cast并不支持自定义类型的转换,例如自定义类或结构体。如果需要进行自定义类型的转换,需要使用Boost库中的其他工具或者自行编写转换函数。
#include <iostream>
#include <string>
#include <boost\lexical_cast.hpp>
using namespace std;
using namespace boost;
int main(int argc, char * argv[])
{
string str[3] = { "100", "102", "3.14159" };
// 字符串转换为数值类型
std::cout << "字符串转为整数: " << lexical_cast<int>(str[0]) << std::endl;
std::cout << "字符串转为长整数: " << lexical_cast<long>(str[1]) << std::endl;
std::cout << "字符串转为浮点数: " << lexical_cast<float>(str[2]) << std::endl;
// 数值类型转化为字符串
std::cout << "数值转为字符串: " << lexical_cast<string>(100) << std::endl;
std::cout << "十六进制转为十进制: " << lexical_cast<string>(0x10) << std::endl;
// 转换后赋值给变量
try{
int number = lexical_cast<int>(str[0]);
std::cout << "转换后赋值给变量: " << number << std::endl;
}
catch(bad_lexical_cast&){
std::cout << "转换失败抛出异常." << std::endl;
}
system("pause");
return 0;
}
此外C++默认库中同样提供了一些可实现字符串与数值之间转换的函数,这些函数包括了atoi,itoa,atof,gcvt,这些内置函数库通常不具有lexical_cast函数所提供的错误检查和异常处理机制,因此在使用时还需要特别注意程序的输出结果。
#include <iostream>
#include <string>
#include <sstream>
#include <boost\lexical_cast.hpp>
using namespace std;
using namespace boost;
int main(int argc, char * argv[])
{
string str[3] = { "100", "102", "3.14159" };
int inter[3] = { 100, 45, 7 };
// atoi
int number_a = atoi(str[0].c_str());
std::cout << "字符串转为整数: " << number_a << std::endl;
// itoa
char buf1[64] = {0};
itoa(inter[0], buf1, 16);
std::cout << "将inter[0]转为16进制并放入buf中: " << buf1 << std::endl;
// atof
double number_b = atof(str[2].c_str());
std::cout << "将字符串转为双精度: " << number_b << std::endl;
// gcvt
char buf2[64] = { 0 };
char *number_c = gcvt(3.54655, 3, buf2);
std::cout << "将浮点数转为字符串,保留两位(四舍五入): " << buf2 << std::endl;
// sprintf
char buf3[64] = { 0 };
int number_d = 10245;
sprintf(buf3, "%d", number_d);
std::cout << "将number_d中的整数转为字符串: " << buf3 << std::endl;
system("pause");
return 0;
}
1.2 字符串格式输出
format是Boost库中用于格式化字符串的工具。它提供了一种简单、安全和灵活的方式来生成格式化字符串,并支持广泛的格式标识符和操作符。使用boost::format,程序员可以在字符串中插入变量、数字等内容,并指定它们的格式。在boost::format中,执行的格式化操作使用类似于printf中格式化字符串的方式,以"{n}"形式表示变量的位置,并使用占位符指定变量的类型和格式。例如,以下示例利用boost::format分别实现了四种不同的格式化方法:
#include <iostream>
#include <string>
#include <boost\format.hpp>
using namespace std;
using namespace boost;
int main(int argc, char * argv[])
{
// 第一种方式: 直接填充字符串
boost::format fmtA("姓名: %s -> 年龄: %d -> 性别: %s");
fmtA %"lyshark";
fmtA % 22;
fmtA %"男";
std::string str = fmtA.str();
std::cout << "第一种输出: " << str << std::endl;
// 第二种方式: 拷贝的使用
boost::format fmtB("姓名: %s -> 年龄: %d -> 性别: %s");
std::cout << "第二种输出: " << format(fmtB) % "lyshark" % 23 % "男" << std::endl;
// 第三种方式: 拷贝后强转
std::string str_format = boost::str(boost::format("%d.%d.%d.%d") % 192.%168.%1. % 100);
std::cout << "第三种输出: " << str_format << std::endl;
// 第四种方式: 格式化输出
// %|10s| 输出宽度为10,不足补空格
// %|06X| 输出宽度为7的大写16进制整数
boost::format str_tmp("%|10s|\n %|07X|\n");
str_tmp %"lyshark" % 100;
string str_format_B = boost::str(str_tmp);
std::cout << "第四种输出: " << str_format_B << endl;
system("pause");
return 0;
}
1.3 字符串大小写转换
字符串大小写转换可使用to_upper()和to_lower()这两个函数,这两个函数都是Boost库中的字符串处理函数,它们与C++标准库的同名函数功能类似,但支持更广泛的字符集以满足更多应用场景的需求。boost::to_upper()函数将指定字符串中的字母字符全部转换为大写格式,并返回转换后的新字符串;boost::to_lower()函数则将指定字符串中的字母字符全部转换为小写格式,并返回转换后的新字符串。
以下是使用boost::to_upper()和boost::to_lower()进行字符串大小写转换的示例:
#include <iostream>
#include <Windows.h>
#include <string>
#include <vector>
#include <boost\algorithm\string.hpp>
using namespace std;
using namespace boost;
int main(int argc, char * argv[])
{
vector<string> str_array = { "hello" , "lyshark" , "welcome" , "to" , "my" , "blog" };
// 循环转换为大写,to_upper_copy不会影响原生字符串
for (int x = 0; x < str_array.size(); x++)
{
string item = to_upper_copy(str_array[x]);
std::cout << "转换拷贝: " << item << std::endl;
}
std::cout << "原始字符串不受影响: " << str_array[1] << std::endl;
// 如果使用to_upper 则会直接修改原生字符串
for (int x = 0; x < str_array.size(); x++)
{
to_upper(str_array[x]);
}
std::cout << "原始字符串受影响: " << str_array[1] << std::endl;
system("pause");
return 0;
}
在这个示例中,通过调用boost::to_upper()和boost::to_lower()函数,将指定字符串中的字母字符全部转换为大写或小写,并输出转换后的新字符串。细心的读者应该还可以观察到to_upper_copy在其后方存在一个COPY字符,当出现拷贝字符时则预示着需要对原始字符串进行拷贝而不是直接更改原始字符串的意思。
1.4 字符串判断与测试
starts_with()和ends_with()也是Boost库中的字符串处理函数。这两个函数分别用于检查一个字符串是否以指定字符串开头或结尾,而contains()则可用于测试字符串的属性。
boost::starts_with接收两个参数,第一个参数是待检查的字符串,第二个参数是被检查作为开头的字符串,返回一个bool值表示原始字符串是否以目标字符串开头。
boost::ends_with也是接收两个参数,第一个参数是待检查的字符串,第二个参数是被检查作为结尾的字符串,返回一个bool值表示原始字符串是否以目标字符串结尾。以下是boost::starts_with()和boost::ends_with()两个函数的示例:
#include <iostream>
#include <string>
#include <boost\algorithm\string.hpp>
using namespace std;
using namespace boost;
int main(int argc, char * argv[])
{
string str[6] = { "hello lyshark", "hello LyShark", "readme.txt", "ABC", "FCE", "lyshark" };
cout << "大小写不敏感判断后缀: " << iends_with(str[0], "lyshark") << endl;
cout << "大小写敏感判断前缀: " << starts_with(str[1], "Hello") << endl;
cout << "测试str[0]里面是否包含str[5]: " << contains(str[0], str[5]) << endl;
cout << "测试前5个字母是否为小写: " << all(str[0].substr(0, 5), is_lower()) << endl;
cout << "测试前2个字符是否为字母: " << all(str[1].substr(0, 2), is_alpha()) << endl;
system("pause");
return 0;
}
1.5 字符串修正与裁剪
boost::replace_first_copy()、boost::replace_last_copy()、boost::trim()、boost::trim_left()和boost::trim_right()都是Boost库中的字符串处理函数。
replace_first_copy用于将字符串中第一个匹配的子字符串替换为新的字符串,返回替换后的新字符串并不改变原字符串。
replace_last_copy函数则用于将字符串中最后一个匹配的子字符串替换为新的字符串,同样返回替换后的新字符串且不改变原字符串。
trim()、trim_left和trim_right用于去除字符串两端的空格或指定的字符,返回处理后的新字符串并不改变原字符串。
其中,boost::trim()函数是去除字符串两端的空格,boost::trim_left()函数是去除字符串左端的空格或指定字符,boost::trim_right()函数是去除字符串右端的空格或指定字符。以下是这几个函数的示例:
#include <iostream>
#include <string>
#include <vector>
#include <boost\format.hpp>
#include <boost\algorithm\string.hpp>
using namespace std;
using namespace boost;
int main(int argc, char * argv[])
{
string str[6] = { "hello lyshark", "hello LyShark", "readme.txt", "ABC", "FCE", "lyshark" };
// 字符串替换: 替换开头/结尾 字符串hello为lyshark
std::cout << replace_first_copy(str[0], "hello", "lyshark") << std::endl;
std::cout << replace_last_copy(str[0], "hello", "lyshark") << std::endl;
// 字符串删除: 删除字符串结尾的.txt并将其开头部分转换为大写
vector<char> v(str[2].begin(), str[2].end());
vector<char> v2 = to_upper_copy(erase_first_copy(v, ".txt"));
for (auto x : v2)
std::cout << x;
std::cout << std::endl;
// 字符串修剪: 去除字符串中的空格或-
boost::format fmt("|%s|\n");
std::string my_string_a = " hello lyshark ";
cout << "删除两端空格: " << fmt %trim_copy(my_string_a) << endl;
cout << "删除左端空格: " << fmt %trim_left_copy(my_string_a) << endl;
cout << "删除左端空格: " << fmt %trim_right_copy(my_string_a) << endl;
std::string s = "--lyshark--";
std::cout << "删除左侧所有的-: " << trim_left_copy_if(s, is_any_of("-")) << std::endl;
std::cout << "删除右侧所有的-: " << trim_right_copy_if(s, is_any_of("-")) << std::endl;
std::cout << "删除两侧所有的-: " << trim_copy_if(s, is_any_of("-")) << std::endl;
// 字符串修剪: 去除字符串中的特殊符号
std::string my_string_b = "2021 happy new Year !!!";
cout << "删除左端数字: " << fmt %trim_left_copy_if(my_string_b, is_digit()) << endl;
cout << "删除右端标点: " << fmt %trim_right_copy_if(my_string_b, is_punct()) << endl;
cout << "删除两端(标点|数字|空格): " << trim_copy_if(my_string_b, is_punct() || is_digit() || is_space()) << endl;
system("pause");
return 0;
}
1.6 字符串匹配开头结尾
boost::find_first()、boost::find_last()、boost::ifind_nth()和boost::ifind_last()都是Boost库中的字符串处理函数,用于在字符串中查找指定的子字符串。
find_first函数接收两个参数,第一个参数是待查找的字符串,第二个参数是要查找的目标子字符串,返回指向第一个匹配子字符串的迭代器,如果没有找到,返回末尾迭代器。
find_last函数则是在待查找的字符串中从后向前查找指定子字符串的第一次出现,同样返回指向子字符串的迭代器或末尾迭代器。
ifind_nth和ifind_last函数均利用不区分大小写的方式进行字符串查找,可以根据需要查找一定位置处的指定数量的子字符串。如果找到了目标子字符串,返回一个指向它的迭代器,否则返回一个指向结束迭代器(end)的迭代器。
#include <iostream>
#include <string>
#include <boost\format.hpp>
#include <boost\algorithm\string.hpp>
using namespace std;
using namespace boost;
int main(int argc, char const *argv[])
{
boost::format fmt("|%s|. pos = %d\n");
std::string my_string = "Long long ago, there was Ago king as long.";
// 定义迭代区间
iterator_range<std::string::iterator> reg;
// 寻找第一次出现的位置(大小写敏感)
reg = find_first(my_string, "Ago");
cout << fmt %reg % (reg.begin() - my_string.begin()) << endl;
// 寻找最后一次出现的位置(大小写不敏感)
reg = ifind_last(my_string, "ago");
cout << fmt %reg % (reg.begin() - my_string.begin()) << endl;
// 寻找第三次出现long的位置(大小写不敏感)
reg = ifind_nth(my_string, "long", 2);
cout << fmt %reg % (reg.begin() - my_string.begin()) << endl;
// 取前四个字符
reg = find_head(my_string, 4);
cout << fmt %reg % (reg.begin() - my_string.begin()) << endl;
// 取后四个字符
reg = find_tail(my_string, 4);
cout << fmt %reg % (reg.begin() - my_string.begin()) << endl;
// 找不到则输出
reg = find_first(my_string, "lyshark");
cout << "flag = " << (reg.empty() && !reg) << endl;
system("pause");
return 0;
}
1.7 字符串替换与删除
boost::replace_first()、boost::replace_tail()、boost::replace_head()、和boost::replace_nth()是Boost库中的字符串处理函数,用于替换指定字符串中的子字符串。
replace_first函数用于在给定字符串中替换第一个匹配的子字符串,接收三个参数,第一个参数是源字符串,第二个参数是查找的目标子串,第三个参数是替换子串,函数返回被处理后的原字符串对象。
replace_tail和replace_head的作用与replace_first类似,但是在字符串的头或尾部查找需要替换的字符串,并进行替换操作。
replace_nth函数用于替换源字符串中的指定位置的子字符串,接收四个参数,第一个参数是源字符串,第二个参数是要替换的子串,第三个参数是替换后的子串,第四个参数是指定要替换的子串的位置(从0开始计数),函数返回被处理后的原字符串对象。
#include <iostream>
#include <string>
#include <boost\format.hpp>
#include <boost\algorithm\string.hpp>
using namespace std;
using namespace boost;
int main(int argc, char const *argv[])
{
boost::format fmt("|%s|. pos = %d\n");
std::string my_string = "Long long ago, there was Ago king as long.";
// 替换开头字符串(两种替换方式)
std::string str_copy = replace_first_copy(my_string, "long", "LONG");
cout << "替换后返回字符串: " << str_copy << endl;
replace_first(my_string, "ago", "AGO");
cout << "直接替换在原始字符串上: " << my_string << endl;
// 替换开头或结尾前后5个字符
replace_tail(my_string, 5, "lyshark");
cout << "替换结尾5个字符: " << my_string << endl;
replace_head(my_string, 5, "lyshark");
cout << "替换开头5个字符: " << my_string << endl;
// 替换第一次出现long的位置为AGES
replace_nth(my_string, "long", 0, "AGES");
cout << "第一次出现位置: " << my_string << endl;
// 替换所有出现过的位置
std::string str_copy_a = replace_all_copy(my_string, "lyshark", "LYSSHARK");
cout << "替换所有位置: " << str_copy_a << endl;
// 删除第1次出现was位置的字符串
std::string del_str_copy = erase_nth_copy(my_string, "was", 0);
cout << "删除后的字符串: " << del_str_copy << endl;
// 删除字符串中所有的LYSSHARK
erase_all(my_string, "LYSSHARK");
cout << "删除后的字符串: " << my_string << endl;
getchar();
return 0;
}
1.8 字符串切割与合并
boost::split()和boost::join()函数都是Boost库中的字符串处理函数,用于分割和连接字符串。
split函数用于将一个字符串按照给定的分隔符拆分成多个子字符串,并将这些子字符串存储到一个容器中。split函数接收三个参数:源字符串、分隔符和存储子字符串的容器。
join函数则是将多个子字符串按照给定的分隔符连接成一个新的字符串,join函数接收两个参数:存储子字符串的容器和分隔符。
#include <iostream>
#include <string>
#include <algorithm>
#include <boost\algorithm\string.hpp>
#include <boost\assign.hpp>
using namespace std;
using namespace boost;
int main(int argc, char const *argv[])
{
std::string my_string = "lyshark,Link.Zelda:Mario-Ligui+zelda,ZELDA";
// 查找字符串中的特定字符串
deque<std::string> deq;
ifind_all(deq, my_string, "zelda");
cout << "查找字符串个数(不区分大小写): " << deq.size() << endl;
if (deq.size() == 3)
{
for (auto each : deq)
cout << "[ " << each << " ]" << endl;
}
// 切割字符串(1)
list<iterator_range<std::string::iterator>> ptr;
split(ptr, my_string, is_any_of(",.:-+"));
for (auto each : ptr)
cout << "[ " << each << " ]" << endl;
// 切割字符串(2)
ptr.clear();
split(ptr, my_string, is_any_of(".:-"), token_compress_on);
for (auto each : ptr)
cout << "[ " << each << " ]" << endl;
// 合并字符串: 用空格将其连接起来
std::vector<string> vct;
vct.push_back("hello");
vct.push_back("lyshark");
cout << "[ " << join(vct, " ") << " ]"<< endl;
system("pause");
return 0;
}
字符串的分割除去上述分割方式外同样可以采用如下方式分割,该方法将字符串放入一个vector::string容器内,并循环每次判断是否为|数显如果是则输出,利用此方式实现字符串的切割。
std::vector<std::string> vect;
std::string mystr = "a | b | c | d | e | f";
boost::split(vect, mystr, boost::is_any_of("|"), boost::token_compress_on);
for (int i = 0; i < vect.size(); ++i)
{
cout << vect[i] << endl;
}
1.9 整数转字符串并合并
boost::algorithm::join()是Boost库中对于字符串拼接的函数,它可以将一个存储子字符串的容器中的所有字符串用指定的分隔符进行拼接。 该函数的返回值是一个字符串,内容为拼接后形成的新字符串。
该函数不仅仅可用于字符串之间的拼接还可以实现整数浮点数与字符串之间的转换,如下案例中则是先了这两者之间的灵活转换。
#include <iostream>
#include <vector>
#include <boost/algorithm/string/join.hpp>
#include <boost/range/adaptor/transformed.hpp>
using boost::adaptors::transformed;
using boost::algorithm::join;
int main(int argc, char *argv[])
{
std::vector<int> vect_int(10);
std::vector<double> vect_double(10);
// 随机数填充元素
std::generate(vect_int.begin(), vect_int.end(), std::rand);
std::generate(vect_int.begin(), vect_int.end(), std::rand);
// 转换并连接
std::string ref_string_int = join(vect_int | transformed(static_cast<std::string(*)(int)>(std::to_string)), ", ");
std::cout << "整数转为字符串:" << ref_string_int << std::endl;
// 转换并连接
std::string ref_string_double = join(vect_int | transformed(static_cast<std::string(*)(double)>(std::to_string)), ", ");
std::cout << "浮点数转为字符串:" << ref_string_double << std::endl;
system("pause");
return 0;
}
1.10 字符串查找/分割迭代器
boost::make_find_iterator()和boost::make_split_iterator()都是Boost库中的字符串处理函数,用于生成指向容器和字符串序列的迭代器。
make_find_iterator 用于生成一个指向容器或字符串序列中第一个匹配指定字符串的迭代器,接收两个参数,第一个参数是源容器或字符序列,第二个参数是匹配的子字符串。如果没有匹配到子字符串,返回的迭代器将指向容器或字符串序列的末尾。
make_split_iterator 则用于生成一个分隔符迭代器,可以用于将字符串分割成多个子字符串,接收两个参数,第一个参数是源字符序列或容器,第二个参数是分隔符。使用迭代器可以遍历分割后的字符串序列。
#include <iostream>
#include <string>
#include <algorithm>
#include <boost\algorithm\string.hpp>
#include <boost\assign.hpp>
using namespace std;
using namespace boost;
int main(int argc, char const *argv[])
{
std::string my_string("hello||lyshark||welcome||link||lyshark");
// 查找迭代器: 查找字符串中的lyshark
typedef find_iterator<string::iterator> string_find_iterator;
string_find_iterator pos, end;
for (pos = make_find_iterator(my_string, first_finder("lyshark", is_iequal())); pos != end; ++pos)
{
cout << "[ " << *pos << " ]" << endl;
}
std::cout << "----------------------------" << std::endl;
// 分割迭代器: 根据||分割字符串
typedef split_iterator<string::iterator> string_split_iterator;
string_split_iterator p, endp;
for (p = make_split_iterator(my_string, first_finder("||", is_iequal())); p != endp; ++p)
{
cout << "[ " << *p << " ]" << endl;
}
system("pause");
return 0;
}
除去使用上方的分割器实现字符串切割以外,读者也可以使用Boost中提供的tokenizer分词器实现切割,boost::tokenizer()的使用非常简单,只需定义一个tokenizer对象,指定要分割的字符串和分隔符即可。可以使用多个不同的构造函数来指定不同的分隔符,其中char_separator和boost_regex_separator分别使用字符和正则表达式作为分隔符。
#include <iostream>
#include <boost/tokenizer.hpp>
using namespace std;
using namespace boost;
int main(int argc, char const *argv[])
{
std::string strTag = "explorer.exe,1024";
// 定义分词器: 定义分割符号为[逗号,空格]
boost::char_separator<char> sep(", ");
typedef boost::tokenizer<boost::char_separator<char>> CustonTokenizer;
CustonTokenizer tok(strTag, sep);
// 将分词结果放入vector链表
std::vector<std::string> vecSegTag;
for (CustonTokenizer::iterator beg = tok.begin(); beg != tok.end(); ++beg)
{
vecSegTag.push_back(*beg);
}
// const_case 将string转换为char*
std::string ref_process = const_cast<char *>(vecSegTag[0].c_str());
std::string ref_ppid = const_cast<char *>(vecSegTag[1].c_str());
cout << "进程名: " << ref_process << " 进程PID: " << ref_ppid<< endl;
cout << "分词数: " << vecSegTag.size() << endl;
system("pause");
return 0;
}
1.11 正则分组匹配字符串
boost::regex_match是Boost库中用于正则表达式匹配的函数,用于判断一个字符串是否符合给定的正则表达式模式。使用改函数可以帮助程序员在程序开发中实现高度的正则表达式匹配。在使用boost::regex_match时,需要注意正确理解正则表达式的规则才能有效地应用。
regex_match函数接收两个参数,第一个参数是要匹配的字符串,第二个参数是一个正则表达式对象。在匹配成功时,regex_match函数返回true;否则返回false。
#include <iostream>
#include <string>
#include <algorithm>
#include <boost\algorithm\string.hpp>
#include <boost\xpressive\xpressive.hpp>
using namespace std;
using namespace boost;
int main(int argc, char const *argv[])
{
using namespace boost::xpressive;
// 匹配字符串
std::string String = "hello lyshark ac lyshark";
sregex start_regx = sregex::compile("^hello.*");
cout << "匹配开头: " << regex_match(String, start_regx) << endl;
sregex end_regx = sregex::compile(".*lyshark$");
cout << "匹配结尾: " << regex_match(String, end_regx) << endl;
// 数组方式匹配
cregex_compiler regx;
regx["regxA"] = regx.compile("a|b|c");
regx["regxB"] = regx.compile("\\d*");
cout << "匹配A: " << regex_match("abcdefg", regx["regxA"]) << endl;
cout << "匹配B: " << regex_match("123123", regx["regxB"]) << endl;
system("pause");
return 0;
}
正则模块支持分组匹配模式,通过cregex::compile可用于生成不同的匹配规则,在匹配时读者可根据不同的匹配规则实现对不同字符串的匹配以此来实现分组匹配的目的,需要注意的是,在匹配时C++ 11规范中需要在规则字符串开头结尾加入---横线,而在C++ 98规范中,则需要增加\符号。
#include <iostream>
#include <string>
#include <algorithm>
#include <boost\algorithm\string.hpp>
#include <boost\xpressive\xpressive.hpp>
using namespace std;
using namespace boost;
int main(int argc, char const *argv[])
{
using namespace boost::xpressive;
// 使用C++ 11 匹配身份证
cregex regx11 = cregex::compile(R"---(\d{6}(1|2)\d{3}(0|1)\d[0-3]\d\d{3}(X|\d))---", icase);
cout << "验证身份证: " << regex_match("513436200002247099", regx11) << endl;
// 使用C++ 98 匹配身份证
cregex regx98 = cregex::compile("\\d{6}((1|2)\\d{3})((0|1)\\d)([0-3]\\d)(\\d{3}(X|\\d))", icase);
cmatch what;
std::string str = "513436200002247099";
regex_match(str.c_str(), what, regx98);
for (auto &each : what)
{
cout << "[ " << each << " ]" << endl;
}
cout << "生日为: " << what[1] << what[3] << what[5] << endl;
system("pause");
return 0;
}
1.12 正则查找替换
regex_search函数用于在一个字符串中查找与指定的正则表达式匹配的任何序列,返回true或false,不像regex_match()函数需要匹配整个字符串。如果匹配成功,可以使用smatch对象的operator[]操作符以及first, second等函数来获取匹配结果。
regex_replace和regex_replace的用法非常相似。它们都可以用指定的正则表达式替换字符串中的部分内容。同样需要一个std::string对象和一个std::regex对象来替换目标字符串中的部分内容。只是boost::regex_replace()需要额外的一个调用参数来指定替换的跟踪处理方式,而std::regex_replace()不需要。
#include <iostream>
#include <string>
#include <algorithm>
#include <boost\algorithm\string.hpp>
#include <boost\xpressive\xpressive.hpp>
using namespace std;
using namespace boost;
int main(int argc, char const *argv[])
{
using namespace boost::xpressive;
// 正则查找特定字符串
char my_stringA[] = "This is power-studio territory";
cregex regx = cregex::compile("(power)-(.{6})", icase);
cmatch what;
regex_search(my_stringA, what, regx);
if (what.size() != 0)
{
for (int x = 0; x < what.size(); x++)
{
cout << what[x] << endl;
}
}
// 正则替换特定字符串
std::string my_stringB = "2020 Happy New Year !!!";
sregex regxA = sregex::compile("^(\\d| )*"); // 匹配开头数字
sregex regxB = sregex::compile("!*$"); // 匹配末尾标点符号
cout << regex_replace(my_stringB, regxA, "2021") << endl;
cout << regex_replace(my_stringB, regxB, "") << endl;
system("pause");
return 0;
}
1.13 正则迭代与分词
boost::sregex_iterator()和boost::cregex_token_iterator()是Boost库中用于正则表达式处理的迭代器,它们可以帮助我们在字符串中查找或分解出与指定的正则表达式模式匹配的子字符串序列。
sregex_iterator 迭代查找一个输入字符串中符合给定正则表达式模式的所有匹配字符串序列。
cregex_token_iterator 迭代器可将输入字符串分解为非匹配部分和与指定的正则表达式模式匹配的子字符串序列。
#include <iostream>
#include <string>
#include <algorithm>
#include <boost\algorithm\string.hpp>
#include <boost\xpressive\xpressive.hpp>
#include <boost\xpressive\regex_iterator.hpp>
using namespace std;
using namespace boost;
int main(int argc, char const *argv[])
{
using namespace boost::xpressive;
std::string my_string_a = "power-shell, power-studio,power-engine,super-user";
char my_string_b[] = "*lyshark*||+administrator+||root!!||metaper";
// 正则迭代输出
sregex regxA = sregex::compile("power-(\\w{5})", icase);
sregex_iterator start_ptr(my_string_a.begin(), my_string_a.end(), regxA);
sregex_iterator end_ptr;
for (; start_ptr != end_ptr; ++start_ptr)
{
cout << "[ " << (*start_ptr)[0] << " ]" << endl;
}
std::cout << "----------------------------------" << std::endl;
// 正则分词: 分出所有的字母
cregex regxB = cregex::compile("\\w+", icase);
cregex_token_iterator pos(my_string_b, my_string_b + strlen(my_string_b), regxB);
for (; pos != cregex_token_iterator(); ++pos)
{
cout << "[ " << *pos << " ]" << endl;
}
system("pause");
return 0;
}
1.14 正则切割与过滤
boost::cregex_token_iterator()与boost::regex_replace()都是Boost库中用于正则表达式处理的函数。
cregex_token_iterator,用于将一个字符串分解成子字符串序列,其中根据正则表达式的匹配模式。我们可以使用boost::regex_token_iterator对象迭代访问这些子字符串,每次迭代将获得一个匹配的子字符串。
regex_replace,函数则是用于正则表达式替换的函数,它可以根据正则表达式的匹配模式,在输入字符串中搜索并替换与指定模式匹配的字符串。
#include <iostream>
#include <string>
#include <algorithm>
#include <boost\algorithm\string.hpp>
#include <boost\xpressive\xpressive.hpp>
#include <boost\xpressive\regex_iterator.hpp>
using namespace std;
using namespace boost;
int main(int argc, char const *argv[])
{
using namespace boost::xpressive;
char my_string[] = "*lyshark*||+administrator+||root!!||metaper";
cregex_token_iterator pos;
// 正则切割
cregex split_regx = cregex::compile("\\|\\|");
pos = cregex_token_iterator(my_string, my_string + strlen(my_string), split_regx, -1);
for (; pos != cregex_token_iterator(); ++pos)
{
cout << "[ " << *pos << " ]" << endl;
}
// 正则格式化(小写转大写)
struct formater
{
string operator()(cmatch const &m) const
{
return boost::to_upper_copy(m[0].str());
}
};
char my_string_b[] = "*lyshark*||+administrator+||root!!||metaper||*lyshark*";
cregex regxC = cregex::compile("\\w+", icase);
cout << "小写转大写输出: " << regex_replace(my_string_b, regxC, formater()) << endl;
// 正则过滤(过滤出所有lyshark)
struct grep_formater
{
string operator()(cmatch const &m) const
{
std::cout << m[0].str() << std::endl;
if (m[0].str() == "lyshark")
{
return "SuperUser";
}
return boost::to_upper_copy(m[0].str());
}
};
cout << "替换输出: " << regex_replace(my_string_b, regxC, grep_formater()) << endl;
system("pause");
return 0;
}
本文作者: 王瑞
本文链接: https://www.lyshark.com/post/5c088cb9.html
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!