文章目录
- 一、查询优化
- 1. 索引失效
- (1)不满足最左前缀法则,索引失效
- (2)在索引列上做任何计算、函数操作,索引失效
- (3)存储引擎使用索引中范围条件右边的列,索引失效
- (4)Mysql使用不等于时,索引失效
- (5)is null可以使用索引,但是is not null无法使用索引
- (6)like以通配符开头,索引失效
- (7)字符串不加单引号,索引失效
- (8)使用or连接时,索引失效
- 小结
- 2. 排序优化
- 3. 单表优化
- 4. 关联查询优化
- 5. 分组优化
- 二、慢查询日志
- 1. 慢查询日志简介
- 2. 慢查询日志使用
一、查询优化
1. 索引失效
(1)最左前缀法则:如果索引有多列,要遵循最左前缀法则,指的是查询从索引的最左前列开始并且不跳过索引中的列。(针对复合索引)
(2)不在索引列上做任何计算、函数操作,会导致索引失效而转向全表扫描。
(3)存储引擎不能使用索引中范围条件右边的列。
(4)Mysql在使用不等于时无法使用索引,会导致全表扫描。
(5)is null可以使用索引,但是is not null无法使用索引。
(6)like以通配符开头会使索引失效,导致全表扫描。
(7)字符串不加单引号,索引会失效。
(8)使用or连接时,索引失效。
- 创建表
drop table if exists students;
CREATE TABLE students (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT "主键id",
sname VARCHAR (24) COMMENT '学生姓名',
age INT COMMENT '年龄',
score INT COMMENT '分数',
time TIMESTAMP COMMENT '入学时间'
);
INSERT INTO students(sname,age,score,time) VALUES('小明',22,100,now());
INSERT INTO students(sname,age,score,time) VALUES('小红',23,80,now());
INSERT INTO students(sname,age,score,time) VALUES('小绿',24,80,now());
INSERT INTO students(sname,age,score,time) VALUES('黑',23,70,now());
- 创建复合索引
alter table students add index idx_sname_age_score(sname,age,score);

- 使用复合索引查询
key_len表示使用索引的字节大小,值越大表示索引使用越充分
explain select * from students where sname="小明" and age = 22 and score = 100;
explain select * from students where sname="小明" and age = 22;
explain select * from students where sname="小明";

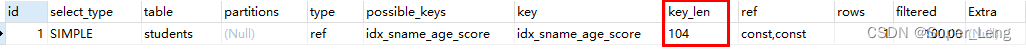
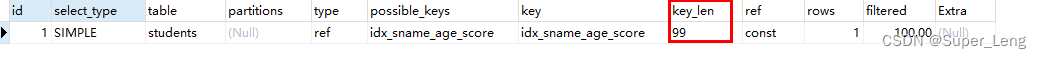
(1)不满足最左前缀法则,索引失效
explain select * from students where age = 20;

查询条件是sname、score,中间跳过了age, 所以score没有用到索引,只有sname用到了索引
跟上面单独使用sname查询时的ken_len一样,都是99
explain select * from students where sname="小明" and score = 80;

(2)在索引列上做任何计算、函数操作,索引失效
-- 不在索引列上做任何计算、函数操作,会导致索引失效而转向全表扫描。
explain select * from students where left(sname,2) = "小明";

(3)存储引擎使用索引中范围条件右边的列,索引失效
age是范围查找,所以age右边的score列索引失效,ken_len=104说明只有sname、age列索引生效
-- 存储引擎不能使用索引中范围条件右边的列。
explain select * from students where sname="小明" and age > 22 and score = 100;
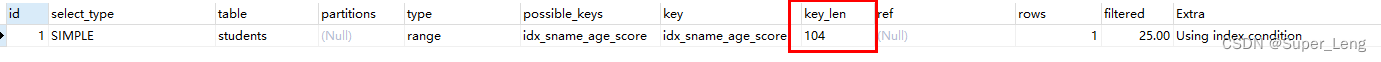
(4)Mysql使用不等于时,索引失效
-- Mysql在使用不等于时无法使用索引会导致全表扫描。
explain select * from students where sname != "小明";

(5)is null可以使用索引,但是is not null无法使用索引
explain select * from students where sname is null;

-- is null可以使用索引,但是is not null无法使用索引。
explain select * from students where sname is not null;

(6)like以通配符开头,索引失效
-- like以通配符开头会使索引失效导致全表扫描。
explain select * from students where sname like "%明";

(7)字符串不加单引号,索引失效
-- 字符串不加单引号索引会失效。
explain select * from students where sname = 123;

(8)使用or连接时,索引失效
-- 使用or连接时索引失效。
explain select * from students where sname="小明" or age = 22;

小结

建议:
1.对于单值索引,尽量选择针对当前查询字段过滤性更好的索引。
2.对于组合索引,当前where查询中过滤性更好的字段在索引字段顺序中位置越靠前越好。
3.对于组合索引,尽量选择能够包含在当前查询中where子句中更多字段的索引。
4.尽可能通过分析统计信息和调整query的写法来达到选择合适索引的目的。
2. 排序优化
1.尽量避免使用Using FileSort方式排序。
2.order by语句使用索引最左前列或使用where子句与order by子句条件组合满足索引最左前列。
3.where子句中如果出现索引范围查询会导致order by索引失效。
KEY a_b_c(a,b,c)
order by 能使用索引最左前缀
-- ORDER BY a
-- ORDER BY a,b
-- ORDER BY a,b,c
-- ORDER BY a DESC, b DESC, c DESC
如果WHERE使用索引的最左前缀定义为常量,则order by能使用索引
-- WHERE a = CONST ORDER BY b,c
-- WHERE a = CONST AND b = CONST ORDER BY c
-- WHERE a = CONST AND b > CONST ORDER BY b,c
不能使用索引进行排序
-- ORDER BY a ASC, b DESC, c DESC // 排序不一致
-- WHERE g = CONST ORDER BY b,c // 丢失a索引
-- WHERE a = CONST ORDER BY c // 丢失b索引
-- WHERE a = CONST ORDER BY a,d // d不是索引的一部分
-- WHERE a in(...) ORDER BY b,c //对于排序来说,多个相等条件也是范围查询
3. 单表优化
- 建表
-- 单表查询优化
CREATE TABLE IF NOT EXISTS article (
id INT(10) PRIMARY KEY AUTO_INCREMENT,
author_id INT(10) NOT NULL,
category_id INT(10) NOT NULL,
views INT(10) NOT NULL,
comments INT(10) NOT NULL,
title VARBINARY(255) NOT NULL,
content TEXT NOT NULL
);
INSERT INTO article(author_id, category_id, views, comments, title, content) VALUES
(1, 1, 1, 1, '1', '1'),
(2, 2, 2, 2, '2', '2'),
(1, 1, 3, 3, '3', '3');
#1.查询category_id为1的,且comments大于1的情况下,views最多的id和author_id的信息
explain select id,author_id
from article
where category_id=1 and comments>1 order by views desc limit 1;

#2.建立索引
alter table article add index idx_ccv(category_id,comments,views);
#3.再次测试,comments是范围查询,所以右边views列索引失效
explain select id,author_id
from article
where category_id=1 and comments>1 order by views desc limit 1;
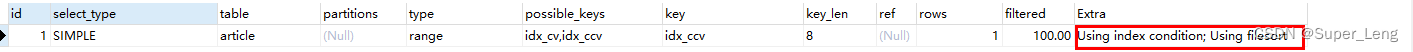
#4.重新创建索引
drop index idx_ccv on article;
// comments是范围查询,所以不建立comments复合索引
alter table article add index idx_cv(category_id,views);
#5.再次测试
explain select id,author_id
from article
where category_id=1 and comments>1 order by views desc limit 1;
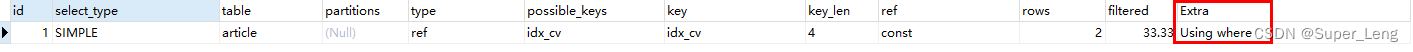
4. 关联查询优化
- 建表
CREATE TABLE IF NOT EXISTS class (
id INT(10) AUTO_INCREMENT,
card INT(10),
PRIMARY KEY (id)
);
CREATE TABLE IF NOT EXISTS book (
bookid INT(10) AUTO_INCREMENT,
card INT(10),
PRIMARY KEY (bookid)
);
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
内连接时,mysql会自动把小结果集的表选为驱动表,所以大表的字段最好加上索引。
左外连接时,左表会全表扫描,所以右边大表字段最好加上索引,右外连接同理。
我们最好保证被驱动表上的字段建立了索引。
#1.联表查询
explain select *
from class
left join book
on class.card = book.card;

#2.建立索引
alter table book add index idx_card(card);
#3.测试
explain select *
from class
left join book
on class.card = book.card;

5. 分组优化
参照排序优化。
- 建表
drop table if exists students;
CREATE TABLE students (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT "主键id",
sname VARCHAR (24) COMMENT '学生姓名',
age INT COMMENT '年龄',
score INT COMMENT '分数',
time TIMESTAMP COMMENT '入学时间'
);
INSERT INTO students(sname,age,score,time) VALUES('小明',22,100,now());
INSERT INTO students(sname,age,score,time) VALUES('小红',23,80,now());
INSERT INTO students(sname,age,score,time) VALUES('小绿',24,80,now());
INSERT INTO students(sname,age,score,time) VALUES('黑',23,70,now());
-- 分组优化
alter table students add index idx_sas(sname,age,score);
#没有WHERE条件,GROUP BY age不满足最左前缀,所以是Using temporary; Using filesort
explain select count(*),sname from students GROUP BY age;

explain select count(*),sname
from students
where sname="小明" and age > 22
GROUP BY score;

二、慢查询日志
1. 慢查询日志简介
MySQL的慢查询日志是MySQL提供的一种日志记录,用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。可以由它来查看哪些SQL超出了我们最大忍耐时间值。
2. 慢查询日志使用
默认情况下,MySQL数据库没有开启慢查询日志,需要手动设置参数。
查看是否开启:show variables like ‘%slow_query_log%’;
开启日志:set global slow_query_log = 1;
设置时间:set global long_query_time = 1;
查看时间: SHOW VARIABLES LIKE ‘long_query_time%’;
查看超时的sql记录日志:Mysql的数据文件夹下
C:\ProgramData\MySQL\MySQL Server 5.7\Data\设备名称-slow.log
注意:非调优场景下,一般不建议启动该参数,慢查询日志支持将日志记录写入文件,开启慢查询日志或多或少带来一定的性能影响。
-- 慢查询日志
-- 查看是否开启:show variables like '%slow_query_log%';
show variables like '%slow_query_log%';

-- 开启日志:
set global slow_query_log = 1;
-- 设置时间:
set global long_query_time = 1;
-- 查看时间: 需要重新开启一个会话才能查看刚设置的时间
SHOW VARIABLES LIKE 'long_query_time%';
- 需要重新开启一个会话才能查看刚设置的时间,cmd新建连接创建新会话
C:\Users\Administrator>mysql -uroot -p
Enter password: ****
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 7
Server version: 5.7.37-log MySQL Community Server (GPL)
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> SHOW VARIABLES LIKE 'long_query_time%';
+-----------------+----------+
| Variable_name | Value |
+-----------------+----------+
| long_query_time | 1.000000 |
+-----------------+----------+
1 row in set, 1 warning (0.00 sec)
mysql>
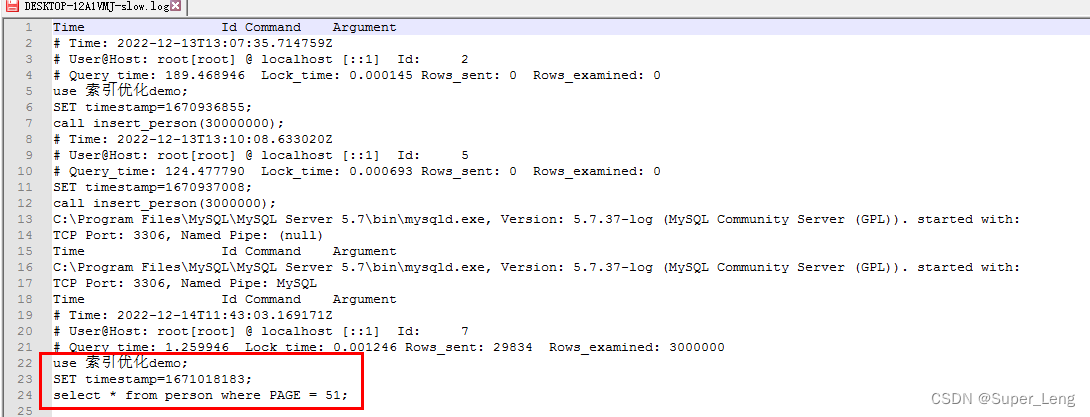
- 查询一个有300万数据的表,没有建PAGE索引,耗时超过1s
select * from person where PAGE = 51;

- 打开慢查询日志文件



![[附源码]Python计算机毕业设计SSM基于Web的摄影爱好者交流社区(程序+LW)](https://img-blog.csdnimg.cn/c240add9de2c4ba1905460ec0345a839.png)







![[附源码]Nodejs计算机毕业设计基于大数据的超市进销存预警系统Express(程序+LW)](https://img-blog.csdnimg.cn/414a8c0d44344cb1944e405c770a1fd6.png)