自己定制负载均衡常见策略
- 一、前言
- 随机(Random)策略的实现
- 轮询(Round Robin)策略的实现
- 哈希(Hash)策略
一、前言
大伙肯定知道,在分布式开发中,目前使用较多的注册中心有以下几个:
- Apache Zookeeper
- Netflix Eureka
- Alibaba Nacos
由于 Zookeeper 在面对高频次的服务注册和发现操作可能会一定的性能损耗等原因,搞得现在好多人都不用 Zookeeper 当做注册中心了。但它也提供了强一致性和高可靠性的特性,也没有被淘汰。
Zookeeper 本身并没有提供现成的服务发现功能,它更专注于分布式协调的能力。所以在使用 Zookeeper 作为注册中心时,需要自己在客户端实现服务的发现和负载均衡的逻辑。当然也可以去整合相关组件简化开发过程。
常见的负载均衡有以下三种:
- 随机(random)策略
- 轮询(round robin)策略
- 哈希(hash)策略
下面的话以寻注册中心的服务地址的需求来去对三种策略进行实现。
// 这是对应的策略接口
public interface RouteHandle {
// 参数1:服务地址集合
// 参数2:对应的key,我这里使用的是userId,这个结合自身项目需求
String routeServer(List<String> values, String key);
}
随机(Random)策略的实现
/**
* 随机的负载均衡
*/
public class RandomHandle implements RouteHandle {
@Override
public String routeServer(List<String> values, String key) {
int size = values.size();
if (size == 0) {
throw new ApplicationException(UserErrorCode.SERVER_NOT_AVAILABLE);
}
// 去获取一个小于size的索引值
// 你可以简单理解:随机整型数&size
int index = ThreadLocalRandom.current().nextInt(size);
return values.get(index);
}
}
轮询(Round Robin)策略的实现
轮询策略即将请求次数和总的服务树取模,然后得出索引去得到服务信息。
/**
* 轮询策略
*/
public class LoopHandle implements RouteHandle {
private AtomicLong index = new AtomicLong();
@Override
public String routeServer(List<String> values, String key) {
int size = values.size();
if (size == 0) {
throw new ApplicationException(UserErrorCode.SERVER_NOT_AVAILABLE);
}
Long l = index.incrementAndGet() % size;
if (l < 0) {
index.set(0L);
l = 0L;
}
return values.get(l.intValue());
}
}
哈希(Hash)策略
这里指的 Hash 策略一般指的是一次性 Hash 算法实现的策略。传统的 hash 在添加或删除一个节点的时候,会出现缓存失效,失效缓存比例为:m/(m+1);传统hash一般是将资源的 hashcode % table.size()(服务数)得到节点索引然后将访问服务,这样的话当增加一个节点的时候,除了hashcode为1的时候其对应的服务不变其他都缓存失效(0就不算它了,近似的一个值吧)也就是近于缓存失效比例为 m/m+1。
传统的hash造成的缓存失效很容易就把服务给搞蹦了,因为有大量资源访问不到的请求嘛。
然后就有了一致性hash算法,它将映射集合规定为0~2^32-1的范围的环,首尾相连。
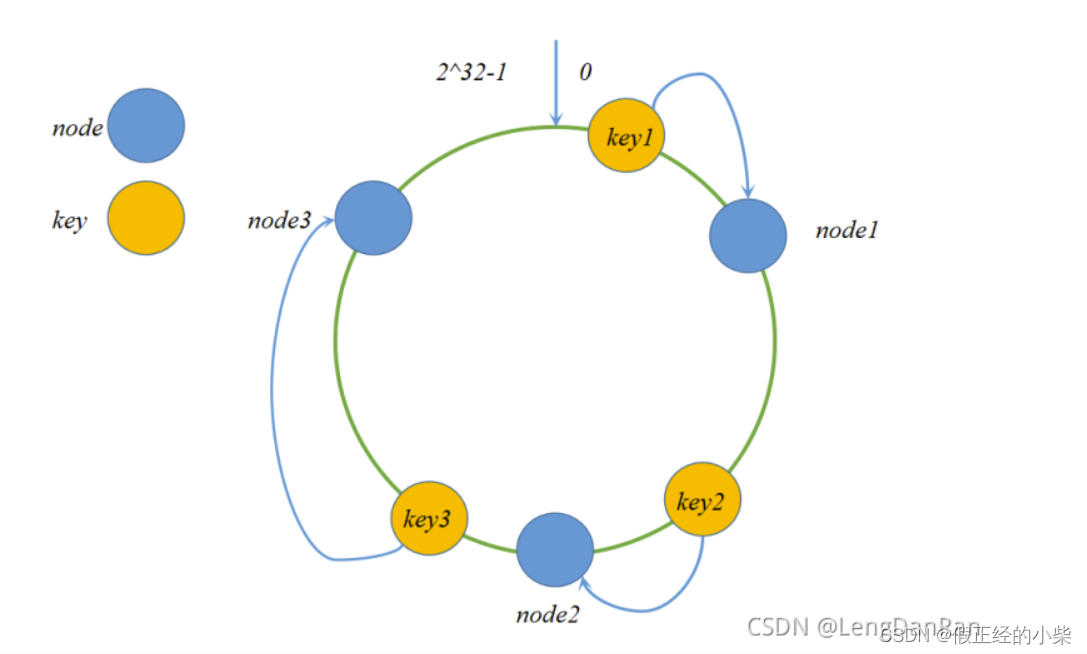 将节点放到(注册到)环中,然后根据资源的hash去顺时针寻其节点服务。
将节点放到(注册到)环中,然后根据资源的hash去顺时针寻其节点服务。
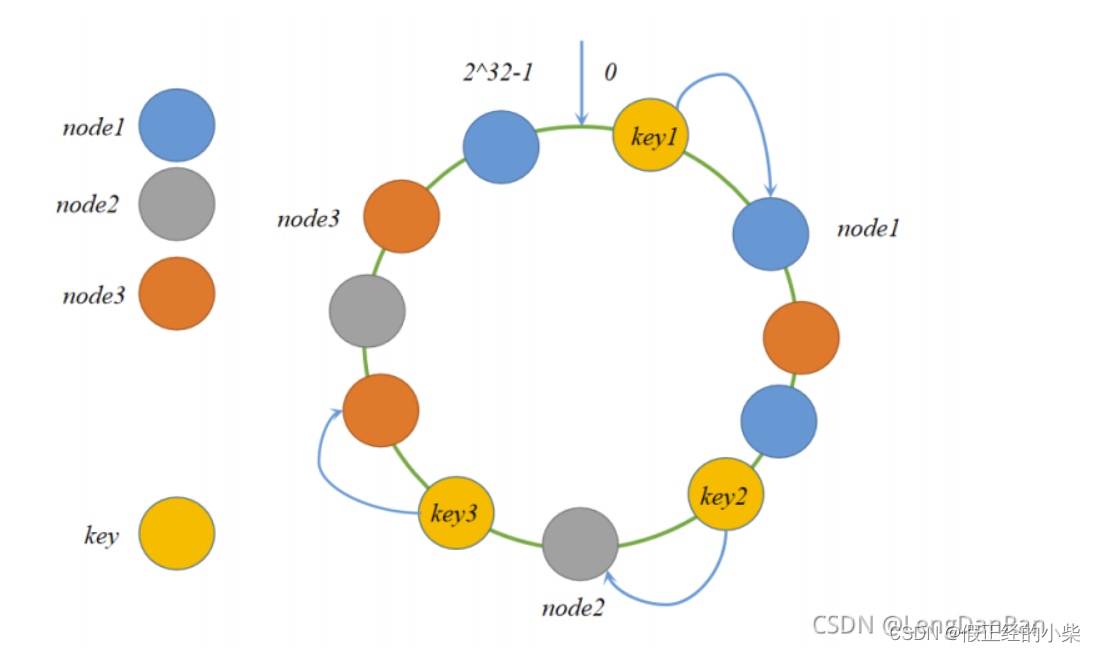
注意:当注册节点的时候,也有可能会出现hash偏斜问题,即节点都被放到了环的一边,使得资源大部分都使用的是俩边的节点,这个时候我们需要将每个服务节点设置一些虚拟节点注册到环上,这样的话每个服务节点近似均衡的分配给资源了。
 这里参考的文献:
这里参考的文献:
一致性hash算法讲解——Java实现
下面对 hash 策略进行实现,下面是使用 TreeMap 对一次性hash算法进行实现的,这是因为它底层是使用 红黑树 进行实现的,有序,且添加起来比起平衡二叉树这样的不用老左旋右旋。主要是因为有序,对闭环的顺时针有序选节点是一致的,所以用 TreeMap 实现它比较多。当然也可以自身定义策略去实现。
/**
* 使用 TreeMap 实现一致性hash
*/
public class TreeMapConsistentHash extends AbstractConsistentHash {
private TreeMap<Long, String> treeMap = new TreeMap<>();
private static final int NODE_SIZE = 2; // 每个节点再注册虚拟节点的数量
@Override
protected void add(long key, String value) {
for (int i = 0; i < NODE_SIZE; i++) {
treeMap.put(super.hash("node" + key + i), value);
}
treeMap.put(key, value);
}
@Override
protected String getFirstNodeValue(String value) {
Long hash = super.hash(value);
SortedMap<Long, String> last = treeMap.tailMap(hash);
if(!last.isEmpty()){
return last.get(last.firstKey());
}
if(treeMap.size() == 0){
throw new ApplicationException(UserErrorCode.SERVER_NOT_AVAILABLE);
}
return treeMap.firstEntry().getValue();
}
@Override
protected void processBefore() {
treeMap.clear(); // 清空是因为,可能出现添加或删除服务的现象
}
}
重点就是 add 和 getFirstNodeValue 方法,至于父类其他方法的实现不影响理解这个策略。