C++函数和 STL容器
- C++排序sort
- C++翻转字符串reverse
- C++截取字符串strsub
- 哈希表的使用
- 定义
- 查询哈希表里是否有该key
- 在哈希表里存放键值
- 链式哈希
- 哈希集合
- 定义一个哈希集合
- 查找一个字符是否在set里面
- 删除和添加
- 优先队列 最大堆
- 优先队列的大顶堆定义方式
- 插入
- 存储数组对
- 定义
- 插入
- 双端队列
- 定义
- 头删和尾删 尾插
常用算法
两数之和
vector twoSum(vector& nums, int target)
返回值类型:vector 存放整型的容器 {i,j}
C++排序sort
可以参考这篇博客:排序函数的使用
可以按照一定的规则排序,需要定义一个函数,应用排序解决问题的例子:牛客上的合并区间
为什么函数用static修饰:用static 修饰普通函数
int main(){
int num[10] = {6,5,9,1,2,8,7,3,4,0};
sort(num,num+10,greater<int>());
for(int i=0;i<10;i++){
cout<<num[i]<<" ";
}//输出结果:9 8 7 6 5 4 3 2 1 0
return 0;
}
C++翻转字符串reverse
可以参考这篇牛课题:字符串变形
tmp=“abc deg geg” tmp是一个字符串
i,j分别是下标
参数里面都是地址
reverse(tmp.begin()+i,tmp.begin()+j);
C++截取字符串strsub
s.substr(0, 3); 该strsub是对象的成员函数,s.substr(0, 3); -> substr(&s,0,3) 所以两个参数,第一个就是需要截取字符串在s的起始下标,第二个参数就是截取的长度,越界按最长处理
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s = "abcdefg";
string a = s.substr(0, 3);
string b = s.substr(2,2);
string c = s.substr(3, 3);
cout << a << endl;
cout << b << endl;
cout << c << endl;
return 0;
}
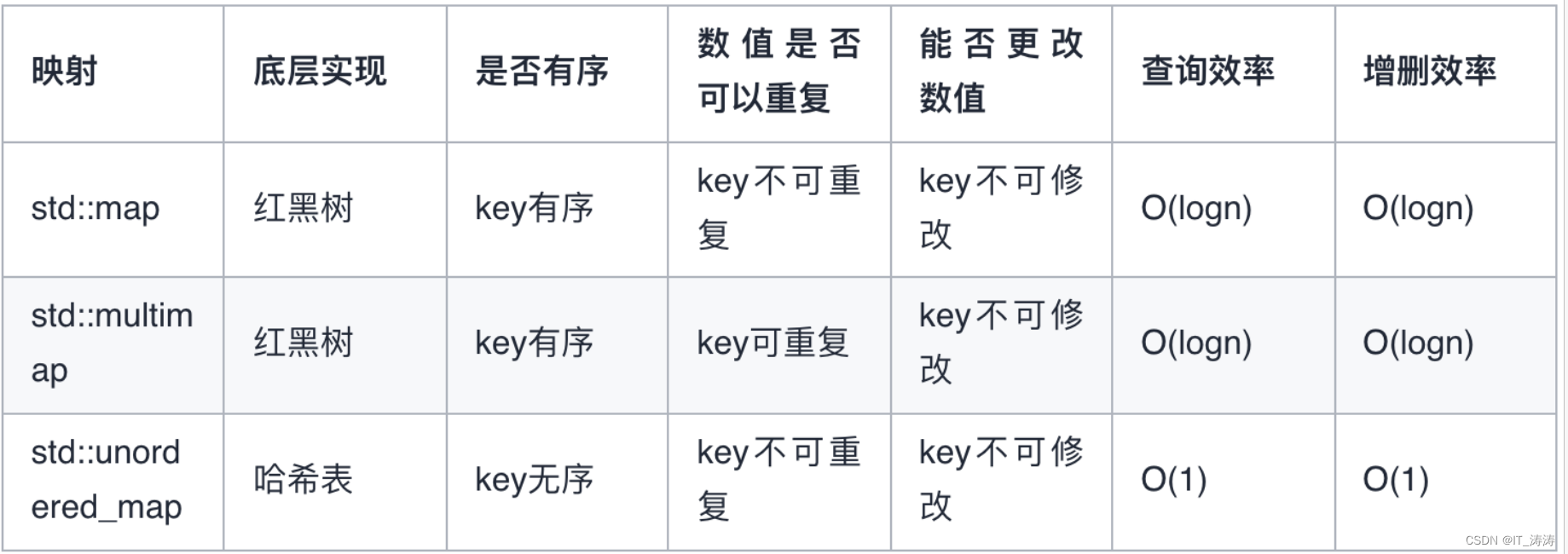
哈希表的使用
哈希表是一种根据关键码(key)直接访问值(value)的一种数据结构。而这种直接访问意味着只要知道key就能 O(1)时间内得到value,因此哈希表常用来统计频率、快速检验某个元素是否出现过等。
定义
定义一个哈希表
unordered_map<int,int>hashtable;
查询哈希表里是否有该key
auto it=hashtable.find(target-nums[i]); //it是key
auto是自动的数据类型,根据后面实际情况确定
it!=hashtable.end() //如果找到了,不等于end()
it==hashtable.end() //如果没有该key,说明到了end(),为空
hashtable.count(s[j])!=0 //哈希表里面有s[j]
hashtable.count(s[j])==0 //哈希表里面没有s[j]
哈希表可以记录一个字符串里各个字符出现的频数
unordered_map<char,int>freq;
for(int i=0;i<s.size();i++){
freq[s[i]]++;
}
it 类似一个结构体,it->fisrt 访问的就是key it->second 访问的就是value
在哈希表里存放键值
hashtable[nums[i]]=i; //nums[i]是key,i是value 一个key 对应一个value
链式哈希
哈希表还可以这样用
unordered_map<string,vector>mp;
以字符串为关键词,对应了一个vector数组,类似一个顺序表
例如把每个单词出现的下标存入哈希表,类似链式哈希
words = [“I”,“am”,“a”,“student”,“from”,“a”,“university”,“in”,“a”,“city”]
unordered_map<string,vector<int>>mp;
void buildmp(vector<string>& words){
for(int i=0;i<words.size();i++){
mp[words[i]].push_back(i);
}
}
哈希集合
定义一个哈希集合
unordered_set<char>set;
//set里面是么有重复元素的
查找一个字符是否在set里面
set.find(s[i])!=set.end() //说明在set找到了s[i]
set.find(s[i])==set.end() //说明set没有s[i]
删除和添加
删除和添加一个元素到集合set里面,插入的前提是set里面无该元素
set.insert(s[i])
set.erase(s[i])
vector& words
如果字符串在vector中,可以直接比较,比如:if(words[2]==words[3])
优先队列 最大堆
优先队列的大顶堆定义方式
有大顶堆和小顶堆
priority_queue<int> pq; //默认情况下使用为大顶堆
priority_queue<int,vector<int>,less<int>> pq; // 定义为大顶堆
// 优先队列的小顶堆定义方式
priority_queue<int,vector<int>,greater<int>> pq; // 定义为小顶堆
插入
元素是一个的话是
q.push(a)
存储数组对
定义
priority_queue<pair<int,int>>q;
插入
此时由于优先队列的元素是pair 插入元素的话,得用
q.emplace(a,b);
队列里面的元素可以是pair里面是char 和 int
queue<pair<char, int>> q;
双端队列
定义
deque<int>qu;
定义一个双端队列,该队列可以头删和尾删
头删和尾删 尾插
qu.pop_front(); qu.pop_back();
qu.push_back(i);//从尾巴入队列