哈喽,Python爬虫小伙伴们!今天我们来聊聊如何从入门到精通地使用和优化Python隧道代理,让我们的爬虫程序更加稳定、高效!今天我们将对使用和优化进行一个简单的梳理,并且会提供相应的代码示例。
1. 什么是隧道代理?
首先,让我们来了解一下什么是隧道代理。隧道代理是一种通过中间服务器转发网络请求的方式,隐藏真实的客户端IP地址,提高爬虫的匿名性和安全性。
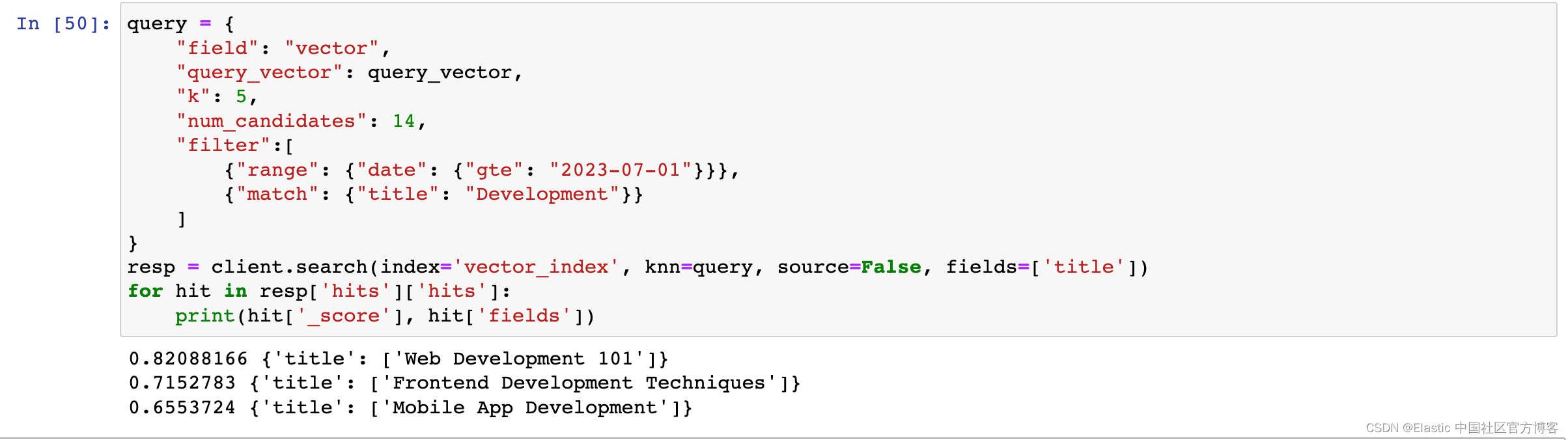
解决方案:使用Python的第三方库,如`requests`或`aiohttp`,结合隧道代理服务商提供的API,实现隧道代理的使用。
示例代码:
```python
import requests
proxy_url = "http://proxy.example.com:port"
target_url = "http://example.com"
proxies = {
"http": proxy_url,
"https": proxy_url
}
response = requests.get(target_url, proxies=proxies)
print(response.text)
```
2. 隧道代理的优化技巧
除了基本的使用,我们还可以通过一些优化技巧,提升隧道代理在爬虫中的性能和稳定性。
a. 代理池管理
隧道代理的可用性是一个重要的问题。为了确保爬虫的持续稳定运行,我们可以使用代理池管理多个可用的代理服务器,并在请求时随机选择一个代理。
解决方案:使用第三方库,如`proxy-pool`或自行开发代理池管理模块,定期检测代理服务器的可用性,并动态维护一个可用的代理池。
示例代码:
```python
import random
proxy_pool = [
"http://proxy1.example.com:port",
"http://proxy2.example.com:port",
"http://proxy3.example.com:port"
]
proxy_url = random.choice(proxy_pool)
target_url = "http://example.com"
proxies = {
"http": proxy_url,
"https": proxy_url
}
response = requests.get(target_url, proxies=proxies)
print(response.text)
```
b. 异常处理与重试机制
在使用隧道代理时,可能会遇到连接超时、代理失效等异常情况。为了增强程序的健壮性,我们可以添加异常处理和重试机制,以应对这些问题。
解决方案:使用`try-except`语句捕获代理请求过程中的异常,并在异常发生时进行重试,或切换到其他可用的代理。
示例代码:
```python
import requests
from requests.exceptions import RequestException
proxy_url = "http://proxy.example.com:port"
target_url = "http://example.com"
proxies = {
"http": proxy_url,
"https": proxy_url
}
max_retries = 3
retry_count = 0
while retry_count < max_retries:
try:
response = requests.get(target_url, proxies=proxies)
print(response.text)
break
except RequestException:
retry_count += 1
print(f"Request failed. Retrying ({retry_count}/{max_retries})...")
```
通过代理池管理和异常处理与重试机制,我们可以提高隧道代理在爬虫中的可用性和稳定性,确保爬虫程序的顺利运行。
希望这些解决方案对你有所帮助,如果你有任何问题,或是有更多更好的见解,欢迎评论区留言讨论,让我们一起让爬虫变得更简单!