使用值为 nil 的 slice、map 会发生什么?
允许对值为 nil 的 slice 添加元素,但是对值为 nil 的 map 添加元素时会造成运行时 panic。
// map错误示例
func main() {
var m map[string]int
m["one"] = 1 // error: panic: assignment to entry in nil map
// m := make(map[string]int) // map的正确声明, 分配了实际的内存
}
// slice正确示例
func main() {
var s []int
s = append(s, 1)
}
访问 map 中的 key,需要注意什么?
当访问 map 中不存在的 key 时,Go 会返回元素对应数据类型的零值,比如 nil、“” 、false 和 0,即取值操作总是有值返回的,故不能通过取出来的值来判断 key 是否存在。
检查 key 是否存在可以用 map 直接访问,检查返回的第二个参数即可。
// 错误的key检测方式
func main() {
x := map[string]string{"one": "2", "two": "", "three": "3"}
if v := x["two"]; v == "" {
fmt.Println("key two is no entry") // 不管键two存不存在都会返回的空字符串
}
}
// 正确示例
func main() {
x := map[string]string{"one": "2", "two": "", "three": "3"}
if _, ok := x["two"]; !ok {
fmt.Println("key two is no entry")
}
}
string 类型的值可以修改吗?
不能,尝试使用索引遍历字符串,来更新字符串中的个别字符时,是不允许的。
string 类型的值是只读的二进制字节切片,如果真要修改字符串中的字符,先将 string 转为 []byte 修改后,再转为 string 即可。
// 修改字符串的错误示例
func main() {
x := "text"
x[0] = "T" // error: cannot assign to x[0]
fmt.Println(x)
}
// 修改示例
func main() {
x := "text"
xBytes := []byte(x)
xBytes[0] = 'T' // 注意此时的T是rune类型
x = string(xBytes)
fmt.Println(x) // Text
}
switch 中如何强制执行下一个 case 代码块?
switch 语句中的 case 代码块会默认带上 break,但可以使用 fallthrough 来强制执行下一个 case 代码块。
func main() {
isSpace := func(char byte) bool {
switch char {
case ' ': // 空格符会直接break, 返回 false
// fallthrough // 返回true
case '\t':
return true
}
return false
}
fmt.Println(isSpace('\t')) // true
fmt.Println(isSpace(' ')) // false
}
切片和数组的区别?
- 数组是具有固定长度,且拥有零个或者多个,相同数据类型元素的序列
- 数组的长度是数组类型的一部分,所以 [3]int 和 [4]int 是两种不同的数组类型
- 数组需要指定大小,不指定也会根据初始化的自动推算出大小,在初始化后长度是固定的,无法修改其长度
- 数组是值传递,数组是内置类型,是一组同类型数据的集合,它是值类型,通过从 0 开始的下标索引访问元素值
var array [10]int
var array =[5]int{1,2,3,4,5}
- 切片表示一个拥有相同类型元素的可变长度的序列
- 切片是一种轻量级的数据结构,它有三个属性:指针、长度和容量
- 切片不需要指定大小
- 切片是地址传递
- 切片可以通过数组来初始化,也可以通过内置函数 make() 来初始化 ,初始化时 len=cap,在追加元素时如果容量 cap 不足,将按 len 的 2 倍扩容
var slice []type = make([]type, len)
new 和 make 的区别?
- new 的作用是初始化一个指向类型的指针(*T)
- new 函数是内建函数,函数定义:func new(Type) *Type
- 使用 new 函数来分配空间
- 传递给 new 函数的是一个类型,不是一个值,返回值是指向这个新分配的零值的指针
- make 的作用是为 slice、map 或 chan 初始化,并返回引用 (T)
- make 函数是内建函数,函数定义:func make(Type, size IntegerType) Type,第一个参数是一个类型,第二个参数是长度,返回值是一个类型
- make(T, args) 函数的目的与 new(T) 不同,它仅仅用于创建 Slice、Map 和 Channel,并且返回类型是 T(不是 *T)的一个初始化的(不是零值)的实例
go 语言中的 for 循环
for 循环支持 continue 和 break 来控制循环,但是它提供了一个更高级的 break,可以选择中断哪一个循环。for 循环不支持以逗号为间隔的多个赋值语句,必须使用平行赋值的方式来初始化多个变量。
outerloop:
for i := 0; i < 3; i++ {
for j := 0; j < 3; j++ {
if j == 2 {
break outerloop
}
fmt.Println(i, j)
}
}
// 在上述示例中, 我们使用了break outerloop来指定要中断的是外层循环。当内部循环中的j的值等于2时, 执行 break outerloop, 这样整个循环就会被完全中断, 不再继续执行。
for i, j := 0, 0; i < 3; i, j = i+1, j+1 {
fmt.Println(i, j)
}
// 在这个示例中, 我们使用了平行赋值的方式来初始化i和j两个变量。每次循环迭代, i和j分别会自增1, 并通过平行赋值将新的值重新关联给它们。
go 语言中的引用类型包含哪些?
数组切片(slice)、字典(map)、通道(channel)、接口(interface)。
go 语言的 main 函数
- main 函数不能带参数
- main 函数不能定义返回值
- main 函数所在的包必须为 main 包
- main 函数中可以使用 flag 包来获取和解析命令行参数
go 语言中的静态类型声明
在 Go 语言中,静态类型声明是指在声明变量、函数或方法时显式指定其类型。静态类型声明是 Go 语言的一个重要特性,它使得变量在编译阶段就能够被确定其类型,并且在编译过程中进行静态类型检查。
静态类型声明的语法格式通常是在变量名或函数名后面加上类型标识符,用于明确指定变量的类型。
var count int // 声明一个名为count的整数类型变量
var message string // 声明一个名为message的字符串类型变量
func add(a int, b int) int { // 声明一个名为add的函数, 接收两个整数类型参数, 返回一个整数类型结果
return a + b
}
在上述示例中,使用了 int 和 string 来显式声明变量 count 和 message 的类型,以及函数 add 的参数类型和返回值类型。
静态类型声明的优势在于可以提供强类型检查。编译器可以在编译阶段对类型信息进行检查,包括类型的兼容性、正确的方法调用等,从而减少在运行时出现类型错误的可能性。这有助于提高代码的可靠性和安全性。
此外,静态类型声明还使代码更易于理解和维护。通过明确指定变量的类型,可以对变量的用途有更好的描述,减少了对类型的猜测和理解上的困惑。
总而言之,Go 语言中的静态类型声明是一种为变量、函数和方法显式指定类型的机制,它提供了静态类型检查和更好的代码可读性、可维护性。
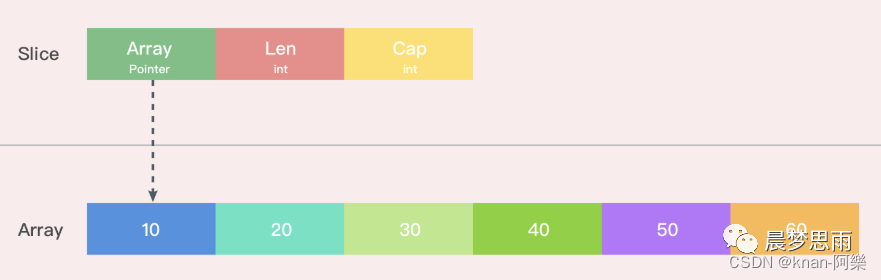
Slice 的底层实现
切片是基于数组实现的,它的底层是数组,它自己本身非常小,可以理解为是对底层数组的抽象。因为基于数组实现,所以它的底层的内存是连续分配的,效率非常高,还可以通过索引获得数据,可以迭代以及垃圾回收优化。
切片本身并不是动态数组或者数组指针。它内部实现的数据结构通过指针引用底层数组,设定相关属性,将数据读写操作限定在指定的区域内。切片本身是一个只读对象,其工作机制类似于数组指针的一种封装。
切片对象非常小,是因为它是只有 3 个字段的数据结构,这 3 个字段就是 Go 语言操作底层数组的元数据。
- 指向底层数组的指针
- 切片的长度
- 切片的容量
Slice 的扩容机制
- 判断新申请的容量是否大于旧容量的两倍。如果是,则最终容量就是新申请的容量
- 如果新申请的容量不满足上一步的条件,判断旧切片长度是否小于 1024。如果是,则最终容量就是旧容量的两倍
- 如果旧切片长度大于等于 1024,则进入循环计算最终容量。从旧容量开始,每次增加原来容量的 1/4,直到最终容量大于等于新申请的容量
- 如果计算出的最终容量超出了限制(即溢出),则最终容量就是新申请的容量
- 情况一:当原数组还有容量可以扩容时,扩容后的数组仍然指向原来的数组。这就意味着对一个切片的操作可能会影响到多个指针,因为它们指向的是同一个地址的切片
- 情况二:如果原来数组的容量已经达到最大值,再次扩容会导致 Go 语言默认先开辟一片新的内存区域,并将原来的值复制过去,然后执行 append() 操作。这种情况不会对原数组造成任何影响
要复制一个 Slice,最好使用 Copy 函数。
Map底层实现
Go 中 map 的底层实现是一个散列表,因此实现 map 的过程实际上就是实现散列表的过程。
在这个散列表中,主要出现的结构体有两个,一个叫 hmap(a header for a go map),一个叫 bmap(a bucket for a Go map,通常称为 bucket)。

我们只需关注标红的字段:buckets 数组。Go 的 map 中用于存储的结构是 bucket 数组(即 bmap)。

相比于 hmap,bucket 的结构显得简单一些,标橙的字段依然是核心,我们使用的 map 中的 key 和 value 就存储在这里。
“高位哈希值”数组记录的是当前 bucket 中 key 相关的“索引”,还有一个字段是一个指向扩容后的 bucket 的指针,使得 bucket 会形成一个链表结构。
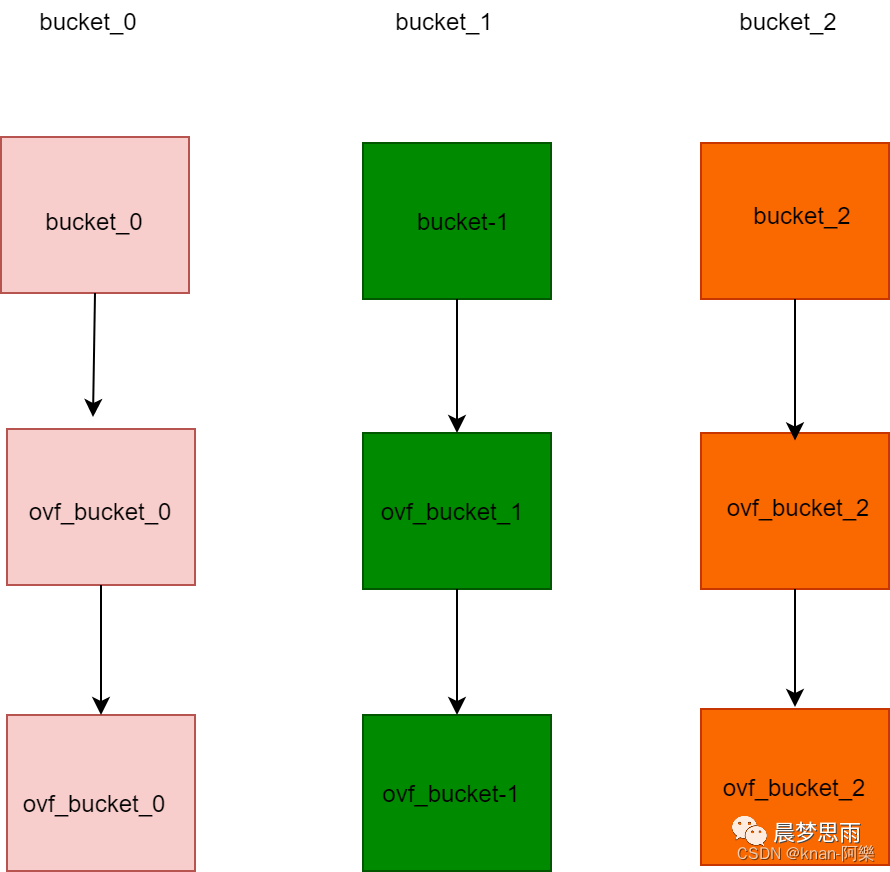
Go 把求得的哈希值按照用途一分为二:高位和低位。低位用于寻找当前 key 属于 hmap 中的哪个 bucket,而高位用于寻找 bucket 中的哪个 key。
注意:map 中的 key/value 值都是存到同一个数组中的。这样做的好处是,在 key 和 value 的长度不同时,可以消除 padding 带来的空间浪费。

map 的扩容:当 Go 的 map 长度增长到大于加载因子所需的 map 长度时,Go 语言就会产生一个新的 bucket 数组,然后把旧的 bucket 数组移到一个属性字段 oldbucket 中。
注意:并不是立刻把旧的数组中的元素转移到新的 bucket 中,而是只有当访问到具体的某个 bucket 的时候,才会把 bucket 中的数据转移到新的 bucket 中。
在 range 迭代 slice 时,如何修改值?
在 range 迭代中,得到的值其实是元素的一份值拷贝,更新拷贝并不会更改原来的元素,即拷贝的地址并不是原有元素的地址。
func main() {
data := []int{1, 2, 3}
for _, v := range data {
v *= 10 // data中原有元素是不会被修改的
}
fmt.Println("data: ", data) // data: [1 2 3]
}
如果要修改原有元素的值,应该使用索引直接访问。
func main() {
data := []int{1, 2, 3}
for i, v := range data {
data[i] = v * 10
}
fmt.Println("data: ", data) // data: [10 20 30]
}
如果你的集合保存的是指向值的指针,需稍作修改。依旧需要使用索引访问元素,不过可以使用 range 出来的元素直接更新原有值。
func main() {
data := []*struct{ num int }{{1}, {2}, {3}}
for _, v := range data {
v.num *= 10 // 直接使用指针更新
}
fmt.Println(data[0], data[1], data[2]) // &{10} &{20} &{30}
}