多家,且独家来自美国的信源同时向“亲爱的数据”表示,
提示工程(Prompt Engineering)在美国大模型领域备受重视。
读者都要聊,
那就干活。
(一)开源真香
现阶段,AI开源极客大展身手,新的软件栈正在形成之中。
开源很香,但是开源是零收费,但不是零成本。
甲方着急用大模型,甲方管理层内心OS:
谁耽误我用大模型,我和谁急。
打工人,打工魂,集体上线。
要不玩一把“LangChain+向量数据库+开源大模型=线上模型服务”?
这几步看上去一点也不“卡脖子”,实则未必,
做完就可以“宣布”这是知识产权了。
讲两个小故事:
第一个小故事
某基金机构领导看到了ChatGPT的威力,要求使用,开发团队安排一下:
第一件事,收集数据;
第二件事,找各种基础开源模型;
第三件事,构建测试大模型的工程代码;
第四件事,各种都测试一遍;
第五件事,选出基础模型;
第六件事,封装成一个模型服务。
第七件事,几乎结束,但仍需业务团队顺利“接棒”。
尽管麻烦事儿有点多,老板依然会说:
市面上,AI开源工具这么多,做一个大模型应用应该不难,内部团队搞定,实在不行再招几个人。
“感谢老板栽培,您说得对,市面上开源工具确实很多,有的还很香。”
包括:
1. 游泳健身和LangChain了解一下:
LangChain用于调试、测试、评估和监控大语言模型应用的开源平台。
LangChain原生支持3个向量数据库,都被封装成统一接口,屏蔽了各自实现的细节。
既然封装好了,用的时候直接安装,动作很简单,就一行代码:pip install chromadb。
2.走过路过,不要错过开源向量数据库
用Chroma,还可以用脸书公司开源的FAiSS(全称为Facebook AI Similarity Search),但后者是个索引库。
3.家人们,开源底层算法大模型挑选一下
说到底基础大模型不就是个供应商嘛。
那么,用开源模型羊驼(Llama2),还是用商业GPT4?
然而,想走通“大模型服务”这条路,没想象的这么简单。
往往模型服务还没开始,人已经“累死”半路了。
躬行实践,底层劳动人民才会有真实的生产体验,老板不理解。
第二个故事:
理想中:用某一个科技公司已有的线上模型服务。
全剧终。
理想还是要有的,万一实现了呢。
(二)Lepton.AI
以Lepton.AI 为例,我们近距离观察一下:
Lepton.AI平台上的一个功能叫TUNA(吞拿鱼)。
名字的由来是据说创始团队成员爱吃吞拿鱼,
这让我想起了Snowflake公司几个创始人都喜欢滑雪。
“亲爱的数据”创始人爱吃西瓜。
用户在Lepton.AI 平台上,上传公司的数据集(最小需200条对话以上,截止目前最大是4.5M)。
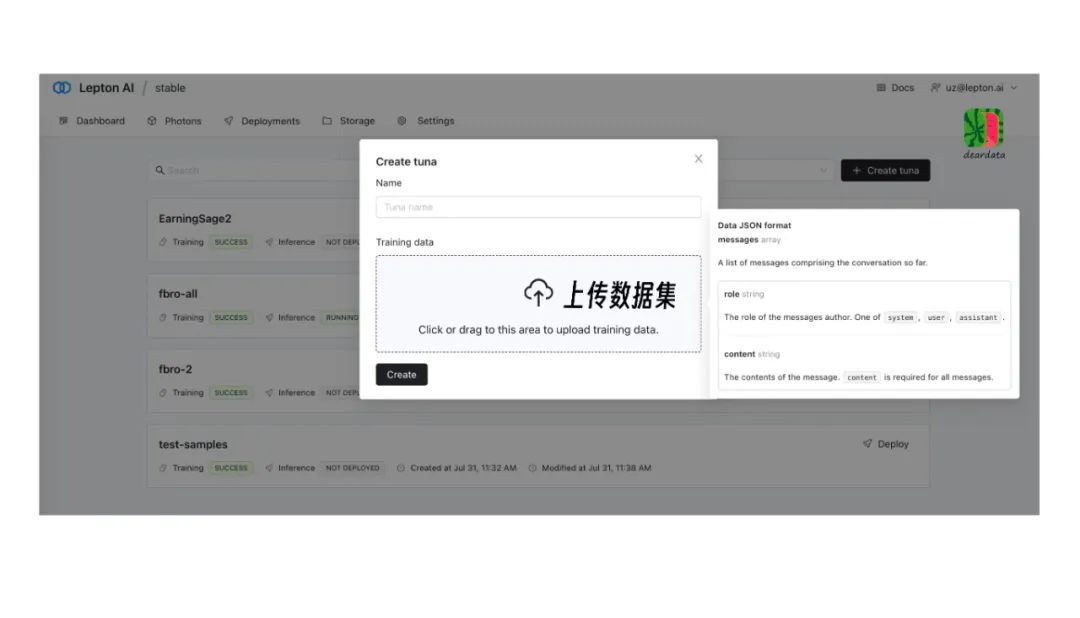
先数据增强,再微调。
当然,客户不用管这些,他们眼中的步骤就是:
上传小数据集,你提出问题,产品回答。
TUNA(吞拿鱼)既包括增强数据功能,也包括大模型微调,这些都是技术活。
如何增强数据?
这个技术点,可以说是每个团队的看家本领,外人很难得知。
大致上,
好比原来只有1个G的数据,生成10个G的数据,再去掉8个G的数据垃圾。剩下的虽不多,好歹有2个G的数据能用,怎么说也比一开始翻了2倍的数据量。
上传数据集后,先增强数据,再微调大模型。
用户可直接获得模型服务的结果。
最终完成模型服务的最后一公里。
服务可有两种方式:
要么一问一答。
要么抽成结构化数据。
然后,就没有然后了。
虽然是一个应用,但是体现出其背后工具链的价值,数据增强加上微调模型,灵便顺手,好用易用。
这个方案即使用开源软件,每一个步骤精细实现,再有机结合,直到产品化,难度还不小。
时间和人力都是成本。
当然,直接调用模型服务的产品最为方便。
AI落地需要灵便产品。
AI落地和商业模式的成功,不是单纯靠技术。
看上去Lepton.AI这家公司想让AI模型服务上线更快,让AI应用落地更快。
用咨询公司腔调表述这件事就是:
数据与大语言模型间的协同作用,增强了AI应用服务的整体性能,同时为更多创新和发现开辟出新可能性。
(三)聊聊细节
评价一个AI应用,用效果说话。
Lepton.AI所选的是财报会议场景,使用者可以是:摩根大通、高盛和摩根士丹利这帮投资人和专业投资分析师。
我们分析一下Lepton.AI的生成结果。
最开始,Lepton.AI的设置如图蓝色底色所示:
“使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答案。”
用技术术语表达,这些是Instruction。
与大语言模型会话,定义前置规则非常重要,包括角色,场景等等。
因为相同的内容,对不同的人,不同的场景可能意思不同。
一个会话机器人不可能一上来就知道你是谁,是什么场景下的问话,是想要创意性的回答还是严谨的回答等等。
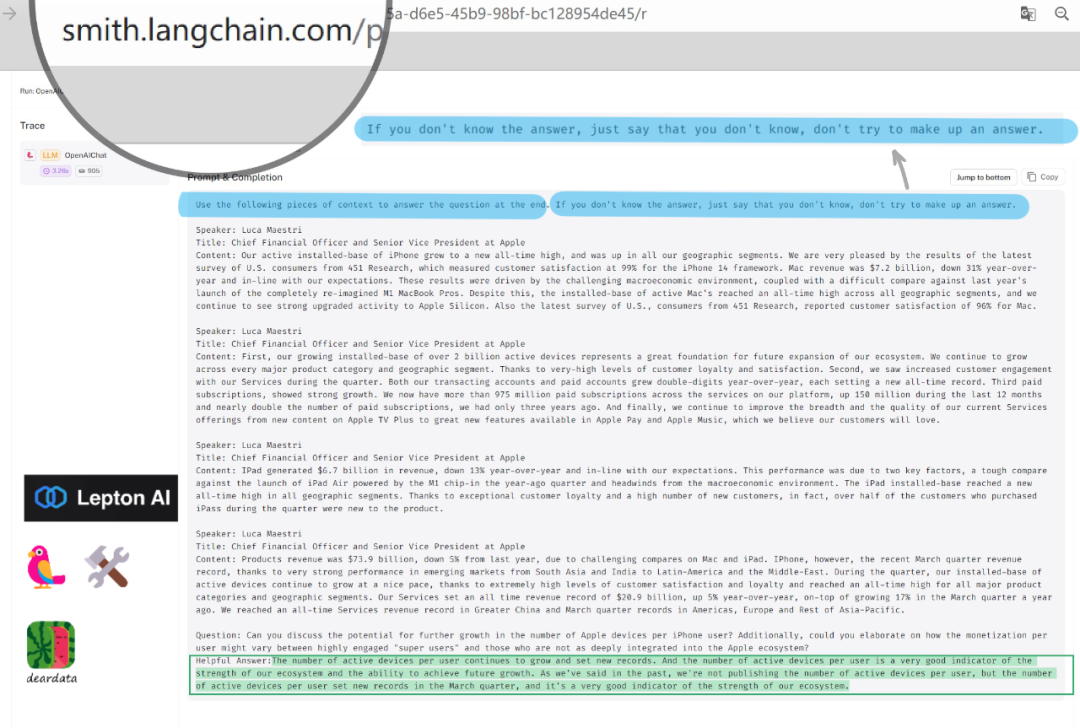
此后,就是大模型的推理过程了,分为三部分:
第一个部分是输入,
第二部分叫处理,
第三个部分是输出。
既然是推理,在第一个部分输入,相当于给微调后的大模型“喂”了新数据。
或者说通过提示(Prompt)引导大模型。
这里用到了向量数据库。
我们知道,向量数据库可以通过向量相似度搜索快速检索相关数据,与传统的基于索引的数据库相比,查询速度快。
结构化的数据从向量数据库提取出来后,喂给大模型,大模型生成了提问问题的答案。
这个输入(Input),是这里面灰色底色,且没有高亮的这些字。
与传统预训练微调的方法不同,大模型推理中所用到的输入提示(Prompt),是从向量数据库里检索而来。
而LangChain在大语言模型输入阶段,通过检索向量数据库获取最相关的信息,将信息整理组合成为提示(Prompt),输入大模型,并得到产出结果。
这里还会用到召回增强型的生成技术。
英文名,Retrieval Auqmented Generation,是基于向量数据库,在上下文中去做内容摘要。
是一种增加大模型推理能力的技术。
产品效果如图:
能观察得到,产品界面能看到除答案之外的更多内容——结构化数据。
谭老师推测,Lepton.AI团队“特意”让大家看到从向量数据库里检索而来的“更多内容”。
用向量数据检索到了什么,本来是幕后工作,用户可以不知道。
“特意”意味着将输入内容也一起展示给大家看。
展示了什么内容?
给模型输入的内容都一样:用了同样的向量数据库,用了同样的数据。
那么更容易对比观察出:谁的效果更好,更“哇塞”?
第二部分,处理(Processing)。
本质上,这部分是对用户不可见的,是幕后工作。
无论是数学方法还是其他。
第三部分,大模型的输出就是给出的答案。
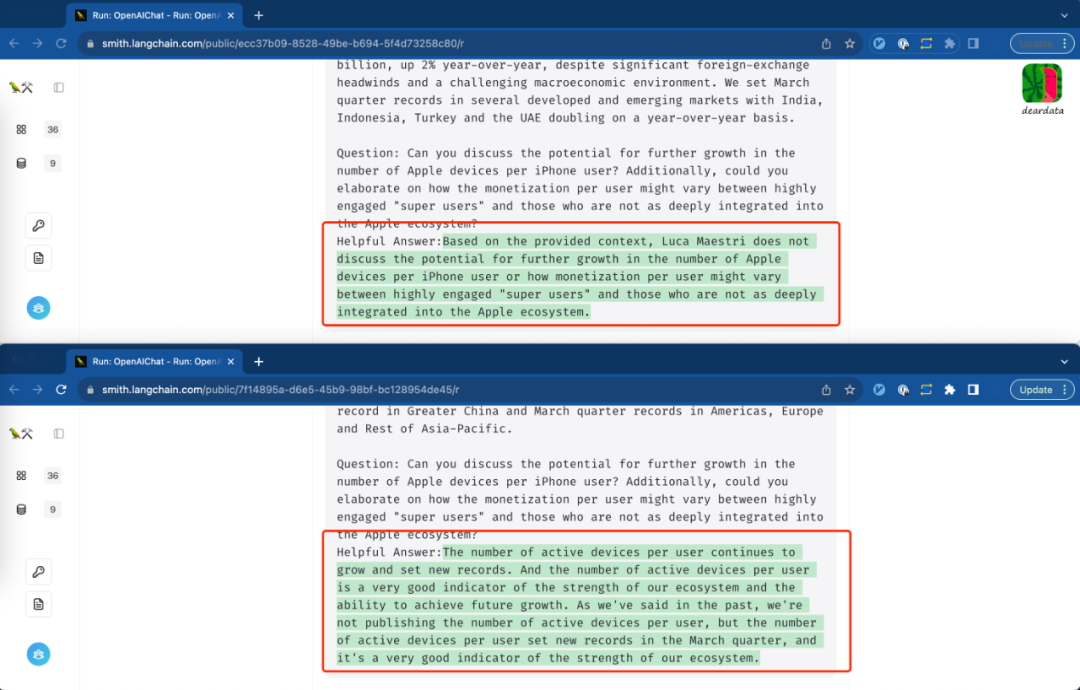
如图所示,模型往外面输出这个结果是绿色底色的是生成的部分。
看上去,原来的电话财报会议的文字内容被切成一段一段,
前面是结构化的数据(灰色底色),后面是问题的答案(绿色底色)。
图片字太小,我们粘出来看。
提问:
Can you discuss the potential for further growth in the number of Apple devices per iPhone user? Additionally, could you elaborate on how the monetization per user might vary between highly engaged "super users" and those who are not as deeply integrated into the Apple ecosystem?
你能谈谈iPhone用户拥有的苹果设备数量进一步增长的潜力吗?
另外,能否详细说明一下,在高度参与的“超级用户”和那些没有深度融入苹果生态系统的用户之间,每个用户的营收可能会有什么不同?
ChatGPT 3.5的答案:
Based on the provided context, Luca Maestri does not discuss the potential for further growth in the number of Apple devices per iPhone user or how monetization per user might vary between highly engaged "super users" and those who are not as deeply integrated into the Apple ecosystem.
基于上述内容,Luca Maestri并没有讨论iPhone用户的苹果设备数量的进一步增长潜力,也没有讨论每名用户的营收在高度参与的“超级用户”和那些没有深度融入苹果生态系统的用户之间的差异。
Lepton.AI的答案:
The number of active devices per user continues to grow and set new records. And the number of active devices per user is a very good indicator of the strength of our ecosystem and the ability to achieve future growth. As we've said in the past, we're not publishing the number of active devices per user, but the number of active devices per user set new records in the March quarter, and it's a very good indicator of the strength of our ecosystem.
活跃用户设备数量继续增长,并创造了新的记录。活跃用户设备数量这一指标很好地反映了苹果公司生态系统的实力和未来实现增长的能力。正如我们之前所说,不会公布活跃用户设备数量,但这个指标在第三季度创下了新的纪录,这是有力证明我们生态系统实力的一个很好的指标。
所见即所得。
Lepton.AI和OpenAI的模型在同样的输入的情况下,Lepton.AI的模型能够做得更好。
因为使用了行业数据进行模型微调,当然,谁也不知道Lepton.AI使用的基础模型是哪个,正如我开头所说,这些都是“知识产权”。
“亲爱的数据”读者群的群友表示:
“(这个时间段),来个LangChain和向量数据库最佳实践,包括选型建议。出书,保证大卖。”
谭老师我听罢,狠狠点了点头,并且开始脑补当上白富美,迎娶CEO。
醒一醒。
我们细看了Lepton.AI的做法,其中的提示工程非常重要。
的确,LangChain+向量数据库+开源模型是一种非常务实的做法,做大模型空谈概念无用。lepton.AI是文章中举的一个例子,想得到一个好的结果,既靠提示工程(Prompt Engineering),微调,也靠向量数据库来优化,AI落地并不是只靠单点技术就能够搞定的。
One More Thing
为了加深理解,有几个用饺子来解释“技术名词”的有趣比喻:
向量数据是干什么的?
谭老师我跟向量数据库说,我喜欢吃荤饺子,不喜欢吃素饺子。
向量数据库收到我的指示,开始准备食材,根据口味偏好,向量数据库所选食材可能有新鲜猪肉,五香牛肉,水晶虾仁等等食材。因为用向量进行模糊查询,以上食材都属于选择范围之内的馅料。
线上模型服务这种产品怎么理解?
谭老师我爱吃饺子,嫌麻烦不愿意自己包。但又是个挑剔的食客,偏要吃我家特有的饺子馅包成的饺子。我理想中的餐厅应有这样的服务:直接拎着饺子馅来餐馆,坐等。
后面的安排,包饺子,煮饺子,端饺子,都由餐厅来服务,除了饺子馅,我自己带,其余的餐厅服务(模型服务)全包。
好了,这次聊到这里。
更多内容参考这个公众号
里面的这篇文章(前方高能,几乎全英文):
Earning Sage: How to Transform AI into a Savvy CFO

带货ing
《我看见了风暴》谭老师新书,京东有售

更多阅读
AI大模型与ChatGPT系列:
1. ChatGPT大火,如何成立一家AIGC公司,然后搞钱?
2. ChatGPT:绝不欺负文科生
3. ChatGPT触类旁通的学习能力如何而来?
4. 独家丨从大神Alex Smola与李沐离职AWS创业融资顺利,回看ChatGPT大模型时代“底层武器”演进
5. 独家丨前美团联合创始人王慧文“正在收购”国产AI框架OneFlow,光年之外欲添新大将
6. ChatGPT大模型用于刑侦破案只能是虚构故事吗?
7. 大模型“云上经济”之权力游戏
8. 云从科技从容大模型:大模型和AI平台什么关系?为什么造行业大模型?
9. 深聊第四范式陈雨强丨如何用AI大模型打开万亿规模传统软件市场?
10. 深聊京东科技何晓冬丨一场九年前的“出发”:奠基多模态,逐鹿大模型
11. 老店迎新客:向量数据库选型与押注中,没人告诉你的那些事
12.抢滩大模型,抢单公有云,Databricks和Snowflake用了哪些“阳谋”?
13.大模型“搅局”,数据湖,数据仓库,湖仓选型会先淘汰谁?
AI大模型与学术论文系列:
1.开源“模仿”ChatGPT,居然效果行?UC伯克利论文,劝退,还是前进?
2. 深聊王金桥丨紫东太初:造一个国产大模型,需用多少篇高质量论文?(二)
3. 深聊张家俊丨 “紫东太初”大模型背后有哪些值得细读的论文(一)
漫画系列
1. 是喜,还是悲?AI竟帮我们把Office破活干完了
2. AI算法是兄弟,AI运维不是兄弟吗?
3. 大数据的社交牛气症是怎么得的?
4. AI for Science这事,到底“科学不科学”?
5. 想帮数学家,AI算老几?
6. 给王心凌打Call的,原来是神奇的智能湖仓
7. 原来,知识图谱是“找关系”的摇钱树?
8. 为什么图计算能正面硬刚黑色产业薅羊毛?
9. AutoML:攒钱买个“调参侠机器人”?
10. AutoML:你爱吃的火锅底料,是机器人自动进货
11. 强化学习:人工智能下象棋,走一步,能看几步?
12. 时序数据库:好险,差一点没挤进工业制造的高端局
13. 主动学习:人工智能居然被PUA了?
14. 云计算Serverless:一支穿云箭,千军万马来相见
15. 数据中心网络:数据还有5纳秒抵达战场
AI框架系列:
1.搞深度学习框架的那帮人,不是疯子,就是骗子(一)
2.搞AI框架那帮人丨燎原火,贾扬清(二)
3.搞 AI 框架那帮人(三):狂热的 AlphaFold 和沉默的中国科学家
4.搞 AI 框架那帮人(四):AI 框架前传,大数据系统往事
注:(三)和(四)仅收录于《我看见了风暴》。