Model Sparsity Can Simplify Machine Unlearning
- 背景
- 主要内容
- Contribution Ⅰ:对Machine Unlearning的一个全面的理解
- Contribution Ⅱ:说明model sparsity对Machine Unlearning的好处
- Pruning方法的选择
- sparse-aware的unlearning framework
- Experiments
- Model sparsity improves approximate unlearning
- Effectiveness of sparsity-aware unlearning
- Application: MU for Trojan model cleanse.
- Application: MU to improve transfer learning.
背景
Machine Unlearning(MU)是指出于对数据隐私保护的目的以及对"RTBF"(right to be forgotten)等数据保护方案的响应,而提出的一种数据遗忘的方法。在现实中,用户有权请求数据收集者删除其个人数据,但是仅将用户数据从数据集中删除是不够的。 原因:对model的攻击,比如成员推理攻击(membership inference attack,MIA),模型反演攻击等,能够从model反推出训练数据集的信息。 如果model A是用完整的数据集训练的,那么将用户信息从数据集中删除的同时,还需要从model A中抹除用户的数据信息。
对MU分类,可以分为exact unlearning和approximate unlearning。
- 前者即利用删除部分数据后的剩余数据集(Dr)重新训练(Retrain),得到一个新的model,因为这个model的训练并没有用到被删除的数据(Df),自然不包含Df的信息。因此通过Retain得到的model被认为是gold-standard retrained model 。 但是重训练需要很高的计算成本、时间成本,因为在模型较大、数据集较大的情况下,训练一个model是需要耗费很多计算资源,并需要很长时间的。因为仅删除几条用户数据,就直接重新训练一个model是不实际的。
- 因此有了后者,近似MU。近似二字体现出这类MU方法在遗忘的程度和计算成本等上一个trade-off。近似遗忘是指通过其他的方法,比如influence function(也是newton step)去更新模型参数,使得模型不必耗费大量计算资源去重训练,而大致从模型中,抹除Df的信息。
实际上,在近似MU的过程中,比如利用influence function,或者fasher information matrix去更新模型参数的过程中,涉及到对模型参数的hessian matrix求逆的操作(hessian matrix就是二阶偏导),如果模型参数量很大,比如百万个参数,那么这些操作的计算量依旧是很大的。 因此为了降低计算量,在基于influence function的放上上又有很多优化,涉及很多理论的推导。
主要内容
论文链接:Model Sparsity Can Simplify Machine Unlearning
这篇论文的核心内容是,使用model sparsity,缩小approximate MU和exact MU之间的gap。这篇论文的model sparsity就是利用pruning,得到稀疏的模型,再去做MU,即先prune,再unlearn。主要内容如下:
Contribution Ⅰ:对Machine Unlearning的一个全面的理解
本文将approximate MU分为了以下四类:
- Fine-tuning(FT):把原来的model θ.在剩余数据集Dr微调少量的epochs,得到unlearning后的model θu。这个过程是希望能够通过在Dr上微调以启动 catastrophic forgetting(即在增量学习、连续学习的过程中,在另外个任务上微调model参数的时候,model就忘掉了在之前任务上学到的东西),使得模型遗忘掉Df的信息(因为原始数据集是Dr+Df)。
- Gradient ascent (GA):模型训练过程中,模型参数是在往loss减小的方向移动,现在针对Df里面的数据集,将模型参数往在Df上数据点上的loss增大的方向移动。
- Influence unlearning(IU):使用influence function来表示数据点对模型参数w的影响。但是这个方法仅使用删除的数据Df不大的情况。因为influence function中用到了first-order Taylor expansion,如果数据集变化较大的话,这个近似就不准确了。
- Fisher fogetting(FF):这个方法主要是用到了fisher information matrix(FIM)……【这个方法相关的论文我没看懂】……FIM的计算量也是很大的。
这篇论文也提到,MU性能的评估指标有很多方面,再related works中各个approximate MU使用的评估指标不仅相同,也不全面,有些方法在metric A下性能可以,但在metric B下就不太优秀;而某些方法则相反。因此这篇论文希望对MU有一个全面的评估:
- Unlearning accuracy (UA):属于反映unlearning efficacy的指标。UA(θu) = 1 - AccDf(θu)。就是unlearn后的model θu对遗忘数据Df的inference accuracy。AccDf(θu)越小越好,因此UA越大越好。
- Membership inference attack(MIA)on Df:MIA-efficacy是指Df中有多少样本被MIA预测为unlearn后的model θu的non-training samples。MIA-efficacy越大越好。
- Remaining accuracy(RA):unlearn后的model θu在Dr上的inference accuracy。属于fidelity of MU。越大越好。
- Test accuracy(TA):unlearn后的model θu在test dataset(不是Df也不是Dr,是一个新的用于测试的数据集)上的inference accuracy,反应了unlearn后的model θu的generalization。
- Run-time efficiency(RTE):以retrain为baseline,看approximate MU在计算上有多少加速。
Contribution Ⅱ:说明model sparsity对Machine Unlearning的好处
model sparsity,其实就是给model的参数上✖一个mask(m),保留的wi对应mi=1,不保留的wj对应mj=0。这里先给出了基于gradient ascent的MU方法的unlearning error+model sparsity的理论分析(proposition 2):
θt是迭代更新θ过程中的某个结果,θ0是初始的model。因为mask m只有很少的项为1,因此m使得unlearning error减少了。
之后通过实验,在上面的4中approximate MU方法上,验证model sparsity对MU是有好处的,尤其是针对FT,随着sparsity rate的增加,efficacy上(UA、MIA)有很大的提升:
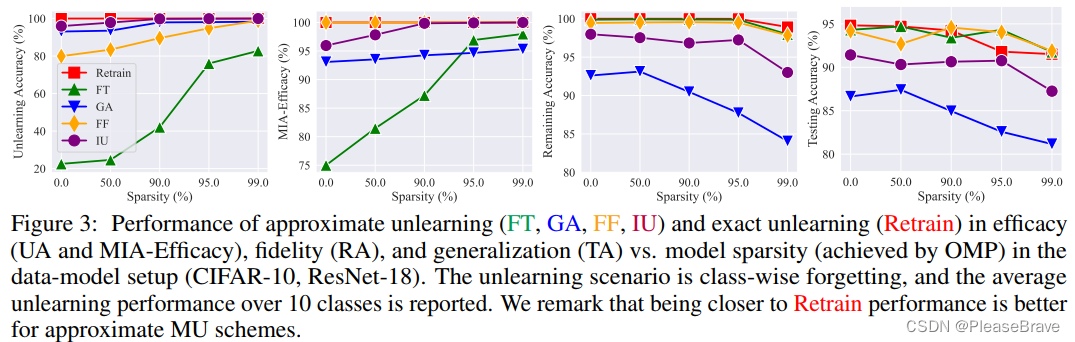
这里的实验是基于one-shot magnitude pruning(OMP)的。
Pruning方法的选择
这篇论文提到的主要方法是:先pruning,再unlearn。那么用什么pruning的方法呢?提到了三个criteria:①least dependence on the forgetting dataset (Df);因为最终是要移除model中包含的Df的信息,如果pruning的过程中过多的依赖Df的信息,那么sparse model中还是有很多Df的信息; ② lossless generalization when pruning;这个是希望pruning尽可能小的影响到TA;③ pruning efficiency,这个是希望尽可能小的影响到RTE,需要高效的pruning方法。 最终列出了三种:SynFlow (synaptic flow pruning),OMP (one-shot magnitude pruning),IMP。最终是用了SynFlow和OMP,因为这两个更优:

OMP和SynFlow在95% sparsity的时候,相对Dense模型,TA有所下降,但是UA提高很多。IMP则是TA有所上升,但是UA下降了。因此最终选择了OMP和SynFlow。因为IMP这个pruning方法对training dataset是强依赖的。
sparse-aware的unlearning framework
前面提到的都是先pruning再unlearn,后面文章提到pruning和unlearning同时进行,在unlearning的目标函数中引入一项L1-norm sparse regularization,最终MU的目标函数如下:
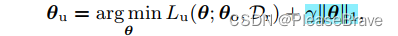
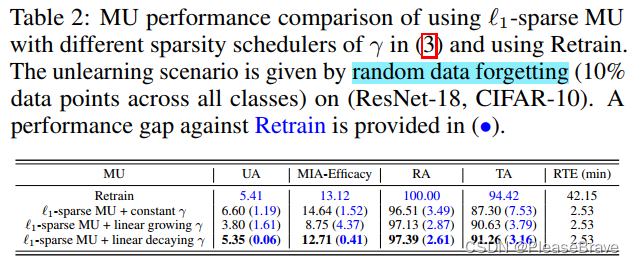
||θ||1越小的话,model也就越稀疏。这里的γ,是这个正则化项的权重,文章给了三种方案极其实验结果,最后说明“use of a linearly decreasing γ scheduler outperforms other schemes.”
Experiments
Model sparsity improves approximate unlearning
两种unlearning scenario:class-wise(Df consisting of training data points of an entire class)的和random datapoints(10% of the whole training dataset together)。
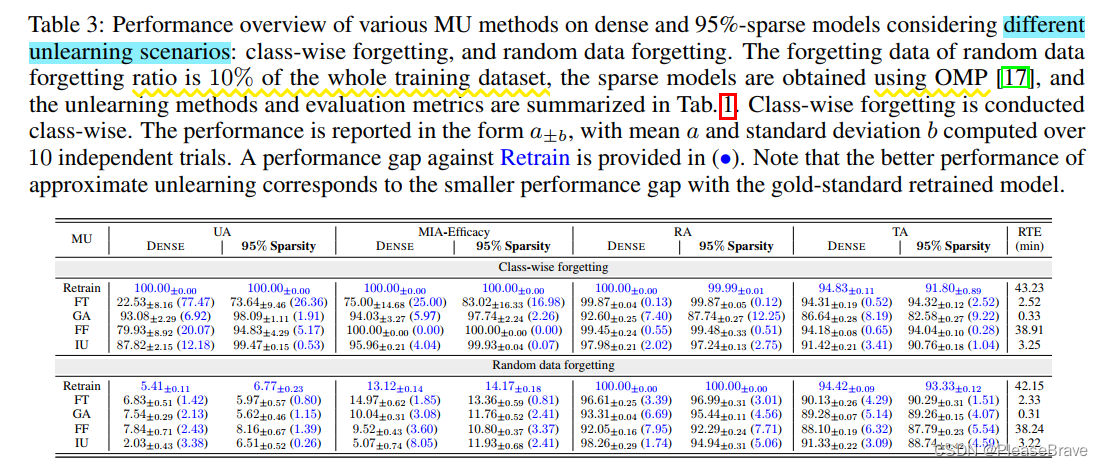
没一纵列,右边的和左边的对比,括号里是与Retain这个gold-standard的对比,数字越小越好。所以文章提出的先pruning能够boost MU performance。
Effectiveness of sparsity-aware unlearning
实验验证文章提出的pruning和unlearning同时进行的sparsity-aware unlearning方法效果:在class-wise forgetting和random data forgetting两个scenario下,与基于Fine-tuning的MU方法和Retain,在五个metric下对比:

蓝线即提出的方法,简直是五边形战士!(但是和FT比有点取巧了吧hhhhFT在dense model上性能本来就不行)。
Application: MU for Trojan model cleanse.
用MU遗忘掉adversarial examples的信息,可以实现后门的移除:
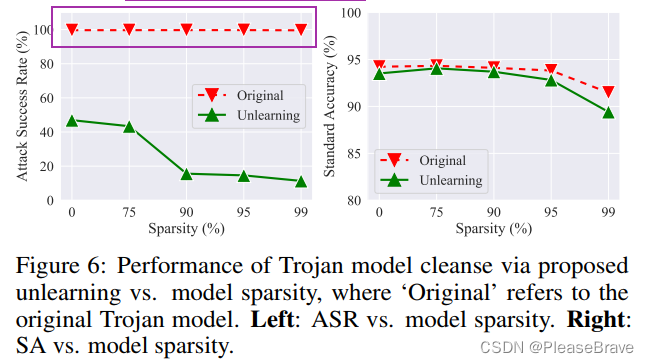
sparsity rate增加,unlearning后的model的ASR明显下降,同时standard accuracy降低不多。
Application: MU to improve transfer learning.
transfer learning是指在一个领域上学习好的较大的model,换一个领域的数据集微调最后分类相关的层就能继续用。但是原始的数据集,可能其中一些类对模型迁移影响是负面的,那么如果把这些类移除后训练的model迁移性更好。那么可以考虑用MU先将一些类的信息从model中移除,再transfer learning:
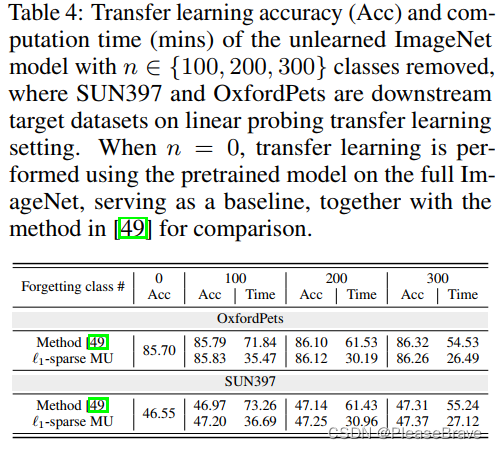
可见本文的方法,与参考方法相比,在两个数据集上的迁移Acc都有所增加,但是Time更少。