目录
Python基础知识
变量
赋值
数据类型
print用法
print格式化输出
运算符
if-else
数据结构
元组
in运算符
列表
切片 [ : ]
追加 append()
插入 insert()
删除 pop()
字典
循环
for循环
for循环应用——遍历
for循环应用——累加
for循环应用——计数器
while循环
for 和 while 的区别
终止循环
嵌套循环
函数
定义函数
调用函数
形参与实参
函数返回值
必选参数
匿名函数
递归
类与对象
类的属性与初始化
Python基础知识
变量
变量就像容器,能够存储各种类型的数据。
变量名只能由大小写字母,数字和下划线组成。需要注意:
1.不能以数字开头 2.不能包含空格 3.大小写敏感,变量A和变量a是不同的
赋值
将数据放入变量的过程,叫作赋值,赋值运算符是 =。
可以把常量赋值给变量, 也可以把变量赋值给变量, 还可以把运算结果赋值给变量。
数据类型
数据类型:整型,浮点型,布尔数,字符串。
这四种数据类型分别对应不同的应用场景。
整型和浮点型用于数字的表示和计算; 布尔数用于逻辑判断和运算; 字符串用来进行文本处理。
print用法
print()的括号里,是要输出的内容。这个内容可以是常量,也可以是变量,甚至是运算的结果。
字符串常量可以使用双引号 " ",单引号 ' ' 来表示。
双引号和单引号的功能相同,唯一的区别是,当字符串的内容已包含单引号时,我们可以使用双引号将内容括起来,反之同理。
print()函数中,字符串不能直接使用回车进行换行,否则系统会报错。
如需要换行,需要在换行处使用转义字符中的 \n。
print格式化输出
除了可以直接使用print()输出,还可以通过格式化输出的方式来对字符串进行“填空”。

格式化输出的语法如图:
1.在字符串常量前添加小写字母f
2.字符串中需要“填空”的地方使用大括号 { } 括起来
3.将需要填空的变量填入大括号 { } 中
eg:
name = "James"
age = 20
# 使用字符串格式化输出,在屏幕上输出: James is 20 years old
print(f"{name} is {age} years old")运算符
加+、减-、乘*、除/
取模 % 表示运算结果为两数相除结果的余数。
取整 // 表示运算结果为两数相除结果的商。
比较运算符:
大于>
小于<
等于==
大于等于>=
小于等于<=
不等于!=
逻辑运算符一共有三个,分别是:
and(并且)——两边的布尔数均为真时才为真,其他情况为假。
or(或者)——两边的布尔数至少有一个为真时为真,两边的布尔数都是假时才为假。
not(非)——仅有一个布尔数参与运算,结果为对这个布尔数取反。
if-else
if ():
xxxxxxxxxxxx
elif ():
xxxxxxxxx
else:
xxxxx容易犯的错误:
1. 语法错误
else 后面的冒号常常被遗漏,这是if-else的固定格式,有冒号程序才知道下面是 else 的代码块。
2. 缩进问题
if 和 else 为互斥关系,if和else 后面的代码块需要通过缩进形成。
3. 如果多个if都能满足,只执行第一个if。(越靠前的if应该越难满足)
数据结构

元组

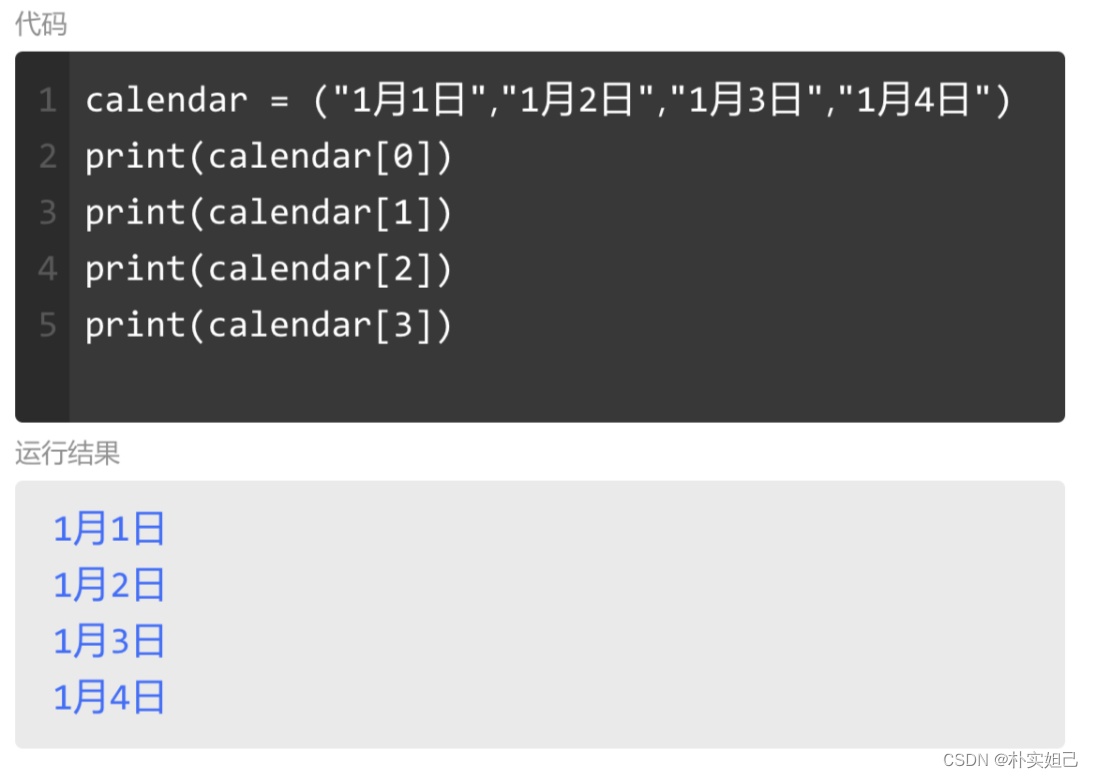
元组=(,,,,,)
元组中的数据是有顺序的。也就是说,如图在calendar这个元组里面,排在第一位的是"1月1日",第二位是"1月2日",第三位的是"1月3日"。第四位的是"1月4日"。
当我们输出calendar[0]的时候,就得到了这个元组的第一个数据。像这样访问它内部数据的机制,叫做“索引”。
索引是在数据结构中用来定位和寻找数据的检索方式。索引都是从0开始的。
可以通过中括号[]和索引的方式,直接访问到某一个位置的元素。
in运算符
快速判断某一个数据,是不是在元组中
numbers = (0,1,2,3,5,8,13,21,34,55,89,144,233,377)
#判断 5是否是元组中的一个元素
result = 5 in numbers
print(result)
列表

列表=【,,,,,】
列表中的数据可以是整型,浮点型,字符串或布尔数的任意组合。
列表的修改:

列表的修改不能应用于元组中,元组具有不可变的特性。
元组的内容定义完成后,里面的内容就不能修改。
切片 [ : ]
编程中的切片能对元组、列表等有序数据结构进行处理,以截取数据中连续的片段,方便使用。

切片要遵循“左闭右开”原则,就是取左边的数据,不取右边的数据,与数学中的区间类似[1, 3),取左不取右。
注意:切片与索引类似,也是从0开始,即第一个元素的索引为0。

例如,第2行中的someLetters[1:3],索引从0开始,这里就是取第2个元素到第4个元素。
又需要遵循“左闭右开”原则,则取第2个到第3个元素,输出['b', 'c']。
切片时,开始位置和结束位置的数字,还有三种填写情况:
1. 只填写结束位置的数字;
2. 只填写开始位置的数字;
3. 两侧数字都不填写。
1. 开始位置数字不填,默认从第一个元素开始切片。根据“左闭右开”原则,如图,从第一个元素(含)开始,取到第三个元素(含)。

2. 结束位置数字不填,默认从开始位置切片,取到最后一个元素。
注意:不填写结束位置的数字时,列表中最后一个元素也会被提取。如图,表示从第二个元素(含)开始,到最后一个元素(含)结束。
3. 开始位置和结束位置都不填写时,就是取列表中的所有元素。
追加 append()
追加一般用于描述在列表的末尾添加元素的行为。

使用 append() 可以追加不同数据类型,包括:字符串、整型、浮点型、元组以及列表等。
使用 append() 一次只能追加一个元素。
插入 insert()

我们需要在 insert() 的括号中填入两项内容:
第一项是元素插入的位置;
第二项是插入的具体数据。
插入元素以后,排在此元素之后的原有元素自动后移一位。
删除 pop()

括号内的数字表示要删除数据的索引,不填写数字则表示默认删除列表中的最后一个数据。
字典
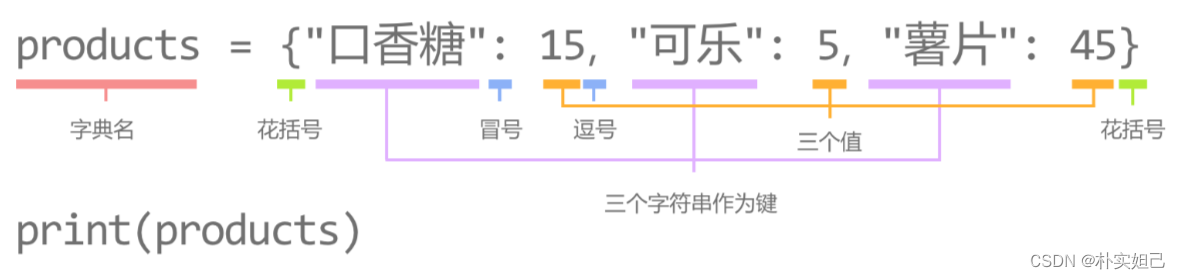
在Python中,将两种数据关联在一起形成一个元素, 由多个这样的元素组成的数据类型称为字典,又称为dict。
字典中的元素是不考虑排列顺序的。
组成字典元素(item)的两个数据一一对应,分别被称为键(key) 与值(value),所以字典的元素又称为键值对(key-value)。
字典的元素只能通过键来查找对应的值,所以一个键只能对应一个值。

在Python中,字典的键值对由冒号分割。冒号左边的数据为键,冒号右边的数据为值。
将多个这样的数据以逗号分割,存储到一个大括号中,就形成了一个字典类型。
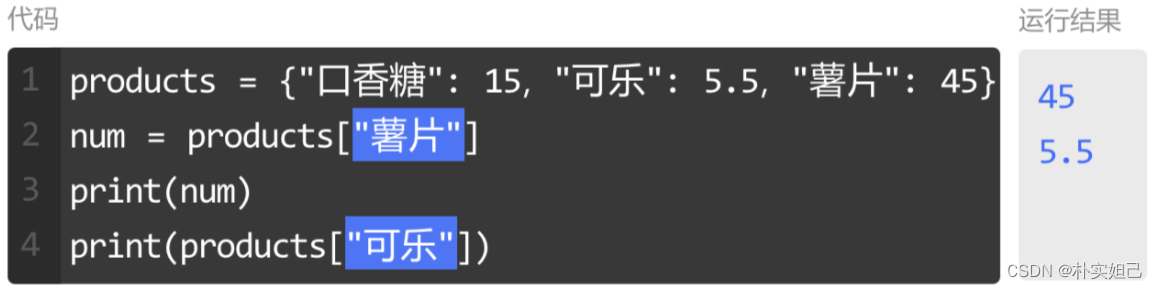
查找【】:
字典是没有顺序的,也就没有索引,所以只能通过字典的键(key)来查找对应的值(value)
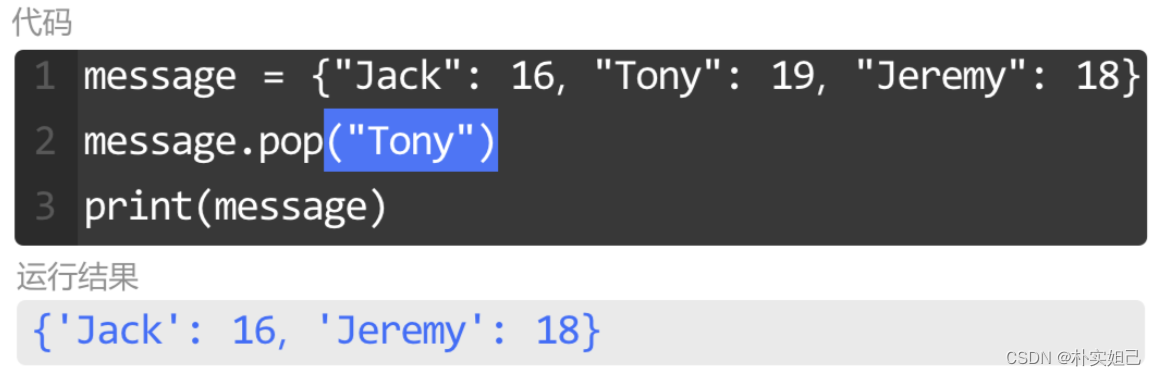
删除还是用pop():
字典的键是不能重复的。当我们尝试添加一个已经存在的键时,就会将该元素覆盖。
添加或修改:【】

对字典的修改,就是对字典的某个已经存在的键重新赋值。

查看字典里的键
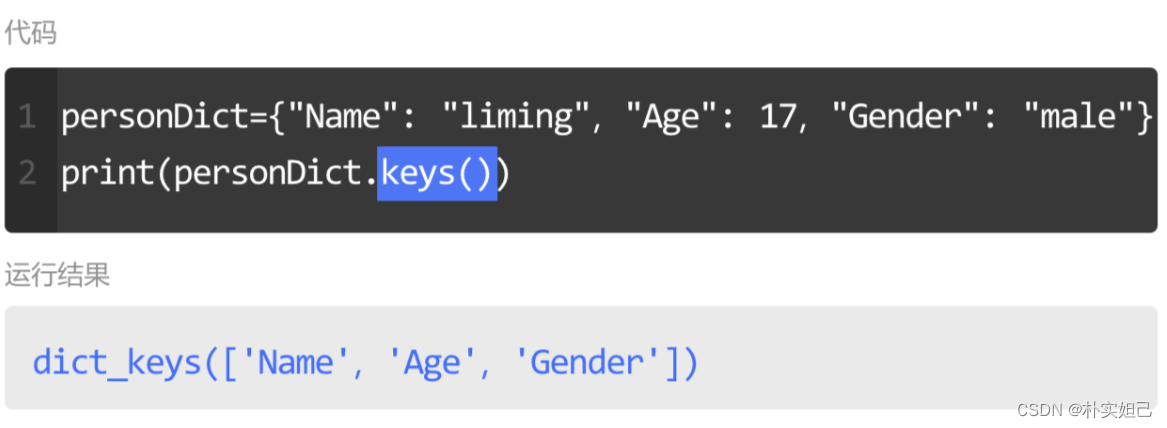
keys()是字典的一个功能,它能够提取一个字典所有的键,并存储在一个类似于列表的名为dict_keys的数据中,方便我们查看该字典的键。
除了使用“keys()”以外,我们也可以通过in运算来检查字典是否包含某个键。

循环
for循环
numberList = [10, 20, 30, 40, 50, 60]
for number in numberList:
print(number)
当程序执行完 for 循环后,如果同一层级(缩进一致)还有代码未执行,则按照顺序,继续自上而下执行。
name = ["david","bob","bill"]
for i in name:
print(i)
print(i)
#输出 david bob bill bill第一个print()是for循环内部的输出。每进行一次循环就会执行输出i的值一次。
第二个print()和for循环处于同一层级。当for循环结束以后,程序跳出循环,才会执行输出,输出最后一次循环结束时i的值。
for循环应用——遍历
遍历是指通过某种顺序对一个数据结构中的所有元素进行访问。
for循环不仅可以遍历列表,还可以遍历字典、元组、甚至字符串等数据结构。
遍历元组和字符串与遍历列表的代码几乎一样,也是逐个获取元组或字符串的每个字符。

for 循环遍历字典稍微有一些区别。
字典是键值对的组合,那么对字典的遍历就包含【键,值,键和值】三种情况。
遍历字典的键
for 循环遍历字典的键,有两种方法可以使用:
1. for 循环遍历字典;
这个方法和 for 循环遍历列表的格式类似。
2. for循环遍历字典中的所有键;
使用 for 循环遍历 dict.keys(),将字典中的键赋值给变量,再通过 print() 输出变量。

遍历字典的值
遍历字典的值,我们可以通过查字典的方式,也就是通过字典的键找到对应指定的值。
首先使用 for 循环遍历字典,将键赋值给变量,通过dict[键]的方式找到对应的值,并赋值给新的变量。
接着使用 print() 输出这个变量,即可遍历字典的值。
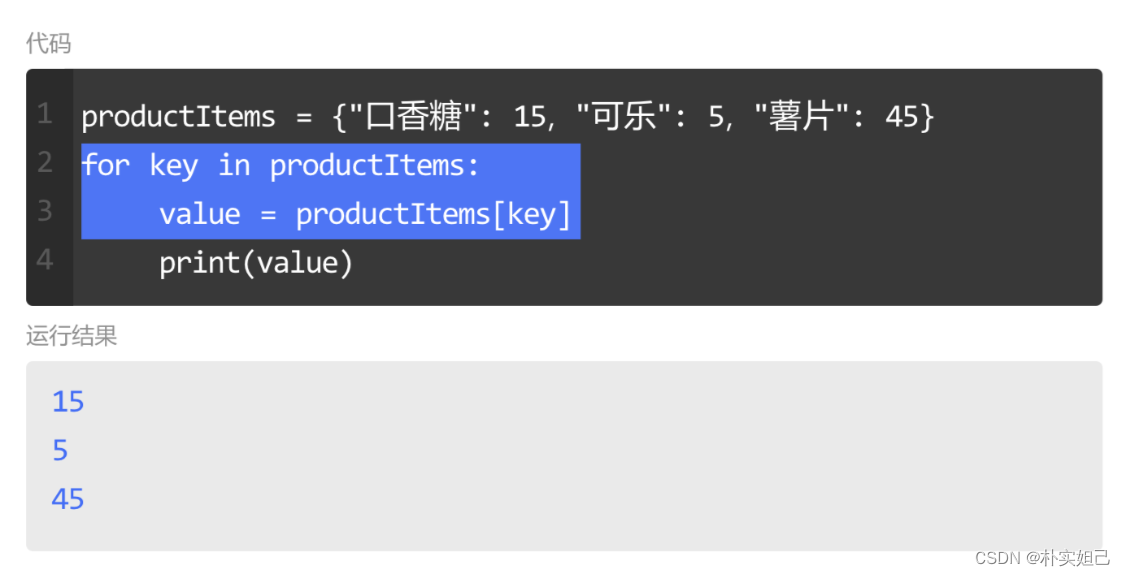
遍历字典的键和值
刚才我们使用 for 循环遍历字典的键和字典的值,如果想要同时输出字典的键和值,该怎么办呢?
这时,我们可以在循环内部分别输出字典的键和对应的值。
注意,在 for 循环中,一次循环会把循环内的代码全部执行完后,再开始下一次循环。

for i in range()
for i in range()的功能是:遍历一个整数列表。
其中range()的功能是:创建一个整数列表。
例如:range(5)可以生成一个从0 开始到5结束但不包括5的整数列表[0,1,2,3,4]
for i in range(5):
print(i)range()功能中可以填写2个内容,range(a,b)。
a: 计数从 a 开始。默认是从 0 开始,可省略。
b: 计数到 b 结束,但不包括 b,不可省略。

for循环应用——累加
jdList = [3, 1.5, 4, 2]
total = 0
for price in jdList:
total = total + price
print(total)
#这5行代码的功能就是,计算列表中的所有元素的总和并输出。
用一个变量来存储总和,第2行定义变量 total ,将0赋值给变量,这个过程就是设置初始值。
注意:这里的初始值需要定义在 for 循环的外侧,若定义在 for 循环中,每次循环变量都会重新赋值。
for循环应用——计数器
# 定义存储学生姓名的列表
students = ["Tom", "Blue", "Max", "Shufen", "Joe", "Tim"]
# TODO 定义变量count,初始值为0
count =0
# TODO 使用for循环变量列表
for name in students:
# TODO count值加1,赋值给count
count=count+1
# TODO 使用格式化输出
print(f"第{count}名是{name}")
while循环
条件循环,又称while循环,以判断条件是否成立,来决定是否执行循环内的代码。
当判断为真时,代码会循环执行,当判断为假时则终止循环。
while循环中,有一个判断条件,来决定是否执行循环内的代码。
判断为True,则继续执行循环;
判断为False,就会中止循环。
这样的判断条件,我们称为——边界条件
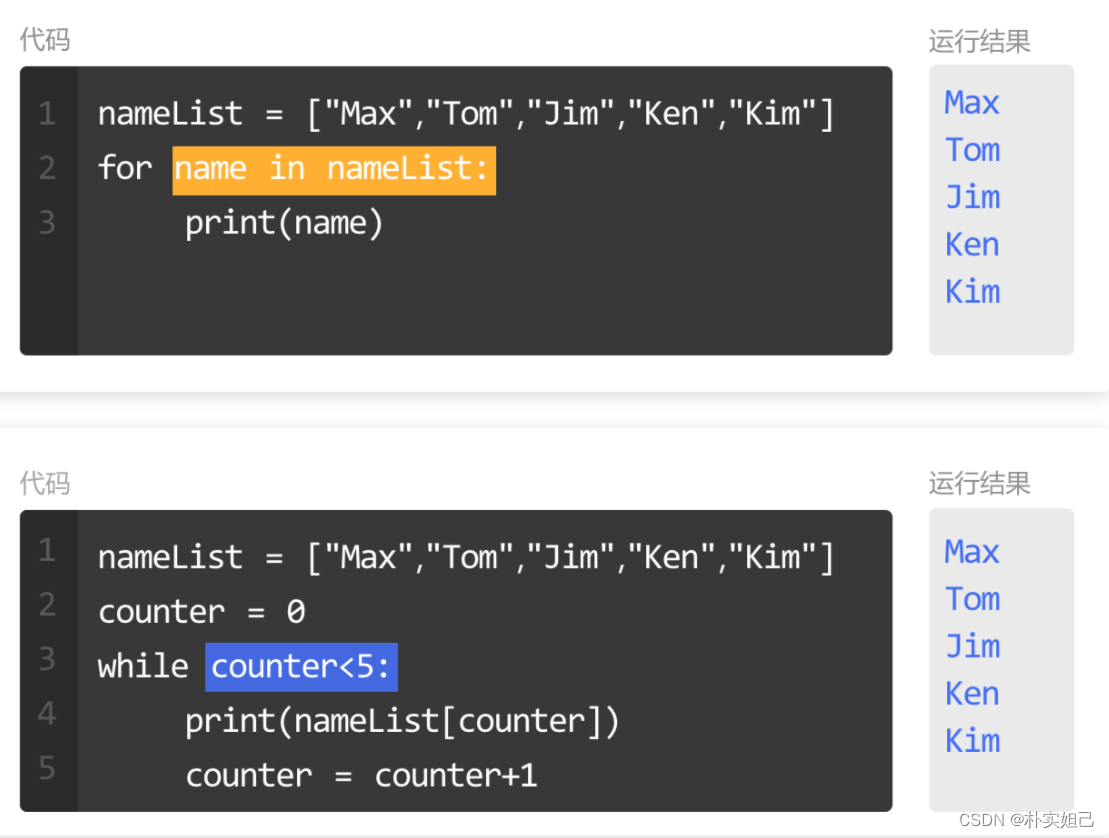
nameList = ["Max","Tom","Jim","Ken","Kim"]
counter = 0
while counter < 5:
print(nameList[counter])
counter = counter + 1
#使用了while循环把列表的元素全部输出出来
for 和 while 的区别
第一个区别:
for循环是在每一次循环的时候,按照从头到尾的顺序自动遍历,给变量name赋值列表中的元素;
而while循环是用一个计数器来索引列表,分别访问这个列表里面的每个元素。

第二个区别:
循环的终止条件不一样。
for循环的终止条件是遍历完这个列表;
while循环的终止条件是边界条件,counter<5,当边界条件为True的时候继续执行代码,为False的时候就终止执行。
终止循环
break
break语句既可以用在for循环中也可以用在while循环中。
它一般和if语句搭配在一起使用,表示如果满足了某种特定条件,就直接终止当前的循环结构。
numberList = [10, 4, 1, 20, 6]
for i in numberList:
print(i)
if i > 15:
break
print(numberList)
#这六行代码遍历了一个列表numberList,并依次输出其中的元素。
#第2-5行是一个完整的for循环结构。如果列表中有大于15的元素,就终止循环结构。
#for循环外,输出了完整的numberList。
continue
continue会“跳过”本次循环内的剩余代码。
drinks = ["water", "coke", "tea", "milk"]
for item in drinks:
if item == "coke":
continue
print(item)
这5行代码遍历了一个列表drinks。
第2-5行是一个完整的循环结构。在循环内,通过if语句判断该列表中是否有元素是"coke"。
如果有,则跳过本次循环中的剩余代码,也就是第5行的print(item),直接进入到下一次循环。
如果没有,就执行print(item),然后进入下一次循环,直到列表drinks中所有元素都被取完为止。break 和 continue 区别
当执行break时,会跳出整个循环结构,并运行循环外的第一行代码。
执行continue时,会“跳过”本次循环内的剩余代码,返回到循环的开头,继续执行下一次循环。
嵌套循环
嵌套循环的特征是:对于外循环的每次迭代,内循环都要完成它的所有迭代。
brandList = ["Ja mer","Cbp","SK3"]
itemList = ["精华","面霜","眼霜","爽肤水"]
for brand in brandList:
for item in itemList:
print(f"恭喜你将获得{brand}品牌的{item}一份")恭喜你将获得Ja mer品牌的精华一份
恭喜你将获得Ja mer品牌的面霜一份
恭喜你将获得Ja mer品牌的眼霜一份
恭喜你将获得Ja mer品牌的爽肤水一份
恭喜你将获得Cbp品牌的精华一份
恭喜你将获得Cbp品牌的面霜一份
恭喜你将获得Cbp品牌的眼霜一份
恭喜你将获得Cbp品牌的爽肤水一份
恭喜你将获得SK3品牌的精华一份
恭喜你将获得SK3品牌的面霜一份
恭喜你将获得SK3品牌的眼霜一份
恭喜你将获得SK3品牌的爽肤水一份函数
函数是指封装了某一特定功能的代码块。
简单的讲,函数就是用来存储代码的“特殊变量”。
定义函数
#这3行代码做的事情是定义了一个叫做“sayWelcome”的函数。
def sayWelcome(): #def是函数定义的关键字,是define的缩写。
print("欢迎光临")
print("商品一律九折")
调用函数

形参与实参
形参是形式参数的简称,指定义函数时设置的参数名称。
实参是实际参数的简称,指调用函数时实际传递的数据。
# TODO 定义一个函数 sayHi
def sayHi(name):
# TODO 格式化输出 "尊敬的会员{name}!"
print(f"尊敬的会员{name}!")
# TODO 输出 "欢迎进入我的网站"
print("欢迎进入我的网站")
# TODO 调用sayHi函数,并传递参数"Tony"
sayHi("Tony")
# TODO 调用sayHi函数,并传递参数"Gary"
sayHi("Gary") 参数可以定义多个,也可以不定义。
如果参数不止一个,多个参数之间可以用英文逗号“,”隔开。
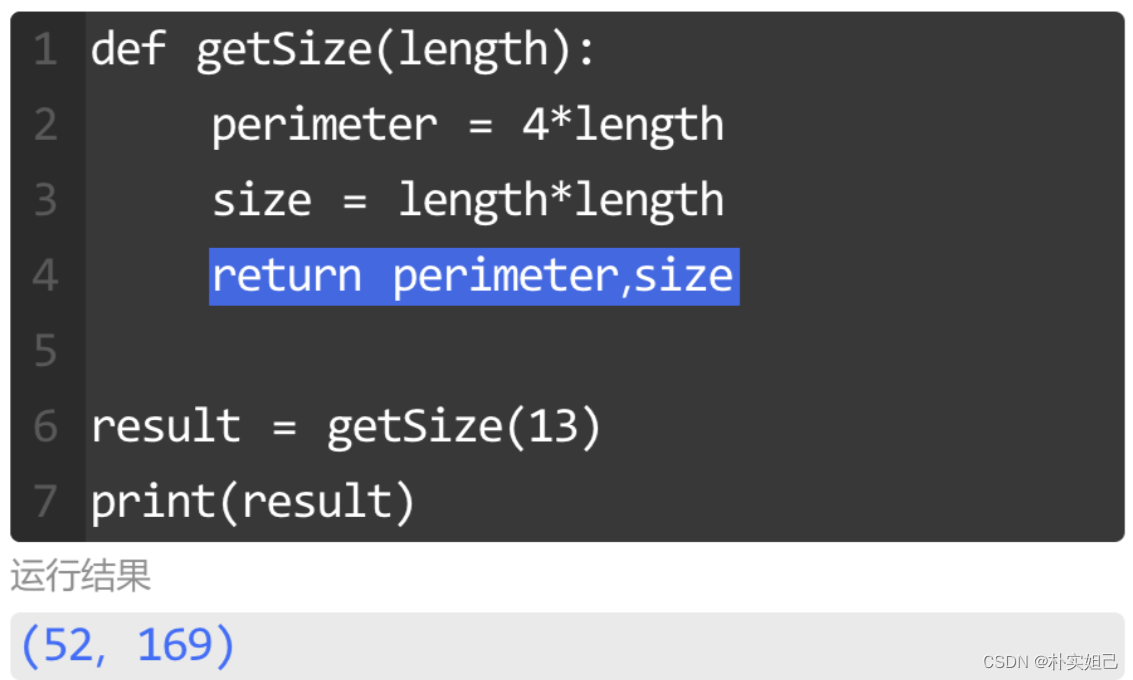
函数返回值
在函数中,使用关键字 return 设置要返回的数据。
return 位置一般都是在函数的末尾,这样才能停止函数内的代码运行并将 return 后的值返回。
return 后面是指定的返回值,返回值会返回到调用的地方。
# 定义函数sayHello(),传入参数name
def sayHello(name):
# 将"Hello!"与name字符串拼接,赋值给变量result
result = "Hello!" + name
# 返回变量result
return result
# 调用sayHello(),传入"Mary",并输出
print(sayHello("Mary"))
# 调用sayHello(),传入"Jack",并输出
print(sayHello("Jack"))函数经过内部代码的执⾏会产⽣一个结果,这个结果可以是一个具体的值也可以是多个值。
当函数同时返回多个值时,以逗号 "," 隔开,并且返回值以元组的格式返回。
函数名
为函数取名是为了方便我们重复使用。在 Python 中,函数的命名规则和变量类似。

必选参数
函数的一种参数类型,在调用这个函数的时候必须传入数据的参数。

在传递必选参数时,形参会按照定义的顺序依次接收数据。
在调用函数时,缺少或超出对必选参数的传递会导致程序错误。也就是说,在函数中定义了多少个必选参数就要传递多少个实参。
当我们忘记了传递顺序时,可以利用“形参名=实参名”的方式传递实参。这样以关键字传递实参的形式,简称为关键字实参。

匿名函数
匿名函数是一种不需要为函数命名的函数定义方式,以 lambda 关键字开头。

注意:lambda后面要空格,用到几个参数就需要写几个字母
area=lambda L,G,H:L*H*G
print(area(10,8,6))
#定义一个“匿名函数”,它的功能是计算立方体的体积,其公式为:长*宽*高,将匿名函数赋值给变量 area。然后传入参数10, 8, 6,并输出计算结果。递归
一段程序调用自身的过程我们叫做递归,多见于函数调用函数自身。
# TODO 定义名为sum()函数,传入参数n
def sum(n):
# TODO 如果n小于等于0
if(n<=0):
# TODO 返回0
return 0
# TODO 返回n加上sum(n-1)
return n+sum(n-1)
# TODO 调用sum()传入200并输出
result=sum(200)
print(result)def factorial(num):
if num <= 1:
return 1
return num * factorial(num-1)
print(factorial(10))
#写一个递归函数可以实现阶乘(factorial),计算10的阶乘。类与对象
类代表一些拥有相同特性与功能的事物,如鸟类,人类,猫类等。
类中的某一个具体实例称为这个类的实例对象,简称为对象。
属性用来描述这个类的一些特征,如品牌,颜色,型号是手机的属性。
方法用来表现这个类的一些功能,如拍照,打电话等是手机的方法。
eg:
用class定义一个类,并命名为Phone。
第2~6行,为该类添加了打电话和发短信两个功能。即定义了两个方法makeCall与sendMsg。
第2,3行,makeCall方法接收联系人的名字为参数,并将文字格式化输出。
第5,6行,sendMsg方法接收联系人的名字与短信内容为参数,并将文字格式化输出
class Phone():
def makeCall(self, who):
return f"正在拨打电话给{who}"
def sendMsg(self, who, txt):
return f"正在发送短信给{who}, 内容为{txt}"
将刚才定义好的Phone类拿过来,并实例化两个对象myPhone与yourPhone。
第9,10行,创建Phone的对象myPhone与yourPhone。
第12行,调用myPhone的方法makeCall,把结果存储到ret中。
第14行,调用yourPhone的方法sendMsg,把结果存储到ret2。
class Phone():
def makeCall(self, who):
return f"正在拨打电话给{who}"
def sendMsg(self, who, txt):
return f"正在发送短信给{who}, 内容为{txt}"
myPhone = Phone()
yourPhone = Phone()
ret = myPhone.makeCall("Tony")
print(ret)
ret2 = yourPhone.sendMsg("Jeremy", "中午吃啥?")
print(ret2) 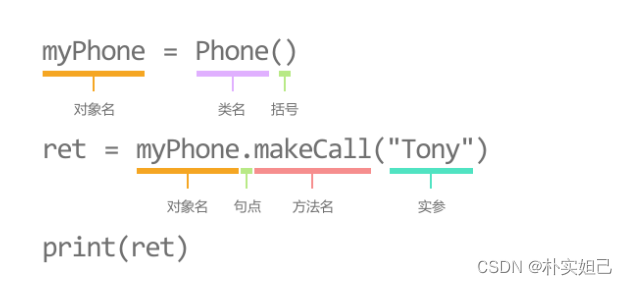
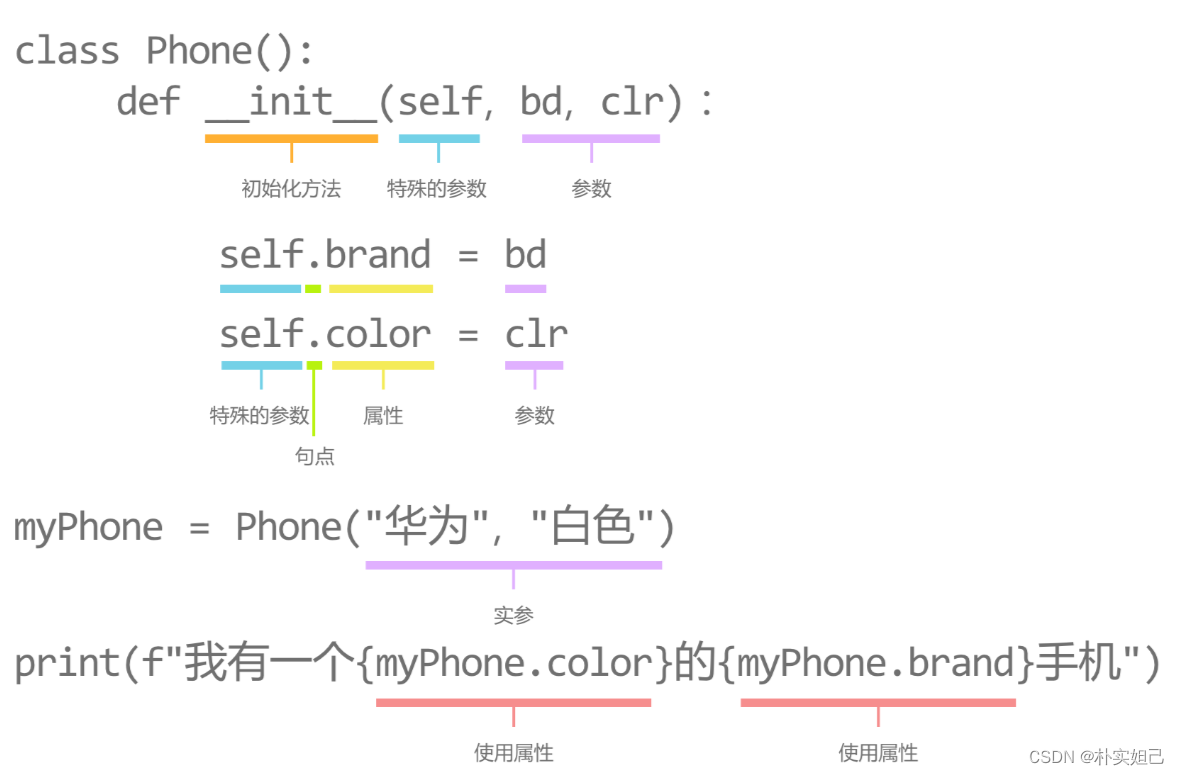
类的属性与初始化
eg:
为Phone类添加品牌(brand)与颜色(color)两个属性。
第2行,定义初始化方法__init__并设定两个参数bd与clr。
第8,9行,创建实例化对象myPhone与yourPhone,并为__init__方法传递参数两组不同的参数。
第10,11行,分别格式化输出实例对象的color与brand属性
class Phone():
def __init__(self, bd, clr):
print("创建实例对象时,自动调用此方法")
self.brand = bd
self.color = clr
myPhone = Phone("华为", "白色")
yourPhone = Phone("苹果", "黑色")
print(f"我有一个{myPhone.color}的{myPhone.brand}手机")
print(f"你有一个{yourPhone.color}的{yourPhone.brand}手机")初始化方法__init__,是一个特殊的方法。
init 的左右两边各有两个下划线,即整个名称共有四个下划线。
初始化类似于出厂设置,表示“开始时做好准备”,会在创建对象时自动被调用。