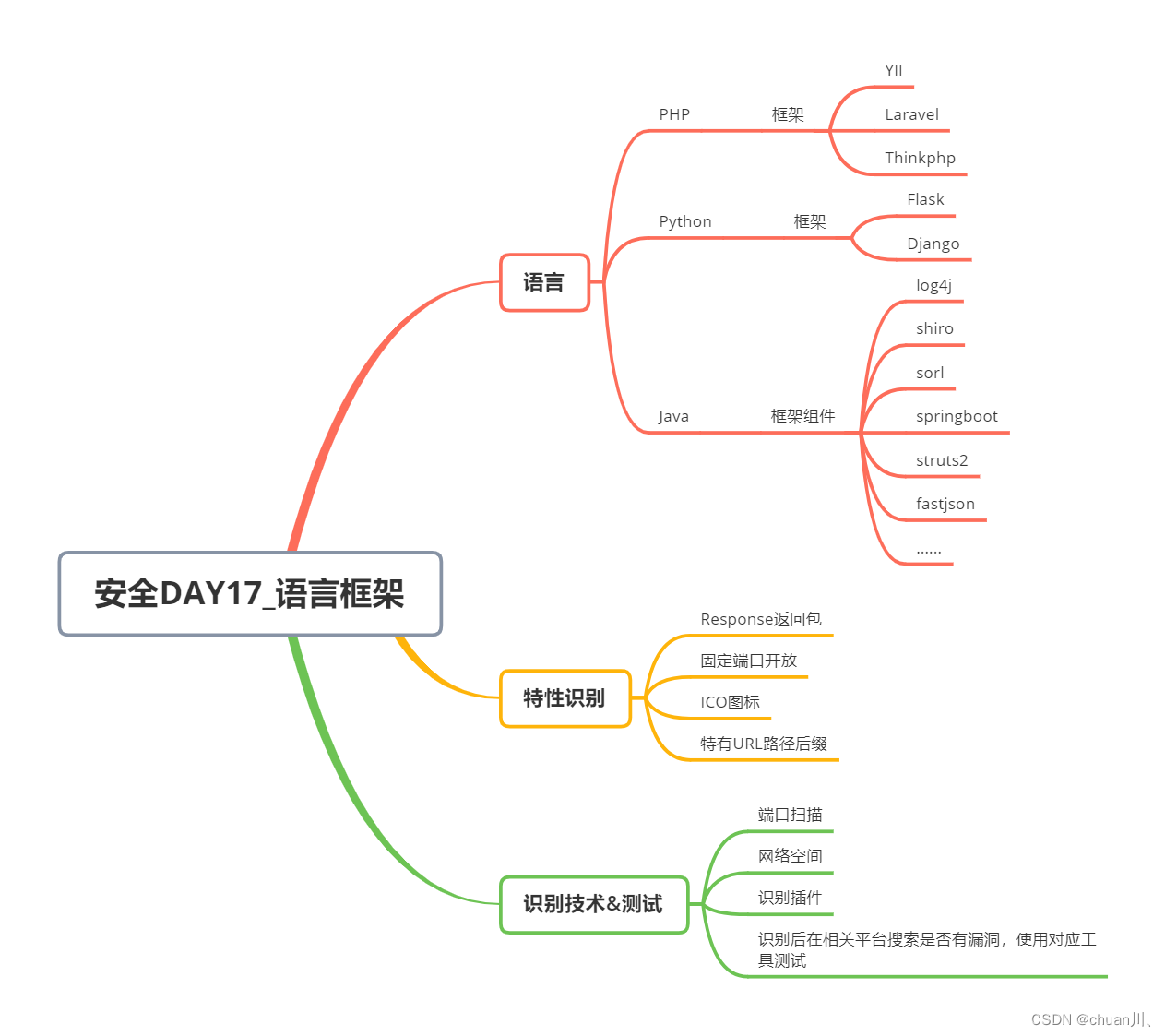
一、位运算
从 Lua 5.3 版本开始,提供了针对数值类型的一组标准位运算符,与算数运算符不同的是,运算符只能用于整型数。
| 运算符 | 描述 |
|---|---|
| & | 按位与 |
| | | 按位或 |
| ~ | 按位异或 |
| >> | 逻辑右移 |
| << | 逻辑左移 |
| ~(一元运算) | 按位取反 |
位的使用,可以参考小盆友的另一篇文章 《android位运算简单讲解》
https://blog.csdn.net/weixin_37625173/article/details/83796580
print(string.format("%x", 0xff & 0xabcd)) --> cd
print(string.format("%x", 0xff | 0xabcd)) --> abff
print(string.format("%x", 0xff ~ 0xabcd)) --> ab32
print(string.format("%x", ~0)) --> ffffffffffffffff (16 个 6,每一个十六进制 4 位,刚好是 64 位)
print(string.format("%x", 0xff << 12)) --> ff000
print(string.format("%x", 0xff >> -12)) --> ff000
-- 移位数等于或大于整型表示的位数,由于所有的位都被移出,则结果为 0
print(string.format("%x", -1 << 80)) --> 0
1-1、注意小点
所有的位运算针对一个整数型的所有位。
Lua 的两个移位操作都会用 0 填充空出的位,这种行为称为逻辑移位。 Lua 中没有提供算术右移(即使用符号位填充空出的位),但是可以通过向下取整除法( floor 除法)达到算数右移
local data = -0x100
print("逻辑右移:", string.format("%x >> 1 --> %x", data, data >> 1)) --> 逻辑右移: ffffffffffffff00 >> 1 --> 7fffffffffffff80
-- 达到算数右移一位,2^n ( n 即为右移位数)
print("算数右移:", string.format("%x >> 1 --> %x", data, data // 2)) --> 算数右移: ffffffffffffff00 >> 1 --> ffffffffffffff80
移位数是负数则表示向相反方向移位。a>>n 和 a<<-n 相等。
二、无符号整型数
在有符号整型数中使用一个比特位来存储符号位。所以 64 的整型数中最大可以表示为 2^63-1 ,而不是 2^64-1 。
值得注意的是 Lua 语言不显示支持无符号整型数, 但这并不妨碍我们在 Lua 中使用无符号整型这一特性,只是在使用过程中需要注意一些细节。
2-1、细节一:打印无符号整数
对于一个数最直观的就是展示出来,所以我们可以使用 string.format 进行格式化数值, 使用 %u(无符号整数)或 %X (十六进制)进行展示,这样就能很直观的感知无符号整数每一位的数值是多少。如果直接将无符号整数打印,会被认为是有符号整数,就不利于阅读。
local x = 3 << 62
print("有符号整数显示:", x) --> 有符号整数显示: -4611686018427387904
print("使用十进制无符号显示", string.format("%u", x)) --> 使用十进制无符号显示 13835058055282163712
print("使用十六进制无符号显示", string.format("0x%X", x)) --> 使用十六进制无符号显示 0xC000000000000000
2-2、细节二:无符号整数,加减乘运算
对于无符号整数的加减乘运算,和有符号是一样的,只是要注意溢出
local x = 3 << 62
print("使用十进制无符号显示", string.format("%u", x)) --> 使用十进制无符号显示 13835058055282163712
print("使用十进制无符号显示 +1", string.format("%u", x + 1)) --> 使用十进制无符号显示 +1 13835058055282163713
print("使用十进制无符号显示 -1", string.format("%u", x - 1)) --> 使用十进制无符号显示 -1 13835058055282163711
x = 1 << 62
print("使用十六进制无符号显示", string.format("0x%X", x)) --> 使用十六进制无符号显示 0x4000000000000000
print("使用十进制无符号显示 * 2", string.format("%X", x * 2)) --> 使用十进制无符号显示 * 2 0x8000000000000000
2-3、细节三:无符号整数,除法运算
对于无符号整数的除法会有些不一样,需要注意其符号位的影响,可以通过下面函数进行无符号整数的除法(细节也在每一行的注释中)
function udiv(n, d)
-- d<0 实质比较除数是否大于 2^63
if d < 0 then
-- 如果除数大于被除数(n<d),则商为 0 ;否则为 1
if math.ult(n, d) then
return 0
else
return 1
end
end
-- n >> 1 等价于将无符号整数 n / 2 , 这样的做法是先去除符号位置的影响
-- 最后 << 1 等价于 * 2 ,这样是为了纠正一开始 >> 1
-- // d 进行有符号整数的正常向下取整除法
local q = ((n >> 1) // d) << 1
-- 计算因为移位和向下取整导致的丢失数值,计算出两个结果后,如果偏差大于除数,说明需要加一
local r = n - q * d
if not math.ult(r, d) then
q = q + 1
end
return q
end
local u1 = 1 << 1
-- 正常数字除法
local div1 = 2
print(string.format("%X/%X = %X", u1, div1, udiv(u1, div1))) --> 2/2 = 1
-- (符号位为 1 )很大的数进行无符号除法
local u2 = 1 << 63
print(string.format("%X/%X = %X", u2, div1, udiv(u2, div1))) --> 8000000000000000/2 = 4000000000000000
-- (符号位为 0 )正常的数进行无符号除法
local u3 = 1 << 62
print(string.format("%X/%X = %X", u3, div1, udiv(u3, div1))) --> 4000000000000000/2 = 2000000000000000
-- 除数很大,符号为为 1 ,被除数 < 除数
local div2 = 1 << 63
print(string.format("%X/%X = %X", u3, div2, udiv(u3, div2))) --> 4000000000000000/8000000000000000 = 0
-- 被除数 > 除数
local u4 = (1 << 63) + 1
print(string.format("%X/%X = %X", u4, div2, udiv(u4, div2))) --> 8000000000000001/8000000000000000 = 1
local u5 = (1 << 63) + 3
print(string.format("%X/%X = %X", u5, div1, udiv(u5, div1))) --> 8000000000000003/2 = 4000000000000001
2-4、细节四:无符号整数比较
如果直接将无符号整数进行比较,则会导致一种情况:因为第 64 位在有符号整数是符号位,而无符号整数则用于正常表示数值,所以当第 64 位为 1 时,则会导致在直接比较时(此时被当作是有符号整数)无符号越大的值反而越小。
解决此类方法有两种方式:
第一种,使用 math.ult 进行比较无符号整数
local n1 = 0x7fffffffffffffff
local n2 = 0x8000000000000000
print(n1, n2, n1 < n2) --> 9223372036854775807 -9223372036854775808 false
print(n1, n2, math.ult(n1, n2)) --> 9223372036854775807 -9223372036854775808 true
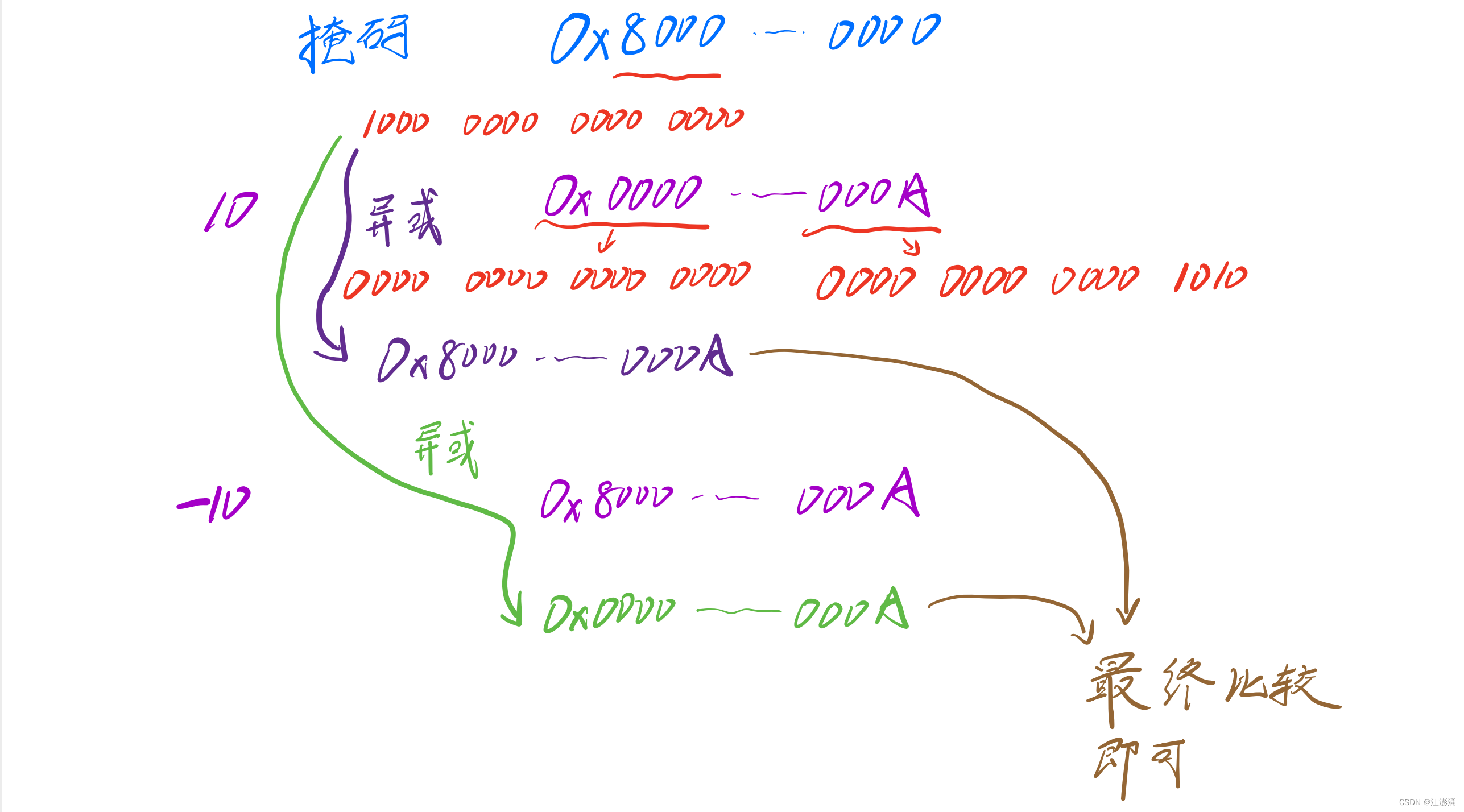
第二种,在进行有符号比较前先用掩码去两个操作数的符号位
local n3 = -10
local n4 = 10
local mask = 0x8000000000000000
print("有符号:", n3, "<", n4, n3 < n4) --> 有符号: -10<10 true
print("无符号:", n4, "<", n3, math.ult(n4, n3)) --> 无符号: 10<-10 true
print("无符号:", n4, "<", n3, (n4 ~ mask) < (n3 ~ mask)) --> 无符号: 10<-10 true
2-5、细节五:整型数和浮点数互转
整型转浮点数
local u = 0xC000000000000000
print(math.type(u), string.format("%X", u)) --> integer C000000000000000
-- + 0.0 是为将 u 转为 float , % 取余的规则符合通用规则,只要其中有一个为浮点数,结果则为浮点数
-- %(2 ^ 64) 是为将结果约束在这其中,否则显示时会被认为是有符号
local f = (u + 0.0) % 2 ^ 64
print(math.type(f), string.format("%.0f", f)) --> float 13835058055282163712
local f1 = (u + 0.0)
print(math.type(f1), string.format("%.0f", f1)) --> float -4611686018427387904
浮点数转整型
function utointerger(value)
if math.type(value) == "integer" then
return value
end
-- f + 2 ^ 63 是为了让数转为一个大于 2 ^ 64 的数
-- % (2 ^ 64) 是为了让数值限制在 [0, 2 ^ 64) 范围
-- - 2 ^ 63 是为了把结果改为一个"负值"(最高位为 1 )
-- 对于小于 2 ^ 63 的数:
-- 其实没有什么特殊的,加完一个数值(2 ^ 63)之后有减掉了,所以没有什么特殊
local result = math.tointeger(((value + 2 ^ 63) % (2 ^ 64)) - 2 ^ 63)
return result + (math.tointeger(value - result) or 0)
end
local f = 0xF000000000000000.0
local u = utointerger(f)
print(math.type(u), string.format("%X", u)) --> integer F000000000000000
值得注意:
因为这里是一个浮点数的计算,在我们之前的分享浮点数的文章中,有讲到 在 [-2^53, 2^53] 范围内,只需要将 整型数值 + 0.0 则可以进行转换为 浮点数,如果超出范围,会导致精度丢失,取近似值。
所以上述代码的 f 值如果超出这一范围,低位数可能会有问题
local f1 = 0x8000000000000001.0
local u1 = utointerger(f1)
print(math.type(u1), string.format("%X", u1)) --> integer 8000000000000000
三、二进制数据
Lua 从 5.3 开始提供了对二进制数和基本类型值之间进行转换的函数。
string.pack 会把值 “打包” 为二进制字符串
string.unpack 则从字符串中提取二进制
3-1、string.pack(fmt, v1, v2, …)
按照 fmt 格式将 v1、v2 进行打包为二进制字符串
参数:
- fmt:打包格式
- v1、v2:需要打包的数据
返回值:
字符串类型,即打包后的二进制数据
local format = "iii"
local s = string.pack(format, 3, -27, 450)
print(s, #s) --> ����� 12
3-2、string.unpack(fmt, s, pos)
按照 fmt 格式对字符串 s 偏移了 pos 个位置后,进行解析
参数:
- fmt:解析格式
- s:需要解析的字符串
- pos:可选,从字符串 s 的第 pos 个位置开始解析,默认为 1
返回值:
会有两个返回值,第一个为解析后的内容,第二个为解析的字符串 s 中最后一个读取的元素在字符串中的位置。
local format = "iii"
local s = string.pack(format, 3, -27, 450) --> ����� 12
-- 最后的 13 即,最后一个读取的元素位置
print(string.unpack(format, s)) --> 3 -27 450 13
3-3、整型数格式可选参数
每种选项对应一种类型大小
| 格式 | 描述 |
|---|---|
| b | char |
| h | short |
| i | int(可以跟一个数字,表示多少字节的整型数) |
| l | long |
| j | Lua 语言中的整型数大小 |
3-3-1、固定字节
在使用 i 的时候,大小会与机器有关,如果想要达到固定大小,可以考虑在后面加上数字(1~16),类似 i8,则会产生 8 个字节的整型数。
local n1 = 1 << 54
print(string.format("%X", n1)) --> 40000000000000
local x1 = string.pack("i8", n1)
print(#x1, string.format("%X", string.unpack("i8", x1))) --> 8 40000000000000
3-3-2、打包和解包都会检测溢出
打包的时候,如果发现字节不够装数值,则会抛出异常 bad argument #2 to 'pack' (integer overflow)
local x2 = string.pack("i8", 1 << 63)
print(string.format("%X", string.unpack("i8", x2)))
-- 打包会进行检查是否溢出
-- bad argument #2 to 'pack' (integer overflow)
print(string.pack("i7", 1 << 63))
解包也是一样的,会抛出异常 12-byte integer does not fit into Lua Integer ,因为对于 Lua 的整型数是 8 字节。
local x = string.pack("i12", 2 ^ 61)
print(string.unpack("i12", x))
x = "aaaa" .. "aaaa" .. "aaaa"
-- 解包也会检查是否能装得下
-- 12-byte integer does not fit into Lua Integer
--string.unpack("i12", x)
3-3-3、格式化无符号
每一个格式化选项都有一个大写的版本,对应无符号整型数:
local s = "\xFF"
print(string.unpack("b", s)) --> -1 2
print(string.unpack("B", s)) --> 255 2
3-4、字符串格式可选参数
可以使用三种形式打包字符串
| 格式 | 描述 |
|---|---|
| z | \0 结尾的字符串 |
| cn | 定长字符串,n 是被打包字符串的字节数 |
| sn | 显式长度字符串,会在存储字符串前加上该字符串的长度,n 是用于保存字符串长度的无符号整型数的大小 |
举些例子
s1 表示将字符串长度保存在一个字节中
print("----- sn -----")
local s1 = string.pack("s1", "hello")
print("s1 长度", #s1)
for i = 1, #s1 do
print(string.unpack("B", s1, i))
end
--> s1 长度 6
--> 5 2 (length)
--> 104 3 ('h')
--> 101 4 ('e')
--> 108 5 ('l')
--> 108 6 ('l')
--> 111 7 ('o')
s2 则表示用两个字节存储
s1 = string.pack("s2", "hello")
print("s2 长度", #s1)
for i = 1, #s1 do
print(string.unpack("B", s1, i))
end
--> s2 长度 7
--> 5 2 (length)
--> 0 3 (length)
--> 104 4 ('h')
--> 101 5 ('e')
--> 108 6 ('l')
--> 108 7 ('l')
--> 111 8 ('o')
值得注意,如果保存长度的字节容纳不下字符串的长度,则会有抛出异常
当然也可以直接使用 s 进行打包字符串,会使用 size_t 类型进行保存,在 64 位的机子上,一般使用 8 个字节保存,大多数情况这会有些浪费。
s1 = string.pack("s", "hello")
print("s 长度", #s1)
print(string.unpack("s", s1, i))
for i = 1, #s1 do
print(string.unpack("B", s1, i))
end
--> s 长度 13
--> hello 14
--> 5 2 (length)
--> 0 3 (length)
--> 0 4 (length)
--> 0 5 (length)
--> 0 6 (length)
--> 0 7 (length)
--> 0 8 (length)
--> 0 9 (length)
--> 104 10 ('h')
--> 101 11 ('e')
--> 108 12 ('l')
--> 108 13 ('l')
--> 111 14 ('o')
cn 打包固定长度自负串
-- 因为这里每个中文占 3 个字节,所以是 c9 ,后面打印也就有九行
local name = "江澎涌"
local fmt = string.format("c%d", #name)
local s3 = string.pack(fmt, name)
for i = 1, #s3 do
print(string.unpack("B", s3, i))
end
print(string.unpack(fmt, s3))
--> 230 2
--> 177 3
--> 159 4
--> 230 5
--> 190 6
--> 142 7
--> 230 8
--> 182 9
--> 140 10
--> 江澎涌 10
3-5、浮点数格式可选参数
| 格式 | 描述 |
|---|---|
| f | 单精度浮点数 |
| d | 双精度浮点数 |
| n | Lua 语言浮点数 |
local p = string.pack("fdn", 3.14, 1.70, 10.89)
print(string.unpack("fdn", p)) --> 3.1400001049042 1.7 10.89 21
3-6、大小端模式
默认情况下,格式使用的是机器原生的大小端模式。可以在格式中使用,一旦使用,后续的都会作用
| 格式 | 描述 |
|---|---|
| > | 大端模式、网络字节序 |
| < | 小端模式 |
| = | 改回机器默认模式 |
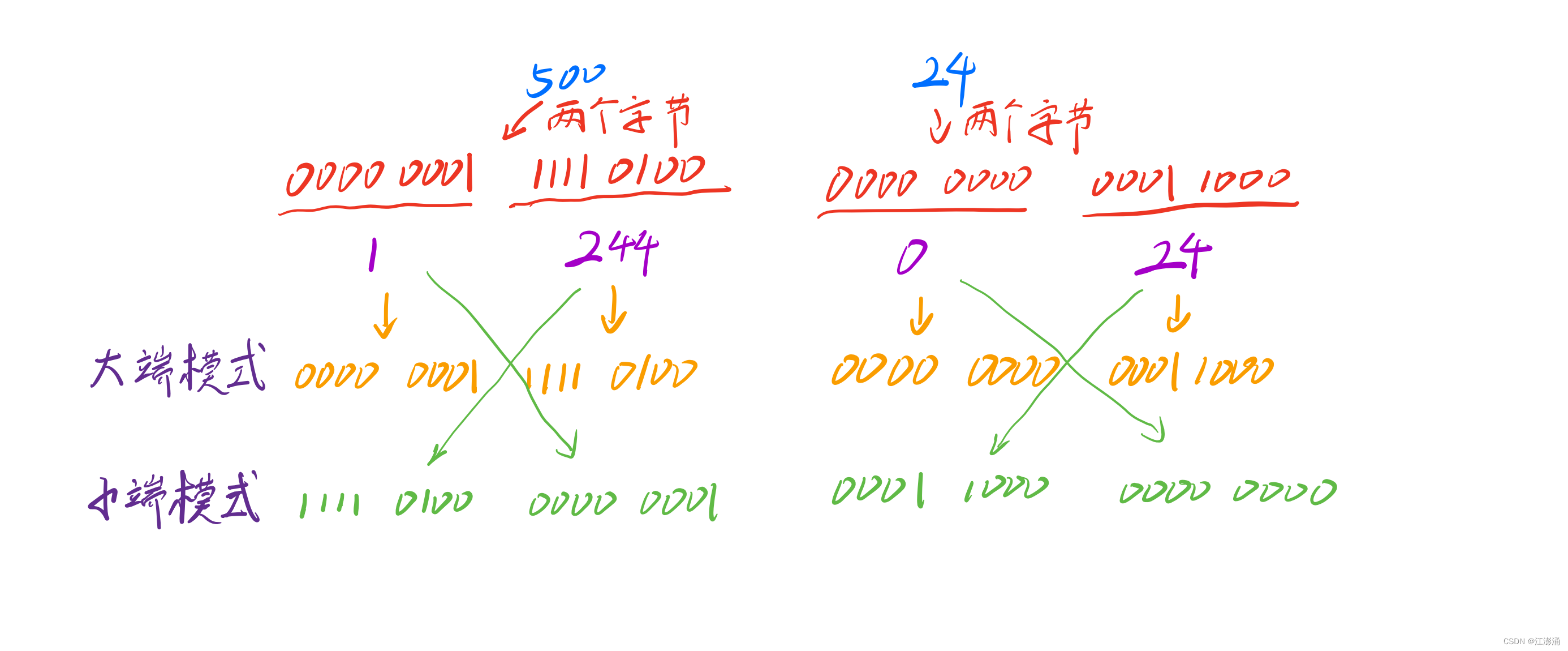
大端模式
local s1 = string.pack(">i2 i2", 500, 24)
for i = 1, #s1 do
print(string.unpack("B", s1, i))
end
--> 1 2
--> 244 3
--> 0 4
--> 24 5
小端模式
local s2 = string.pack("<i2 i2", 500, 24)
for i = 1, #s2 do
print(string.unpack("B", s2, i))
end
--> 244 2
--> 1 3
--> 24 4
--> 0 5
一图胜千言
改回默认
local s3 = string.pack(">i2 =i2", 500, 24)
for i = 1, #s3 do
print(string.unpack("B", s3, i))
end
--> 1 2
--> 244 3
--> 24 4
--> 0 5
3-7、对齐数据
使用 !n 进行强制数据对齐到 n 为倍数的索引上。如果只是使用 ! 则会使用机器默认对其方式
如果数据比 n 小,则对其到其自身大小,否则对其到 n 上。
例如 !4 ,则 1 字节整型数会被写入以 1 位倍数的所以位置上,2 字节的整型数会被写入到以 2 为倍数的索引位置上,而 4 字节或更大的整型数会被写入到以 4 为倍数的索引位置上。
local s = string.pack("!4 i1 i2 i4", 10, 10, 10)
print("#s", #s)
for i = 1, #s do
print(string.unpack("i1", s, i))
end
--> #s 8
--> 10 2
--> 0 3
--> 10 4
--> 0 5
--> 10 6
--> 0 7
--> 0 8
--> 0 9
string.pack 通过补 0 的形式实现对齐。string.unpack 则会在读取字符串时简单的跳过这些补位。
对齐只对 2 的整数次幂有效,如果不是则会报错 format asks for alignment not power of 2
在所有的格式化字符串默认的都会带有前缀 =!1,即表示使用默认的大小端模式且不对齐。
3-8、手工添加补位
可以通过 x 进行 1 字节的补位,string.pack 会在结果字符串中增加一个 0 字节,string.unpack 则会从目标字符串中跳过这一字节
local s = string.pack("i1i1xi1", 10, 10, 10)
print("#s", #s)
for i = 1, #s do
print(string.unpack("i1", s, i))
end
--> #s 4
--> 10 2
--> 10 3
--> 0 4
--> 10 5
四、拓展一下
可以使用这一节的内容实现一些类似二进制文件查看器的功能,如下图所示
具体代码 https://github.com/zincPower/lua_study_2022/blob/master/7%20%E4%BD%8D%E5%92%8C%E5%AD%97%E8%8A%82/dump.lua

还可以对图片进行操作,具体可以看 https://github.com/zincPower/lua_study_2022/blob/master/7%20%E4%BD%8D%E5%92%8C%E5%AD%97%E8%8A%82/writeBinary.lua
五、写在最后
Lua 项目地址:Github传送门 (如果对你有所帮助或喜欢的话,赏个star吧,码字不易,请多多支持)
如果觉得本篇博文对你有所启发或是解决了困惑,点个赞或关注我呀。
公众号搜索 “江澎涌”,更多优质文章会第一时间分享与你。