前言
看起来像是一篇投稿CVPR的文章,不知道被哪个瞎眼审稿人拒了。同期还有一篇CVPR被接收的工作Segment Any Motion in Videos,看起来不如这篇直白(也可能是因为我先看过spotlesssplats的缘故),后面也应该一并介绍了的。总体来说:就是如何给sam2提供一个很好地prompt,获得视频序列的dynamic mask 分割结果。
RoMo: Robust Motion Segmentation Improves Structure from Motion
造成像素变化的原因有两种:相机移动和物体移动,如何把这两种解耦并只获得物体移动的变化?
第一步
epipolar(RANSAC) 估计相机运动,RAFT估计光流变化,使用以下公式计算t到t’上的重投影误差:

并设置两个阈值:2v和0.01v,其中v是整体光流的平均移动速度。

这里获得了两个大致的动态mask和静态mask。
第二步
训练一个简单的分割网络(2个iteration),损失函数如下:
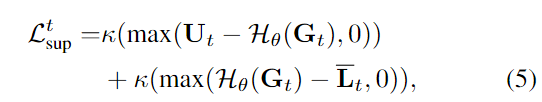
其中,H就是网络估计出来的dynamic mask。G是从sam2的encoder中取的最后一层feature。
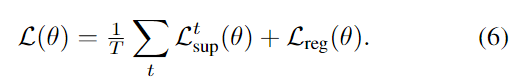
对于公式(5),目的就是让上述mask中估计出来的动态位置,MLP的预测值一定尽可能接近1,静态位置MLP预测值尽可能接近0。
由于上面是feature层面的操作,所以分辨率小于原始分辨率,最后再使用SAM2做致密化。