本篇博客介绍使用Python语言的深度学习网络,从零搭建一个ECG深度学习网络。
任务
本次入门的任务是,筛选出MIT-BIH数据集中注释为[‘N’, ‘A’, ‘V’, ‘L’, ‘R’]的数据作为本次数据集,然后按照8:2的比例划分为训练集,验证集。最后送入RCNN模型进行训练。
1. 数据集介绍
本次使用大名鼎鼎的MIT-BIH Arrhythmia Database数据集。下载地址:https://physionet.org/content/mitdb/1.0.0/
MIT系列有很多数据集,都可以在生理网:https://physionet.org/about/database/ 上找到下载地址。本次使用的MT-BIH心律失常数据库拥有48条心电记录,且每个记录的时长是30分钟。这些记录来自于47名研究对象。这些研究对象包括25名男性和22名女性,其年龄介于23到89岁(其中记录201与202来自于同一个人)。信号的采样率为360赫兹,AD分辨率为11比特。对于每条记录来说,均包含两个通道的信号。第一个通道一般为MLⅡ导联(记录102和104为V5导联);第二个通道一般为V1导联(有些为V2导联或V5导联,其中记录124号为Ⅴ4导联)。为了保持导联的一致性,往往在研究中采用MLⅡ导联。
在生理网:https://physionet.org/about/database/上,我们可以看到数据集更加详细的说明。比如:
MIT-BIH 数据集每个单独病人的说明:https://www.physionet.org/physiobank/database/html/mitdbdir/mitdbdir.htm

MIT-BIH 数据集每个单独病人的整个数据以及注释的可视化:https://www.physionet.org/physiobank/database/html/mitdbdir/mitdbdir.htm
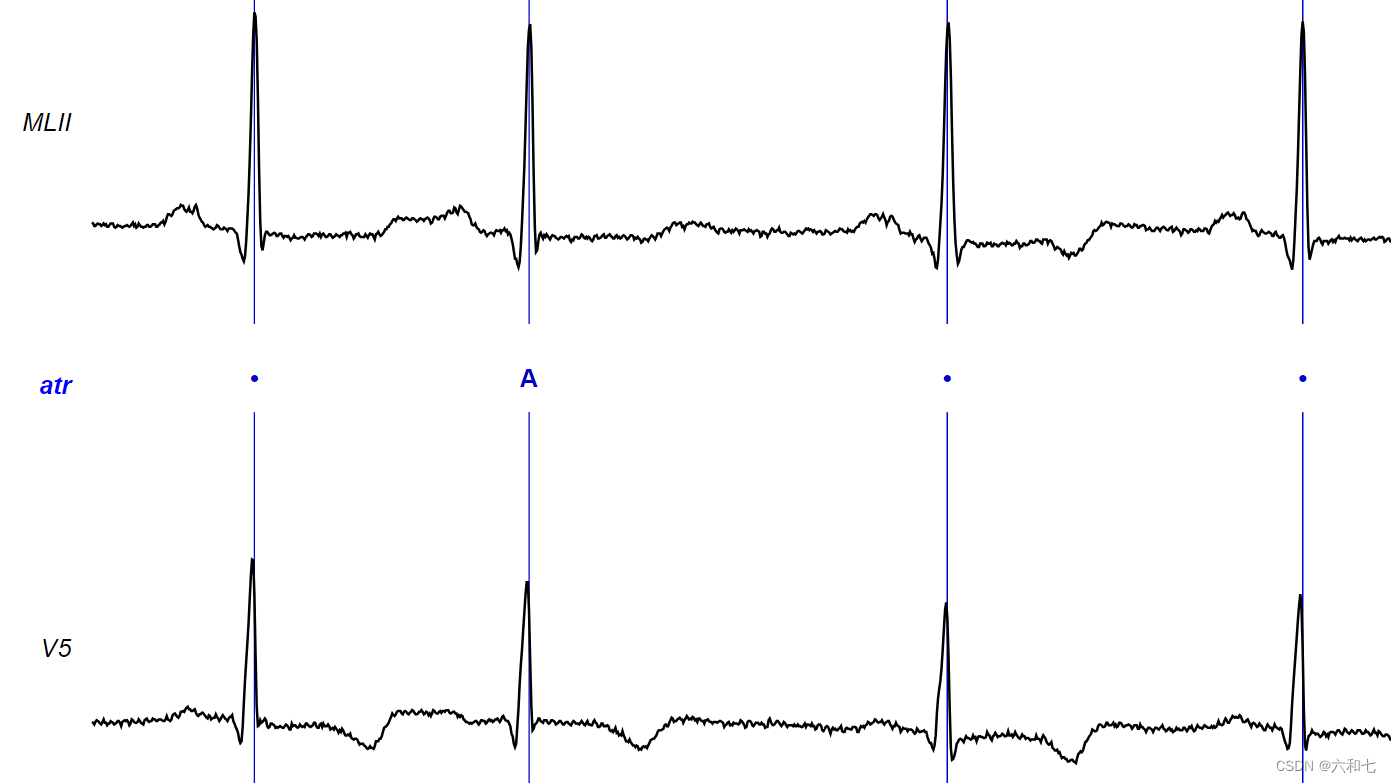
下载MIT-BIH 数据集之后,我们需要知晓以下几点:
- 从100-234不连续号码,一共48个病人。每个病人有三个文件(.dat,.atr,*.hea),包含有两路心电信号,一个注释。
- 有专门库读取MIT-BIH 数据集,叫做 wfdb。所以不要担心文件后缀的陌生感。
- 对心电图的标注样式如上图,“A"代表心房早搏,”."代表正常。整个数据集标注有40多种符号,表示40多种心拍状态。
2. 提取数据集
提取之前,先安装必要的库wfdb。wfdb详细介绍
pip install wfdb
这个库非常强大,打印数据信息,读取数据,绘制心电波形图,都可以靠它完成。
现在我们的划分步骤是:
- 提取出所有心电图数据点,心电图注释点
- 筛选出所有心电图注释点中仅为[‘N’, ‘A’, ‘V’, ‘L’, ‘R’]某一类的注释点
- 截取心电图数据中标记为[‘N’, ‘A’, ‘V’, ‘L’, ‘R’]某一类的点,在点周围长度为300的数据
- 将得到的数据进行维度处理,送入DataLoader()函数,完成模型对数据的认可。
3. 定义模型
本次使用的模型是输入大小为300,3层循环,隐藏层大小50。
'''
模型搭建
'''
class RnnModel(nn.Module):
def __init__(self):
super(RnnModel, self).__init__()
'''
参数解释:(输入维度,隐藏层维度,网络层数)
'''
self.rnn = nn.RNN(300, 50, 3, nonlinearity='tanh')
self.linear = nn.Linear(50, 5)
def forward(self, x):
r_out, h_state = self.rnn(x)
output = self.linear(r_out[:,-1,:]) # 将 RNN 层的输出 r_out 在最后一个时间步上的输出(隐藏状态)传递给线性层
return output
model = RnnModel()
4. 全部训练代码
'''
导入相关包
'''
import wfdb
import pywt
import seaborn
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import torch
import torch.utils.data as Data
from torch import nn
'''
加载数据集
'''
# 测试集在数据集中所占的比例
RATIO = 0.2
# 小波去噪预处理
def denoise(data):
# 小波变换
coeffs = pywt.wavedec(data=data, wavelet='db5', level=9)
cA9, cD9, cD8, cD7, cD6, cD5, cD4, cD3, cD2, cD1 = coeffs
# 阈值去噪
threshold = (np.median(np.abs(cD1)) / 0.6745) * (np.sqrt(2 * np.log(len(cD1))))
cD1.fill(0)
cD2.fill(0)
for i in range(1, len(coeffs) - 2):
coeffs[i] = pywt.threshold(coeffs[i], threshold)
# 小波反变换,获取去噪后的信号
rdata = pywt.waverec(coeffs=coeffs, wavelet='db5')
return rdata
# 读取心电数据和对应标签,并对数据进行小波去噪
def getDataSet(number, X_data, Y_data):
ecgClassSet = ['N', 'A', 'V', 'L', 'R']
# 读取心电数据记录
# print("正在读取 " + number + " 号心电数据...")
# 读取MLII导联的数据
record = wfdb.rdrecord('C:/mycode/dataset_make/mit-bih-arrhythmia-database-1.0.0/' + number, channel_names=['MLII'])
data = record.p_signal.flatten()
rdata = denoise(data=data)
# 获取心电数据记录中R波的位置和对应的标签
annotation = wfdb.rdann('C:/mycode/dataset_make/mit-bih-arrhythmia-database-1.0.0/' + number, 'atr')
Rlocation = annotation.sample
Rclass = annotation.symbol
# 去掉前后的不稳定数据
start = 10
end = 5
i = start
j = len(annotation.symbol) - end
# 因为只选择NAVLR五种心电类型,所以要选出该条记录中所需要的那些带有特定标签的数据,舍弃其余标签的点
# X_data在R波前后截取长度为300的数据点
# Y_data将NAVLR按顺序转换为01234
while i < j:
try:
# Rclass[i] 是标签
lable = ecgClassSet.index(Rclass[i]) # 这一步就是相当于抛弃了不在ecgClassSet的索引
# 基于经验值,基于R峰向前取100个点,向后取200个点
x_train = rdata[Rlocation[i] - 100:Rlocation[i] + 200]
X_data.append(x_train)
Y_data.append(lable)
i += 1
except ValueError:
i += 1
return
# 加载数据集并进行预处理
def loadData():
numberSet = ['100', '101', '103', '105', '106', '107', '108', '109', '111', '112', '113', '114', '115',
'116', '117', '119', '121', '122', '123', '124', '200', '201', '202', '203', '205', '208',
'210', '212', '213', '214', '215', '217', '219', '220', '221', '222', '223', '228', '230',
'231', '232', '233', '234']
dataSet = []
lableSet = []
for n in numberSet:
getDataSet(n, dataSet, lableSet)
# 转numpy数组,打乱顺序
dataSet = np.array(dataSet).reshape(-1, 300) # 转化为二维,一行有 300 个,行数需要计算
lableSet = np.array(lableSet).reshape(-1, 1) # 转化为二维,一行有 1 个,行数需要计算
train_ds = np.hstack((dataSet, lableSet)) # 将数据集和标签集水平堆叠在一起,(92192, 300) (92192, 1) (92192, 301)
# print(dataSet.shape, lableSet.shape, train_ds.shape) # (92192, 300) (92192, 1) (92192, 301)
np.random.shuffle(train_ds)
# 数据集及其标签集
X = train_ds[:, :300].reshape(-1, 1, 300) # (92192, 1, 300)
Y = train_ds[:, 300] # (92192)
# 测试集及其标签集
shuffle_index = np.random.permutation(len(X)) # 生成0-(X-1)的随机索引数组
# 设定测试集的大小 RATIO是测试集在数据集中所占的比例
test_length = int(RATIO * len(shuffle_index))
# 测试集的长度
test_index = shuffle_index[:test_length]
# 训练集的长度
train_index = shuffle_index[test_length:]
X_test, Y_test = X[test_index], Y[test_index]
X_train, Y_train = X[train_index], Y[train_index]
return X_train, Y_train, X_test, Y_test
X_train, Y_train, X_test, Y_test = loadData()
'''
数据处理
'''
train_Data = Data.TensorDataset(torch.Tensor(X_train), torch.Tensor(Y_train)) # 返回结果为一个个元组,每一个元组存放数据和标签
train_loader = Data.DataLoader(dataset=train_Data, batch_size=128)
test_Data = Data.TensorDataset(torch.Tensor(X_test), torch.Tensor(Y_test)) # 返回结果为一个个元组,每一个元组存放数据和标签
test_loader = Data.DataLoader(dataset=test_Data, batch_size=128)
'''
模型搭建
'''
class RnnModel(nn.Module):
def __init__(self):
super(RnnModel, self).__init__()
'''
参数解释:(输入维度,隐藏层维度,网络层数)
'''
self.rnn = nn.RNN(300, 50, 3, nonlinearity='tanh')
self.linear = nn.Linear(50, 5)
def forward(self, x):
r_out, h_state = self.rnn(x)
output = self.linear(r_out[:,-1,:]) # 将 RNN 层的输出 r_out 在最后一个时间步上的输出(隐藏状态)传递给线性层
return output
model = RnnModel()
'''
设置损失函数和参数优化方法
'''
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
'''
模型训练
'''
EPOCHS = 5
for epoch in range(EPOCHS):
running_loss = 0
for i, data in enumerate(train_loader):
inputs, label = data
y_predict = model(inputs)
loss = criterion(y_predict, label.long())
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
# 预测
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, label = data
y_pred = model(inputs)
_, predicted = torch.max(y_pred.data, dim=1)
total += label.size(0)
correct += (predicted == label).sum().item()
print(f'Epoch: {epoch + 1}, ACC on test: {correct / total}')





![[C++] string类的介绍与构造的模拟实现,进来看吧,里面有空调](https://img-blog.csdnimg.cn/a746a3bdb3db4521a78cc094207f94ed.gif#pic_center)