[oneAPI] 手写数字识别-VAE
- oneAPI
- VAE模型实现手写数字识别任务
- 定义使用包
- 定义参数
- 加载数据
- VAE模型与介绍
- 训练过程
- 结果
比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517
Intel® DevCloud for oneAPI:https://devcloud.intel.com/oneapi/get_started/aiAnalyticsToolkitSamples/
oneAPI
import intel_extension_for_pytorch as ipex
# Device configuration
device = torch.device('xpu' if torch.cuda.is_available() else 'cpu')
model = VAE().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
'''
Apply Intel Extension for PyTorch optimization against the model object and optimizer object.
'''
model, optimizer = ipex.optimize(model, optimizer=optimizer)
VAE模型实现手写数字识别任务
手写数字识别是一种常见的机器学习和计算机视觉任务,旨在识别手写的数字字符并将其分类为数字 0 到 9 中的一个。这个任务通常用于展示和验证机器学习算法和模型的性能。
任务描述:
- 输入:手写的数字字符图像,通常是灰度图像,每个像素代表一个像素点的亮度值。
- 输出:识别出的数字,范围从 0 到 9。
任务步骤:
- 数据收集:收集包含手写数字的图像数据集,通常是包含大量手写数字图像的数据集,如 MNIST 数据集。
- 数据预处理:对图像进行预处理,包括图像缩放、归一化、去噪等,以便输入模型进行训练和测试。
- 模型选择:选择适合手写数字识别任务的模型,常用的有卷积神经网络(CNN)等。
- 模型训练:使用训练数据对模型进行训练,通过反向传播优化模型参数,以最小化损失函数。
- 模型评估:使用测试数据评估模型的性能,计算识别准确率、损失值等指标。
- 预测和应用:使用训练好的模型对新的手写数字图像进行预测,输出识别结果。
- 手写数字识别任务在计算机视觉领域具有重要意义,不仅为图像分类提供了一个基本示例,还为更复杂的任务如物体识别、人脸识别等提供了基础。这个任务也常常被用于展示深度学习技术的能力,因为它相对简单且容易理解。
使用了pytorch以及Intel® Optimization for PyTorch,通过优化扩展了 PyTorch,使英特尔硬件的性能进一步提升,让手写数字识别问题更加的快速高效
使用MNIST数据集,该数据集包含了一系列以黑白图像表示的手写数字,每个图像的大小为28x28像素,数据集组成如下:
- 训练集:包含60,000个图像和标签,用于训练模型。
- 测试集:包含10,000个图像和标签,用于测试模型的性能。
每个图像都被标记为0到9之间的一个数字,表示图像中显示的手写数字。这个数据集常常被用来验证图像分类模型的性能,特别是在计算机视觉领域。
定义使用包
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import transforms
from torchvision.utils import save_image
import intel_extension_for_pytorch as ipex
定义参数
# Device configuration
device = torch.device('xpu' if torch.cuda.is_available() else 'cpu')
# Create a directory if not exists
sample_dir = 'samples'
if not os.path.exists(sample_dir):
os.makedirs(sample_dir)
# Hyper-parameters
image_size = 784
h_dim = 400
z_dim = 20
num_epochs = 15
batch_size = 128
learning_rate = 1e-3
加载数据
# MNIST dataset
dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
# Data loader
data_loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True)
VAE模型与介绍
VAE(Variational Autoencoder,变分自编码器)是一种生成模型,它结合了自编码器(Autoencoder)和概率图模型的思想,用于学习数据的潜在表示和生成新的数据样本。VAE 是一种无监督学习方法,常用于生成图像、声音、文本等数据。
VAE 的核心思想是学习数据的分布,并通过学习编码器和解码器来实现数据的自动生成和潜在表示学习。以下是 VAE 的主要组成部分:
- 编码器(Encoder):将输入数据映射到潜在空间(通常是高维的均值和标准差)中,生成潜在变量的分布。
- 采样(Sampling):从潜在变量的分布中随机采样,得到潜在变量的实际值。
- 解码器(Decoder):将潜在变量映射回原始数据空间,生成重构的数据样本。
- 损失函数(Loss Function):VAE 使用变分下界(Variational Lower Bound)作为损失函数,该下界包括重构误差和潜在变量的正则项,用于训练编码器和解码器。
VAE 的训练过程通过最小化损失函数来学习编码器和解码器的参数,使得模型能够学习数据的分布并生成具有类似分布的新数据样本。VAE 还具有潜在空间的连续性和插值性质,使得可以在潜在空间中进行有趣的操作,如图像插值和样式转换。
总之,VAE 是一种强大的生成模型,具有学习数据分布和生成新数据的能力,被广泛应用于图像生成、特征学习、数据降维等领域。
# VAE model
class VAE(nn.Module):
def __init__(self, image_size=784, h_dim=400, z_dim=20):
super(VAE, self).__init__()
self.fc1 = nn.Linear(image_size, h_dim)
self.fc2 = nn.Linear(h_dim, z_dim)
self.fc3 = nn.Linear(h_dim, z_dim)
self.fc4 = nn.Linear(z_dim, h_dim)
self.fc5 = nn.Linear(h_dim, image_size)
def encode(self, x):
h = F.relu(self.fc1(x))
return self.fc2(h), self.fc3(h)
def reparameterize(self, mu, log_var):
std = torch.exp(log_var / 2)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
h = F.relu(self.fc4(z))
return F.sigmoid(self.fc5(h))
def forward(self, x):
mu, log_var = self.encode(x)
z = self.reparameterize(mu, log_var)
x_reconst = self.decode(z)
return x_reconst, mu, log_var
model = VAE().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
'''
Apply Intel Extension for PyTorch optimization against the model object and optimizer object.
'''
model, optimizer = ipex.optimize(model, optimizer=optimizer)
训练过程
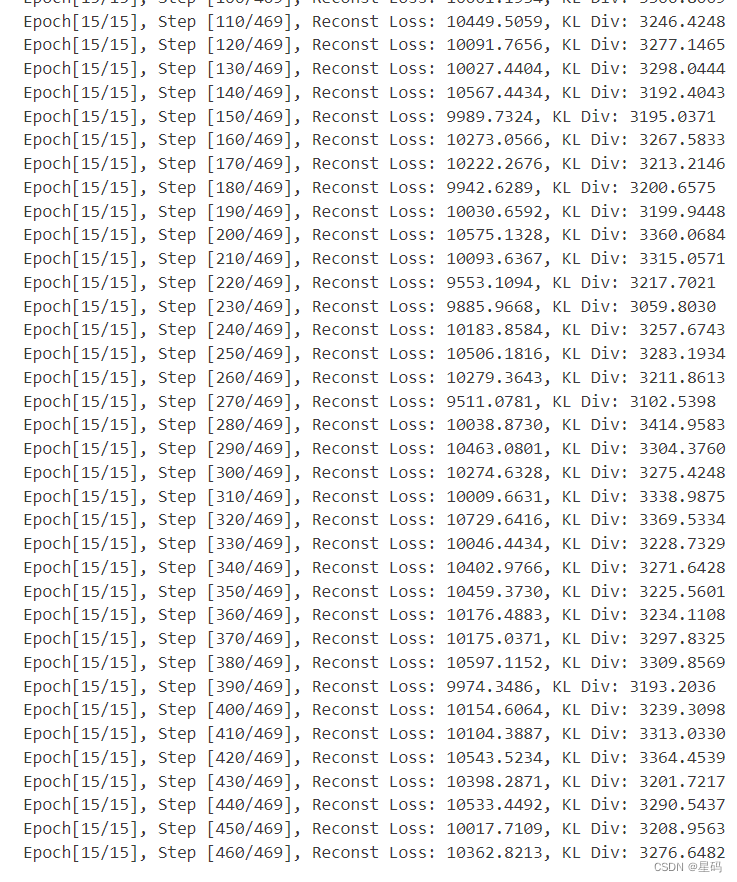
# Start training
for epoch in range(num_epochs):
for i, (x, _) in enumerate(data_loader):
# Forward pass
x = x.to(device).view(-1, image_size)
x_reconst, mu, log_var = model(x)
# Compute reconstruction loss and kl divergence
# For KL divergence, see Appendix B in VAE paper or http://yunjey47.tistory.com/43
reconst_loss = F.binary_cross_entropy(x_reconst, x, size_average=False)
kl_div = - 0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
# Backprop and optimize
loss = reconst_loss + kl_div
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 10 == 0:
print("Epoch[{}/{}], Step [{}/{}], Reconst Loss: {:.4f}, KL Div: {:.4f}"
.format(epoch + 1, num_epochs, i + 1, len(data_loader), reconst_loss.item(), kl_div.item()))
with torch.no_grad():
# Save the sampled images
z = torch.randn(batch_size, z_dim).to(device)
out = model.decode(z).view(-1, 1, 28, 28)
save_image(out, os.path.join(sample_dir, 'sampled-{}.png'.format(epoch + 1)))
# Save the reconstructed images
out, _, _ = model(x)
x_concat = torch.cat([x.view(-1, 1, 28, 28), out.view(-1, 1, 28, 28)], dim=3)
save_image(x_concat, os.path.join(sample_dir, 'reconst-{}.png'.format(epoch + 1)))
结果