论文:VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture Design
演示:https://vits-2.github.io/demo/
论文:https://arxiv.org/abs/2307.16430


目前仍然存在的问题:
-
intermittent unnaturalness
-
low efficiency of the duration predictor
-
complex input format to alleviate the limitations of alignment and duration modeling (use of blank token)
-
insufficient speaker similarity in the multi-speaker model
-
slow training, and strong dependence on the phoneme conversion.
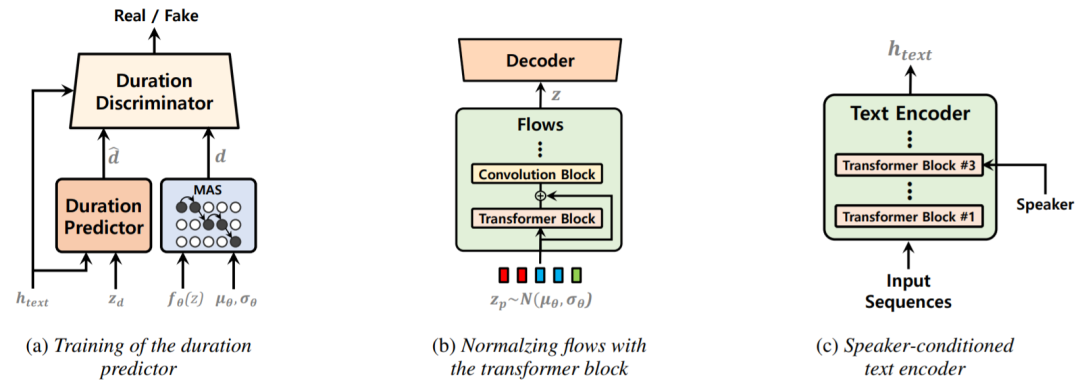
提出的方法:
-
a stochastic duration predictor trained through adversarial learning
-
normalizing flows improved by utilizing the transformer block
-
a speaker-conditioned text encoder to model multiple speakers’ characteristics better.