基于用户的协同过滤算法(UserCF)
因为我写的是博客项目,博客数量可能比用户数量还多
所以选择基于用户的协同过滤算法
重要思想
当要向用户u进行推荐时,我们先找出与用户u最相似的几个用户,再从这几个用户的喜欢的物品中预测出用户u最喜欢的几个物品并且用户u没有交互过的物品进行推荐
听起来好像很麻烦,实则不然,搞清楚思路后就是简单的套公式而已,我们就根据这个基本思想来进行所有的操作,就是说,这个思想会贯穿始终。
完整思路
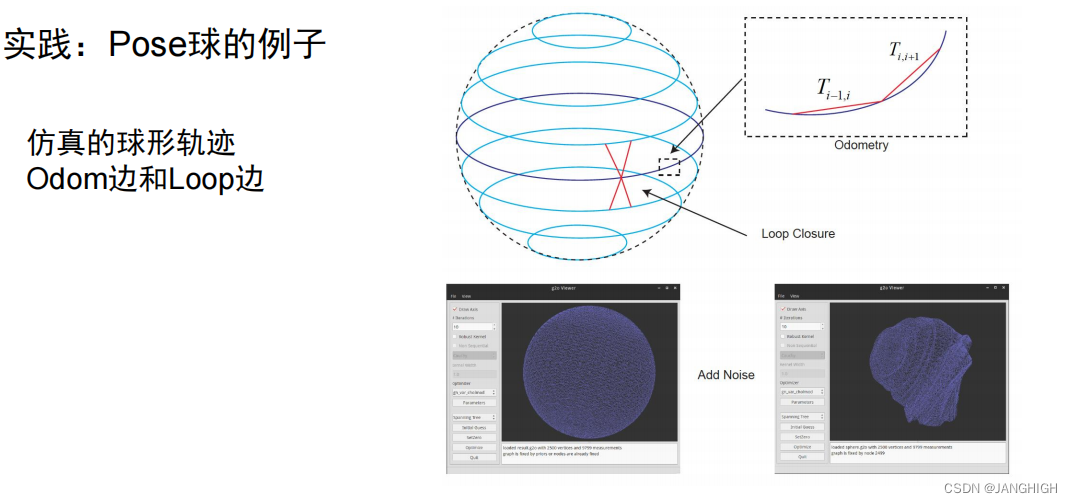
步骤一:首先,我们要找出与用户u最相似的几个用户
那我们是不是要知道2个用户之间的相似度是怎么计算的,然后根据其他所有用户与用户u的相似度进行一个排序,这样最前面k位就是与u最相似的k个用户。
这里我给出相似度公式---Jaccard公式
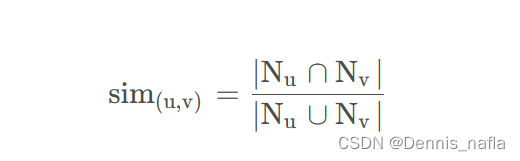
解释
- sim( u , v ) 是集合 u 和集合 v 的 Jaccard 相似度。
- |Nu∩ Nv| 表示集合 u 和集合 v 的交集的大小。
- |Nu∪ Nv| 表示集合 u 和集合 v 的并集的大小。
那么这些集合的含义又是什么?
这些集合表示的是用户所交互过的物品的集合
比如Nu就是用户u所交互过的物品的集合
什么是交互就不用我说了吧,比如我对某篇博客进行点赞,或者收藏,都是交互,其实点踩也是,但是我们是在做推荐系统,所以只要正反馈。
简单地说,这个公式的意思是:
用户u与用户v之间的相似度,是用户 u和用户 v 共同交互过的物品的数量
除以根号下(用户 u的交互过的物品总数*用户 v交互过的物品总数)
所以根据公式:我们需要得到2个东西:
1.每2个用户之间共同交互过的物品数量(又叫做协同过滤矩阵)
2.每个用户所交互过的物品总数量
1.先来求第一个条件--每2个用户之间共同交互过的物品数量
正常思路就是先得到每个用户交互过的物品的集合,再建立倒排表,表示每个博客被哪些用户交互过,这是很关键的一步。
这是我的从数据库取数据的操作,你们根据自己的实际情况来获取数据即可,
我的用户id是账号是String类型,博客Id就是它在博客表中的主键id,是int
//1.将user表里面所有用户查出来
//2.遍历所有用户,将点赞表,收藏表里面该用户的记录中的博客id都找出来,放在一个Set
//每遍历完一个用户就存Map里面
List<User> users = userMapper.getAllUser();
Map<String,Set<Integer>>userToBlogs = new HashMap<>();
Map<String, Integer> num = new HashMap<>();
for(User user:users)
{
//这个Set存放当前遍历到的用户所交互过的所有博客的id
Set<Integer> blogIds = new HashSet<>();
//下面这个blogIdsFromUpvote是用户所有点赞过的博客id
List<Integer> blogIdsFromUpvote = upvoteMapper.getBlogIdByUserId(user.getAccount());
blogIds.addAll(blogIdsFromUpvote);
//下面这个blogIdsFromCollect是用户所有收藏了的博客id
List<Integer> blogIdsFromCollect = collectMapper.getAllBlogIdByUserId(user.getAccount());
blogIds.addAll(blogIdsFromCollect);
userToBlogs.put(user.getAccount(),blogIds);
num.put(user.getAccount(),blogIds.size());
}不管过程怎么样,反正最终只需要得到2个Map:
1.Map<String,Set<Integer>>userToBlogs = new HashMap<>();
这个Map存的是用户ID所对应的一个交互过的博客id的Set集合,Set有自动去重功能。
2.Map<String, Integer> num = new HashMap<>();
这个Map存的是每个用户ID对应的该用户交互过的物品总数。
num到后面计算jaccard相似度的时候才用,现在只需要根据userToBlogs来建立倒排表,表示每个博客被哪些用户交互过。
也很简单,遍历userToBlogs这个Map的每个键值对,在嵌套内循环遍历每个键值对中的Set<Integer>,也就是用户交互过的物品集合,将每个遍历到的物品和当前对应的键(也就是当前遍历到的用户)存进倒排表,就是这样一个Map,表示每个物品所对应的交互过这个物品的用户的集合:
Map<Integer, Set<String>> itemToUsers
代码:
package com.mycsdn.util.UserCF;
import com.mycsdn.pojo.Blog;
import java.util.*;
public class InvertedIndex {
public static Map<Integer, Set<String>> getItemToUsers(Map<String, Set<Integer>> userToItems) {
Map<Integer, Set<String>> ItemToUsers = new HashMap<>();
for (Map.Entry<String, Set<Integer>> entry : userToItems.entrySet()) {
String userId = entry.getKey();
Set<Integer> blogs = entry.getValue();
for (Integer blogId : blogs) {
//如果当前博客对应的用户集合中没有用户,就新建一个Set再把当前用户加进去,如果有的话就之间加进去
Set<String> users = ItemToUsers.getOrDefault(blogId, new HashSet<>());
users.add(userId);
ItemToUsers.put(blogId, users);
}
}
return ItemToUsers;
}
}
现在得到了倒排表,就是这样一个Map,表示每个物品所对应的交互过这个物品的用户的集合:
Map<Integer, Set<String>> itemToUsers
开始求协同过滤矩阵
我们需要根据这个倒排表来求出协同过滤矩阵,也就是一个表示每2个用户之间共同交互过的物品数量
Map<String, Map<String, Integer>> CFMatrix = new HashMap<>();
String表示当前用户,对应的 Map<String, Integer>表示其他各个用户以及与当前用户的共同交互过的物品的数量
1.遍历这个倒排表,嵌套内循环遍历每个物品对应的用户集合的每个用户
2.对于遍历到的每个用户,通过遍历其他所有用户,将当前用户与其他用户的共同交互物品数加1
代码:
package com.mycsdn.util.UserCF;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class GetCFMatrix {
//得到的协同过滤矩阵是对于用户A,其他与A有共同交互过的博客的用户ID和共同交互过的博客的数量
public static Map<String, Map<String, Integer>> getCFMatrix( Map<Integer, Set<String>> itemToUsers) {
Map<String, Map<String, Integer>> CFMatrix = new HashMap<>();
System.out.println("开始构建协同过滤矩阵....");
// 遍历所有的物品,统计用户两两之间交互的物品数
for (Map.Entry<Integer, Set<String>> entry : itemToUsers.entrySet()) {
Integer item = entry.getKey();
Set<String> users = entry.getValue();
// 首先统计每个用户交互的物品个数
for (String u : users) {//遍历所有该博客对应的交互过的用户
// 统计每个用户与其它用户共同交互的物品个数
if (!CFMatrix.containsKey(u)) {
CFMatrix.put(u, new HashMap<>());
}
for (String v : users) {//再次遍历所有用户,对不是u的其他用户进行操作
if (!v.equals(u)) {
if (!CFMatrix.get(u).containsKey(v)) {
CFMatrix.get(u).put(v, 0);
}
CFMatrix.get(u).put(v, CFMatrix.get(u).get(v) + 1);
}
}
}
}
//还要返回num这个Map
return CFMatrix;
}
}现在得到了协同过滤矩阵,也就是每2个用户之间的共同交互物品数:
Map<String, Map<String, Integer>> CFMatrix
2.再来求第二个条件--每个用户所交互过的物品总数量
这个已经在第一遍顺手得出来了,就是这个num。
Map<String, Integer> num = new HashMap<>();
有了这2个条件后,就可以使用jaccard公式了
步骤二:根据协同过滤矩阵和每个用户所交互的物品总数求相似度-jaccard公式
很简单,直接套公式
package com.mycsdn.util.UserCF;
import java.util.HashMap;
import java.util.Map;
public class SimMatrix {
public static Map<String, Map<String, Double>> getSimMatrix(Map<String, Map<String, Integer>> CFMatrix, Map<String, Integer> num) {
Map<String, Map<String, Double>> sim =new HashMap<>();
System.out.println("构建用户相似度矩阵....");
for (Map.Entry<String, Map<String, Integer>> entry : CFMatrix.entrySet()) {//遍历协同过滤矩阵,遍历每个键值对
String u = entry.getKey();
Map<String, Integer> otherUser = entry.getValue();
for (Map.Entry<String, Integer> userScore : otherUser.entrySet()) {
String v = userScore.getKey();
int score = userScore.getValue();
if(!sim.containsKey(u))
{
sim.put(u,new HashMap<>());
}
sim.get(u).put(v, CFMatrix.get(u).get(v) / Math.sqrt(num.get(u) * num.get(v)));
}
}
return sim;
}
}
现在得到了 Map<String, Map<String, Double>> sim =new HashMap<>();
表示当前用户对应的其他用户以及其他用户与当前用户的相似度
接下来我们只需要取前k位用户,遍历这些用户的交互过的物品但是被推荐用户还没有交互过的物品进行计分
分数就是(用户相似度 *物品分数),这个物品分数因为我们博客项目是隐式计分,也就是没有对哪篇博客进行过打分,所以交互过的博客都是1分。
也就是说,每篇博客的推荐指数就是被交互过的用户的相似度之和
代码:
package com.mycsdn.util.UserCF;
import java.util.*;
public class Recommend {
public static Set<Integer> recommendForUser(Map<String, Map<String, Double>> sim,
Map<String, Set<Integer>> valUserItem,
int K, int N, String targetUser) {
System.out.println("给测试用户进行推荐....");
Map<Integer, Double> itemRank = new HashMap<>();
if (valUserItem.containsKey(targetUser)) {
Set<Integer> items = valUserItem.get(targetUser);
// sim[u] 的格式为 {user_id: similarity,....}
// 按照相似度进行排序,然后取前 K 个
List<Map.Entry<String, Double>> sortedSim = new ArrayList<>(sim.get(targetUser).entrySet());
Collections.sort(sortedSim, new Comparator<Map.Entry<String, Double>>() {
public int compare(Map.Entry<String, Double> o1, Map.Entry<String, Double> o2) {
return Double.compare(o2.getValue(), o1.getValue());
}
});
System.out.println("检查对相似度矩阵排序后的矩阵");
for (Map.Entry<String, Double> entry : sortedSim) {
String item = entry.getKey();
Double similarity = entry.getValue();
System.out.println("用户 " + item + ", 相似度: " + similarity);
}
for (int i = 0; i < K; i++) {
//前k个相似度高的用户
if (i >= sortedSim.size())
break;
String similarUser = sortedSim.get(i).getKey();
double score = sortedSim.get(i).getValue();
// 找出相似用户中有交互的物品,但当前用户并未交互过的物品进行推荐
for (int item : valUserItem.get(similarUser)) {
if (valUserItem.get(targetUser).contains(item))//如果用户已经对该物品交互过,就不用再推荐
continue;
itemRank.put(item, itemRank.getOrDefault(item, 0.0) + score);
//这里就得到的推荐候选的一个集合
}
}
}
// 根据评分进行排序,取排名靠前的 N 个物品作为推荐列表
List<Map.Entry<Integer, Double>> topNItems = new ArrayList<>(itemRank.entrySet());
Collections.sort(topNItems, new Comparator<Map.Entry<Integer, Double>>() {
public int compare(Map.Entry<Integer, Double> o1, Map.Entry<Integer, Double> o2) {
return Double.compare(o2.getValue(), o1.getValue());
}
});
Set<Integer> recommendedItems = new HashSet<>();
for (int i = 0; i < Math.min(N, topNItems.size()); i++) {
recommendedItems.add(topNItems.get(i).getKey());
}
return recommendedItems;
}
}至此,我们已经得到了被推荐的物品的id集合
Set<Integer> recommendedItems;
只要根据id查出对应的物品再返回前端,前端进行渲染即可。
缺点:
项目建立之初,还未收集足够的用户信息,协同过滤算法不能为指定用户找到合适的邻居,从而无法向用户提供推荐预测。
对于新注册的用户由于系统里没有他们的历史数据信息,所以协同过滤算法也无法为新用户推荐商品。
对于冷门的商品,可能从未被评过分,比如新加进的商品或者是比较小众的商品,它们也是不可能会被推荐给用户的。
如果是在写音乐播放器或者电影播放器,请移步基于物品的协同过滤算法