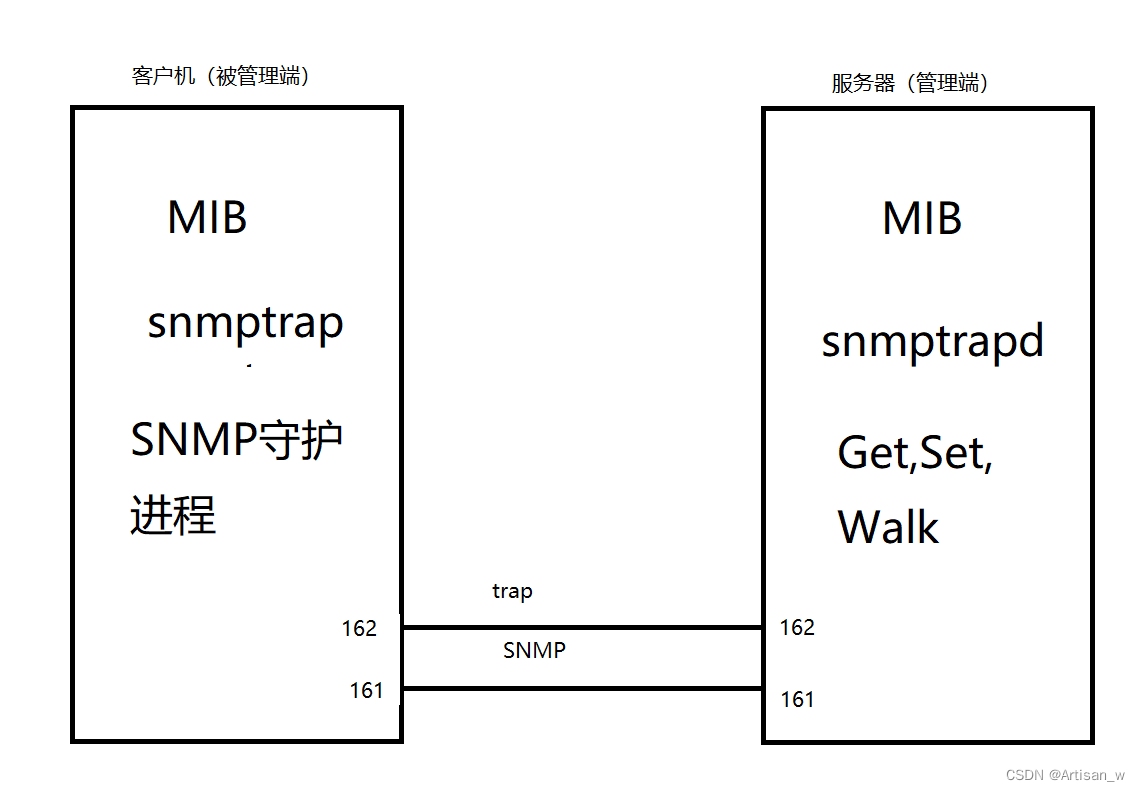
强化学习A3C算法
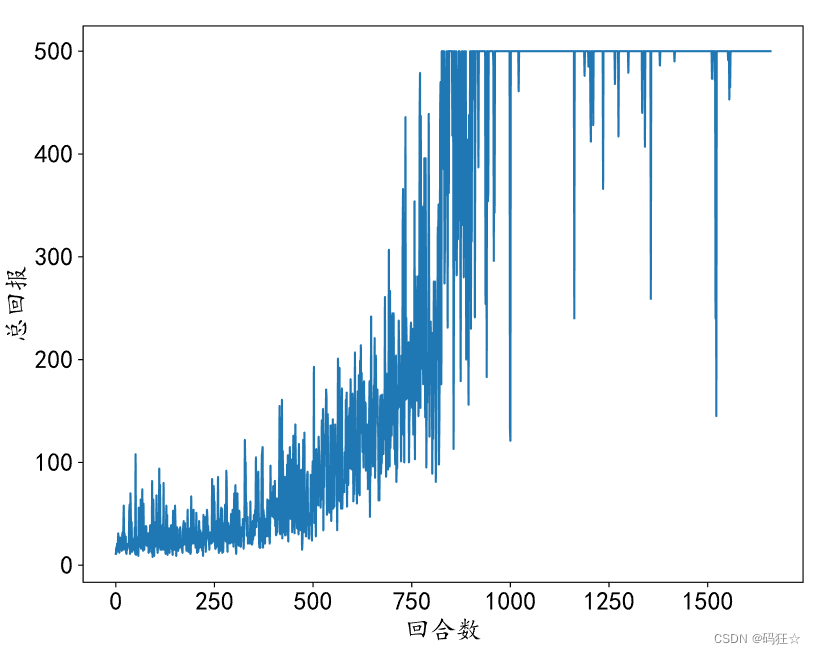
效果:
a3c.py
import matplotlib
from matplotlib import pyplot as plt
matplotlib.rcParams['font.size'] = 18
matplotlib.rcParams['figure.titlesize'] = 18
matplotlib.rcParams['figure.figsize'] = [9, 7]
matplotlib.rcParams['font.family'] = ['KaiTi']
matplotlib.rcParams['axes.unicode_minus']=False
plt.figure()
import os
import threading
import gym
import multiprocessing
import numpy as np
from queue import Queue
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers,optimizers,losses
# os.environ["CUDA_VISIBLE_DEVICES"] = "0" #使用GPU
# 按需占用GPU显存
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# 设置 GPU 显存占用为按需分配,增长式
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e :
# 异常处理
print(e)
SEED_NUM = 1234
tf.random.set_seed(SEED_NUM)
np.random.seed(SEED_NUM)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
# 互斥锁,用于线程同步数据
g_mutex = threading.Lock()
class ActorCritic(keras.Model):
""" Actor-Critic模型 """
def __init__(self, state_size, action_size):
super(ActorCritic, self).__init__()
self.state_size = state_size # 状态向量长度
self.action_size = action_size # 动作数量
# 策略网络Actor
self.dense1 = layers.Dense(128, activation='relu')
self.policy_logits = layers.Dense(action_size)
# V网络Critic
self.dense2 = layers.Dense(128, activation='relu')
self.values = layers.Dense(1)
def call(self, inputs):
# 获得策略分布Pi(a|s)
x = self.dense1(inputs)
logits = self.policy_logits(x)
# 获得v(s)
v = self.dense2(inputs)
values = self.values(v)
return logits, values
def record(episode,
episode_reward,
worker_idx,
global_ep_reward,
result_queue,
total_loss,
num_steps):
""" 统计工具函数 """
if global_ep_reward == 0:
global_ep_reward = episode_reward
else:
global_ep_reward = global_ep_reward * 0.99 + episode_reward * 0.01
print(
f"{episode} | "
f"Average Reward: {int(global_ep_reward)} | "
f"Episode Reward: {int(episode_reward)} | "
f"Loss: {int(total_loss / float(num_steps) * 1000) / 1000} | "
f"Steps: {num_steps} | "
f"Worker: {worker_idx}"
)
result_queue.put(global_ep_reward) # 保存回报,传给主线程
return global_ep_reward
class Memory:
""" 数据 """
def __init__(self):
self.states = []
self.actions = []
self.rewards = []
def store(self, state, action, reward):
self.states.append(state)
self.actions.append(action)
self.rewards.append(reward)
def clear(self):
self.states = []
self.actions = []
self.rewards = []
class Agent:
""" 智能体,包含了中央参数网络server """
def __init__(self):
# 服务模型优化器,client不需要,直接从server拉取参数
self.opt = optimizers.Adam(1e-3)
# 服务模型(状态向量,动作数量)
self.server = ActorCritic(4, 2)
self.server(tf.random.normal((2, 4)))
def train(self):
# 共享队列,线程安全,不需要加锁同步
res_queue = Queue()
# 根据cpu线程数量创建多线程Worker
workers = [Worker(self.server, self.opt, res_queue, i)
for i in range(10)] #multiprocessing.cpu_count()
# 启动多线程Worker
for i, worker in enumerate(workers):
print("Starting worker {}".format(i))
worker.start()
# 统计并绘制总回报曲线
returns = []
while True:
reward = res_queue.get()
if reward is not None:
returns.append(reward)
else: # 结束标志
break
# 等待线程退出
[w.join() for w in workers]
print(returns)
plt.figure()
plt.plot(np.arange(len(returns)), returns)
# plt.plot(np.arange(len(moving_average_rewards)), np.array(moving_average_rewards), 's')
plt.xlabel('回合数')
plt.ylabel('总回报')
plt.savefig('a3c-tf-cartpole.svg')
class Worker(threading.Thread):
def __init__(self, server, opt, result_queue, idx):
super(Worker, self).__init__()
self.result_queue = result_queue # 共享队列
self.server = server # 服务模型
self.opt = opt # 服务优化器
self.client = ActorCritic(4, 2) # 线程私有网络
self.worker_idx = idx # 线程id
self.env = gym.make('CartPole-v1').unwrapped #私有环境
self.ep_loss = 0.0
def run(self):
# 每个worker自己维护一个memory
mem = Memory()
# 1回合最大500步
for epi_counter in range(500):
# 复位client游戏状态
current_state,info = self.env.reset(seed=SEED_NUM)
mem.clear()
ep_reward = 0.0
ep_steps = 0
done = False
while not done:
# 输入AC网络状态获得Pi(a|s),未经softmax
logits, _ = self.client(tf.constant(current_state[None, :],dtype=tf.float32))
# 归一化概率
probs = tf.nn.softmax(logits)
# 随机采样动作
action = np.random.choice(2, p=probs.numpy()[0])
# 交互
new_state, reward, done, truncated, info = self.env.step(action)
# 累加奖励
ep_reward += reward
# 记录
mem.store(current_state, action, reward)
# 计算回合步数
ep_steps += 1
# 刷新状态
current_state = new_state
# 最长500步或者规则结束,回合结束
if ep_steps >= 500 or done:
# 计算当前client上的误差
with tf.GradientTape() as tape:
total_loss = self.compute_loss(done, new_state, mem)
# 计算梯度
grads = tape.gradient(total_loss, self.client.trainable_weights)
# 梯度提交到server,在server上更新梯度
global g_mutex
g_mutex.acquire()
self.opt.apply_gradients(zip(grads,self.server.trainable_weights))
g_mutex.release()
# 从server拉取最新的梯度
g_mutex.acquire()
self.client.set_weights(self.server.get_weights())
g_mutex.release()
# 清空Memory
mem.clear()
# 统计此回合回报
self.result_queue.put(ep_reward)
print(f"thread worker_idx : {self.worker_idx}, episode reward : {ep_reward}")
break
# 线程结束
self.result_queue.put(None)
def compute_loss(self,
done,
new_state,
memory,
gamma=0.99):
if done:
reward_sum = 0. # 终止状态的v(终止)=0
else:
# 私有网络根据新状态计算回报
reward_sum = self.client(tf.constant(new_state[None, :],dtype=tf.float32))[-1].numpy()[0]
# 统计折扣回报
discounted_rewards = []
for reward in memory.rewards[::-1]: # reverse buffer r
reward_sum = reward + gamma * reward_sum
discounted_rewards.append(reward_sum)
discounted_rewards.reverse()
# 输入AC网络环境状态获取 Pi(a|s) v(s) 预测值
logits, values = self.client(tf.constant(np.vstack(memory.states), dtype=tf.float32))
# 计算advantage = R() - v(s) = 真实值 - 预测值
advantage = tf.constant(np.array(discounted_rewards)[:, None], dtype=tf.float32) - values
# Critic网络损失
value_loss = advantage ** 2
# 归一化概率预测值Pi(a|s)
policy = tf.nn.softmax(logits)
# 真实动作a 概率预测值Pi(a|s) 交叉熵
policy_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=memory.actions, logits=logits)
# 计算策略网络损失时,并不会计算V网络
policy_loss = policy_loss * tf.stop_gradient(advantage)
# 动作概率测值Pi(a|s) 熵
entropy = tf.nn.softmax_cross_entropy_with_logits(labels=policy, logits=logits)
policy_loss = policy_loss - 0.01 * entropy
# 聚合各个误差
total_loss = tf.reduce_mean((0.5 * value_loss + policy_loss))
return total_loss
if __name__ == '__main__':
master = Agent()
master.train()