一、介绍
你有没有想过数据是如何压缩、传输和重建的?自动编码器是人工智能世界中一个引人入胜的概念,它正是实现这一目标的。想象一下,一个神奇的盒子,它接受复杂的信息,压缩成简化的形式,然后把它恢复到原来的形状——就像科幻电影中的神奇运输车一样。在本文中,我们将揭开自动编码器的奥秘,并提供一个简单的分步指南来从头开始编写自动编码器。
二、什么是自动编码器?
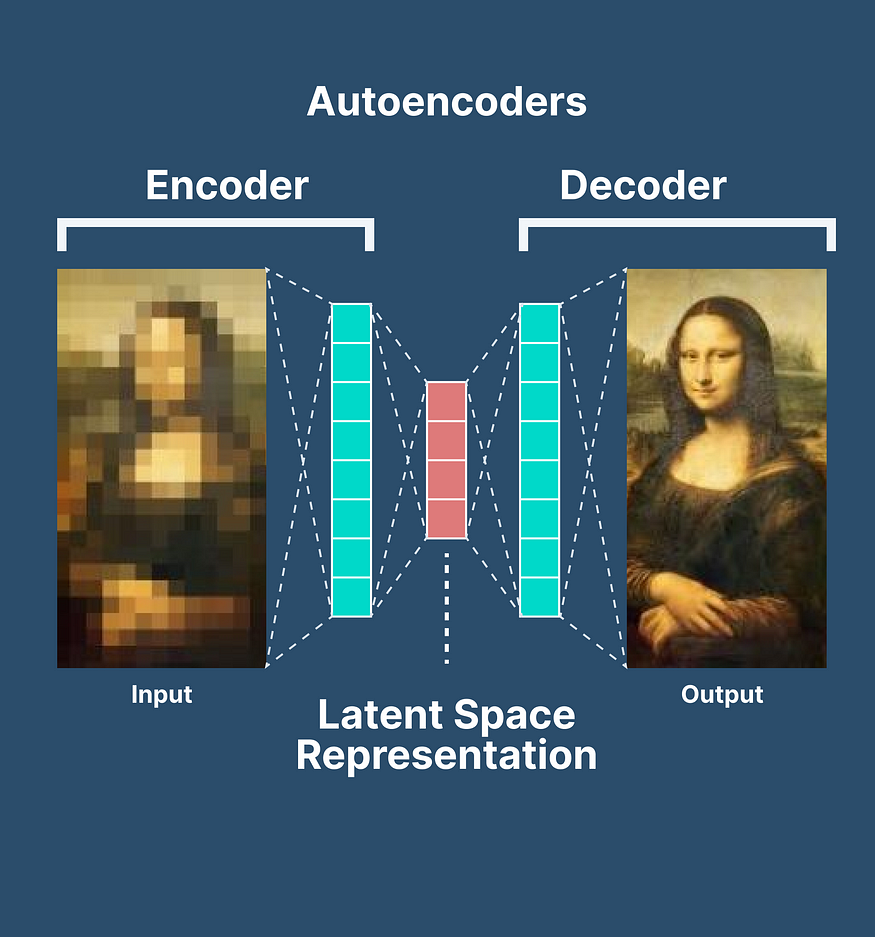
自动编码器是一种神经网络架构,这是一种奇特的说法,它们是一组以特定方式排列的数学运算。自动编码器的主要目的是降低数据的维度。简单来说,它们采用大型和复杂的输入,并将它们转换为更小、更易于管理的表示形式,类似于将照片压缩成更小的文件大小。
自动编码器由两个主要组件组成:
- 编码器:自动编码器的这一部分负责将输入数据压缩为低维表示形式。它捕获输入的最重要特征,同时丢弃不太相关的细节。
2. 解码器:解码器从编码器获取压缩表示,并尝试从中重建原始输入。它就像编码器的反面,因为它将压缩数据扩展回其原始形式。
编码器和解码器协同工作,以创建高效的数据压缩和重建系统。
三、从头开始编写自动编码器
为了更好地理解自动编码器,让我们使用 Python 和流行的深度学习库 TensorFlow 从头开始创建一个简单的编码器。如果您不熟悉编程,请不要担心;我们将用简单的术语解释每个步骤。
步骤 1:导入所需的库
我们需要 TensorFlow 来构建神经网络,所以让我们导入它:
import tensorflow as tf
步骤 2:定义自动编码器体系结构
现在,我们将创建编码器和解码器层。为简单起见,假设我们正在处理灰度图像,每个图像为 28x28 像素(总共 784 像素)。我们的自动编码器会将此图像压缩为32维表示,然后将其重建回原始的784像素。
# Input layer
input_layer = tf.keras.layers.Input(shape=(784,))
# Encoder
encoded = tf.keras.layers.Dense(32, activation='relu')(input_layer)
# Decoder
decoded = tf.keras.layers.Dense(784, activation='sigmoid')(encoded)步骤 3:将编码器和解码器组合成自动编码器模型
autoencoder = tf.keras.models.Model(input_layer, decoded)步骤 4:编译模型
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')步骤 5:训练自动编码器
若要训练自动编码器,需要一个数据集,其中包含要压缩和重建的图像或任何其他类型的数据。在此示例中,我们将使用 MNIST 数据集,该数据集由手写数字组成。
# Load the MNIST dataset
(x_train, _), (x_test, _) = tf.keras.datasets.mnist.load_data()
# Normalize and flatten the data
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
x_train = x_train.reshape((len(x_train), 784))
x_test = x_test.reshape((len(x_test), 784))
# Train the autoencoder
autoencoder.fit(x_train, x_train, epochs=10, batch_size=256, shuffle=True)步骤 6:评估自动编码器
让我们看看我们的自动编码器如何压缩和重建测试图像。
reconstructed_images = autoencoder.predict(x_test)四、结论
自动编码器是巧妙的神经网络架构,提供数据压缩和重建功能。它们由一个用于压缩数据的编码器和一个用于将其重建回原始形式的解码器组成。从头开始构建自动编码器并不像看起来那么令人生畏,您可以将其用于各种应用程序,从图像压缩到异常检测。
因此,下次您考虑数据压缩和重建时,请记住自动编码器在幕后工作的魔力!
Visheshtaposthali









![[Go版]算法通关村第十二关青铜——不简单的字符串转换问题](https://img-blog.csdnimg.cn/516ee25c89ae4cfd9e217d9c709f16ed.png)