生成对抗网络的概念
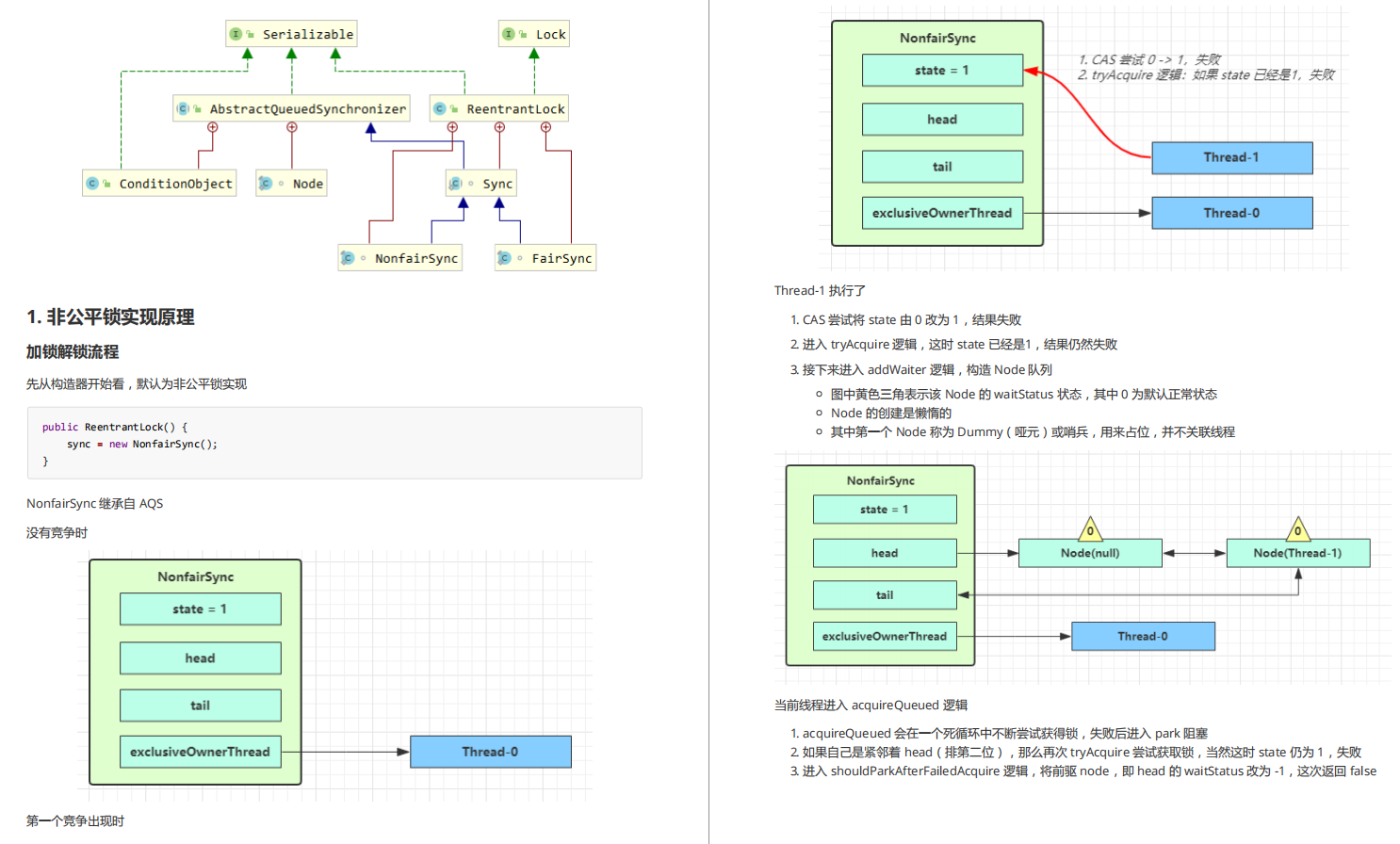
最基本的GAN模型由一个生成器 G 和判别器 D 组成。生成器用于生成假样本,判别器用于判断样本是真实的还是假的。
- 生成器(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器
- 判别器(Discriminator):判断这张图像是真实的还是机器生成的,目的是找出生成器做的“假数据”
首先,固定判别器D,训练生成器G。让生成器不断生成假数据,然后让判别器D去判断,一开始生成器G生成的结果很容易被判别器D识别,然而随着不断的训练,生成器G效果不断提升,直到判别器无法分辩出数据的真假,也就是说这时判别器判断真假数据的概率为0.5.
然后固定生成器G,训练判别器D。当判别器无法分辩生成器生成的数据的时候,这时继续训练生成器是没有意义的。这时,可以训练判别器D,提升判别器D的性能。
数据集的显示
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision import datasets
transforms=transforms.Compose(
[
transforms.Resize(28),
transforms.ToTensor(),
# transforms.Normalize([0.5],[0.5]) ##均值,标准差
]
)
train_datasets=datasets.MNIST(root='./',train=True,download=True,transform=transforms)
test_datasets=datasets.MNIST(root='./',train=False,download=True,transform=transforms)
print('训练集的数量',len(train_datasets))
print('测试集的数量',len(test_datasets))
train_loader = DataLoader(train_datasets, batch_size=100, shuffle=True)
test_loader = DataLoader(test_datasets, batch_size=1, shuffle=False)
print('训练集可视化')
fig=plt.figure()
for i in range(12):
plt.subplot(3,4,i+1)
img=train_datasets.train_data[i]
label=train_datasets.train_labels[i]
plt.imshow(img,cmap='gray')
plt.title(label)
plt.xticks([])
plt.yticks([])
plt.show()
print('测试集可视化')
fig=plt.figure()
for i in range(12):
plt.subplot(3,4,i+1)
img=test_datasets.test_data[i]
label=test_datasets.test_labels[i]
plt.imshow(img,cmap='gray')
plt.title(label)
plt.xticks([])
plt.yticks([])
plt.show()
网络结构
import numpy as np
import argparse
import torch.nn as nn
import torch
parser = argparse.ArgumentParser()
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
opt = parser.parse_args()
class Generator(nn.Module):
"""
生成器,根据一组随机的向量生成一组图像
"""
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8)) #BatchNorm:在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布,momentum=0.8
layers.append(nn.LeakyReLU(0.2, inplace=True)) #inplace = True ,直接覆盖原输入数据的值
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False), #opt.latent_dim,100维的随机噪声
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod((opt.channels, opt.img_size, opt.img_size)))), #np.prod(img_shape),返回1*28*28
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
# img = img.view(img.size()[0], *(opt.channels, opt.img_size, opt.img_size))
img=img.view(img.size()[0],opt.channels,opt.img_size,opt.img_size)
return img
class Discriminator(nn.Module):
"""
判别器是用来判断生成器生成图片的真假,判别器效果越真越好,直到最后判别无法判别生成器的输出(即输出概率为0.5的时候)
"""
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod((opt.channels, opt.img_size, opt.img_size))), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# model=Discriminator()
# input=torch.rand(10,int(np.prod((opt.channels, opt.img_size, opt.img_size))))
# output=model(input)
# print('判别器的输出',output.shape)
#
# model=Generator()
# input=torch.rand(10,100)
# output=model(input)
# print('生成器的输出',output.shape)
模型的训练
先训练判别器,在训练生成器
import argparse
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision import datasets
import torch
from model import Generator,Discriminator
parser = argparse.ArgumentParser() #创建一个参数对象
#调用 add_argument() 方法给 ArgumentParser对象添加程序所需的参数信息
parser.add_argument("--n_epochs", type=int, default=50, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=128, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
opt = parser.parse_args() # parse_args()返回我们定义的参数字典
print(opt)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device',device)
transforms=transforms.Compose(
[
transforms.Resize(opt.img_size),
transforms.ToTensor(),
transforms.Normalize([0.5],[0.5]) ##均值,标准差
]
)
train_datasets=datasets.MNIST(root='./',train=True,download=True,transform=transforms)
lenth = 10000
train_datasets, _ = torch.utils.data.random_split(train_datasets, [lenth, len(train_datasets) - lenth])
# test_datasets=datasets.MNIST(root='./',train=False,download=True,transform=transforms)
print('训练集的数量',len(train_datasets))
# print('测试集的数量',len(test_datasets))
train_loader = DataLoader(train_datasets, batch_size=100, shuffle=True)
# test_loader = DataLoader(test_datasets, batch_size=1, shuffle=False)
# 损失函数
adversarial_loss = torch.nn.BCELoss().to(device)
# 定义网络结构
generator = Generator().to(device)
discriminator = Discriminator().to(device)
# 优化器的设置
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2)) #Betas是动量梯度的下降
for epoch in range(opt.n_epochs):
total_d_loss=0
total_g_loss=0
#开始训练
for i, (img, _) in enumerate(train_loader):
##将图片变为1维数据
real_img=img.view(img.size()[0],-1)
#定义真实的图片label为1
real_label=torch.ones(img.size()[0],1)
#定义假的图片label为0
fake_label=torch.zeros(img.size()[0],1)
#判别器训练
#将真实图片输入到判别器中
real_out=discriminator(real_img)
#得到真实图片的loss
d_loss_real=adversarial_loss(real_out,real_label)
#得到真实图片的判别值,real_out输出的值越接近1越好
real_scores=real_out
#计算假图片的损失
noise=torch.randn(img.size()[0],opt.latent_dim) ##随机生成一些噪声,
##将随机噪声放入生成网络中,生成一张假的图片
#避免梯度传到生成器,这里生成器不用更新,detach分离
fake_img=generator(noise).detach()
#判别器判断假的图片
fake_out=discriminator(fake_img)
#得到假图片的loss
d_loss_fake=adversarial_loss(fake_out,fake_label)
#得到假图片的判别值,对于判别器来讲,假图片的d_loss_fake越接近越好
d_loss=d_loss_real+d_loss_fake ##损失包含判真损失和判假损失
total_d_loss+=d_loss.data.item()
optimizer_D.zero_grad() #反向传播之前,将梯度归0
d_loss.backward() #将误差反向传播
optimizer_D.step() #更新参数
#训练生成器
#原理:目的是希望生成的假图片可以被判别器判断为真的图片
#在此过程中,将判别器固定,将假的图片传入判别器的结果real_label对应
#使得生成的图片让判别器以为是真的。这样就达到了对抗的目的
#计算假图片的损失
noise=torch.randn(img.size()[0],opt.latent_dim) #随机生成一些噪声
fake_img=generator(noise) ##随机噪声输入到生成器中,得到一幅假的图片
output=discriminator(fake_img) ##经过判别器得到的结果
g_loss=adversarial_loss(output,real_label)
total_g_loss+=g_loss.data.item()
#反向传播 更新参数
optimizer_G.zero_grad()
g_loss.backward()
optimizer_G.step()
#打印每个epoch 的损失
print('Epoch[{}/{}],d_loss:{:.6f},g_loss:{:.6f}'.format(epoch,opt.n_epochs,total_d_loss/len(train_loader),total_g_loss/len(train_loader)))
torch.save(generator,'./gen.pth')
torch.save(discriminator,'./dis.pth')先训练生成器,在训练判别器
import argparse
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision import datasets
import torch
from model import Generator,Discriminator
parser = argparse.ArgumentParser() #创建一个参数对象
#调用 add_argument() 方法给 ArgumentParser对象添加程序所需的参数信息
parser.add_argument("--n_epochs", type=int, default=10, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=128, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
opt = parser.parse_args() # parse_args()返回我们定义的参数字典
print(opt)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device',device)
transforms=transforms.Compose(
[
transforms.Resize(opt.img_size),
transforms.ToTensor(),
transforms.Normalize([0.5],[0.5]) ##均值,标准差
]
)
train_datasets=datasets.MNIST(root='./',train=True,download=True,transform=transforms)
# lenth = 60000
# train_datasets, _ = torch.utils.data.random_split(train_datasets, [lenth, len(train_datasets) - lenth])
# test_datasets=datasets.MNIST(root='./',train=False,download=True,transform=transforms)
print('训练集的数量',len(train_datasets))
# print('测试集的数量',len(test_datasets))
train_loader = DataLoader(train_datasets, batch_size=opt.batch_size, shuffle=True)
# test_loader = DataLoader(test_datasets, batch_size=1, shuffle=False)
# 损失函数
adversarial_loss = torch.nn.BCELoss().to(device)
# 定义网络结构
generator = Generator().to(device)
discriminator = Discriminator().to(device)
# 优化器的设置
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2)) #Betas是动量梯度的下降
for epoch in range(opt.n_epochs):
total_d_loss=0
total_g_loss=0
#开始训练
for i, (img, _) in enumerate(train_loader):
##将图片变为1维数据
real_img=img.view(img.size()[0],-1)
#定义真实的图片label为1
real_label=torch.ones(img.size()[0],1)
#定义假的图片label为0
fake_label=torch.zeros(img.size()[0],1)
#训练生成器
#原理:目的是希望生成的假图片可以被判别器判断为真的图片
#在此过程中,将判别器固定,将假的图片传入判别器的结果real_label对应
#使得生成的图片让判别器以为是真的。这样就达到了对抗的目的
#计算假图片的损失
noise=torch.randn(img.size()[0],opt.latent_dim) #随机生成一些噪声
fake_img=generator(noise).detach() ##随机噪声输入到生成器中,得到一幅假的图片
output=discriminator(fake_img) ##经过判别器得到的结果
g_loss=adversarial_loss(output,real_label)
total_g_loss+=g_loss.data.item()
#反向传播 更新参数
optimizer_G.zero_grad()
g_loss.backward()
optimizer_G.step()
#判别器训练
#将真实图片输入到判别器中
real_out=discriminator(real_img)
#得到真实图片的loss
d_loss_real=adversarial_loss(real_out,real_label)
#计算假图片的损失
noise=torch.randn(img.size()[0],opt.latent_dim) ##随机生成一些噪声,
##将随机噪声放入生成网络中,生成一张假的图片
#避免梯度传到生成器,这里生成器不用更新,detach分离
fake_img=generator(noise).detach()
#判别器判断假的图片
fake_out=discriminator(fake_img)
#得到假图片的loss
d_loss_fake=adversarial_loss(fake_out,fake_label)
#得到假图片的判别值,对于判别器来讲,假图片的d_loss_fake越接近越好
d_loss=d_loss_real+d_loss_fake ##损失包含判真损失和判假损失
total_d_loss+=d_loss.data.item()
optimizer_D.zero_grad() #反向传播之前,将梯度归0
d_loss.backward() #将误差反向传播
optimizer_D.step() #更新参数
#打印每个epoch 的损失
print('Epoch[{}/{}],d_loss:{:.6f},g_loss:{:.6f}'.format(epoch,opt.n_epochs,total_d_loss/len(train_loader),total_g_loss/len(train_loader)))
torch.save(generator,'./gen.pth')
torch.save(discriminator,'./dis.pth')模型的测试
import argparse
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision import datasets
import torch
import matplotlib.pyplot as plt
import numpy as np
parser = argparse.ArgumentParser() #创建一个参数对象
#调用 add_argument() 方法给 ArgumentParser对象添加程序所需的参数信息
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
opt = parser.parse_args() # parse_args()返回我们定义的参数字典
print(opt)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device',device)
transforms=transforms.Compose(
[
transforms.Resize(opt.img_size),
transforms.ToTensor(),
transforms.Normalize([0.5],[0.5]) ##均值,标准差
]
)
train_datasets=datasets.MNIST(root='./',train=True,download=True,transform=transforms)
lenth = 10000
train_datasets, _ = torch.utils.data.random_split(train_datasets, [lenth, len(train_datasets) - lenth])
test_datasets=datasets.MNIST(root='./',train=False,download=True,transform=transforms)
print('训练集的数量',len(train_datasets))
# print('测试集的数量',len(test_datasets))
train_loader = DataLoader(train_datasets, batch_size=100, shuffle=True)
# test_loader = DataLoader(test_datasets, batch_size=1, shuffle=False)
# 损失函数
adversarial_loss = torch.nn.BCELoss().to(device)
# 定义网络结构
generator = torch.load('./gen.pth',map_location=lambda storage, loc: storage)
discriminator = torch.load('./dis.pth',map_location=lambda storage, loc: storage)
noise=torch.randn(12,opt.latent_dim)
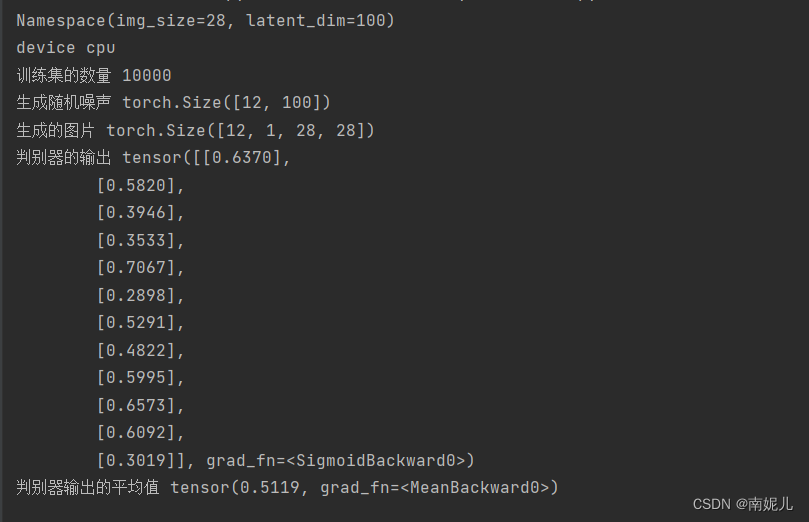
print('生成随机噪声',noise.shape)
image=generator(noise)
print('生成的图片',image.shape)
##判别器进行判断
output=discriminator(image)
#判别器判定大于0.5为真,小于0.5为假。所以判别器最好的结果是为0.5,即分不清楚真假
print('判别器的输出',output)
print('判别器输出的平均值',torch.mean(output))
for i in range(12):
plt.subplot(3,4,i+1)
img=image[i].reshape(28,28)
plt.imshow(np.array(img.data),cmap='gray')
plt.xticks([])
plt.yticks([])
plt.show()
 参考文献:
参考文献:
基于Pytorch用GAN生成手写数字实例(附代码)_使者大牙的博客-CSDN博客_gan生成手写数字 pytorch
GAN学习总结三-Pytorch实现利用GAN进行MNIST手写数字生成_DaneAI的博客-CSDN博客_plt.rcparams['figure.figsize'] = (10.0, 8.0) # 设置画
【pytorch】基于mnist数据集的cgan手写数字生成实现_Xavier Jiezou的博客-CSDN博客_cgan mnist pytorch


![[附源码]Nodejs计算机毕业设计基于百度AI平台的财税报销系统Express(程序+LW)](https://img-blog.csdnimg.cn/ea2490126edb492da2222432b43eabcd.png)