一:Bounding-box regression回归
1.问题理解(为什么要做 Bounding-box regression? )如图 1 所示, 绿色的框为飞机的 Ground Truth, 红色的框是 Selective Search 提取的 Region Proposal。 那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准(IoU<0.5), 那么这张图相当于没有正确的检测出飞机。 如果我们能对红色的框进行微调, 使得经过微调后的窗口跟Ground Truth 更接近, 这样岂不是定位会更准确。 确实,Bounding-box regression 就是用来微调这个窗口的.

2.问题数学表达(回归/微调的对象是什么? )
对于窗口一般使用四维向量( , , , ) x y w h 来表示, 分别表示窗口的中心点坐标和宽高。 对于图 2, 红色的框 P 代表原始的
Proposal, 绿色的框 G 代表目标的 Ground Truth, 我们的目标是
寻找一种关系使得输入原始的窗口 P 经过映射得到一个跟真实
窗口 G 更接近的回归窗口

3.问题解决方案(Bounding-box regression)

二:fast-rcnn
一篇不错的文章:https://blog.csdn.net/wonder233/article/details/53671018 对各阶段原理进行了详细的描述
这里再用另一篇文章的总结来强调一下:RCNN学习笔记(4):fast rcnn
1.用selective search在一张图片中生成约2000个object proposal,即感兴趣区域RoI。
2.把它们整体输入到全卷积的网络中,在最后一个卷积层上对每个ROI求映射关系,并用一个RoI pooling layer来统一到相同的大小-> (fc)feature vector ,即->提取一个固定维度的特征表示。
3.继续经过两个全连接层(FC)得到特征向量。特征向量经由各自的FC层,得到两个输出向量:
第一个是分类,使用softmax,第二个是每一类的bounding box回归。
另外还有一个关于测试过程的总结也写得不错:Fast R-CNN论文详解
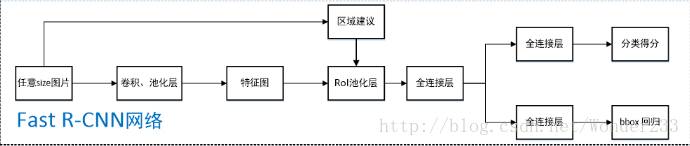
1、任意size图片输入CNN网络,经过若干卷积层与池化层,得到特征图;
2、在任意size图片上采用selective search算法提取约2k个建议框;
3、根据原图中建议框到特征图映射关系,在特征图中找到每个建议框对应的特征框【深度和特征图一致】,并在RoI池化层中将每个特征框池化到H×W【VGG-16网络是7×7】的size;/
4、固定H×W【VGG-16网络是7×7】大小的特征框经过全连接层得到固定大小的特征向量;
5、第4步所得特征向量经由各自的全连接层【由SVD分解实现】,分别得到两个输出向量:一个是softmax的分类得分,一个是Bounding-box窗口回归;/
6、利用窗口得分分别对每一类物体进行非极大值抑制剔除重叠建议框,最终得到每个类别中回归修正后的得分最高的窗口。
整体框架大致如上述所示了,对比SPP-Net,可以看出FRCN大致就是一个joint training版本的SPP-Net,改进如下:
SPP-Net在实现上无法同时tuning在SPP layer两边的卷积层和全连接层。
SPP-Net后面的需要将第二层FC的特征放到硬盘上训练SVM,之后再额外训练bbox regressor。
在这里我们不关注实现的具体的细节,主要对一些重要性的原理进行一些概括总结:
1:roi池话

区域建议窗口是在原图中得到的,只不过后续池话会导致窗口变小,然后根据这些小区域做分类和回归。

2:总的loss

二:faster-rcnn
这个网络与fast-rcnn网络的最大不同就是在区域的选择上,这个网络是在特征图上进行候选区域的选择。



至于RPN怎么实现的倒是不需要关注!
具体的实现细节可以参考:https://blog.csdn.net/Seven_year_Promise/article/details/60954553
这篇文章的作者是动脑子思考的。

可以看到这个网络结构瞬间增大了好多。
三:ssd&yolo
特征到类别最后分类或者回归的实现是单独的层,在代码最后还是有体现的。
---------------------
作者:runner668
来源:CSDN
原文:https://blog.csdn.net/runner668/article/details/80436850
版权声明:本文为博主原创文章,转载请附上博文链接!

![[C++]笔记-函数的栈空间(避免栈空间溢出)](https://img-blog.csdnimg.cn/cdb2ef309d7f4cd3a6e4d99918bcb5f5.png)