生物笔记——暑期学习笔记(四)
文章目录
- 前言
- 一、R篇
- 1. unname()
- 2. duplicated()
- 3. 数据提取
- 4. 分组
- 二、生信篇
- 1. 文本处理常用命令
- 2. 命令输出
- 1. 重定向
- 2. 多命令执行
- 3. 文本工具
- 4. 本地hmm鉴定
- 1. hmmer软件安装
- 2. 文件准备
- 3. 基于hmm的鉴定
- 总结
前言
这一系列文章主要是对于在暑期,老师每周教导的生信方面的课程的课后学习笔记的总结,希望用此方法来巩固我的所学。
一、R篇
1. unname()
x <- c(1,4,6.25)
> x
[1] 1.00 4.00 6.25
x[] <- 7
> x
[1] 7 7 7
x <- c('星'=55,"石"=88,"苑"=99)
> x
星 石 苑
55 88 99
#去掉列名
y<- unname(x)
> y
[1] 55 88 99
age <- c(8:88)
name <- paste("wht",seq(8,88))
age[c(3,5,7)]
age[age>15]
df <- cbind(age,name)
x <- df[,]
df <- read.table("D:/class.csv",header = TRUE,sep =",")
head(df)
name <- df[,"name"]
age <- df[,"age"]
head(age)
age1 <- age[c(3,5,7)]
age2 <- age[age>=15]
df1 <- df[df$name%in%c("Mary","James"),]
age3 <- df1[,c("name","age")]
df2<- df[!df$name%in%c("Mary","James"),]
age34 <- df2$age
cut(1:9,breaks = c(0,3,6,9)) #分割
cut(1:88,breaks=3)
table(df$sex)
str(df)
df$sex <- factor(df$sex,levels = c("F", "M"), labels = c("Female", "Male"))
str(df)
tapply(df$age,df$sex,max)
2. duplicated()
duplicated,翻译过来是重复的意思,所以它的用处是判断是否是重复元素,并返回布尔值(方便记忆)
intersect(c(5,7),c(1,5,2,5))
union(c(5,7),c(1,5,2,5))
setdiff(c(5,7),c(1,5,2,5)) #求差集,前一向量中不属于后面向量元素组成的集合
x <- c(6,9,8,6)
> duplicated(x)
[1] FALSE FALSE FALSE TRUE
> x[!duplicated(x)]
[1] 6 9 8
#或者直接使用unique()
> unique(x)
[1] 6 9 8
3. 数据提取
df <- read.table("D:/class.csv",header = TRUE,sep =",")
> head(df)
name sex age height weight
1 Alice F 13 56.5 84.0
2 Becka F 13 65.3 98.0
3 Gail F 14 64.3 90.0
4 Karen F 12 56.3 77.0
5 Kathy F 12 59.8 84.5
6 Mary F 15 66.5 112.0
name <- df[,"name"]
age <- df[,"age"]
#head(age)
age1 <- age[c(3,5,7)]
age2 <- age[age>=15]
#取出“Mary"和"James"对应的age
df1 <- df[df$name%in%c("Mary","James"),]
age3 <- df1[,c("name","age")]
> age3
name age
6 Mary 15
13 James 12
#取出其他人的
df2<- df[!df$name%in%c("Mary","James"),]
age4 <- df2[,c("name","age")]
4. 分组
#分割,通过对breaks参数的设置,来分割连续性变量
> cut(1:9,breaks = c(0,3,6,9))
[1] (0,3] (0,3] (0,3] (3,6] (3,6] (3,6] (6,9] (6,9] (6,9]
Levels: (0,3] (3,6] (6,9]
cut(1:88,breaks=3)
> table(df$sex)
F M
9 10
> str(df)
'data.frame': 19 obs. of 5 variables:
$ name : chr "Alice" "Becka" "Gail" "Karen" ...
$ sex : chr "F" "F" "F" "F" ...
$ age : int 13 13 14 12 12 15 11 15 14 14 ...
$ height: num 56.5 65.3 64.3 56.3 59.8 66.5 51.3 62.5 62.8 69 ...
$ weight: num 84 98 90 77 84.5 ...
#将sex变量转换为因子类型,方便分组
df$sex <- factor(df$sex,levels = c("F", "M"), labels = c("Female", "Male"))
#通过对labels参数的设置,改变因子的名称
> str(df)
'data.frame': 19 obs. of 5 variables:
$ name : chr "Alice" "Becka" "Gail" "Karen" ...
$ sex : Factor w/ 2 levels "Female","Male": 1 1 1 1 1 1 1 1 1 2 ...
$ age : int 13 13 14 12 12 15 11 15 14 14 ...
$ height: num 56.5 65.3 64.3 56.3 59.8 66.5 51.3 62.5 62.8 69 ...
$ weight: num 84 98 90 77 84.5 ...
#根据sex分组并对于age求最大值
> tapply(df$age,df$sex,max)
Female Male
15 16
二、生信篇
1. 文本处理常用命令
less命令
打开并查看文件内容, less -SN (按行查看),按 q 退出 ; 支持直接查看压缩文件
示例: less -SN example.axt

wc 命令
简单统计文件内容
-c 只显示 字节数
-l 只显示行数
-w 只显示字数
$ wc example.axt
4 3 1755 example.axt
$ wc -c example.axt
1755 example.axt
$ wc -l example.axt
4 example.axt
$ wc -w example.axt
example.axt
可以得知该文件中的字节数为1755,行数为4,字数(是一个文本中的单词数量。在计算字数时,通常以空格或其他标点符号作为单词之间的分隔符)为3.
diff 命令
比较两个文件的不同
-a :只逐行比较文本文件
-b :忽略空格
-B :忽略空行
-c :显示全部内容,并标出不同之处
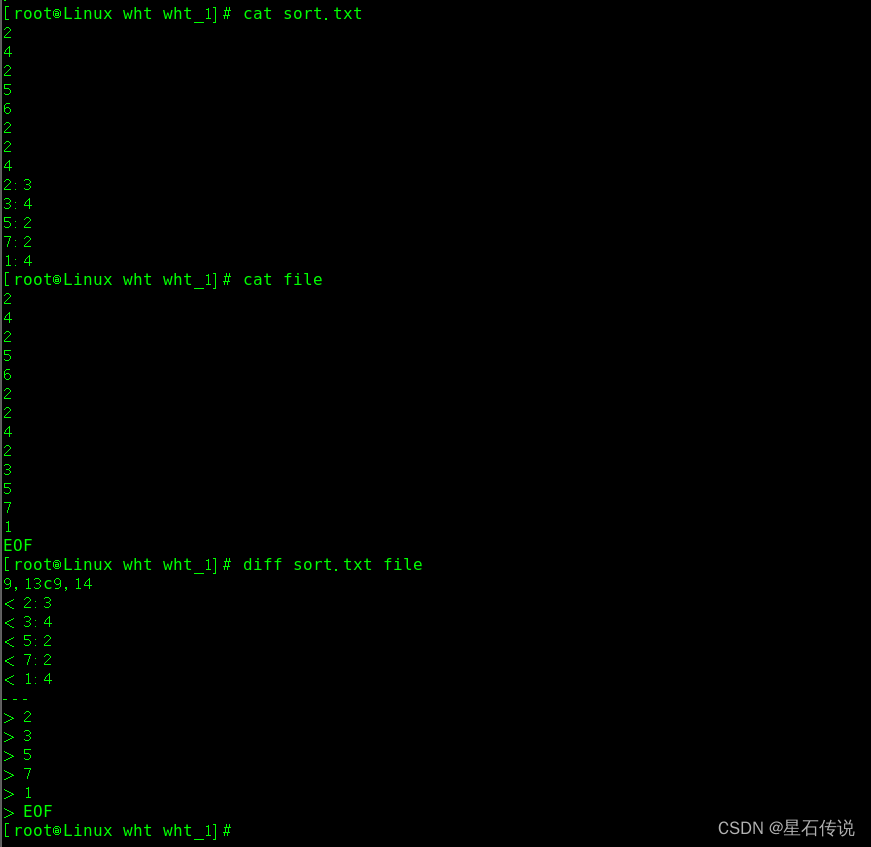
比如,我比较了一下sort.txt 和 file 两个文件。第一行的"9,13c9,14" 表示的是前一个文件的9到13行与后面文件的9到14行是不同的。
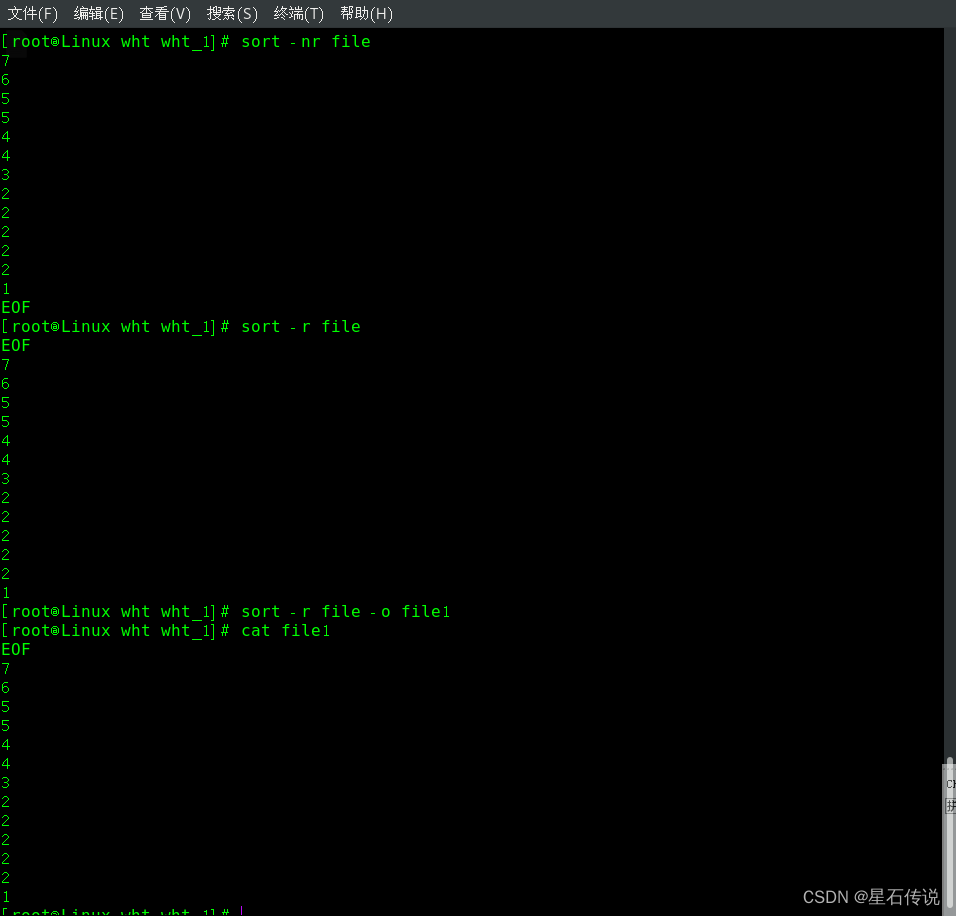
sort 命令
-r :降序输出
-n :以数值来排序
-o :输出到新文件
uniq 命令
比较相邻的行,显示不重复的行
-i :忽略大小写
-c :计数
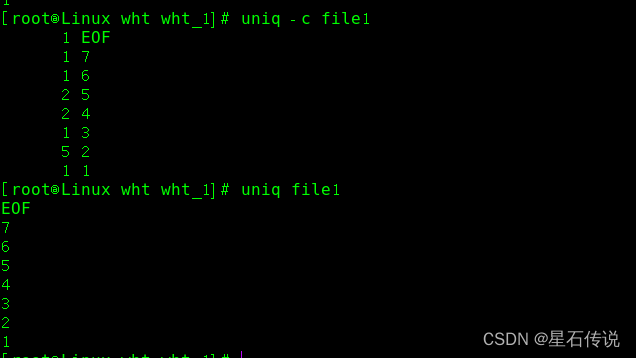
命令 练习

2. 命令输出
1. 重定向
> 代表以覆盖的方式,将输出内容写入到指定文件
>> 代表以追加方式输出
命令 >> 文件 A 2>> 文件 B :正确的输出到 A 文件中,错误的输出到 B 文件中

2. 多命令执行
命令 1 ;命令 2 (两个命令互不干扰)
命令 1 && 命令 2 (只有前者执行,后者才能执行)
命令 1|| 命令 2 (只要前者能执行,后者就不执行;前者不执行,后者就顶上)
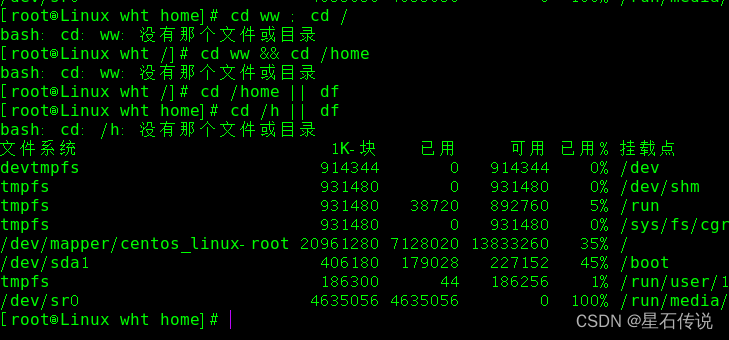
3. 文本工具
grep 、 sed 、awk
有关更多信息,请看
Linux中文本工具应用(Linux入门六)
4. 本地hmm鉴定
1. hmmer软件安装
mamba 是一个基于 Python 的 CLI 工具,被认为是 conda 的直接替代品,自带多线程下载,可以提高下载速度。
首先安装mamba
安装过程推荐:https://zhuanlan.zhihu.com/p/489499097?utm_id=0
# 创建一个新环境”wht_env1"并安装 iqtree软件
mamba create -n wht_env1 iqtree
安装完成:
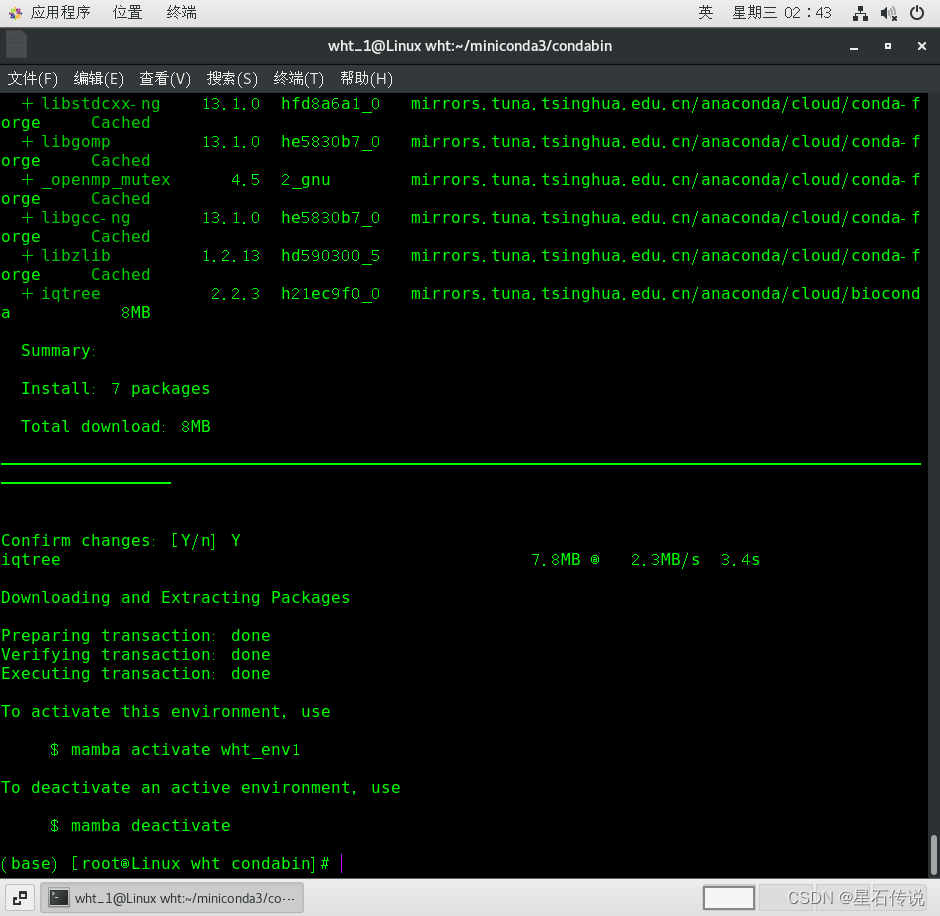
#安装hmmer软件
mamba create -n wht_env2 hmmer
通过mamba安装的软件通常会安装到Conda环境的envs目录下( 安装时设置了环境)
2. 文件准备
hmm 模型文件 : 如 PF03936.hmm
fasta格式的AA序列文件 : 如 Lindera_aggregata.gene.pep
3. 基于hmm的鉴定
hmmsearch /home/PF03936.hmm /home/Lindera_aggregata.gene.pep >/home/Lagg.PF03936.out

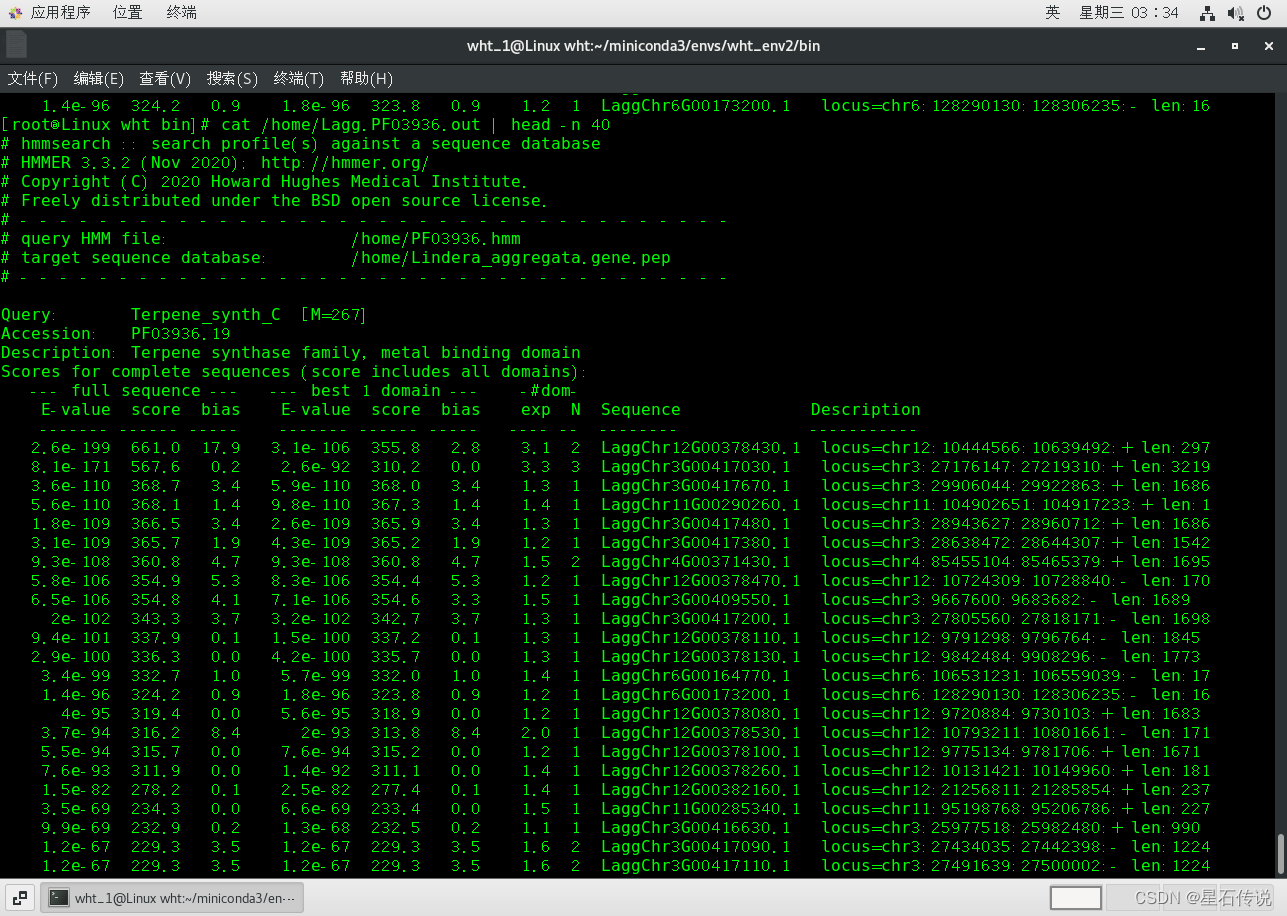
总结
本文的R篇主要讲了unname()、duplicated()、因子分组等。生信篇则介绍了一些在Linux中的简单操作命令。同时也学会了根据mamba管理器来下载所需软件,如用于hmm鉴定的hmmer软件等。
两情若是久长时,又岂在朝朝暮暮。
–2023-8-16






![[机器学习]特征工程:主成分分析](https://img-blog.csdnimg.cn/img_convert/29d4c948ca9d9f2770c6e926a210d0b2.png)