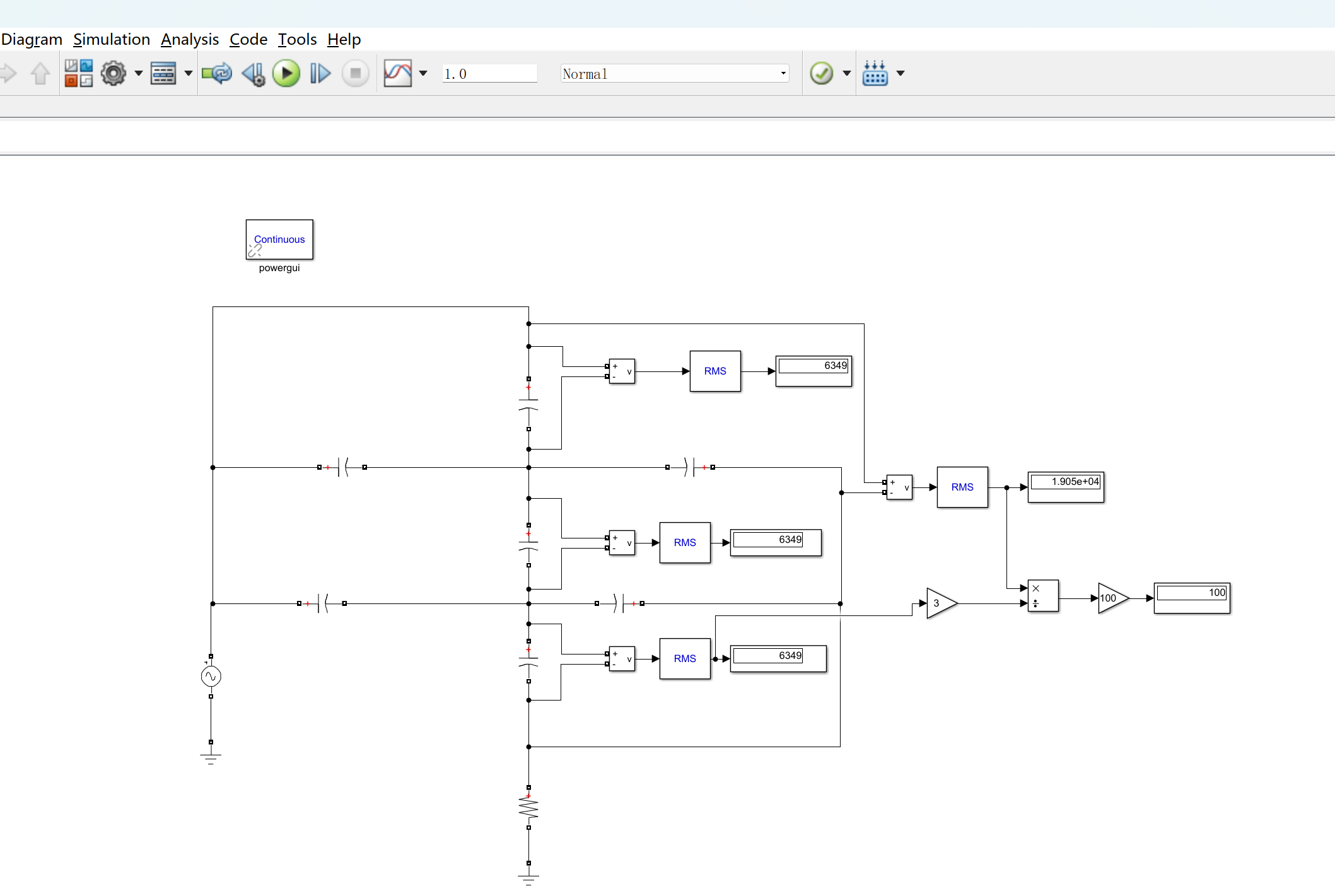
1 一个mapreduce进程会启动多少map进程多少reduce进程*
1)map数量由处理的数据分成的block数量决定default_num = total_size / split_size;
2)reduce数量为job.setNumReduceTasks(x)中x 的大小。不设置的话默认为 1。
2 讲下shuffle的过程
shuffle分为map端和reduce端的工作。
MapTask工作机制
(1)Read阶段:Map Task通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
(2)Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
(3)Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
(4)Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。(5)Combine阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
ReduceTask工作机制
(1)Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(2)Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
(3)Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。(4)Reduce阶段:reduce()函数将计算结果写到HDFS上。
3 常见的数据倾斜情况以及解决方案
- 空值引发的数据倾斜
解决方案:
第一种:可以直接不让null值参与join操作,即不让null值有shuffle第二种:因为null值参与shuffle时的hash结果是一样的,那么我们可以给null值随机赋值,这样它们的hash结果就不一样,就会进到不同的reduce中 - 不同数据类型引发的数据倾斜
解决方案:
如果key字段既有string类型也有int类型,默认的hash就都会按int类型来分配,那我们直接把int类型都转为string就好了,这样key字段都为string,hash时就按照string类型分配了 - 不可拆分大文件引发的数据倾斜
解决方案:
这种数据倾斜问题没有什么好的解决方案,只能将使用GZIP压缩等不支持文件分割的文件转为bzip和zip等支持文件分割的压缩方式。
所以,我们在对文件进行压缩时,为避免因不可拆分大文件而引发数据读取的倾斜,在数据压缩的时候可以采用bzip2和Zip等支持文件分割的压缩算法。 - 数据膨胀引发的数据倾斜
解决方案:
在Hive中可以通过参数 hive.new.job.grouping.set.cardinality 配置的方式自动控制作业的拆解,该参数默认值是30。表示针对grouping sets/rollups/cubes这类多维聚合的操作,如果最后拆解的键组合大于该值,会启用新的任务去处理大于该值之外的组合。如果在处理数据时,某个分组聚合的列有较大的倾斜,可以适当调小该值。 - 表连接时引发的数据倾斜
解决方案:
通常做法是将倾斜的数据存到分布式缓存中,分发到各个Map任务所在节点。在Map阶段完成join操作,即MapJoin,这避免了 Shuffle,从而避免了数据倾斜。 - 其他情况引发的数据倾斜
解决方案:
这类问题最直接的方式就是调整reduce所执行的内存大小。
调整reduce的内存大小使用mapreduce.reduce.memory.mb这个配置。
4 HBase读写流程*
HBase读写数据与操作流程![]() https://zhuanlan.zhihu.com/p/373740211
https://zhuanlan.zhihu.com/p/373740211
5 星形模型的特点
- 维度表只和事实表关联,维度表之间没有关联;
- 每个维度表的主码为单列,且该主码放置在事实表中,作为两边连接的外码;
- 以事实表为核心,维度表围绕核心呈星形分布。
6 常见事实表几种?特点?周期形快照事实表的特点?除了是数值形的还有什么?*
一篇文章搞懂数据仓库:三种事实表(设计原则,设计方法、对比)-阿里云开发者社区一篇文章搞懂数据仓库:三种事实表(设计原则,设计方法、对比)
7 主题域划分的思路*
按部门划分、按业务线划分、按业务系统划分、按业务过程划分。
8 数仓建模6连(细问项目)
- 有负责过具体某个域或者某个主题的开发吗?
- 一共化了几个主题域?挑一个讲一讲
- 做了哪个域的建设,负责了哪些业务过程,一致性纬度有哪些,建了哪些表?
- 描述下总线矩阵(一边是业务过程、一边是一致性维度)
- dwd是怎么建设?
- 用户下单有很多流水,是什么类型的事实表?有哪些维表?
按照业务系统划分,先按系统划分一级主题域,再按系统各自的菜单(也就是子系统)划分二级主题域,例如主要的订票APP实际上有订票系统,还有积分系统,值机系统,抽奖活动系统等等。
我来介绍下我做过的托运系统的主题域,其业务过程大致如下:创建订单(订单维度(订单id、流水号、订单号、下单时间)、客户维度(用户昵称、用户真实姓名、用户性别、用户身份证号、用户出生日期)、航班维度(起飞机场名称、起飞城市id、到达机场、名称、是否转机)、城市维度)->买家付款->客户值机(打印登机牌上的信息,有城市维度、客户维度、)->航班起飞->航班降落->用户服务。
公共维度有城市维度(客户值机、航班起飞航班降落)、客户维度(创建订单、用户服务)、机长维度、乘务员维、机场维度、航班维度。
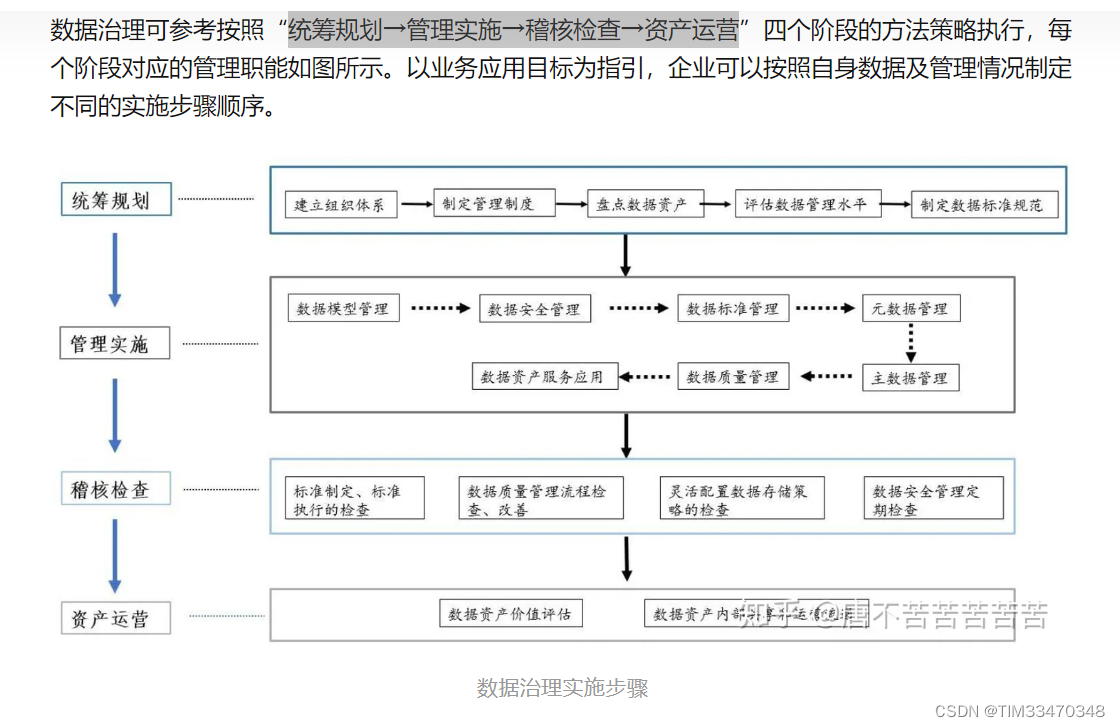
9 数据治理做了哪些工作?*
数据治理分为四个实施步骤:统筹规划→管理实施→稽核检查→资产运营,我主要参与了前两个步骤,在第一步统筹规划中,我的主要工作在盘点数据资产,其主要针对元数据,根据大数据之路的第12章,将元数据分成两类,技术性元数据和业务形元数据,然后针对业务形元数据梳理血缘图谱,并给元数据打标签。在第二步工作中,我主要通过计算统计量对数据质量做出评估,计算空值的比例,计算空值字段较多的比例,计算有效字段的中位数和众数(当空值达到一定比例时,认为该字段无效,遵循3西格玛准则,大于5%无效)
10 手撕SQL两道题
1.某一天的新用户。
窗口函数row_number()
2.连续7天登录的客户。*
先去重、再row_number()开窗、日期-rnk、最后group by id、rnk having count(*)>=7