文章目录
- 嫌啰嗦直接看代码
- Q2 Image Captioning with Vanilla RNNs
- 一个给的工具代码里的bug
- 问题展示
- 问题解决思路
- 解决办法
- rnn_step_forward
- 题面
- 解析
- 代码
- 输出
- rnn_step_backward
- 题面
- 解析
- 代码
- 输出
- rnn_forward
- 题面
- 解析
- 代码
- 输出
- rnn_backward
- 题面
- 解析
- 代码
- 输出
- word_embedding_forward
- word embedding 技术解释
- 题面
- 解析
- 代码
- 输出
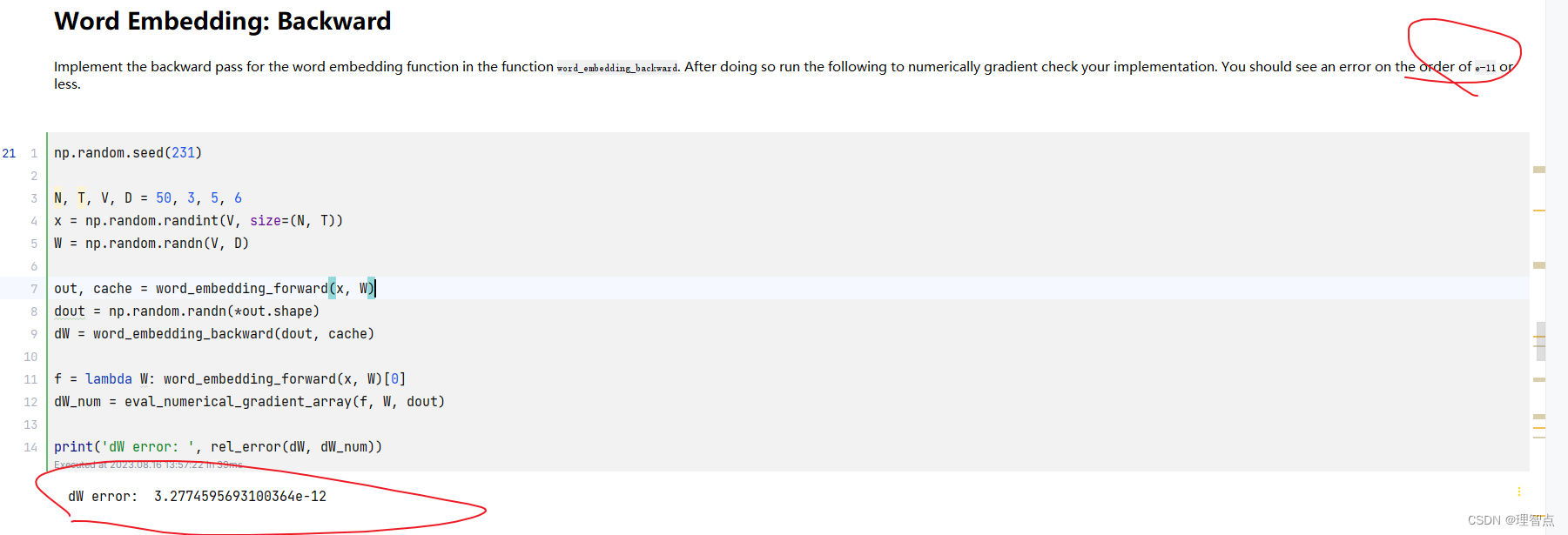
- word_embedding_backward
- 题面
- 解析
- 代码
- 输出
- CaptioningRNN .loss
- 题面
- 解析
- 代码
- 输出
- CaptioningRNN.sample
- 题面
- 解析
- 代码
- 输出
- 结语
嫌啰嗦直接看代码
Q2 Image Captioning with Vanilla RNNs
一个给的工具代码里的bug
image_from_url 里的报错
[WinError 32] 另一个程序正在使用此文件,进程无法访问。: 'C:\\Users\\Leezed\\AppData\\Local\\Temp\\tmp7r3fjusu'
问题展示
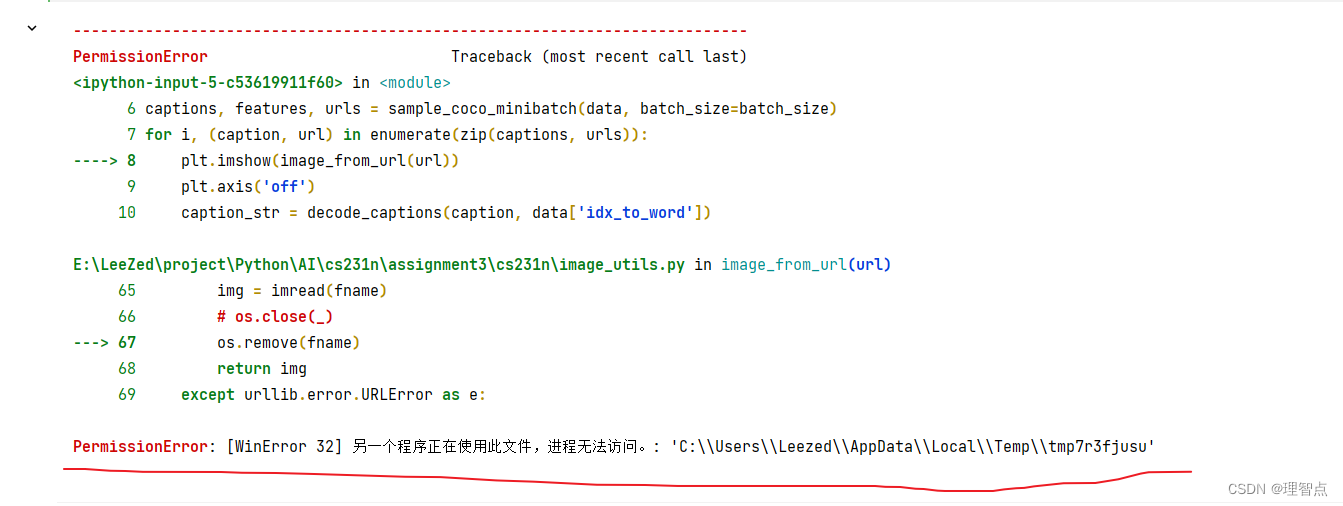
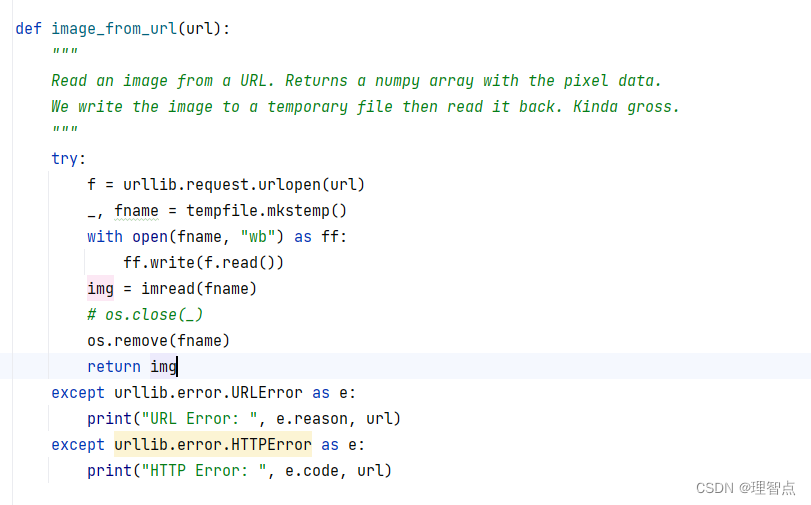
我在运行这段代码的时候就报错了 另一个进程正在使用此文件,文件无法访问
问题解决思路
- 我一开始以为是img = imread(fname) 里的问题导致文件还在被占用,所以无法释放文件的所有权,导致os.remove(fname)无法删除。 就是我以为img = imread(fname) 是另开了一个线程去读取图片,然后直接运行了os.remove,但是图片还没有读取完,导致占用没有被释放,所以删除失败
- 所以我一开始加了延时函数,time.sleep(5),但是还是同样的问题,正常情况下一张图片5秒肯定能读完了,我不死心再检查了一下,我直接吧img = imread(fname) 改成了 img =None ,结果还是报了同样的错,我就知道肯定不是它的问题了
- 我后来甚至开始怀疑是ff没有close的问题了,但是with as 语句会自动关闭ff,这就很奇怪了
- 最后我一步步排查觉得是tempfile.mkstemp的问题
- 查阅相关文档,这个函数返回的是两个参数,一个是fd,一个是fname,fd是文件描述符,fname是指生成的文件的绝对路径。
那么文件描述符是啥呢
内核(kernel)利用文件描述符(file descriptor)来访问文件。文件描述符是非负整数。
打开现存文件或新建文件时,内核会返回一个文件描述符。
读写文件也需要使用文件描述符来指定待读写的文件。
文件描述符在同一进程下与文件是对应的,一个描述符只指向一个文件,但是一个文件可以被多个文件描述符关联。
同一进程下,文件描述符是不可重复的。但是不同进程可以有一样的文件描述符。它们也可以指向不同的文件。
因此如果直接使用os.remove(fname)删除文件的话,文件描述符还在我们的内存里,而文件描述符还在内存里说明文件还被占用着,所以无法删除
那我们应该怎么删除临时文件呢
首先需要使用os.close(fd) 方法用于关闭指定的文件描述符 fd,
然后再使用os.remove(fname)删除临时文件。
解决办法
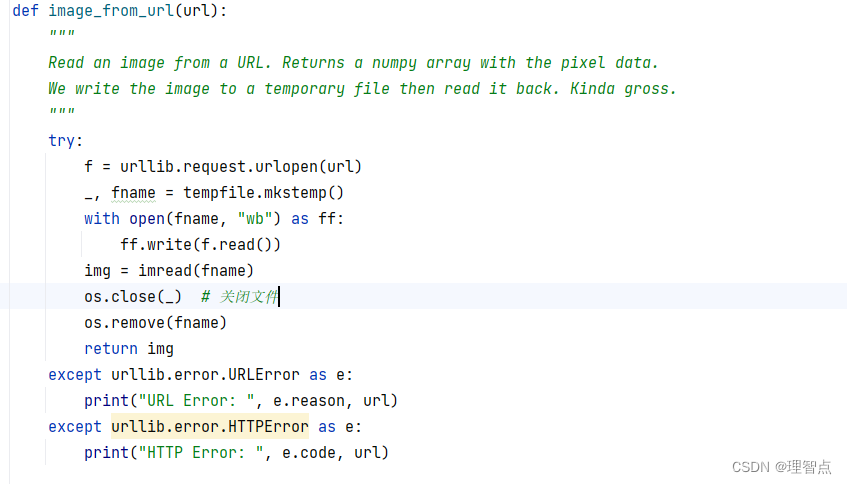
在os.remove(fname)之前加一句代码 os.close(_)就好了,如下图所示
rnn_step_forward
题面
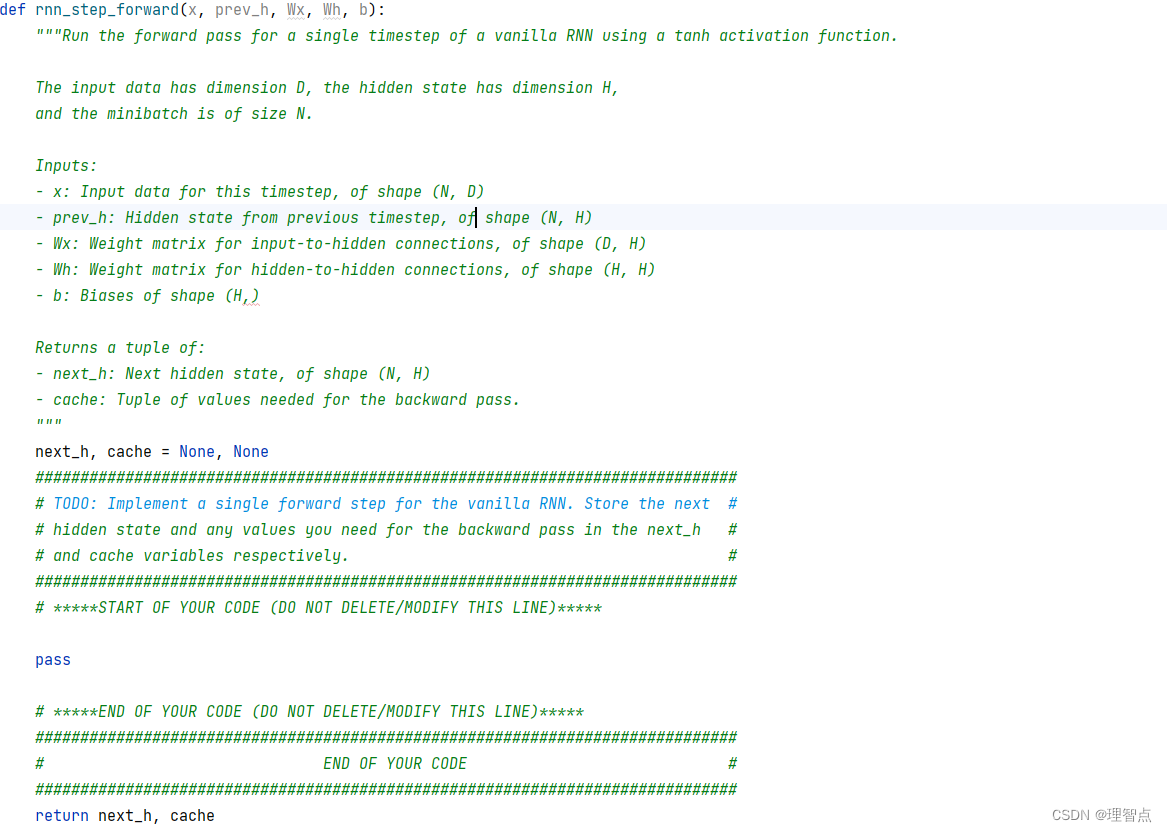
让我们完成循环神经网络的前向一步
解析
看课吧,我觉得课程里讲的很详细了,或者看代码注释
代码
def rnn_step_forward(x, prev_h, Wx, Wh, b):
"""Run the forward pass for a single timestep of a vanilla RNN using a tanh activation function.
The input data has dimension D, the hidden state has dimension H,
and the minibatch is of size N.
Inputs:
- x: Input data for this timestep, of shape (N, D)
- prev_h: Hidden state from previous timestep, of shape (N, H)
- Wx: Weight matrix for input-to-hidden connections, of shape (D, H)
- Wh: Weight matrix for hidden-to-hidden connections, of shape (H, H)
- b: Biases of shape (H,)
Returns a tuple of:
- next_h: Next hidden state, of shape (N, H)
- cache: Tuple of values needed for the backward pass.
"""
next_h, cache = None, None
##############################################################################
# TODO: Implement a single forward step for the vanilla RNN. Store the next #
# hidden state and any values you need for the backward pass in the next_h #
# and cache variables respectively. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
next_h = x @ Wx + prev_h @ Wh + b
next_h = np.tanh(next_h)
cache = (x, prev_h, Wx, Wh, b, next_h)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return next_h, cache
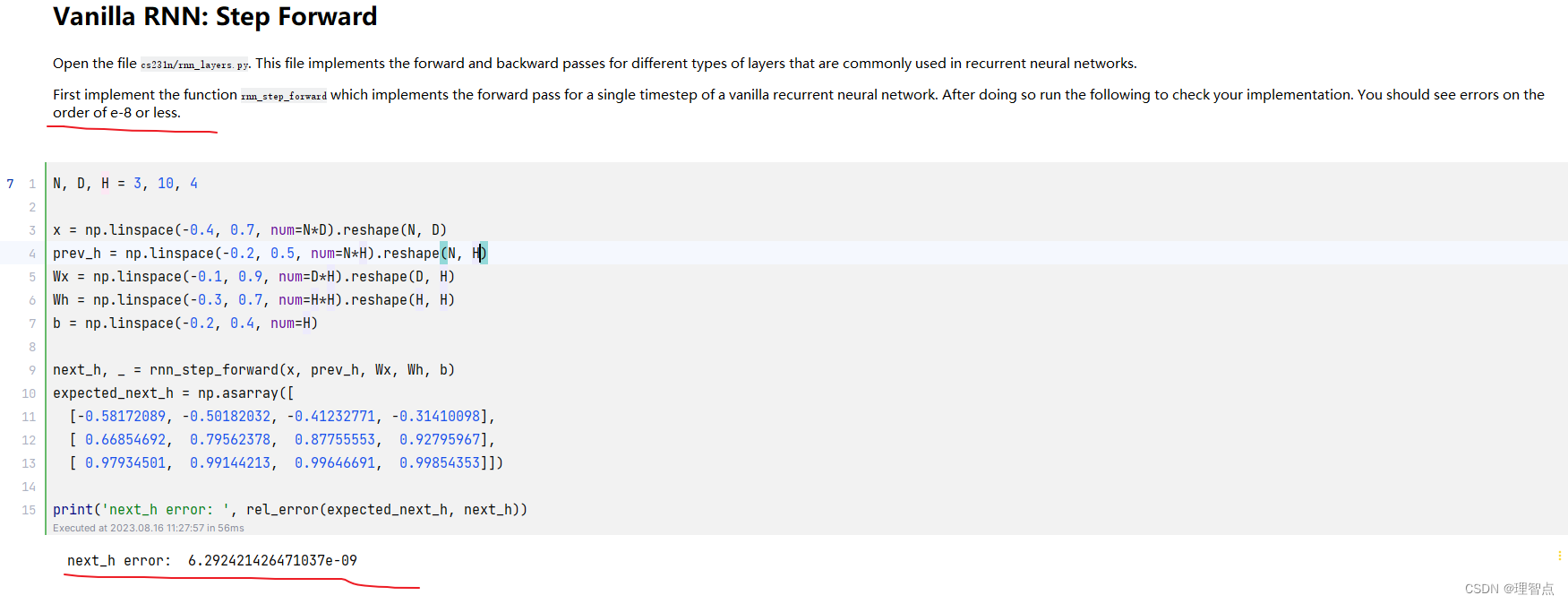
输出
rnn_step_backward
题面
让我们完成循环神经网络的后向一步
解析
不赘述了,看代码吧
tanh函数求导公式可以看下面这个连接的文章
激活函数tanh(x)求导
代码
def rnn_step_backward(dnext_h, cache):
"""Backward pass for a single timestep of a vanilla RNN.
Inputs:
- dnext_h: Gradient of loss with respect to next hidden state, of shape (N, H)
- cache: Cache object from the forward pass
Returns a tuple of:
- dx: Gradients of input data, of shape (N, D)
- dprev_h: Gradients of previous hidden state, of shape (N, H)
- dWx: Gradients of input-to-hidden weights, of shape (D, H)
- dWh: Gradients of hidden-to-hidden weights, of shape (H, H)
- db: Gradients of bias vector, of shape (H,)
"""
dx, dprev_h, dWx, dWh, db = None, None, None, None, None
##############################################################################
# TODO: Implement the backward pass for a single step of a vanilla RNN. #
# #
# HINT: For the tanh function, you can compute the local derivative in terms #
# of the output value from tanh. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
x, prev_h, Wx, Wh, b, next_h = cache
# 求导 tanh(x) = (1 - tanh(x)^2) * dx
dnext_h = dnext_h * (1 - next_h ** 2)
dx = dnext_h @ Wx.T
dprev_h = dnext_h @ Wh.T
dWx = x.T @ dnext_h
dWh = prev_h.T @ dnext_h
db = np.sum(dnext_h, axis=0)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return dx, dprev_h, dWx, dWh, db
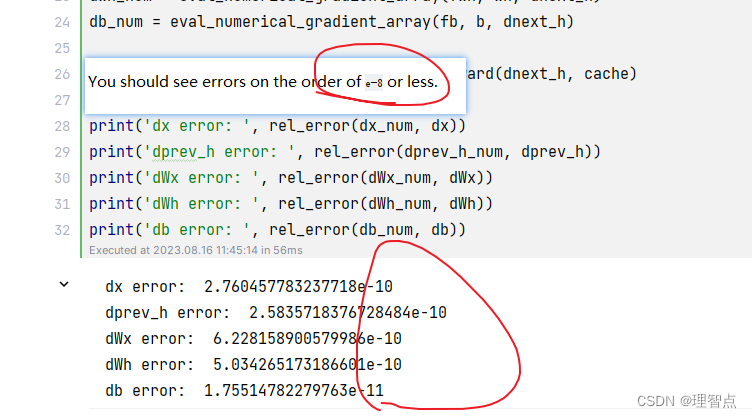
输出
rnn_forward
题面
解析
看代码吧
代码
def rnn_forward(x, h0, Wx, Wh, b):
"""Run a vanilla RNN forward on an entire sequence of data.
We assume an input sequence composed of T vectors, each of dimension D. The RNN uses a hidden
size of H, and we work over a minibatch containing N sequences. After running the RNN forward,
we return the hidden states for all timesteps.
Inputs:
- x: Input data for the entire timeseries, of shape (N, T, D)
- h0: Initial hidden state, of shape (N, H)
- Wx: Weight matrix for input-to-hidden connections, of shape (D, H)
- Wh: Weight matrix for hidden-to-hidden connections, of shape (H, H)
- b: Biases of shape (H,)
Returns a tuple of:
- h: Hidden states for the entire timeseries, of shape (N, T, H)
- cache: Values needed in the backward pass
"""
h, cache = None, None
##############################################################################
# TODO: Implement forward pass for a vanilla RNN running on a sequence of #
# input data. You should use the rnn_step_forward function that you defined #
# above. You can use a for loop to help compute the forward pass. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# 获取维度
N, T, _ = x.shape
_, H = h0.shape
# 初始化
h = np.zeros((N, T, H))
cache = []
# 前向传播
for i in range(T):
if i == 0:
h[:, i, :], cache_i = rnn_step_forward(x[:, i, :], h0, Wx, Wh, b)
else:
h[:, i, :], cache_i = rnn_step_forward(x[:, i, :], h[:, i - 1, :], Wx, Wh, b)
cache.append(cache_i)
cache = tuple(cache)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return h, cache
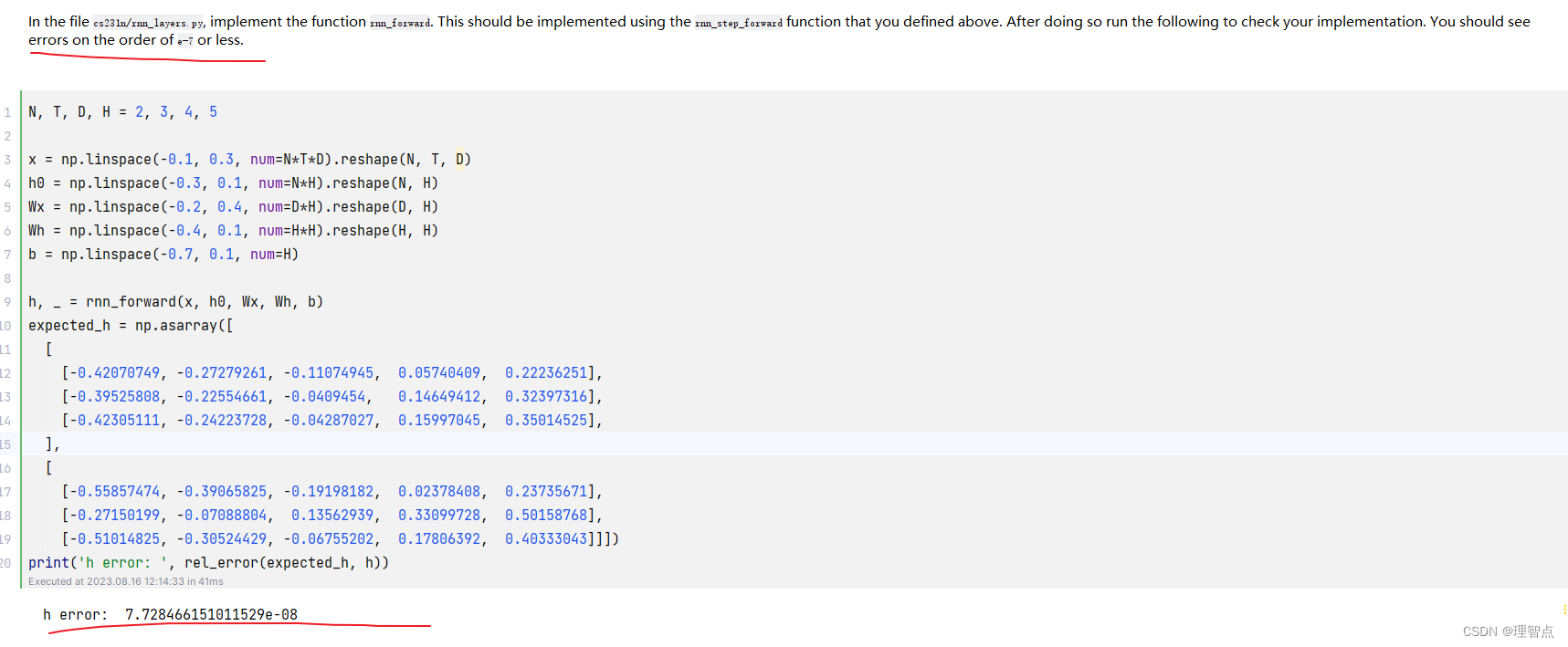
输出
rnn_backward
题面
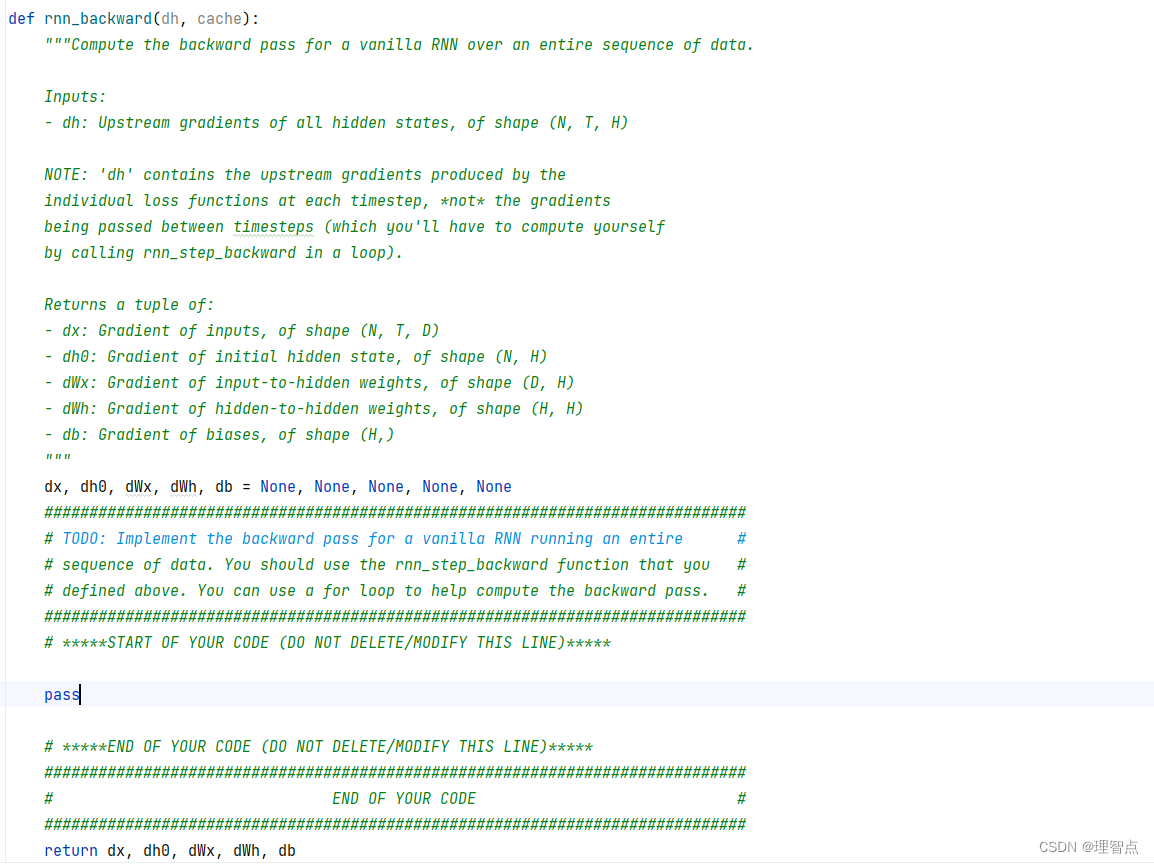
解析
看代码吧,认真听课的话肯定能理解的
代码
def rnn_backward(dh, cache):
"""Compute the backward pass for a vanilla RNN over an entire sequence of data.
Inputs:
- dh: Upstream gradients of all hidden states, of shape (N, T, H)
NOTE: 'dh' contains the upstream gradients produced by the
individual loss functions at each timestep, *not* the gradients
being passed between timesteps (which you'll have to compute yourself
by calling rnn_step_backward in a loop).
Returns a tuple of:
- dx: Gradient of inputs, of shape (N, T, D)
- dh0: Gradient of initial hidden state, of shape (N, H)
- dWx: Gradient of input-to-hidden weights, of shape (D, H)
- dWh: Gradient of hidden-to-hidden weights, of shape (H, H)
- db: Gradient of biases, of shape (H,)
"""
dx, dh0, dWx, dWh, db = None, None, None, None, None
##############################################################################
# TODO: Implement the backward pass for a vanilla RNN running an entire #
# sequence of data. You should use the rnn_step_backward function that you #
# defined above. You can use a for loop to help compute the backward pass. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# 获取维度
N, T, H = dh.shape
D, _ = cache[0][2].shape
# 初始化
dx = np.zeros((N, T, D))
dh0 = np.zeros((N, H))
dWx = np.zeros((D, H))
dWh = np.zeros((H, H))
db = np.zeros((H,))
# 反向传播
for i in range(T - 1, -1, -1):
dx[:, i, :], dh0, dWx_i, dWh_i, db_i = rnn_step_backward(dh[:, i, :] + dh0, cache[i])
dWx += dWx_i
dWh += dWh_i
db += db_i
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return dx, dh0, dWx, dWh, db
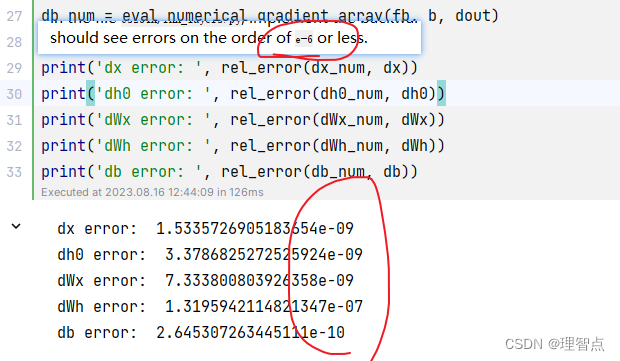
输出
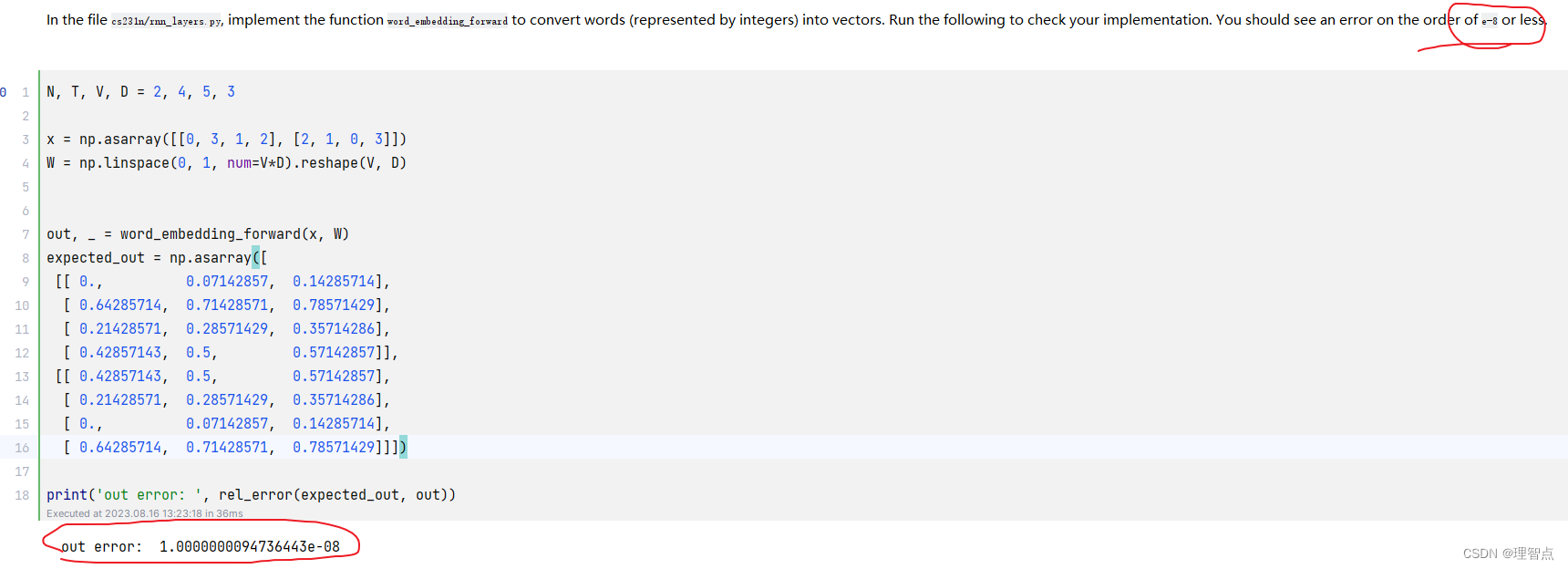
word_embedding_forward
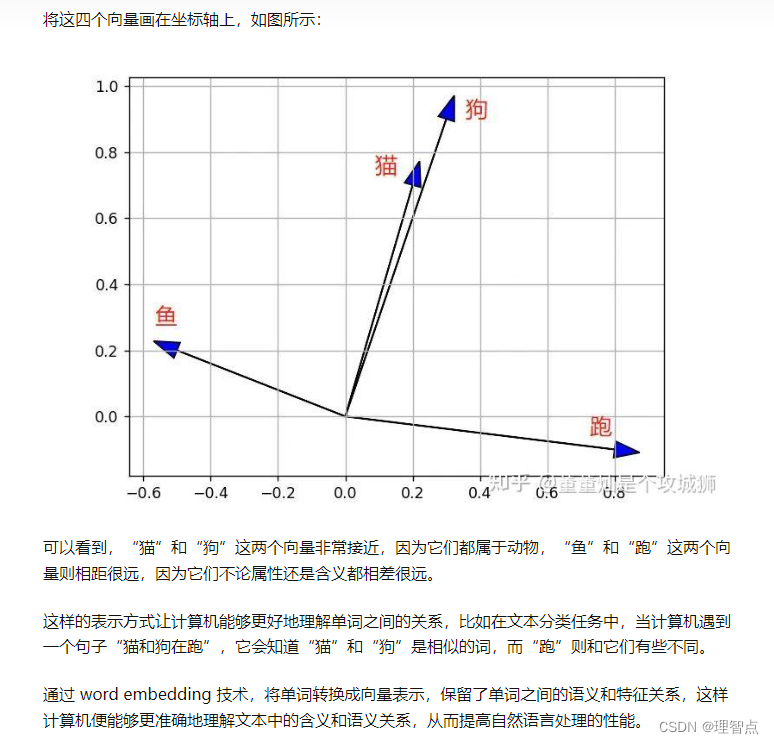
word embedding 技术解释
word embedding 技术解释

题面
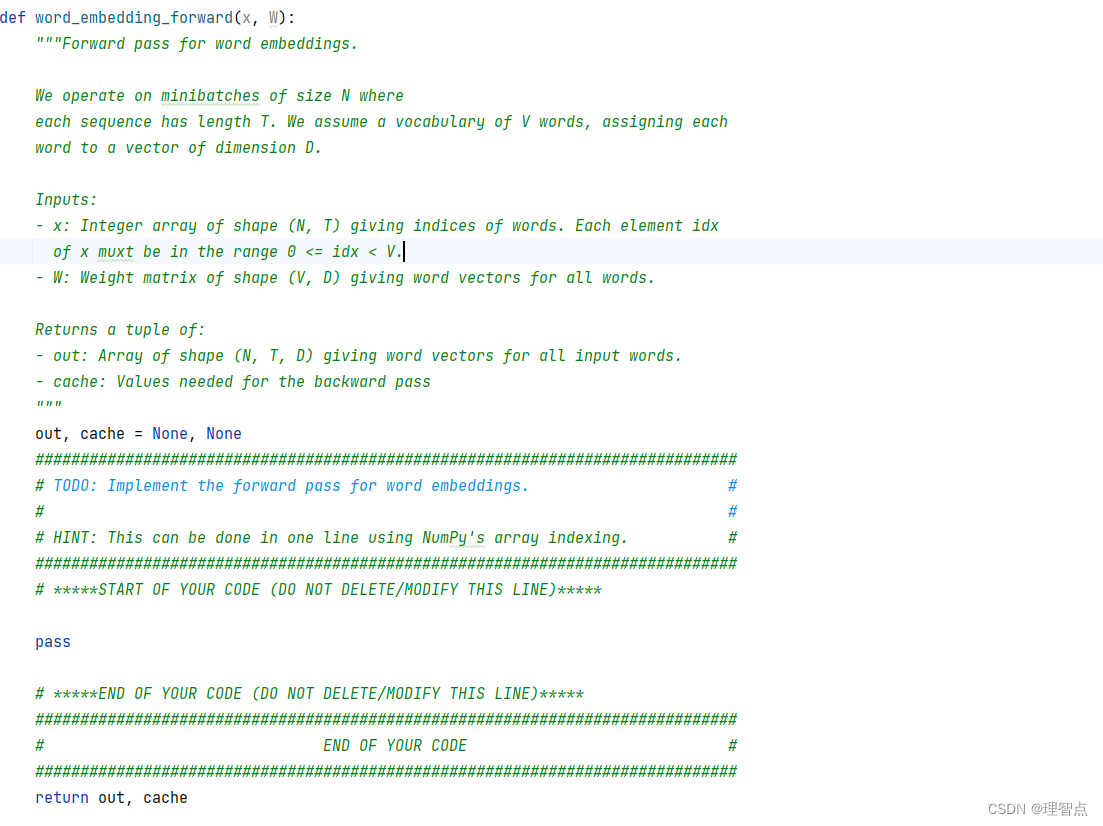
解析
看代码吧
代码
def word_embedding_forward(x, W):
"""Forward pass for word embeddings.
We operate on minibatches of size N where
each sequence has length T. We assume a vocabulary of V words, assigning each
word to a vector of dimension D.
Inputs:
- x: Integer array of shape (N, T) giving indices of words. Each element idx
of x muxt be in the range 0 <= idx < V.
- W: Weight matrix of shape (V, D) giving word vectors for all words.
Returns a tuple of:
- out: Array of shape (N, T, D) giving word vectors for all input words.
- cache: Values needed for the backward pass
"""
out, cache = None, None
##############################################################################
# TODO: Implement the forward pass for word embeddings. #
# #
# HINT: This can be done in one line using NumPy's array indexing. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
out = W[x]
cache = (x, W)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return out, cache
输出
word_embedding_backward
题面
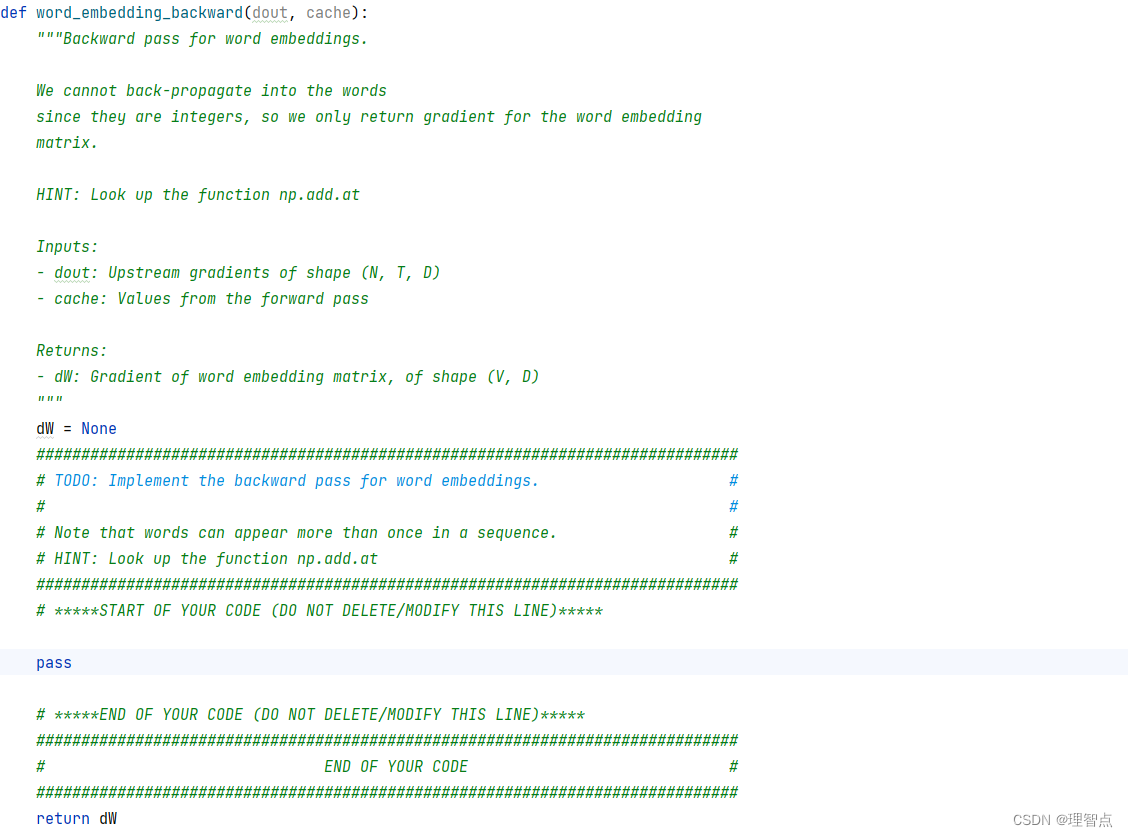
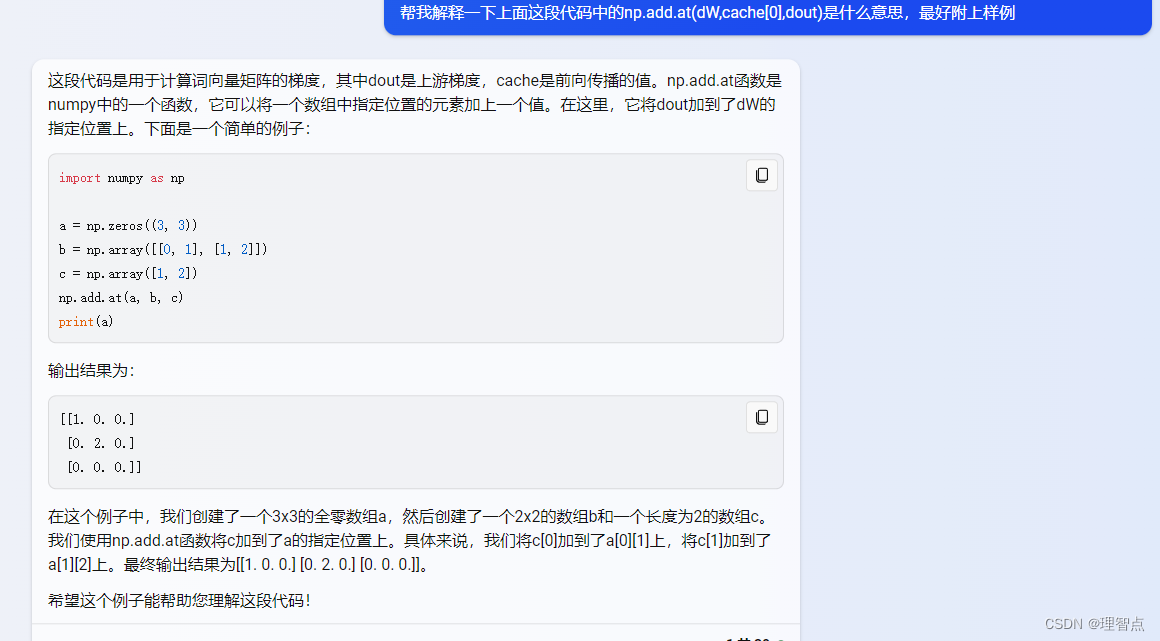
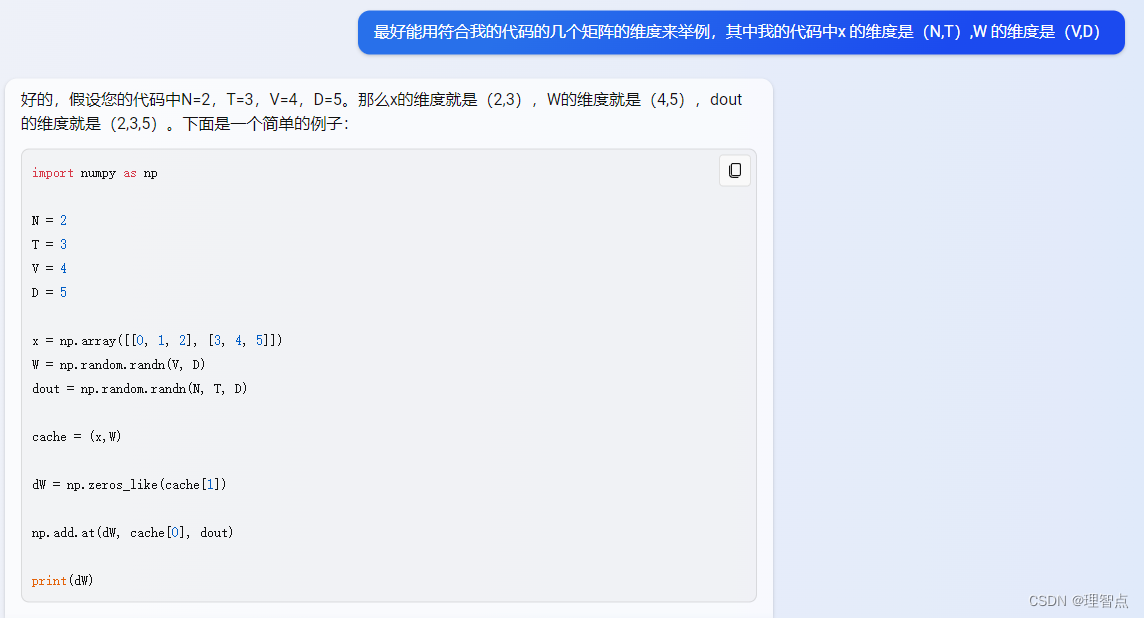
解析
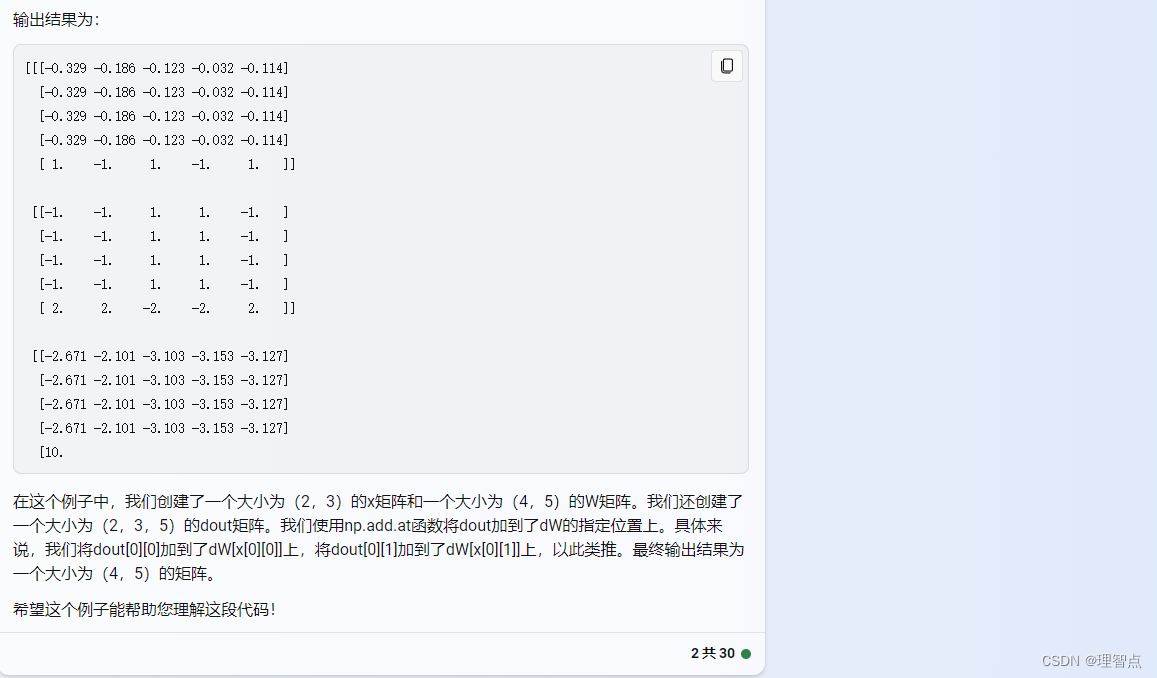
代码
def word_embedding_backward(dout, cache):
"""Backward pass for word embeddings.
We cannot back-propagate into the words
since they are integers, so we only return gradient for the word embedding
matrix.
HINT: Look up the function np.add.at
Inputs:
- dout: Upstream gradients of shape (N, T, D)
- cache: Values from the forward pass
Returns:
- dW: Gradient of word embedding matrix, of shape (V, D)
"""
dW = None
##############################################################################
# TODO: Implement the backward pass for word embeddings. #
# #
# Note that words can appear more than once in a sequence. #
# HINT: Look up the function np.add.at #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
dW = np.zeros_like(cache[1])
np.add.at(dW, cache[0], dout)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return dW
输出
CaptioningRNN .loss
题面
解析
就按照题面给的意思一步一步来就好了
代码
def loss(self, features, captions):
"""
Compute training-time loss for the RNN. We input image features and
ground-truth captions for those images, and use an RNN (or LSTM) to compute
loss and gradients on all parameters.
Inputs:
- features: Input image features, of shape (N, D)
- captions: Ground-truth captions; an integer array of shape (N, T + 1) where
each element is in the range 0 <= y[i, t] < V
Returns a tuple of:
- loss: Scalar loss
- grads: Dictionary of gradients parallel to self.params
"""
# Cut captions into two pieces: captions_in has everything but the last word
# and will be input to the RNN; captions_out has everything but the first
# word and this is what we will expect the RNN to generate. These are offset
# by one relative to each other because the RNN should produce word (t+1)
# after receiving word t. The first element of captions_in will be the START
# token, and the first element of captions_out will be the first word.
captions_in = captions[:, :-1]
captions_out = captions[:, 1:]
# You'll need this
mask = captions_out != self._null
# Weight and bias for the affine transform from image features to initial
# hidden state
W_proj, b_proj = self.params["W_proj"], self.params["b_proj"]
# Word embedding matrix
W_embed = self.params["W_embed"]
# Input-to-hidden, hidden-to-hidden, and biases for the RNN
Wx, Wh, b = self.params["Wx"], self.params["Wh"], self.params["b"]
# Weight and bias for the hidden-to-vocab transformation.
W_vocab, b_vocab = self.params["W_vocab"], self.params["b_vocab"]
loss, grads = 0.0, {}
############################################################################
# TODO: Implement the forward and backward passes for the CaptioningRNN. #
# In the forward pass you will need to do the following: #
# (1) Use an affine transformation to compute the initial hidden state #
# from the image features. This should produce an array of shape (N, H)#
# (2) Use a word embedding layer to transform the words in captions_in #
# from indices to vectors, giving an array of shape (N, T, W). #
# (3) Use either a vanilla RNN or LSTM (depending on self.cell_type) to #
# process the sequence of input word vectors and produce hidden state #
# vectors for all timesteps, producing an array of shape (N, T, H). #
# (4) Use a (temporal) affine transformation to compute scores over the #
# vocabulary at every timestep using the hidden states, giving an #
# array of shape (N, T, V). #
# (5) Use (temporal) softmax to compute loss using captions_out, ignoring #
# the points where the output word is <NULL> using the mask above. #
# #
# #
# Do not worry about regularizing the weights or their gradients! #
# #
# In the backward pass you will need to compute the gradient of the loss #
# with respect to all model parameters. Use the loss and grads variables #
# defined above to store loss and gradients; grads[k] should give the #
# gradients for self.params[k]. #
# #
# Note also that you are allowed to make use of functions from layers.py #
# in your implementation, if needed. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# 第一步,使用全连接层,将图像特征转换为隐藏层的初始状态
h0, cache_h0 = affine_forward(features, W_proj, b_proj)
# 第二步,使用词嵌入层,将输入的单词转换为词向量
word_vector, cache_word_vector = word_embedding_forward(captions_in, W_embed)
# 第三步,使用RNN或者LSTM,将词向量序列转换为隐藏层状态序列
if self.cell_type == "rnn":
h, cache_h = rnn_forward(word_vector, h0, Wx, Wh, b)
elif self.cell_type == "lstm":
h, cache_h = lstm_forward(word_vector, h0, Wx, Wh, b)
# 第四步,使用全连接层,将隐藏层状态序列转换为词汇表上的得分序列
scores, cache_scores = temporal_affine_forward(h, W_vocab, b_vocab)
# 第五步,使用softmax,计算损失
loss, dscores = temporal_softmax_loss(scores, captions_out, mask)
# 反向传播
# 第四步,全连接层的反向传播
dh, dW_vocab, db_vocab = temporal_affine_backward(dscores, cache_scores)
# 第三步,RNN或者LSTM的反向传播
if self.cell_type == "rnn":
dword_vector, dh0, dWx, dWh, db = rnn_backward(dh, cache_h)
elif self.cell_type == "lstm":
dword_vector, dh0, dWx, dWh, db = lstm_backward(dh, cache_h)
# 第二步,词嵌入层的反向传播
dW_embed = word_embedding_backward(dword_vector, cache_word_vector)
# 第一步,全连接层的反向传播
dfeatures, dW_proj, db_proj = affine_backward(dh0, cache_h0)
# 将梯度保存到grads中
grads["W_proj"] = dW_proj
grads["b_proj"] = db_proj
grads["W_embed"] = dW_embed
grads["Wx"] = dWx
grads["Wh"] = dWh
grads["b"] = db
grads["W_vocab"] = dW_vocab
grads["b_vocab"] = db_vocab
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return loss, grads
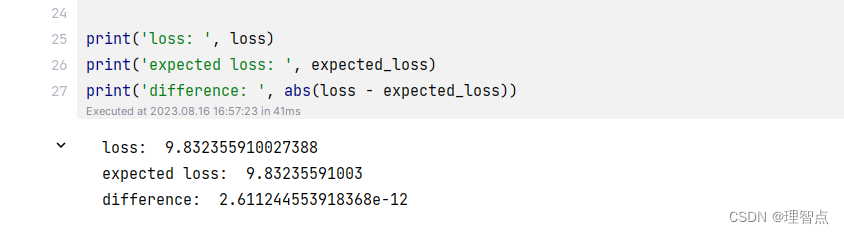
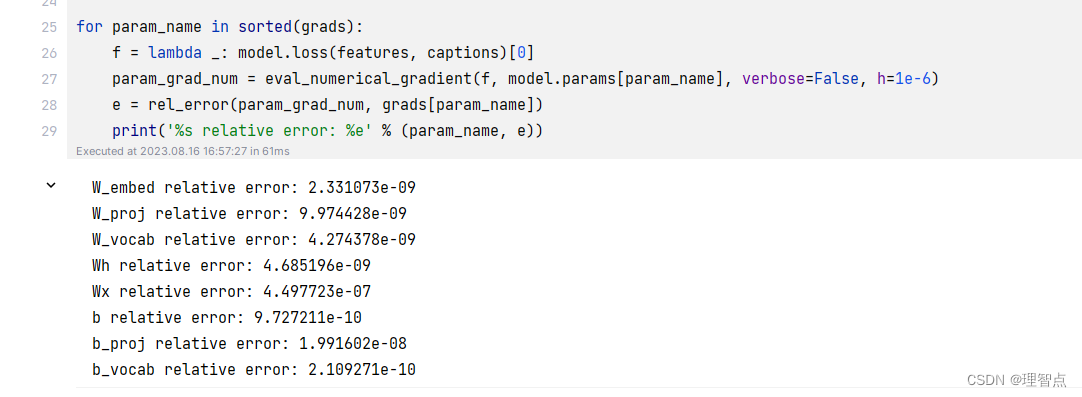
输出
CaptioningRNN.sample
题面
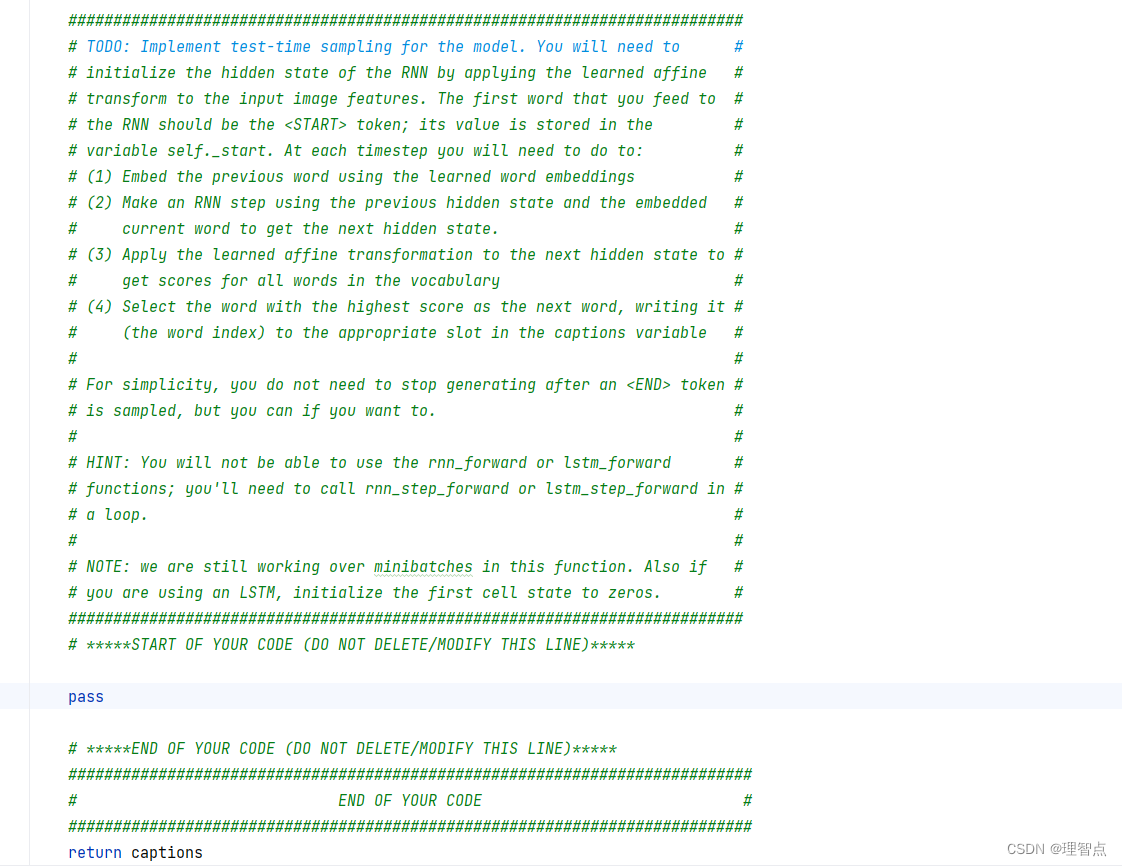
解析
看代码注释吧
代码
def sample(self, features, max_length=30):
"""
Run a test-time forward pass for the model, sampling captions for input
feature vectors.
At each timestep, we embed the current word, pass it and the previous hidden
state to the RNN to get the next hidden state, use the hidden state to get
scores for all vocab words, and choose the word with the highest score as
the next word. The initial hidden state is computed by applying an affine
transform to the input image features, and the initial word is the <START>
token.
For LSTMs you will also have to keep track of the cell state; in that case
the initial cell state should be zero.
Inputs:
- features: Array of input image features of shape (N, D).
- max_length: Maximum length T of generated captions.
Returns:
- captions: Array of shape (N, max_length) giving sampled captions,
where each element is an integer in the range [0, V). The first element
of captions should be the first sampled word, not the <START> token.
"""
N = features.shape[0]
captions = self._null * np.ones((N, max_length), dtype=np.int32)
# Unpack parameters
W_proj, b_proj = self.params["W_proj"], self.params["b_proj"]
W_embed = self.params["W_embed"]
Wx, Wh, b = self.params["Wx"], self.params["Wh"], self.params["b"]
W_vocab, b_vocab = self.params["W_vocab"], self.params["b_vocab"]
###########################################################################
# TODO: Implement test-time sampling for the model. You will need to #
# initialize the hidden state of the RNN by applying the learned affine #
# transform to the input image features. The first word that you feed to #
# the RNN should be the <START> token; its value is stored in the #
# variable self._start. At each timestep you will need to do to: #
# (1) Embed the previous word using the learned word embeddings #
# (2) Make an RNN step using the previous hidden state and the embedded #
# current word to get the next hidden state. #
# (3) Apply the learned affine transformation to the next hidden state to #
# get scores for all words in the vocabulary #
# (4) Select the word with the highest score as the next word, writing it #
# (the word index) to the appropriate slot in the captions variable #
# #
# For simplicity, you do not need to stop generating after an <END> token #
# is sampled, but you can if you want to. #
# #
# HINT: You will not be able to use the rnn_forward or lstm_forward #
# functions; you'll need to call rnn_step_forward or lstm_step_forward in #
# a loop. #
# #
# NOTE: we are still working over minibatches in this function. Also if #
# you are using an LSTM, initialize the first cell state to zeros. #
###########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# 第一步 初始化隐藏层状态
h, _ = affine_forward(features, W_proj, b_proj)
# 第二步 初始化第一个单词
word = np.repeat(self._start, N)
c = np.zeros_like(h)
# 第三步 生成后面的单词
for i in range(max_length):
# 第一步 生成第i个单词的词向量
word, _ = word_embedding_forward(word, W_embed)
# 第二步 生成第i个单词的隐藏层状态
if self.cell_type == "rnn":
h, _ = rnn_step_forward(word, h, Wx, Wh, b)
elif self.cell_type == "lstm":
h, c, _ = lstm_step_forward(word, h, c, Wx, Wh, b)
# 第三步 生成第i个单词的得分
scores, _ = affine_forward(h, W_vocab, b_vocab)
# 第四步 生成第i个单词的预测值 并记录到captions中,同时作为下一个单词的输入
word = np.argmax(scores, axis=1)
captions[:, i] = word
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return captions
输出
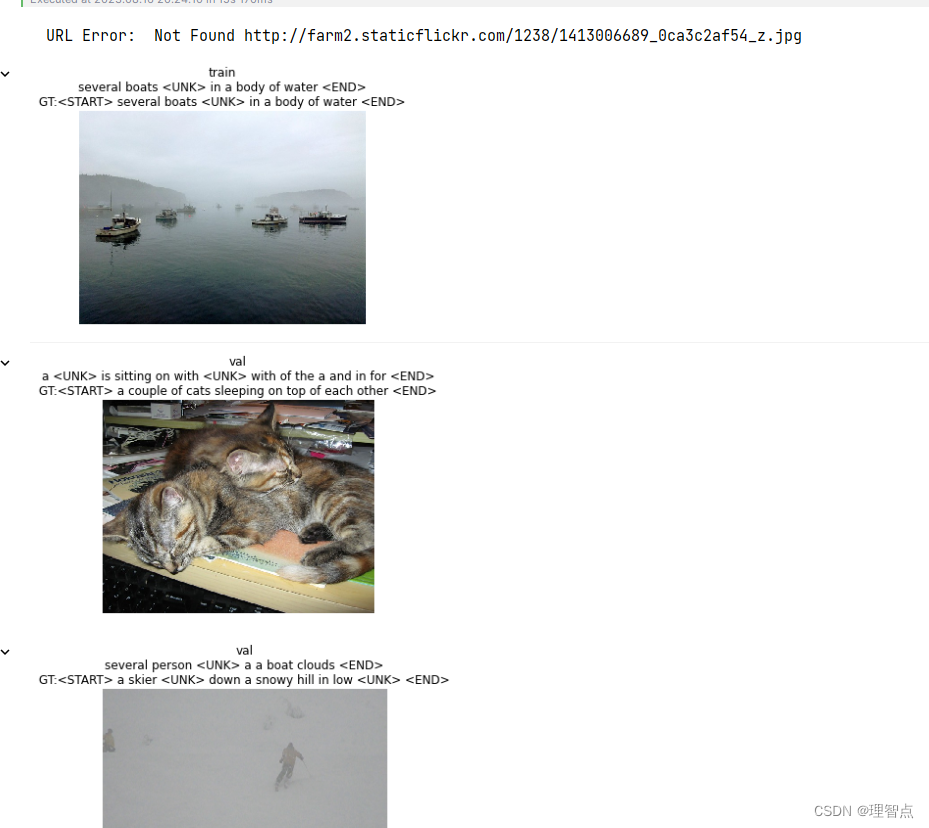
结语
对于循环神经网络的理解,不仅需要课程的讲解,也需要实验的理解,然后在结合课程,会有一个更深的理解。