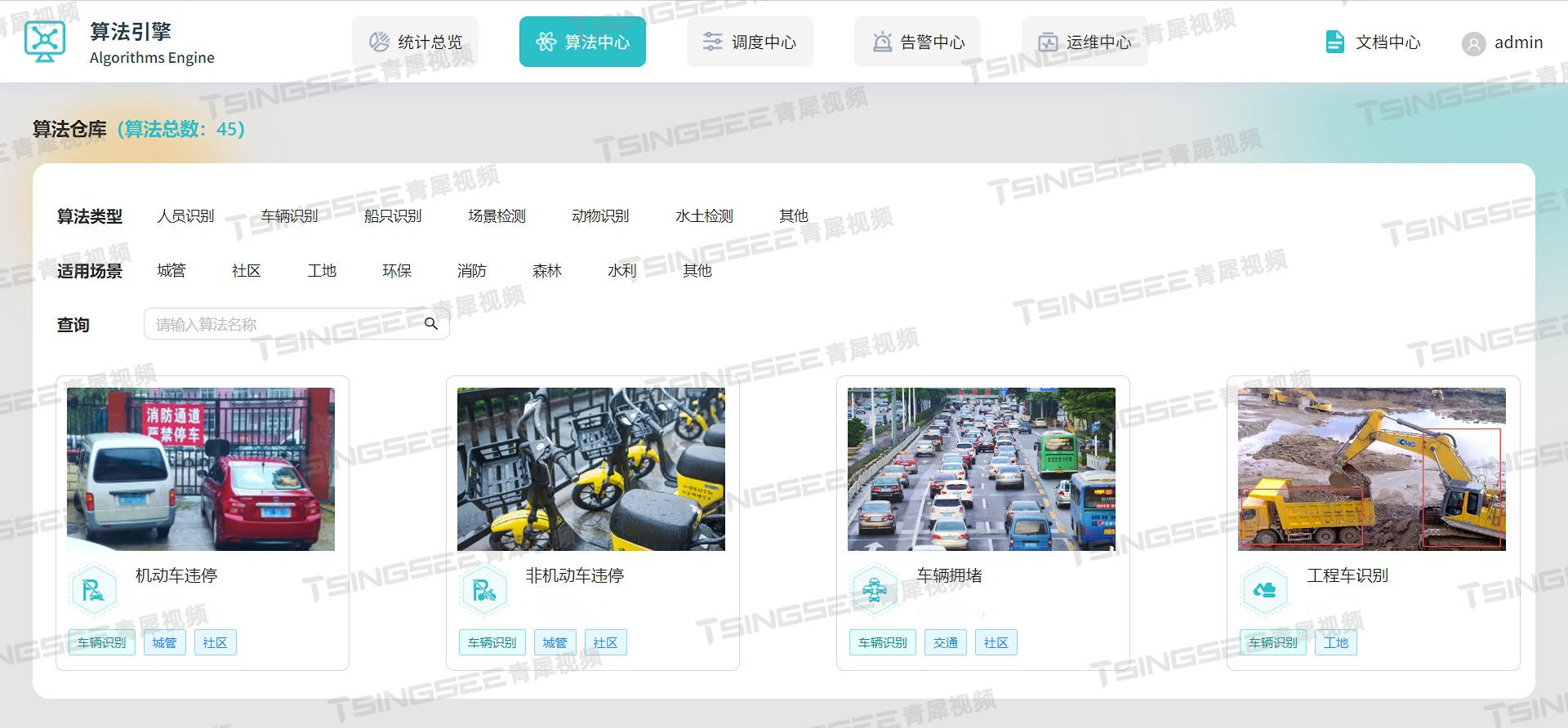
- 创建爬虫项目
srcapy startproject scrapy_dangdang
- 进入到spider文件里创建爬虫文件(这里爬取的是青春文学,仙侠玄幻分类)
srcapy genspider dang http://category.dangdang.com/cp01.01.07.00.00.00.html
- 获取图片、名字和价格
# 所有的seletor的对象,都可以再次调用xpath方法
li_list = response.xpath('//div[@id="search_nature_rg"]//li')
for li in li_list:
# 获取图片
src = li.xpath('.//img/@data-original').extract_first()
# 第一张图片和其他图片的标签的属性不一样
# 第一张图片的src是可以使用的,其他图片的地址在data-original里
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
# 获取名字
name = li.xpath('.//img/@alt').extract_first()
# 获取价格
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
print(src, name, price)
- 在items里定义要下载的数据
import scrapy
class ScrapyDangdang39Item(scrapy.Item):
# 要下载的数据都有什么
# 图片
src = scrapy.Field()
# 名字
name = scrapy.Field()
# 价格
price = scrapy.Field()
- 在dang.py里导入items
from ..items import ScrapyDangdang39Item
- 在parse方法里定义一个对象book,然后把获取到的值传递到pipelines
book = ScrapyDangdang39Item(src=src, name=name, price=price)
# 获取一个book就将book传递给pipelines
yield book
- 开启管道
在settings中,把这几行代码取消注释

管道可以有很多个,但是管道是有优先级的,优先级的范围是1到1000 值越小,优先级越高 - 下载数据
打开piplines.py
class ScrapyDangdang39Pipeline:
# 方法1
# 在爬虫文件执行前执行的一个方法
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
# item就是yield后面的book对象
# 1.write方法必须要写一个字符串,而不是其他的对象
# 2.w模式,每一个对象都会打开一次文件,然后覆盖之前的内容,所以使用a模式
with open('book.json', 'a', encoding='utf-8')as fp:
fp.write(str(item))
return item
但是这种模式不推荐,因为每传递过来一个数据,就要打开一次文件,对文件的操作太过频繁
换一种方法
class ScrapyDangdang39Pipeline:
# 在爬虫文件执行前执行的一个方法
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
# item就是yield后面的book对象
self.fp.write(str(item))
return item
# 在爬虫文件执行完后执行的一个方法
def close_spider(self, spider):
self.fp.close()
- 运行dang.py文件就可以把数据保存到本地了

![[PyTorch][chapter 52][迁移学习]](https://img-blog.csdnimg.cn/13af96d4eb06494db8b249f0f5a4c63b.png)