文章目录
一、准备工作
1、安装elasticSearch+kibana
我们此处用的es和kibana版本是7.4.0版本的。
docker安装elasticSearch+kibana
2、安装MySQL
docker安装mysql-简单无坑
3、安装Logstash
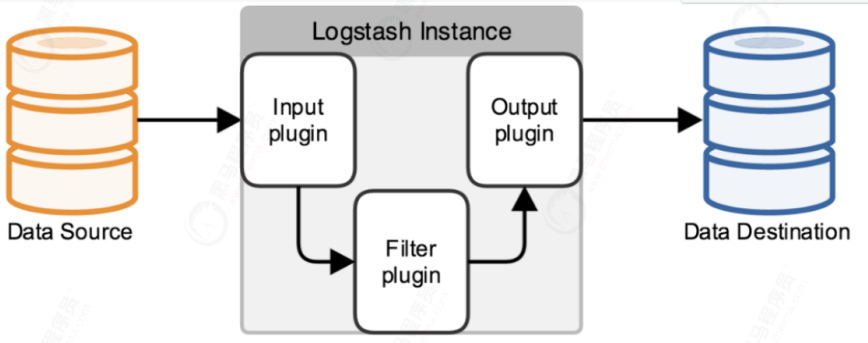
logstash就是一个具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以根据自己的需求在inuput --output中间加上滤网,Logstash内置了几十种插件,可以满足各种应用场景。
logstash官方插件 logstash-input-jdbc集成在logstash(5.X之后)中,通过配置文件实现mysql与elasticsearch数据同步。
能实现mysql数据全量和增量的数据同步,且能实现定时同步。
# 拉取logstach
docker pull logstash:8.5.2
二、全量同步
全量同步是指全部将数据同步到es,通常是刚建立es,第一次同步时使用。
1、准备MySQL数据与表
CREATE TABLE `product` (
`id` int NOT NULL COMMENT 'id',
`name` varchar(255) DEFAULT NULL,
`price` decimal(10,2) DEFAULT NULL,
`create_at` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
INSERT INTO `shop`.`product`(`id`, `name`, `price`, `create_at`) VALUES (1, '小米手机', 33.00, '1');
INSERT INTO `shop`.`product`(`id`, `name`, `price`, `create_at`) VALUES (2, '长虹手机', 2222.00, '2');
INSERT INTO `shop`.`product`(`id`, `name`, `price`, `create_at`) VALUES (3, '华为电脑', 3333.00, '3');
INSERT INTO `shop`.`product`(`id`, `name`, `price`, `create_at`) VALUES (4, '小米电脑', 333.30, '4');
2、上传mysql-connector-java.jar
把mysql-connector-java-8.0.21.jar上传到logstach服务器,
3、启动Logstash
# 编辑logstash.yml
vi /usr/local/logstash/config/logstash.yml
# 内容,需要修改es地址
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://172.17.0.3:9200" ]
# 自定义网络(可以解决网络不一致的问题)
#docker network create --subnet=172.188.0.0/16 czbkNetwork
# 启动 logstash
docker run --name logstash -v /usr/local/logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml -v /usr/local/logstash/config/conf.d/:/usr/share/logstash/pipeline/ -v /root/mysql-connector-java-8.0.21.jar:/usr/share/logstash/logstash-core/lib/jars/mysql-connector-java-5.1.48.jar -d d7102f8c625d
# 查看日志
docker logs -f --tail=200 c1d20ebf76c3
4、修改logstash.conf文件
cd /usr/local/logstash/config/conf.d
vi logstash.conf
stdin从标准输入读取事件。
默认情况下,每一行读取为一个事件
input {
stdin {}
#使用jdbc插件
jdbc {
# mysql数据库驱动
#jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/mysql-connector-java-5.1.48.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
# mysql数据库链接,数据库名
jdbc_connection_string => "jdbc:mysql://172.17.0.2:3306/shop?allowMultiQueries=true&useUnicode=true&characterEncoding=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true"
# mysql数据库用户名,密码
jdbc_user => "root"
jdbc_password => "root"
# 分页
jdbc_paging_enabled => "true"
# 分页大小
jdbc_page_size => "50000"
# sql语句执行文件,也可直接使用 statement => 'select * from t'
statement_filepath => "/usr/share/logstash/pipeline/sql/full_jdbc.sql"
#statement => " select * from product where id <=100 "
}
}
# 过滤部分(不是必须项)
filter {
json {
source => "message"
remove_field => ["message"]
}
}
# 输出部分
output {
elasticsearch {
# elasticsearch索引名
index => "product"
# elasticsearch的ip和端口号
hosts => ["172.17.0.3:9200"]
# 同步mysql中数据id作为elasticsearch中文档id
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
5、修改full_jdbc.sql文件
mkdir /usr/local/logstash/config/conf.d/sql
cd /usr/local/logstash/config/conf.d/sql
vi full_jdbc.sql
full_jdbc.sql内容如下
SELECT
id,
TRIM( REPLACE ( name, ' ', '' ) ) AS productname,
price
FROM product
6、打开Kibana创建索引和映射
注意!mysql—>logstash—>es
如果创建的映射是有大写的时候,es会自动转成小写
而且查看映射数据结构的时候会出现两个相同的字段(productname和productName)
这样就导致我们自己定义的映射无法使用,而有数据的是es自动生成的那个小写
PUT product
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"productname": {
"type": "text"
},
"price": {
"type": "double"
}
}
}
}
如果对映射没有硬性要求,可以忽略当前步骤,会自动创建索引。
# 当前在es中是没有数据的
GET product/_search
7、重启logstash进行全量同步
# 重启
docker restart c1d20ebf76c3
# 查看日志
docker logs -f --tail=200 c1d20ebf76c3
发现mysql中的数据已经同步至logstash中了。
8、踩坑
(1)报错
Error response from daemon: Cannot restart container 3849f947e115: driver failed programming external connectivity on endpoint logstash (60f5d9678218dc8d19bc8858fb1a195f4ebee294cff23d499a28612019a0ff78): (iptables failed: iptables --wait -t nat -A DOCKER -p tcp -d 0/0 --dport 4567 -j DNAT --to-destination 172.188.0.77:4567 ! -i br-413b460a0fc8: iptables: No chain/target/match by that name.
原因为:在启动firewalld之后,iptables被激活,
此时没有docker chain,重启docker后被加入到iptable里面
解决方案:
systemctl restart docker
三、增量同步
1、修改增量配置
修改上面的logstash.conf文件
input {
stdin {}
#使用jdbc插件
jdbc {
# mysql数据库驱动
#jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/mysql-connector-java-5.1.48.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
# mysql数据库链接,数据库名
jdbc_connection_string => "jdbc:mysql://172.188.0.15:3306/shop?characterEncoding=UTF-8&useSSL=false"
# mysql数据库用户名,密码
jdbc_user => "root"
jdbc_password => "root"
# 设置监听间隔 各字段含义(分、时、天、月、年),全部为*默认含义为每分钟更新一次
# /2* * * *表示每隔2分钟执行一次,依次类推
schedule => "* * * * *"
# 分页
jdbc_paging_enabled => "true"
# 分页大小
jdbc_page_size => "50000"
# sql语句执行文件,也可直接使用 statement => 'select * from t'
statement_filepath => "/usr/share/logstash/pipeline/sql/increment_jdbc.sql"
#上一个sql_last_value值的存放文件路径, 必须要在文件中指定字段的初始值
#last_run_metadata_path => "./config/station_parameter.txt"
#设置时区,此处更新sql_last_value查询的时区,sql_last_value还是默认UTC
jdbc_default_timezone => "Asia/Shanghai"
#使用其它字段追踪,而不是用时间
#use_column_value => true
#追踪的字段
#tracking_column => id
tracking_column_type => "timestamp"
}
}
# 过滤部分(不是必须项)
filter {
json {
source => "message"
remove_field => ["message"]
}
}
# 输出部分
output {
elasticsearch {
# elasticsearch索引名
index => "product"
# elasticsearch的ip和端口号
hosts => ["172.188.0.88:9200"]
# 同步mysql中数据id作为elasticsearch中文档id
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
2、新建increment_jdbc.sql文件
/usr/local/logstash/config/conf.d/sql目录下新建increment_jdbc.sql文件
cd /usr/local/logstash/config/conf.d/sql
vi increment_jdbc.sql
increment_jdbc.sql内容如下:
此处sql尽量保持与全量一致Select后的
SELECT
id,
TRIM( REPLACE ( product_name, ' ', '' ) ) AS productname,
price
FROM product where update_time > :sql_last_value
3、重启容器
# 启动
docker restart 容器id
4、测试
数据库插入一条数据之后,会自动同步至es
5、同步原理
#进入容器
docker exec -it 4f95a47f12de /bin/bash
#查看记录点
cat /usr/share/logstash/.logstash_jdbc_last_run
last_run_metadata_path=>“/usr/share/logstash/.logstash_jdbc_last_run”
在容器里面的/usr/share/logstash/路径下的隐藏文件.logstash_jdbc_last_run中记录了全量同步的UTC时间
每次同步完成记录该时间(重要)

注意
logstash_jdbc_last_run默认是没有的,执行增量后创建
文件也是可以删除的
容器重启会自动创建


![[HZNUCTF 2023 preliminary] 2023杭师大校赛(初赛) web方向题解wp 全](https://img-blog.csdnimg.cn/img_convert/c1b7907bf9d24c5bef97455d9211c038.png)