1. LeNet
LeNet由两个部分组成:
- 卷积编码器:由两个卷积层组成;
- 全连接层密集块:由三个全连接层组成。

- 每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均汇聚层;
- 每个卷积层使用5×5卷积核和一个sigmoid激活函数;
- 这些层将输入映射到多个二维特征输出,通常同时增加通道的数量;
- 每个4×4池操作(步幅2)通过空间下采样将维数减少4倍。
import torch
from torch import nn
from d2l import torch as d2l
# 定义模型net
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
该模型去掉了最后一层的高斯激活,下面将一个大小为28×28的单通道(黑白)图像通过LeNet,打印每一层输出的形状。
# 观察各层的输入输出通道数,宽度和高度
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)

- 第一个卷积层使用2个像素的填充,来补偿5×5卷积核导致的特征减少;
- 第二个卷积层没有填充,因此高度和宽度都减少了4个像素;
- 随着层叠的上升,通道的数量从输入时的1个,增加到第一个卷积层之后的6个,再到第二个卷积层之后的16个;
- 每个汇聚层的高度和宽度都减半;
- 每个全连接层减少维数,最终输出一个维数与结果分类数相匹配的输出。
2. 模型训练
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
"""
定义精度评估函数:
1、将数据集复制到显存中
2、通过调用accuracy计算数据集的精度
"""
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
# 判断net是否属于torch.nn.Module类
if isinstance(net, nn.Module):
net.eval()
# 如果不在参数选定的设备,将其传输到设备中
if not device:
device = next(iter(net.parameters())).device
# Accumulator是累加器,定义两个变量:正确预测的数量,总预测的数量。
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
# 将X, y复制到设备中
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
# 计算正确预测的数量,总预测的数量,并存储到metric中
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
"""
定义GPU训练函数:
1、为了使用gpu,首先需要将每一小批量数据移动到指定的设备(例如GPU)上;
2、使用Xavier随机初始化模型参数;
3、使用交叉熵损失函数和小批量随机梯度下降。
"""
#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
# 定义初始化参数,对线性层和卷积层生效
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
# 在设备device上进行训练
print('training on', device)
net.to(device)
# 优化器:随机梯度下降
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
# 损失函数:交叉熵损失函数
loss = nn.CrossEntropyLoss()
# Animator为绘图函数
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
# 调用Timer函数统计时间
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# Accumulator(3)定义3个变量:损失值,正确预测的数量,总预测的数量
metric = d2l.Accumulator(3)
net.train()
# enumerate() 函数用于将一个可遍历的数据对象
for i, (X, y) in enumerate(train_iter):
timer.start() # 进行计时
optimizer.zero_grad() # 梯度清零
X, y = X.to(device), y.to(device) # 将特征和标签转移到device
y_hat = net(X)
l = loss(y_hat, y) # 交叉熵损失
l.backward() # 进行梯度传递返回
optimizer.step()
with torch.no_grad():
# 统计损失、预测正确数和样本数
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop() # 计时结束
train_l = metric[0] / metric[2] # 计算损失
train_acc = metric[1] / metric[2] # 计算精度
# 进行绘图
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
# 测试精度
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
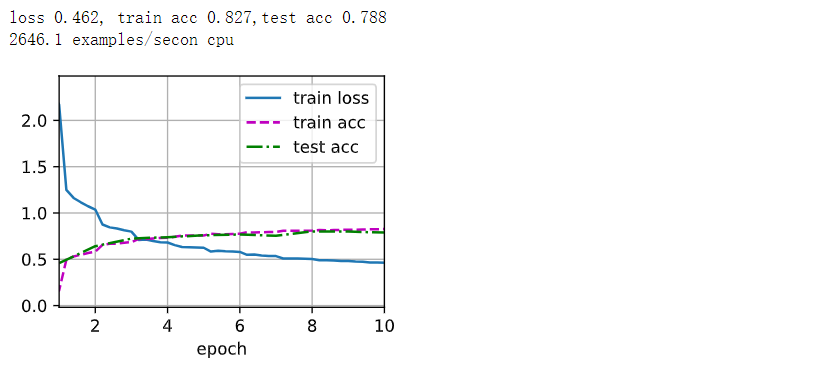
# 输出损失值、训练精度、测试精度
print(f'loss {train_l:.3f}, train acc {train_acc:.3f},'
f'test acc {test_acc:.3f}')
# 设备的计算能力
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec'
f'on {str(device)}')

lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
3. 小结
- 卷积神经网络(CNN)是一类使用卷积层的网络;
- 卷积神经网络中,可以组合使用卷积层、非线性激活函数和汇聚层;
- 为了构造高性能的卷积神经网络,通常对卷积层进行排列,逐渐降低其表示的空间分辨率,同时增加通道数;
- 在传统的卷积神经网络中,卷积块编码得到的表征在输出之前需由一个或多个全连接层进行处理。