👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——seq2seq实现机器翻译(详细实现与原理推导)
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
机器翻译(序列生成策略)
- 引入
- 贪心搜索
- 穷举搜索
- 束搜索
- 小结
引入
上一节已经实现了机器翻译的模型训练和预测,逐个预测输出序列, 直到预测序列中出现特定的序列结束词元eos,而对于预测序列的结果我们进行了评估,发现了效果并不好。因为之前的方式是使用了贪心搜索方式,这个搜索方式并不能使得全局上是优秀的,甚至是非常差的。接下来将介绍搜索方式。
我们已经知道,在任意的时间步,解码器的输出的概率取决于时间步之前的输出子序列和对输入序列的信息进行编码得到的上下文变量。为了量化计算代价,用γ表示输出词表(包含eos),而|γ|显然就是词表大小。
除此之外,我们限制一下输出序列的最大词元数T’。
贪心搜索
对于输出序列的每一个时间步t’,我们都将基于贪心搜索从γ中找到具有最高条件概率的词元,即:
y
t
′
=
a
r
g
m
a
x
y
∈
γ
P
(
y
∣
y
1
,
.
.
.
,
y
t
′
−
1
,
c
)
y_{t^{'}}=argmax_{y∈γ}P(y|y_1,...,y_{t^{'}-1},c)
yt′=argmaxy∈γP(y∣y1,...,yt′−1,c)
一旦输出序列包含了eos或者已经达到了最大长度T’,则输出完成。
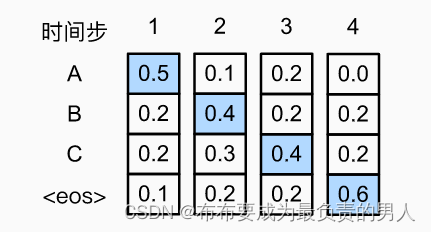
上图中的预测输出序列是ABC和eos,这个输出序列的条件概率就是0.5×0.4×0.4×0.6=0.048。
而如果我们在第二个时间步换一下,换成C,那么可能AC后面跟着的A、B、C和eos的概率就会全变了,例如:
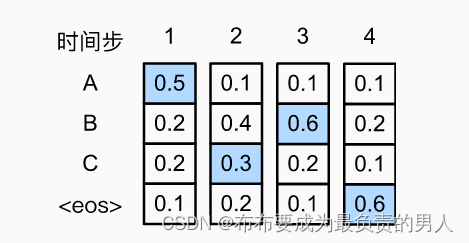
计算得出输出序列ACB和eos的条件概率为0.054,大于之前的贪心方式得到的结果。搞过动态规划算法的朋友们都知道贪心就是很可能出现这种情况,所以贪心搜索本身就不是一个很好的搜索策略。
穷举搜索
这个好理解,就是所有结果全部遍历过去,这样的话,我们绝对可以找到条件概率最高的一个。然而这样的复杂度将会非常的大,计算量会达到:
O
(
∣
γ
∣
T
′
)
O(|γ|^{T^{'}})
O(∣γ∣T′)
因此在词元数过多,或者预测序列的最大词元数太大的话,这个方法简直是非常的慢。
束搜索
显然,上面的可以得出一个简单的选择策略:如果精度最重要,则显然是穷举搜索;如果计算成本最重要,则显然是贪心搜索。而束搜索则是介于两者之间的(算是贪心的一个改进版本)。
它有一个超参数,名为束宽,记为k。在每个时间步,我们都选择具有最高条件概率的k个词元,过程如下所示(束宽为2,最大长度为3):
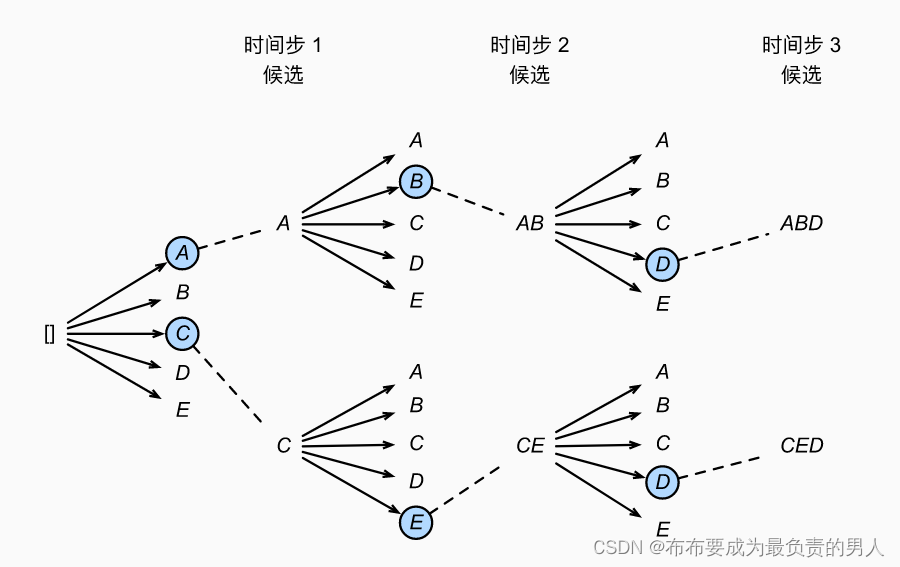
我们从这里面选出六个候选输出序列:
(1)A;(2)C;(3)AB;(4)CE;(5)ABD;(6)CED
最后基于这六个序列, 我们获得最终候选输出序列集合。然后我们选择其中条件概率乘积最高的序列作为输出序列:
1
L
α
l
o
g
P
(
y
1
,
.
.
.
,
y
L
∣
c
)
=
1
L
α
∑
t
′
=
1
L
l
o
g
P
(
y
t
′
∣
y
1
,
.
.
.
,
y
t
′
−
1
,
c
)
\frac{1}{L^α}logP(y_1,...,y_L|c)=\frac{1}{L^α}\sum_{t^{'}=1}^LlogP(y_{t^{'}}|y_1,...,y_{t^{'}-1},c)
Lα1logP(y1,...,yL∣c)=Lα1t′=1∑LlogP(yt′∣y1,...,yt′−1,c)
其中,L是最终候选序列的长度,α通常设为0.75。这样做是因为,一个较长的序列在求和中会有更多的对数项,因此分母用来惩罚长序列。
实际上,贪心搜索就可以看作是一种束宽为1的特殊类型的束搜索。束搜索可以在正确率和计算代价之间进行权衡。
小结
1、序列搜索策略包括贪心搜索、穷举搜索和束搜索。
2、贪心搜索所选取序列的计算量最小,但精度相对较低。
3、穷举搜索所选取序列的精度最高,但计算量最大。
4、束搜索通过灵活选择束宽,在正确率和计算代价之间进行权衡。