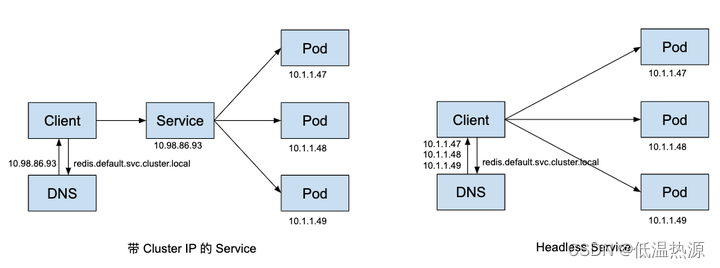
一、整体流程演示
上一篇我们进行了银行卡数字识别,这次我们利用opnecv等基础图像处理方法实现文档扫描OCR识别,该项目可以对任何一个文档,识别扫描出该文档上所有的文字信息。
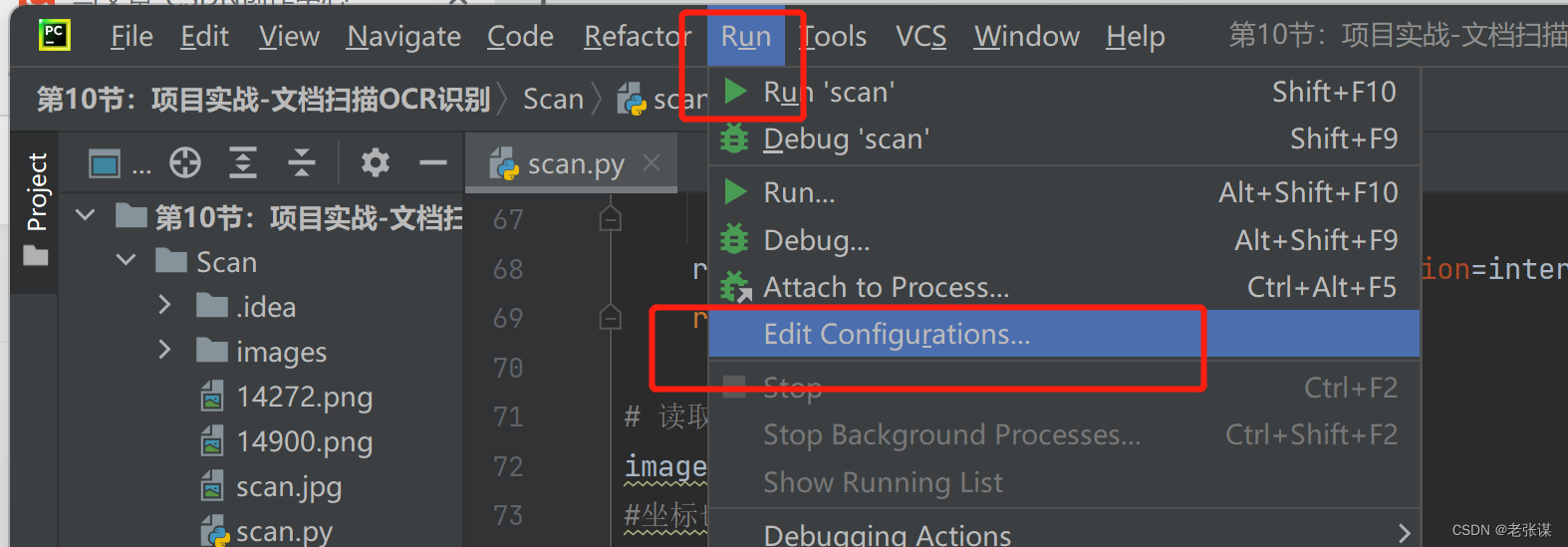
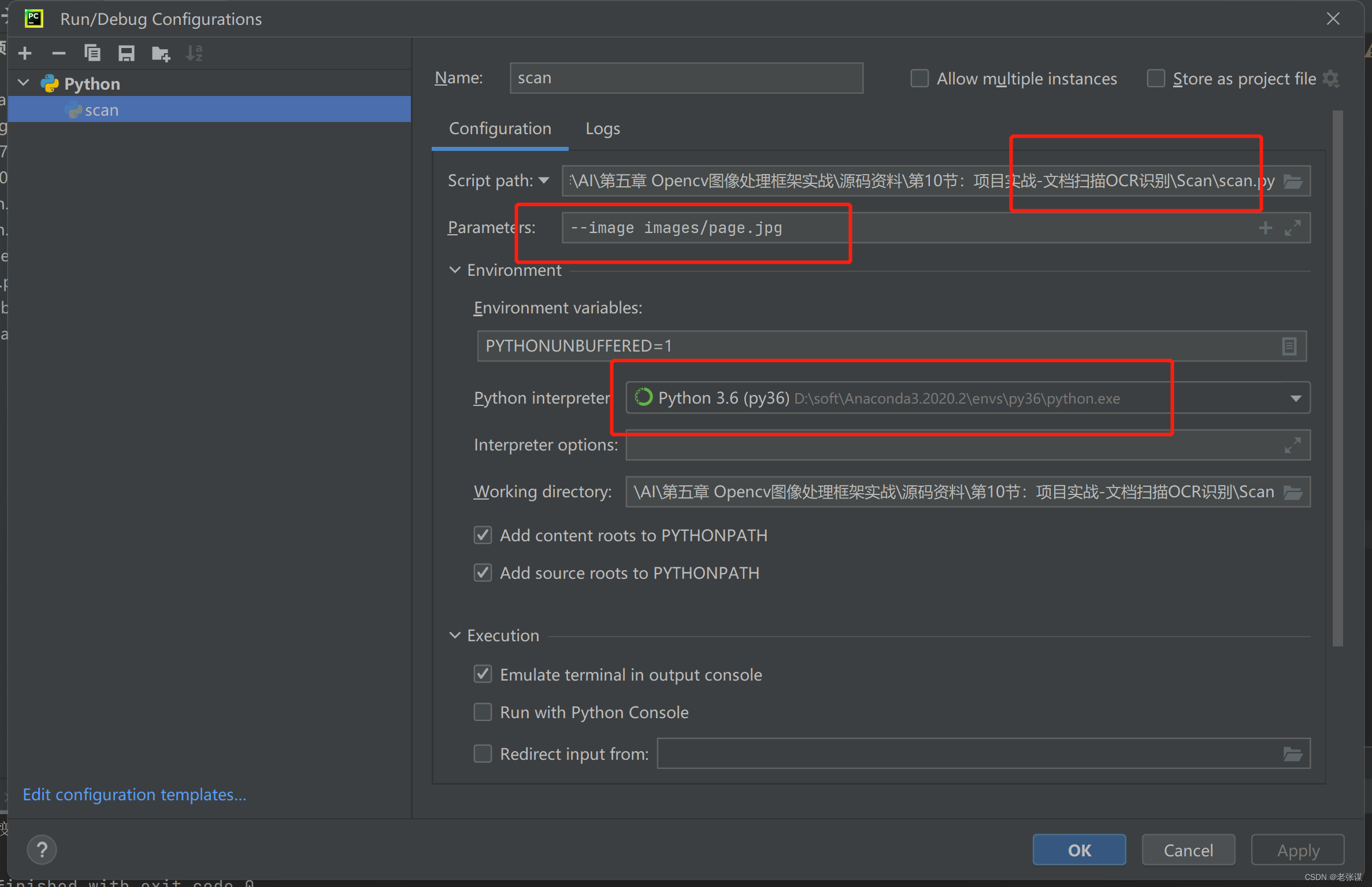
为了方便后续程序运行,大家可以在Run->Edit Configuration中配置相关参数,选择相应编译器、运行的代码文件,该代码需要传入的参数等,这样大家以后在运行的时候就不用每次都输入一遍参数,比较方便。配置过程如下图所示:
那具体如何实现呢,其实就包括两个事情,第一个就是把小票拿出来,第二个就是把拿出来的小票上文字的进行识别。
- 首先,先通过边缘检测, 拿到图片中间的小票部分,去掉冗余的背景信息
- 接下来,轮廓检测,把中间小票部分用框框起来,从而获取小票对象
- 透视变换。上一步只获取了这个对象,形状不规则,接下来,还需要进行透视变换操作,让整个小票横铺到图片大小,在图像配准里面是一个非常经典的操作。也是这次学习任务的重点。
通过上面这些预处理操作,就能得到一个非常规整且突出的只有小票信息的图片