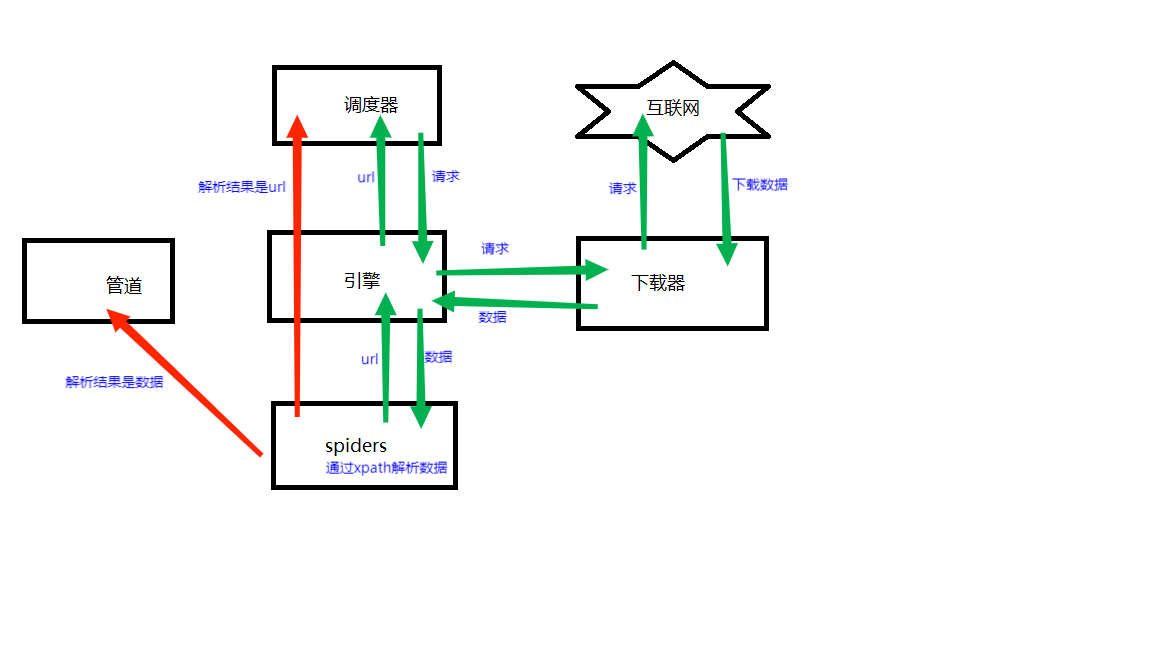
- 引擎向spiders要url
- 引擎把将要爬取的url给调度器
- 调度器会将url生成的请求对象放入到指定的队列中
- 从队列中出队一个请求
- 引擎将请求交给下载器进行处理
- 下载器发送请求获取互联网数据
- 下载器将数据返回给引擎
- 引擎将数据再次给到spiders
- spiders通过xpath解析该数据,得到数据或者url
- spiders将数据或者url给到引擎
- 引擎判断改数据是url,还是数据,是数据的话就交给管道(itempipeline)处理,是url的话就交给调度器处理
Python爬虫——scrapy_工作原理
news2026/2/16 12:31:07
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/883061.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

springboot集成ES
1.引入pom依赖2.application 配置3.JavaBean配置以及ES相关注解 3.1 Student实体类3.2 Teacher实体类3.3 Headmaster 实体类4. 启动类配置5.elasticsearchRestTemplate 新增 5.1 createIndex && putMapping 创建索引及映射 5.1.1 Controller层5.1.2 service层5.1.3 ser…
飞天使-jenkins进行远程linux机器修改某个文件的思路
文章目录 jenkins配置的方式jenkins中执行shell的思路 jenkins配置的方式 jenkins中执行shell的思路 下面的脚本别照抄,只是一个思路
ipall"$ips"# 将文本参数按行输出为变量
while IFS read -r line; doecho "$line"
if [[ ! -z $line ]] &…
linux——mysql的高可用MHA
目录
一、概述
一、概念
二、组成
三、特点
四、工作原理
二、案例
三、构建MHA
一、基础环境
二、ssh免密登录
三、主从复制
master
slave1
四、MHA安装
一、环境
二、安装node
三、安装manager 一、概述
一、概念 MHA(MasterHigh Availability&a…
Spring Boot 知识集锦之actuator监控端点详解
文章目录 0.前言1.参考文档2.基础介绍默认支持的端点 3.步骤3.1. 引入依赖3.2. 配置文件3.3. 核心源码 4.示例项目5.总结 0.前言 背景: 一直零散的使用着Spring Boot 的各种组件和特性,从未系统性的学习和总结,本次借着这个机会搞一波。共同学…
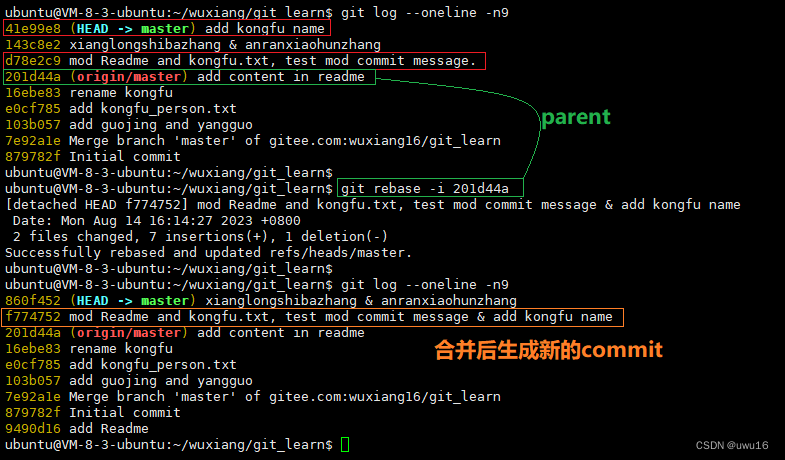
10 - 把间隔的几个commit整理成1个
查看所有文章链接:(更新中)GIT常用场景- 目录 文章目录 把间隔的几个commit整理成1个 把间隔的几个commit整理成1个

Elisp之获取PC电池状态(二十八)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…

xarray 简易体会与实现
1 基础原理
xarray1主要由 xarray 结点组成,xarray 结点主要由槽位(即指针)、父节点指针等组成。xarray 根据整型索引组织 xarray 结点实现对目标值的高效存、查、删操作。 此文以
存查删等流程对应源码2具体实例 —— xarray 结点槽位数 …

Databend 开源周报第 106 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.cn 。 Whats On In Databend
探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。
数据脱敏
Data…

【2022吴恩达机器学习课程视频翻译笔记】3.3代价函数公式
忙了一阵子,回来继续更新
3.3 代价函数公式
In order to implement linear regression. The first key step is first to define something called a cost function. This is something we’ll build in this video, and the cost function will tell us how well…
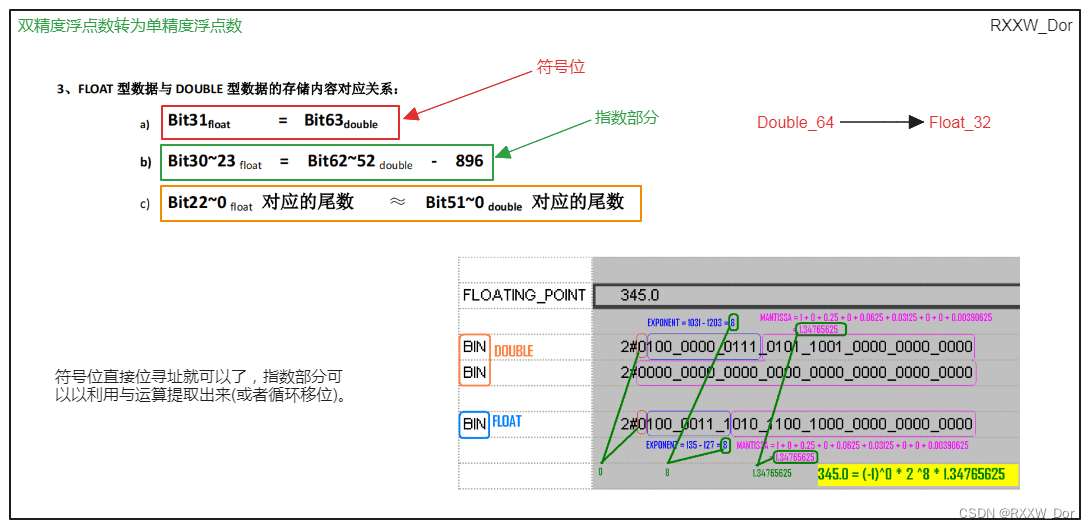
SMART PLC 64位双精度浮点数转32位单精度浮点数(Double_TO_Float)
有关博途PLC对位、字节、字元素的拆分和合并,请参看下面文章链接:
博途PLC 位/字/字节 Bit/ Word/Byte拆分与合并_博途的bit_RXXW_Dor的博客-CSDN博客有时候我们需要将分散分布的开关量信号组合为一个整体比如一个字节再完成发送,或者一些报警联锁控制,组合为一个字方便触…
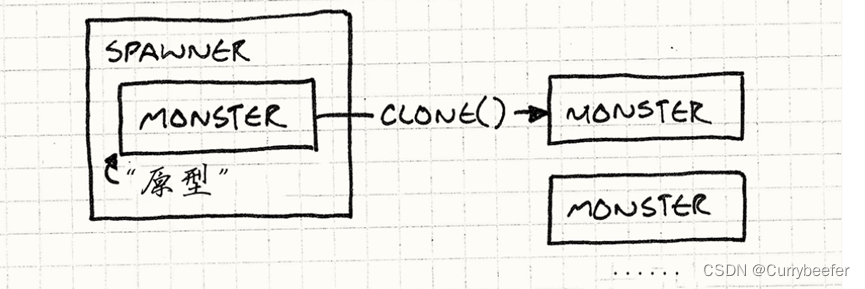
原型模式 Prototype Pattern 《游戏编程模式》学习笔记
原型的定义
用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
举个例子
假设我现在要做一款游戏,这个游戏里有许多不同种类的怪物,鬼魂,恶魔和巫师。这些怪物通过“生产者”进入这片区域,每种敌人…
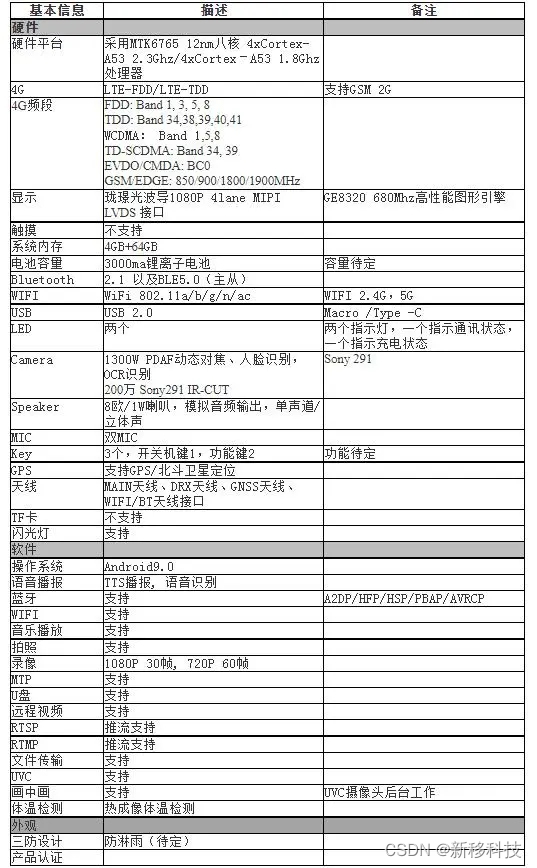
VR/AR眼镜方案,MTK联发科平台智能眼镜安卓主板设计方案
随着人工智能在不同领域的逐渐深入,人们对一款产品的需求不再局限于某种单一的功能或单一场景,尤其是在工业医疗等专业领域,加快数字化转型才能实现产业的升级。
AR智能眼镜,是一个可以让现场作业更智能的综合管控设备。采用移动…

实验三 图像分割与描述
一、实验目的: (1)进一步掌握图像处理工具Matlab,熟悉基于Matlab的图像处理函数。 (2)掌握图像分割方法,熟悉常用图像描述方法。 二、实验原理 1.肤色检测 肤色是人类皮肤重要特征之一ÿ…

Springboot 实践(4)swagger-ui 测试controller
前文项目操作,完成了项目的创建、数据源的配置以及数据库DAO程序的生成与配置。此文讲解利用swagger-ui界面,测试生成的数据库DAO程序。目前,项目swagger-ui界面如下: 以”用户管理”为例,简单讲述swagger-ui测试数据库…
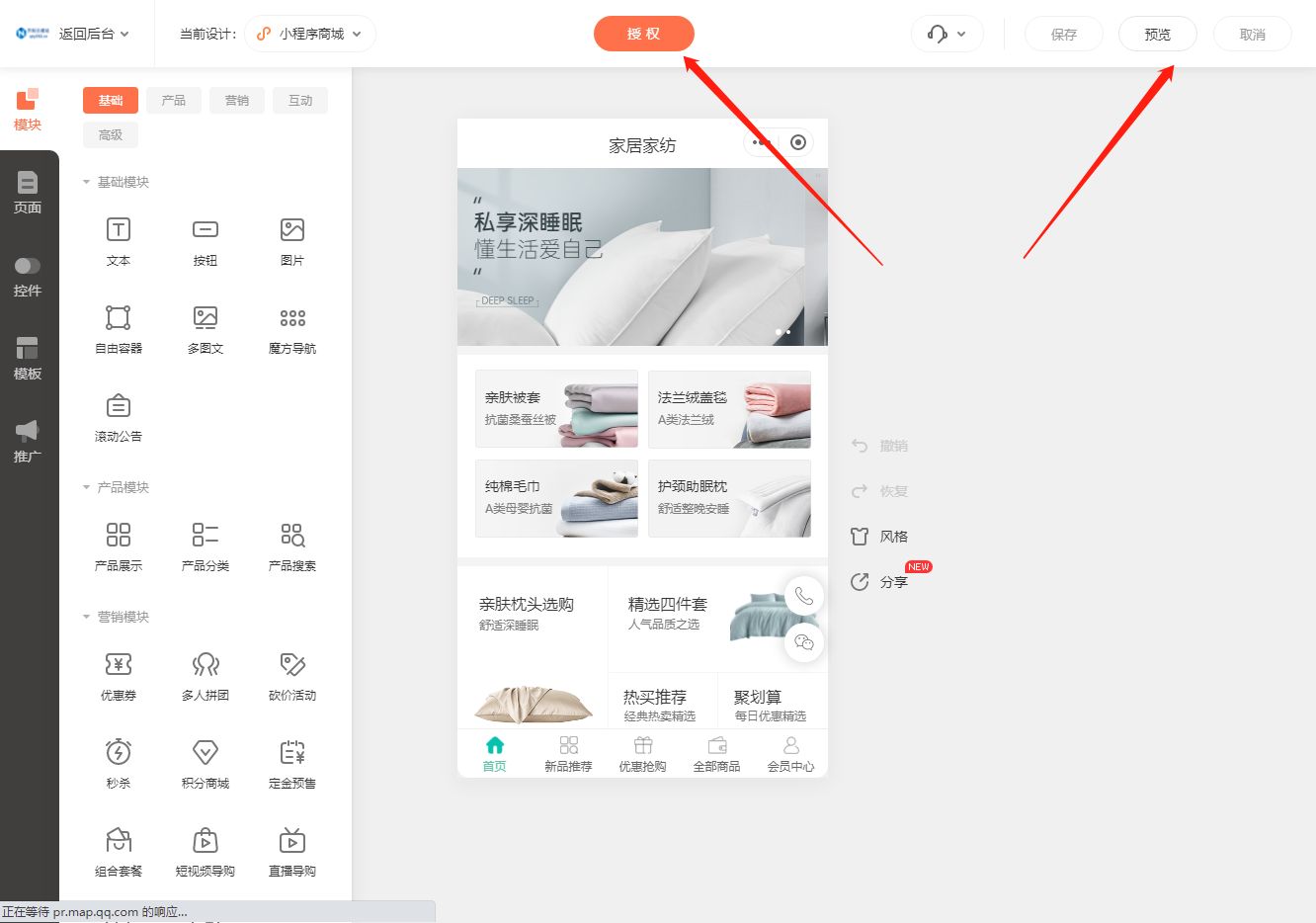
家纺行业小程序商城搭建指南
家纺行业作为一个不可或缺的消费领域,近年来备受关注。随着互联网的发展,小程序商城成为家纺行业拓展市场的新利器。搭建一个家纺行业小程序商城并不是一件困难的事情,只需要按照以下几个步骤进行操作,就能轻松上手。 首先&#x…
软件测试52讲-学习笔记
测试基础知识篇(11讲) 01 你真的懂测试吗?从“用户登录”测试谈起
测试用例设计框架 基于功能性需求和非功能性需求思考: 功能性需求使用等价类划分、边界值分析、错误推断法设计用例 非功能性需求考虑安全(信息的保存…
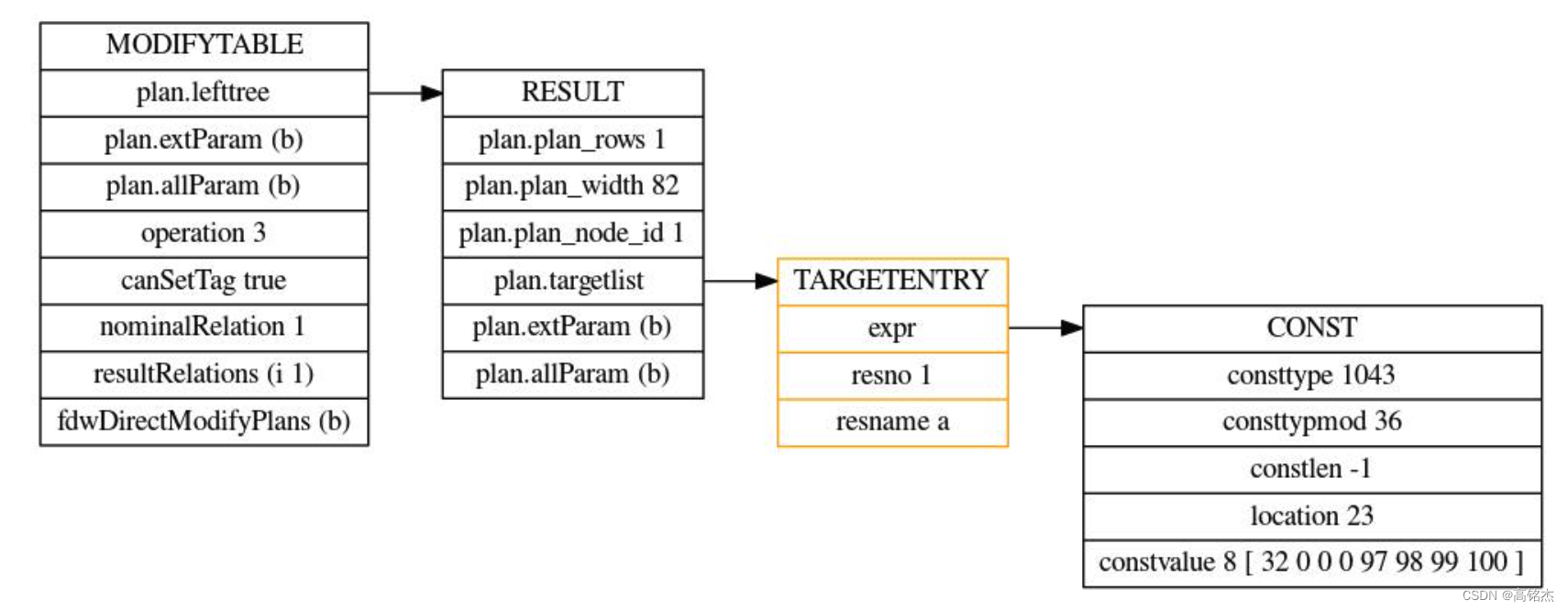
Postgresql源码(112)plpgsql执行sql时变量何时替换为值
相关 《Postgresql源码(41)plpgsql函数编译执行流程分析》 《Postgresql源码(46)plpgsql中的变量类型及对应关系》 《Postgresql源码(49)plpgsql函数编译执行流程分析总结》 《Postgresql源码(5…

【每日一题】—— B - Who is Saikyo?(AtCoder Beginner Contest 313)
🌏博客主页:PH_modest的博客主页 🚩当前专栏:每日一题 💌其他专栏: 🔴 每日反刍 🟡 C跬步积累 🟢 C语言跬步积累 🌈座右铭:广积粮,缓称…