Power Query中一些忽略的细节
- 重新认识Power Query
- 查询的引用----提高数据加载效率
- 透视逆透视----一对“好朋友”
- 神奇的拼接----实现很多意想不到的操作
重新认识Power Query
关于它的定义,这里不再赘述,主要说一些新的理解。
Power Query 可以理解就是一个 ETL 工具;他可以从几乎所有类型的数据源中提取数据,根据业务进行转换,然后加载应用。虽然,乍一看,它的很多功能在Excel都能实现,那它是不是就是Excel的替换品呢?答案是否定的。
当应用场景是只需要一次的处理,且数据量不大的情况下,Excel方便、快捷、上手快;但当这个处理过程是要每天循环呢?Excel就显得有点力不从心,所以这就是PQ的优点:
1.把重复的工作变成一次性工作(之后刷新即可更新数据)
2.很多数据处理操作,PQ有更高的效率和更方便的操作方式,不出现Excel中的 “卡死” 现象
查询的引用----提高数据加载效率
想象有这样一个业务场景:
对同一个数据源,需要进行不同的操作(分组、透视、提取、分裂等),然后使用相应的结果去做后续的分析,几次结果之间没法使用一张表呈现,怎么解决呢?
当然,最简单的肯定是用几次就做几个查询,然后问题就解决了!
是的,按上述的方法可以解决,但是,当业务数据很大时,加载就会花费很多的时间,这是业务中最不愿看到的,这就不得不说说PQ中的暂存设置。
基本思路就是加载一次数据源,对数据源不做任何操作,后续不同的操作直接对数据源进行引用,然后进行相应各自的操作,减少数据加载次数。具体步骤如下:
1.数据源直接加载,不做操作

2.对数据源右键选择引用(引用的数据源变成之前的数据源,而不是加载路径,只要之前的数据源变动,它也更着变动)
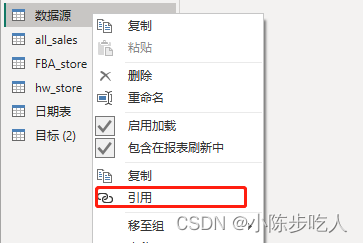
3.再在引用的查询后面进行相应的操作即可,不会影响数据源,也不会影响其他数据源的引用,而且数据只加载的一次(加载数据源)
笔者测试的原本更新一次数据源要花费200s(不暂存,直接加载三次数据源),而更换暂存逻辑后,更新一次数据,只需要90s,效果还是很明显的,尤其是在数据很大的业务中。
透视逆透视----一对“好朋友”
这里对透视和逆透视不再赘述,感兴趣的可以参考 透视和逆透视
这里只是说下,透视就是把行数据变成列数据,而逆透视就是把列数据换成行数据
换句话说,透视是把一维数据变成二(多)维数据,逆透视是把二(多)维数据变成一维数据
神奇的拼接----实现很多意想不到的操作
这里对拼接不再赘述,感兴趣的可以参考 PQ中的各种拼接
拼接的使用场景
1.多个相同数据的合并(纵向)
2.批量合并文件(可以理解成1的应用)
3.实现Excel中的vlookup(xlookup)等复杂映射(横向)
需要说明的是:PQ实现的拼接比Excel更加强大和复杂,类似于SQL中的内外联,实际业务中引用很方便