文章目录
- 正则表达式
- re模块最基础操作(匹配开头)
- 匹配单个字符
- 匹配多个字符
- 匹配开头结尾
- 匹配分组
- 对于group的理解
- r的作用
- re 模块高级用法
- compile
- search
- findall
- 易错点
- sub
- 直接替换
- 函数替换
- split 根据匹配进行切割字符串,并返回一个列表
- python 贪婪和非贪婪
- HTTP 协议
- 对于F12的一些组件介绍
- 浏览器解析过程
- http 协议的结束符
- B/S模式下的Web静态服务器
- Web 静态服务器-1-显示固定的页面
- Web 静态服务器-2-显示需要的页面
- Web 静态服务器-3-多进程
- Web 静态服务器-4-多线程
- Web 静态服务器-5-非堵塞模式
- Web 静态服务器-6-epoll
- Web 静态服务器-7-gevent 版
正则表达式
在 Python 中需要通过正则表达式对字符串进行匹配的时候,可以使用一个模块,名字为 re。
re模块最基础操作(匹配开头)
# 导入 re 模块
import re
# 使用 match 方法进行匹配操作
result = re.match(正则表达式,要匹配的字符串)
# 如果上一步匹配到数据的话,可以使用 group 方法来提取数据
result.group()
示例:
import re
result = re.match("helloworld","helloworld.cn")
print(result.group())
输出的结果:
helloworld
说明:re.match() 能够匹配出以== xxx 开头==的字符串
匹配单个字符
| 字符 | 功能 |
|---|---|
| . | 匹配任意 1 个字符(除了\n) |
| [ ] | 匹配[ ]中列举的字符 |
| \d | 匹配数字,即 0-9 dicimal |
| \D | 匹配非数字,即不是数字 |
| \s | 匹配空白,即 空格,tab 键 space |
| \S | 匹配非空白 |
| \w | 匹配单词字符,即 a-z、A-Z、0-9、_ (汉字) word |
| \W | 匹配非单词字 |
示例:
import re
ret = re.match("t.o","two")
print(ret.group())
# 大小写 h 都可以的情况
ret = re.match("[hH]","hello Python")
print(ret.group())
# 匹配 0 到 9 第二种写法
ret = re.match("[0-9]Hello Python","7Hello Python")
print(ret.group())
ret = re.match("[0-35-9]Hello Python","7Hello Python")
print(ret.group())
# 使用\d 进行匹配
ret = re.match("嫦娥\d 号","嫦娥 1 号发射成功")
print(ret.group())
# 等等
匹配多个字符
| 字符 | 功能 |
|---|---|
| * | 匹配前一个字符出现 0 次或者无限次,即可有可无 |
| + | 匹配前一个字符出现 1 次或者无限次,即至少有 1 次 |
| ? | 匹配前一个字符出现 1 次或者 0 次,即要么有 1 次,要么没有 |
| {m} | 匹配前一个字符出现 m 次 |
| {m,n} | 匹配前一个字符出现从 m 到 n 次 |
示例:
import re
# *的功能实现
ret = re.match("[A-Z][a-z]*","Aabcdef")
print(ret.group())
# 输出结果:Aabcdef
# +的功能实现
names = ["name1", "_name", "2_name", "__name__"]
for name in names:
ret = re.match("[a-zA-Z_]+[\w]*",name)
if ret:
print("变量名 %s 符合要求" % ret.group())
else:
print("变量名 %s 非法" % name)
# 输出结果:
# 变量名 name1 符合要求
# 变量名 _name 符合要求
# 变量名 2_name 非法
# 变量名 __name__ 符合要求
# ?的功能实现
ret = re.match("[1-9]?\d","09")
print(ret.group())
# 输出结果:0
# {m}的功能实现
ret = re.match("[a-zA-Z0-9_]{8,20}","1ad12f23s34455ff66")
print(ret.group())
# 输出结果:1ad12f23s34455ff66
匹配开头结尾
| 字符 | 功能 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
示例:
email_list = ["xiaoWang@163.com","xiaoWang@163.comheihei",".com.xiaowang@qq.com"]
for email in email_list:
ret = re.match("[\w]{4,20}@163\.com$", email)
if ret:
print("%s 是符合规定的邮件地址,匹配后的结果是:%s" %(email,ret.group()))
else:
print("%s 不符合要求" % email)
或者说,实际上我们仅需要所有情况下在最前面加上^ 最后面加上$也可以解决大多数问题。
匹配分组
| 字符 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中字符作为一个分组 |
| \num | 引用分组 num 匹配到的字符串 |
| (?P<name>) | 分组起别名 |
| (?P=name) | 引用别名为 name 分组匹配到的字 |
[^符号]* 代表没有遇到符号就一直进行匹配,一直匹配下去
例子:
import re
# |的使用
ret = re.match("[1-9]?\d$|100","100")
print(ret.group())
# 输出:100
# ()分组的使用
ret = re.match("\w{4,20}@(163|126|qq)\.com", "test@126.com")
print(ret.group())
# 输出:test@126
# ([^-]*) 代表没有遇到小横杠-就一直进行匹配,一直匹配下去
ret = re.match("([^-]+)-(\d+)","010-12345678")
print(ret.group())
# 输出:'010-12345678'
# 使用\num,需要注意的是,这边需要使用元字符串,即类似 r""这种格式
ret = re.match(r"<([a-zA-Z]*)>\w*</\1>", "<html>hh</html>")
print(ret.group())
# (?P<name>) (?P=name)
# 注意P要大写
ret = re.match(r"<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>","<html><h1>www.qq.com</h1></html>")
print(ret.group())
# 输出:<html><h1>www.qq.com</h1></html>
对于group的理解
实际上:
re.group(0)和re.group()输出的是符合的正则表达式的东西
re.group(1)输出的的是第一个分组内的东西(如果有分组才有这一项,没有的话就无这一项)
r的作用
Python 中字符串前面加上 r 表示原生字符串,
与大多数编程语言相同,正则表达式里使用"“作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符”“,那么使用编程语言表示的正则表达式里将需要 4 个反斜杠”\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python 里的原生字符串很好地解决了这个问题,有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
值得关注的是这个r只解决了//,就是只对/生效,如果需要匹配.,实际上也需要使用转义/.
re 模块高级用法
compile
compile实际上就是为了避免写这个正则表达式的式子太长,每次都要进行书写,就先把这个封装成一个对象,然后调用这个对象里面的方法进行使用。
com = re.compile(r'\d{4}/[01]?[0-9]/[1-3]?[0-9]\s(?:0[0-9]|1[0-9]|2[0-4])\:[0-5][0-9]')
com.match('2020/7/20 18:20')
search
功能:使用正则匹配式去字符串中寻找第一个符合该格式的子串
import re
ret = re.search(r"\d+", "阅读次数为 9999")
print(ret.group())
输出:
9999
findall
功能:寻找字符串中所有符合正则表达式的字串
基础样例:
import re
ret = re.findall(r"\d+", "python = 9999, c = 7890, c++ = 12345")
print(ret)
输出(值得关注的是返回的是一个列表,而非一个对象,然后使用group方法进行调用):
['9999', '7890', '12345']
易错点
对于包含分组的正则表达式,findall会去匹配分组内的正则表达式。
ret_s = hello world, now is 2020/7/20 18:48, 现在是2020/7/20 18:48
# compile避免了每次都去写正则,findall 有问题
com = re.compile(r'\d{4}/[01]?[0-9]/[1-3]?[0-9]\s(0[0-9]|1[0-9]|2[0-4]):[0-5][0-9]')
ret = com.findall(ret_s)
print(ret)
# ?:可以避免findall只提取分组内的内容
com1 = re.compile(r'\d{4}/[01]?[0-9]/[1-3]?[0-9]\s(?:0[0-9]|1[0-9]|2[0-4]):[0-5][0-9]')
ret = com1.findall(ret_s)
print(ret)
输出:
['18', '18']
['2020/7/20 18:48', '2020/7/20 18:48']
sub
功能:替换字符串
直接替换
import re
s = 'hello world, now is 2020/7/20 18:48, 现在是 2020 年 7 月 20 日 18 时 48 分。'
ret_s = re.sub(r'年|月', r'/', s)
ret_s = re.sub(r'日|分', r' ', ret_s)
ret_s = re.sub(r'时', r':', ret_s)
print(ret_s)
输出:
hello world, now is 2020/7/20 18:48, 现在是2020/7/20 18:48 。
函数替换
不论使用匿名函数还是使用真实的函数都是可以的,唯一值得关注的是传进来的对象是正则表达式匹配后的字符串类型的数据,如果需要整形化处理,记得加上int(),最后也需要返回str()类型的数据
import re
def add(temp):
strNum = temp.group()
num = int(strNum) + 1
return str(num)
ret = re.sub(r"\d+", add, "python = 997")
print(ret)
ret = re.sub(r"\d+", lambda temp: str(int(temp.group()) + 1), "python = 99")
print(ret)
split 根据匹配进行切割字符串,并返回一个列表
import re
ret = re.split(r":| ","info:xiaoZhang 33 shandong")
print(ret)
python 贪婪和非贪婪
Python 里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试匹配尽可能少的字符。
解决方式:非贪婪操作符“?”,这个操作符可以用在"*“,”+“,”?"的后面,要求正则匹配的越少越好。
test_str='''
<img data-original="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg" src="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg" style="display: inline;">
'''
# 贪婪的写法,最后得到的数据会匹配到最后一个jpg,实际上就是*一直吃到最后
print(re.search(r"https://.*\.jpg",test_str).group())
# 非贪婪的写法,最后得到的数据会匹配到最开始的一个jpg
print(re.search(r"https://.*?\.jpg", test_str).group())
输出结果:
https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg" src="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg
https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg
HTTP 协议
对于F12的一些组件介绍
监测一下百度官网(这边采用edge浏览器,其他的用谷歌的也是差不多的。)
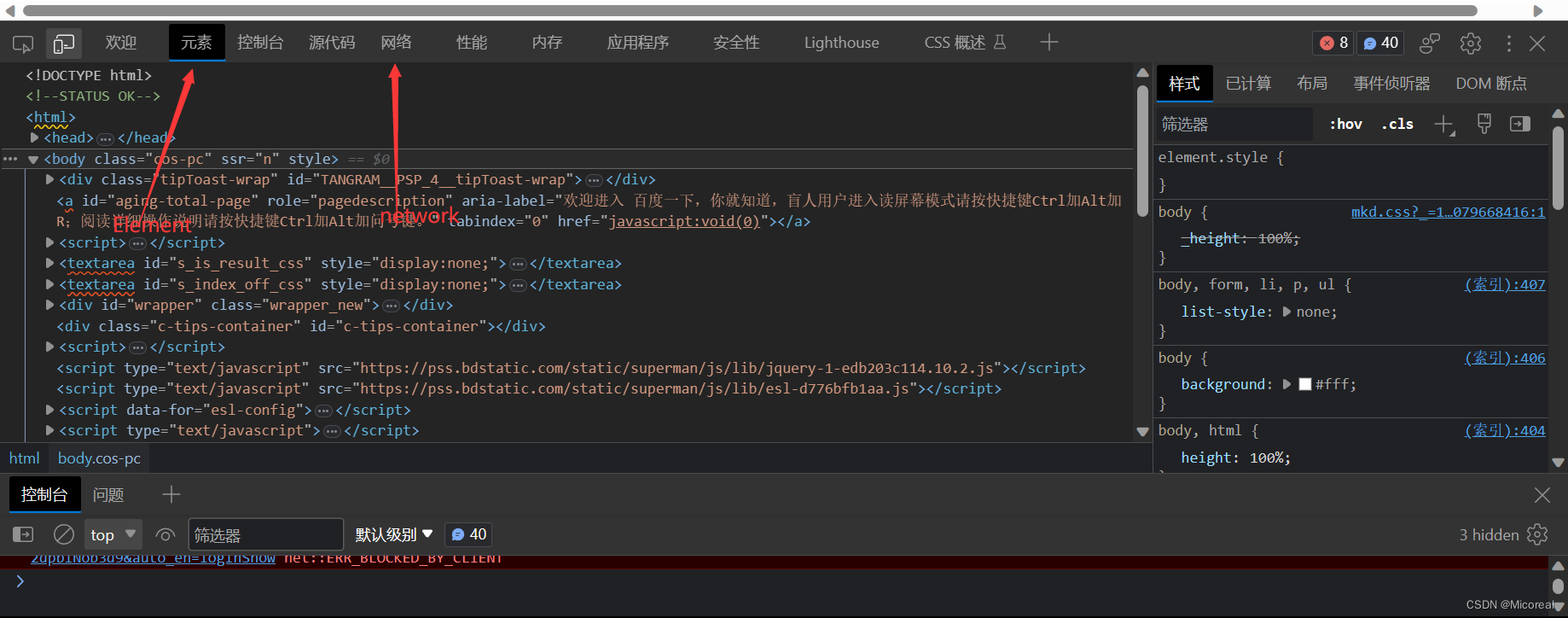
Elements 显示网页的结构
Network 显示浏览器和服务器的通信
我们点 Network,确保第一个小红灯亮着,浏览器就会记录所有浏览器和服务器之间的通信。
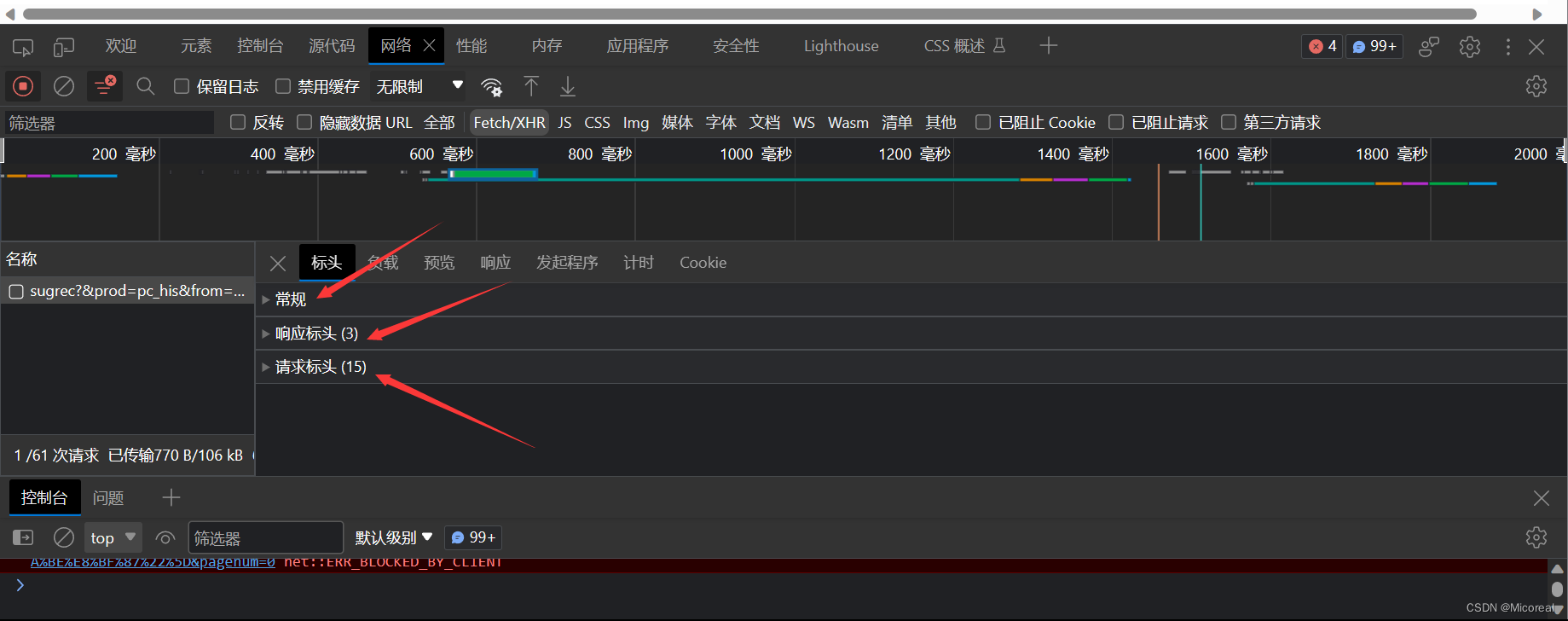
点开即可查看对应的是什么,然后进行对比以下的格式会有更深的领悟,这边列一下我这边接受到百度http协议的包,并对于比较重要的概念的介绍。
General(常规):
Request URL: https://www.baidu.com/
Request Method: GET
Status Code: 200 OK
Remote Address: 36.152.44.96:443
Referrer Policy: unsafe-url
- Request URL:即你请求的网站
- Request Method:请求资源的方法,一般请求资源的方法有四种:get(查询),post(新增),put(修改),delete(删除)
- Status Code:状态,200代表成功返回响应
- Remote Address:远程连接多少ip的多少port,而我们采用http即都是80端口,https是443端口
- Referrer Policy:来源页面政策,暂时不用了解,想要了解,可以百度
Response header(响应标头)这一部分就是服务器返回来的数据header:
HTTP/1.1 200 OK
Bdpagetype: 1
Bdqid: 0x87d5ef110007ca38
Connection: keep-alive
Content-Encoding: gzip
Content-Security-Policy: frame-ancestors 'self' https://chat.baidu.com http://mirror-chat.baidu.com https://fj-chat.baidu.com https://hba-chat.baidu.com https://hbe-chat.baidu.com https://njjs-chat.baidu.com https://nj-chat.baidu.com https://hna-chat.baidu.com https://hnb-chat.baidu.com http://debug.baidu-int.com;
Content-Type: text/html; charset=utf-8
Date: Tue, 15 Aug 2023 06:17:21 GMT
Server: BWS/1.1
Set-Cookie: BDSVRTM=0; path=/
Set-Cookie: BD_HOME=1; path=/
Set-Cookie: H_PS_PSSID=36544_39107_38831_26350_39138_39132_39100; path=/; domain=.baidu.com
Strict-Transport-Security: max-age=172800
Traceid: 169208024116233405549787992221453634104
X-Ua-Compatible: IE=Edge,chrome=1
Transfer-Encoding: chunked
HTTP 响应分为 Header 和 Body 两部分(Body 是可选项),我们在 Network 中看到的 Header 最重要的几行如下:
- HTTP/1.1 200 OK
200 表示一个成功的响应,后面的 OK 是说明。
如果返回的不是 200,那么往往有其他的功能,例如
1.1 失败的响应有 404 Not Found:网页不存在
1.2 500 Internal Server Error:服务器内部出错
1.3 …等等… - Content-Type: text/html
Content-Type 指示响应的内容,这里是 text/html 表示 HTML 网页。请注意,浏览器就是依靠 Content-Type 来判断响应的内容是网页还是图片,是视频还是音乐。浏览器并不靠 URL 来判断响应的内容,所以,即使 URL 是http://www.baidu.com/meimei.jpg,它也不一定就是图片。 - HTTP 响应的 Body 就是 HTML 源码,我们在菜单栏选择“视图”,“开发者”,“查看网页源码”就可以在浏览器中直接查看 HTML 源码
- Connection: keep-alive当中代表连接是长连接,也就是说你与服务器会保持连接,不会像短链接一样,仅仅在使用的时候connect服务器,发送完数据之后就结束连接
- Transfer-Encoding: chunked流式文件后面介绍
Request Header(请求头)这就是浏览器发给服务器的数据,因为这些数据是有格式的,所以就称作http协议:
GET / HTTP/1.1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cache-Control: max-age=0
Connection: keep-alive
Cookie: 这边有一串数据,里面包含了token等等一系列东西
Host: www.baidu.com
Referer: https://www.baidu.com/s?tn=15007414_9_dg&wd=%E7%99%BE%E5%BA%A6
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: same-origin
Sec-Fetch-User: ?1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.200
sec-ch-ua: "Not/A)Brand";v="99", "Microsoft Edge";v="115", "Chromium";v="115"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
最主要的头两行分析如下,第一行:
- GET / HTTP/1.1
GET 表示一个读取请求,将从服务器获得网页数据,/表示 URL 的路径,URL 总是以/开头,/就表示首页,最后的 HTTP/1.1 指示采用的 HTTP 协议版本是 1.1。目前 HTTP 协议的版本就是 1.1,但是大部分服务器也支持 1.0 版本,主要区别在于 1.1 版本允许多个 HTTP 请求复用一个 TCP 连接,以加快传输速度。 - 从第二行开始,每一行都类似于 Xxx: abcdefg:
- Host: www.sina.com
表示请求的域名是 www.baidu.com。如果一台服务器有多个网站,服务器就需要通过 Host 来区分浏览器请求的是哪个网站
浏览器解析过程
当浏览器读取到新浪首页的 HTML 源码后,它会解析 HTML,显示页面,然后,根据 HTML 里面的各种链接,再发送 HTTP 请求给新浪服务器,拿到相应的图片、视频、JavaScript 脚本、CSS 等各种资源,最终显示出一个完整的页面。所以我们在 Network 下面能看到很多额外的 HTTP 请求
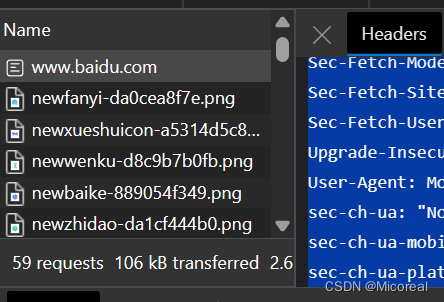
http 协议的结束符
http 的 header 和 body 之间空行分割的,又因为每个头部项是以 \r\n 作为结束符,所以,数据流中是以 \r\n\r\n 来分割解析请求头(响应头)与请求体(响应体)的。如下图所示:

理解一下使用/r/n/r/n进行隔断数据,但是现在这一句话也不是很正确,这边写者也只是粗浅理解。
补充:链接
B/S模式下的Web静态服务器
我们这边写的代码属于的就是web服务器端,算作对于前面网络编程epoll,进程池,线程池,协程的综合,虽然不如web服务器端常用的框架apache和nginx,但写一下还是有利于自己对于http协议以及一系列网络编程的理解:
Web 静态服务器-1-显示固定的页面
#! /bin/usr/python3.6
# 编辑人:lgt
# 时间2023年08月15日
import socket
def tcp_server():
# 创建socket对象
tcp_server = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# 复用端口
tcp_server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
# bind
tcp_server.bind(('',2000))
# listen
tcp_server.listen(128)
# 阻塞连接等待连接对象
client,client_arr = tcp_server.accept()
# 接收消息
http_head = client.recv(10000)
print(http_head.decode('utf-8'))
# 连接之后,这边默认直接返回一个前端的页面,第一个demo不搞太难
# response头的标准写法 每行的结束以\r\n为标志
response = "HTTP/1.1 200 OK\r\n"
# 多加个\r\n代表协议头结束
response += "\r\n"
# 此时加上body的内容
response += '<html><h1>hello world</h1></html>'
# 传回消息
client.send(response.encode('utf-8'))
client.close()
# 这边就不关闭tcp服务器了
if __name__ == '__main__':
tcp_server()
输出过去给浏览器的:
此时打开ipconfig进行查看,然后使用浏览器进行访问端口,即可看到对应的页面。
此时服务器端口能发现返回了这一个协议属性,所以我们可以再次进行相对应的修改

Web 静态服务器-2-显示需要的页面
这里我们思考一个问题,如果我们采用单进程有没有可能可以多个网页进行和服务器进行沟通,得到页面请求?
直觉告诉我们是不太可能的,原因就是我们的思想背局限在长连接上了,在短连接的情况下是完全可以做到的,下面就是使用单进程,短连接的方式进行写的。
import socket
import re
def tcp_server():
"""
tcp_server的创建
:return: None
"""
# 创建socket对象
tcp_server = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# 复用端口
tcp_server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
# bind
tcp_server.bind(('',2000))
# listen
tcp_server.listen(128)
while True:
# 阻塞连接等待连接对象
client,client_arr = tcp_server.accept()
solve_task(client)
# 关闭tcp服务器,实际上没有关闭,原因就是上面的是死循环
tcp_server.close()
def solve_task(client:socket):
"""
实现http协议传输以及接受需求的对应的网页资源的返回
:param client:客户端
:return:None
"""
# 接收消息
print('*' * 100)
http_head = client.recv(10000)
print(http_head.decode('utf-8'))
# 定义正则表达式,提取
print('*' * 100)
# [^/]*吞掉/之前所有的字符,后面重要部分使用()进行括起来,后面使用group(1)进行提取
re1 = re.compile(r'[^/]*(/[^ ]*)')
file1 = re1.match(http_head.decode('utf-8')).group(1)
print(file1)
if file1 == '/':
file1 = '/index.html'
# 拿到了想要返回的html的样式,这时候就应该返回相关的数据
try:
f = open('./html' + file1 , 'rb')
except:
# 如果文件没有找到
response = "HTTP/1.1 404 NOT FOUND\r\n"
# 多加个\r\n代表协议头结束
response += "\r\n"
response += "<html><h1>------file not found-----</h1></html>"
client.send(response.encode("utf-8"))
else:
# 如果文件找到了
# response头的标准写法 每行的结束以\r\n为标志
response = "HTTP/1.1 200 OK\r\n"
# 多加个\r\n代表协议头结束
response += "\r\n"
# 此时加上body的内容
body = f.read()
f.close()
# 传回消息
client.send(response.encode('utf-8'))
client.send(body)
# 此处是关键,判断短连接的重要标志
client.close()
if __name__ == '__main__':
tcp_server()
Web 静态服务器-3-多进程
import socket
import re
from multiprocessing import Process
def tcp_server():
"""
tcp_server的创建
:return: None
"""
# 创建socket对象
tcp_server = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# 复用端口
tcp_server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
# bind
tcp_server.bind(('',2000))
# listen
tcp_server.listen(128)
while True:
# 阻塞连接等待连接对象
client,client_arr = tcp_server.accept()
# 值得关注的是args=(client,)需要有一个,
p = Process(target=solve_task,args=(client,))
p.start()
# 此处为什么要关掉呢?这里因为我们使用的是进程,对于进程来说,资源属于引入计数,也就是别的进程到这里是复制主进程的所有的变量,再进去的,此时主进程就可以关掉了
client.close()
# 关闭tcp服务器,实际上没有关闭,原因就是上面的是死循环
tcp_server.close()
def solve_task(client:socket):
"""
实现http协议传输以及接受需求的对应的网页资源的返回
:param client:客户端
:return:None
"""
# 接收消息
print('*' * 100)
http_head = client.recv(10000)
print(http_head.decode('utf-8'))
# 定义正则表达式,提取
print('*' * 100)
# [^/]*吞掉/之前所有的字符,后面重要部分使用()进行括起来,后面使用group(1)进行提取
re1 = re.compile(r'[^/]*(/[^ ]*)')
file1 = re1.match(http_head.decode('utf-8')).group(1)
print(file1)
if file1 == '/':
file1 = '/index.html'
# 拿到了想要返回的html的样式,这时候就应该返回相关的数据
try:
f = open('./html' + file1 , 'rb')
except:
# 如果文件没有找到
response = "HTTP/1.1 404 NOT FOUND\r\n"
# 多加个\r\n代表协议头结束
response += "\r\n"
response += "<html><h1>------file not found-----</h1></html>"
client.send(response.encode("utf-8"))
else:
# 如果文件找到了
# response头的标准写法 每行的结束以\r\n为标志
response = "HTTP/1.1 200 OK\r\n"
# 多加个\r\n代表协议头结束
response += "\r\n"
# 此时加上body的内容
body = f.read()
f.close()
# 传回消息
client.send(response.encode('utf-8'))
client.send(body)
# 此处是关键,判断短连接的重要标志
client.close()
if __name__ == '__main__':
tcp_server()
Web 静态服务器-4-多线程
#! /bin/usr/python3.6
# 编辑人:lgt
# 时间2023年08月15日
import socket
import re
import threading
def tcp_server():
"""
tcp_server的创建
:return: None
"""
# 创建socket对象
tcp_server = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# 复用端口
tcp_server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
# bind
tcp_server.bind(('',2000))
# listen
tcp_server.listen(128)
while True:
# 阻塞连接等待连接对象
client,client_arr = tcp_server.accept()
# 值得关注的是args=(client,)需要有一个,
p = threading.Thread(target=solve_task,args=(client,))
p.start()
# 多线程时,client传递给子线程以后,主线程不能关闭
# client.close()
# 关闭tcp服务器,实际上没有关闭,原因就是上面的是死循环
tcp_server.close()
def solve_task(client:socket):
"""
实现http协议传输以及接受需求的对应的网页资源的返回
:param client:客户端
:return:None
"""
# 接收消息
print('*' * 100)
http_head = client.recv(10000)
print(http_head.decode('utf-8'))
# 定义正则表达式,提取
print('*' * 100)
# [^/]*吞掉/之前所有的字符,后面重要部分使用()进行括起来,后面使用group(1)进行提取
re1 = re.compile(r'[^/]*(/[^ ]*)')
file1 = re1.match(http_head.decode('utf-8')).group(1)
print(file1)
if file1 == '/':
file1 = '/index.html'
# 拿到了想要返回的html的样式,这时候就应该返回相关的数据
try:
f = open('./html' + file1 , 'rb')
except:
# 如果文件没有找到
response = "HTTP/1.1 404 NOT FOUND\r\n"
# 多加个\r\n代表协议头结束
response += "\r\n"
response += "<html><h1>------file not found-----</h1></html>"
client.send(response.encode("utf-8"))
else:
# 如果文件找到了
# response头的标准写法 每行的结束以\r\n为标志
response = "HTTP/1.1 200 OK\r\n"
# 多加个\r\n代表协议头结束
response += "\r\n"
# 此时加上body的内容
body = f.read()
f.close()
# 传回消息
client.send(response.encode('utf-8'))
client.send(body)
# 此处是关键,判断短连接的重要标志
client.close()
if __name__ == '__main__':
tcp_server()
Web 静态服务器-5-非堵塞模式
import time
import socket
import sys
import re
class WSGIServer(object):
"""定义一个WSGI服务器的类"""
def __init__(self, port, documents_root):
# 1. 创建套接字
self.server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 2. 绑定本地信息
self.server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.server_socket.bind(("", port))
# 3. 变为监听套接字
self.server_socket.listen(128)
self.server_socket.setblocking(False)
self.client_socket_list = list()
self.documents_root = documents_root
def run_forever(self):
"""运行服务器"""
# 等待对方链接
while True:
# time.sleep(0.5) # for test
#下面try的目的是接收请求并放入列表
try:
new_socket, new_addr = self.server_socket.accept()
except Exception as ret:
# print("-----1----", ret) # for test
pass
else:
print(time.time())
new_socket.setblocking(False)
self.client_socket_list.append(new_socket)
#遍历列表中的连接,如果有浏览器发过来数据,那么就处理
for client_socket in self.client_socket_list:
try:
request = client_socket.recv(4096).decode('utf-8')
except Exception as ret:
# print("------2----", ret) # for test
pass
else:
if request:#有数据就处理数据
self.deal_with_request(request, client_socket)
else:#浏览器断开了
client_socket.close()
self.client_socket_list.remove(client_socket)
print(time.time())
# print(self.client_socket_list)
def deal_with_request(self, request, client_socket):
"""为这个浏览器服务器"""
if not request:
return
request_lines = request.splitlines()
#这个for循环是为了打印看数据
# for i, line in enumerate(request_lines):
# print(i, line)
# 提取请求的文件(index.html)
# GET /a/b/c/d/e/index.html HTTP/1.1
ret = re.match(r"([^/]*)([^ ]+)", request_lines[0])
if ret:
# print("正则提取数据:", ret.group(1))
# print("正则提取数据:", ret.group(2))
file_name = ret.group(2)
if file_name == "/":
file_name = "/index.html"
# 读取文件数据
try:
f = open(self.documents_root+file_name, "rb")
except:
response_body = "file not found, 请输入正确的url"
response_header = "HTTP/1.1 404 not found\r\n"
response_header += "Content-Type: text/html; charset=utf-8\r\n"
response_header += "Content-Length: %d\r\n" % (len(response_body))
response_header += "\r\n"
# 将header返回给浏览器
client_socket.send(response_header.encode('utf-8'))
# 将body返回给浏览器
client_socket.send(response_body.encode("utf-8"))
else:
content = f.read()
f.close()
response_body = content
response_header = "HTTP/1.1 200 OK\r\n"
response_header += "Content-Length: %d\r\n" % (len(response_body))
response_header += "\r\n"
# 将header返回给浏览器
client_socket.send( response_header.encode('utf-8') + response_body)
# 设置服务器服务静态资源时的路径
DOCUMENTS_ROOT = "./html"
def main():
"""控制web服务器整体"""
# python3 xxxx.py 7890
if len(sys.argv) == 2:
port = sys.argv[1]
if port.isdigit():
port = int(port)
else:
print("运行方式如: python3 xxx.py 7890")
return
print("http服务器使用的port:%s" % port)
http_server = WSGIServer(port, DOCUMENTS_ROOT)
http_server.run_forever()
if __name__ == "__main__":
main()
Web 静态服务器-6-epoll
import socket
import re
import select
def service_client(new_socket, request):
"""为这个客户端返回数据"""
# 1. 接收浏览器发送过来的请求 ,即http请求
# GET / HTTP/1.1
# .....
# request = new_socket.recv(1024).decode("utf-8")
# print(">>>"*50)
# print(request)
if not request:
return
request_lines = request.splitlines()
print("")
print(">"*20)
print(request_lines)
if not request_lines:
return
# GET /index.html HTTP/1.1
# get post put del
file_name = ""
ret = re.match(r"[^/]+(/[^ ]*)", request_lines[0])
if ret:
file_name = ret.group(1)
# print("*"*50, file_name)
if file_name == "/":
file_name = "/index.html"
# 2. 返回http格式的数据,给浏览器
try:
f = open("./html" + file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "------file not found-----"
new_socket.send(response.encode("utf-8"))
else:
html_content = f.read()
f.close()
response_body = html_content
response_header = "HTTP/1.1 200 OK\r\n"
response_header += "Content-Length:%d\r\n" % len(response_body)
response_header += "\r\n"
response = response_header.encode("utf-8") + response_body
new_socket.send(response)
def main():
"""用来完成整体的控制"""
# 1. 创建套接字
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2. 绑定
tcp_server_socket.bind(("", 7890))
# 3. 变为监听套接字
tcp_server_socket.listen(128)
tcp_server_socket.setblocking(False) # 将套接字变为非堵塞
# 创建一个epoll对象
epl = select.epoll()
# 将监听套接字对应的fd注册到epoll中
epl.register(tcp_server_socket.fileno(), select.EPOLLIN)
fd_event_dict = dict()
while True:
fd_event_list = epl.poll() # 默认会堵塞,直到 os监测到数据到来 通过事件通知方式 告诉这个程序,此时才会解堵塞
# [(fd, event), (套接字对应的文件描述符, 这个文件描述符到底是什么事件 例如 可以调用recv接收等)]
for fd, event in fd_event_list:
# 等待新客户端的链接
if fd == tcp_server_socket.fileno():
new_socket, client_addr = tcp_server_socket.accept()
epl.register(new_socket.fileno(), select.EPOLLIN)
fd_event_dict[new_socket.fileno()] = new_socket #字典,键是fileno
elif event==select.EPOLLIN:
# 判断已经链接的客户端是否有数据发送过来
#如何通过不遍历来定位socket
recv_data = fd_event_dict[fd].recv(4096).decode("utf-8")
if recv_data:
service_client(fd_event_dict[fd], recv_data)
else:
fd_event_dict[fd].close()
epl.unregister(fd)
del fd_event_dict[fd] #从字典中移除
# 关闭监听套接字
tcp_server_socket.close()
if __name__ == "__main__":
main()
Web 静态服务器-7-gevent 版
import socket
import re
import gevent
from gevent import monkey
# monkey组件
monkey.patch_all()
def service_client(new_socket):
'''为客户端返回数据'''
# 接收http请求
request = new_socket.recv(1024).decode('utf-8')
if request:
request_lines = request.splitlines()
print("")
print(">" * 20)
print(request_lines)
file_name = ""
ret = re.match(r"[^/]+(/[^ ]*)", request_lines[0])
if ret:
file_name = ret.group(1)
if file_name == "/":
file_name = "/index.html"
print(file_name)
try:
f = open("./html" + file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "-------file not found-------"
new_socket.send(response)
else:
html_content = f.read()
f.close()
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
new_socket.send(response.encode('utf-8'))
new_socket.send(html_content)
new_socket.close()
def main():
'''创建套接字'''
# 初始化
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定
tcp_server_socket.bind(("", 7890))
# 激活
tcp_server_socket.listen(128)
while True:
new_socket, socket_addr = tcp_server_socket.accept()
gevent.spawn(service_client, new_socket)
tcp_server_socket.close()
if __name__ == '__main__':
main()