人工智能之基本概念
- 常见问题
- 什么是人工智能?
- 人工智能应用在那些地方?
- 人工智能的三种形态
- 图灵测试是啥?
- 人工智能、机器学习和深度学习之间是什么关系?
- 为什么人工智能计算会用到GPU?
- 机器学习
- 什么是机器学习?
- 标签、特征、样本、模型
- 监督学习、无监督学习、半监督学习、弱监督学习、自监督学习
- 强化学习、对抗学习、对比学习
- 回归和分类
- 聚类
- 模式识别和机器学习的区别
- 神经网络
- 什么是神经网络?
- 神经网络的逻辑架构
常见问题
什么是人工智能?
人工智能(Artificial Intelligence,AI):根据对环境的感知做出合理行动,并获得最大收益的计算程序。
人工智能应用在那些地方?
计算机视觉(Computer Vision,CV):图像分类、物体检测、语义分析、视频分析等等。
语音识别(Speech Recognition,SR):声纹识别、语音合成。
自然语言处理(Natural Language Processing,NLP):机器翻译、阅读理解、自动摘要、文本分类、中文分词。
推荐系统(Recommendation System):实现个性化推荐,例如抖音。
专家系统(Expert System):模拟人类专家解决特定的问题,专家系统=知识库+推理机。
人工智能的三种形态
弱人工智能 (Artificial Narrow Intelligence, ANI):擅长与单个方面的人工智能,例如围棋大胜中韩顶尖高手的阿尔法狗。
强人工智能(Artificial General Intelligence, AGI):人类级别的人工智能,指在各方面都能和人类比肩的人工智能,目前还做不到。
超人工智能 (Artificial Super Intelligence, ASI):几乎所有领域都比最聪明的人类大脑都聪明很多,小说电影里面经常见到。
图灵测试是啥?
图灵测试(The Turing test):是用来判断机器是否又类似人类“智能”的测试。测试人在与被测试者(一个人和一台机器)隔开的情况下,通过一些装置(如键盘)向被测试者随意提问,如果有超过30%的测试者不能确定被测者是人还是机器,那么这个机器就通过了图灵测试。
人工智能、机器学习和深度学习之间是什么关系?
机器学习是实现人工智能最常用的方法,而深度学习是机器学习的一个分支,主要用于神经网络。
人工智能>机器学习>深度学习>神经网络。
为什么人工智能计算会用到GPU?
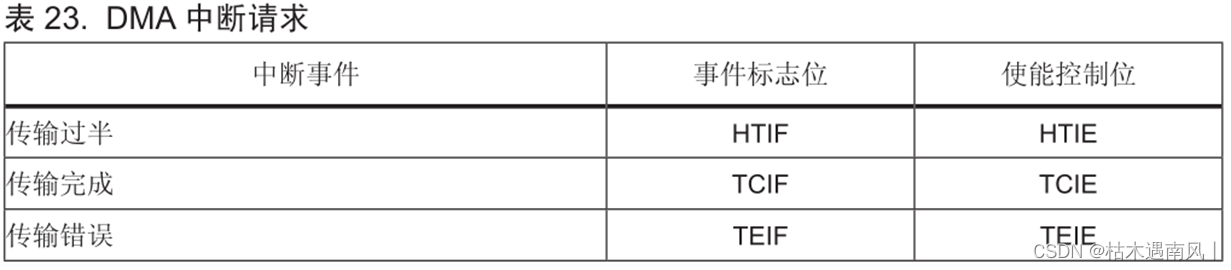
CPU和GPU的区别:
结构上来说,虽然CPU和GPU都有控制单元、运算单元和缓存,但是CPU需要大量空间存放控制单元和缓存,而GPU中运算单元占了大部分。
功能上来说,由于结构上占比,所以CPU在大规模并行计算能力上极受限制,而更擅长逻辑控制。而GPU有数量众多的计算单元和超长的流水线,非常适合计算海量同类型处理的数据。
GPU比CPU的优势在于能提供高性能的并行运算,而对模型训练常常需要大规模的数据集,可以通过算法并行优化来提高运行效率。
机器学习
什么是机器学习?
机器学习(Machine Learning):从数据中自动分析获得模型,并利用模型对未知数据进行预测。
例如人脸识别,从大量的人脸数据集中训练得到模型,模型可以对没见过的图片进行人脸识别。
标签、特征、样本、模型
标签:输出变量,例如要判断图片动物品种,这个品种结果就是标签。
特征:输入变量,例如要判断图片动物品种,动物有没有角、毛发等,就是特征。
样本:指的是数据特定的实例,分为有标签样本(标签+特征)和无标签样本(特征)。
模型:模型定义了特征和标签之间的关系,通过训练后的模型来预测无标签样本的标签。
监督学习、无监督学习、半监督学习、弱监督学习、自监督学习
监督学习(Supervised Learning):训练数据有输入值也有输出值,也就是既有特征也有标签,训练其能够给数据正确的标签。
无监督学习(Unsupervised Learning):训练数据是没有输出值的,有特征没有标签,训练其能够对观察值就行分类或区分。
弱监督学习(Weakly Supervised Learning):只有很弱的标签,但是要去完成一个很强的任务。例如要对目标进行分割,但是数据的标签只有类别没有位置。
半监督学习(Semi-supervised Learning):利用少量有标签的数据和大量无标签的数据来训练网络,减少标注成本。通常分为两个阶段训练,先用有标签数据训练一个Teacher模型,再用Teacher模型对无标签数据预测伪标签,让伪标签的数据集作为Student模型的训练数据。
自监督学习(Self-supervised Learning): 属于无监督的一个分支,它的目标是更好地利用无监督数据,提升后续监督学习任务的效果。首先定义一个Pretext task (辅助任务),即从无监督的数据中,通过巧妙地设计自动构造出有监督(伪标签)数据,学习一个预训练模型。
强化学习、对抗学习、对比学习
强化学习(Reinforcement Learning):通过不断试错来学习,需要和环境大量的交互尝试,例如AlphaGo。
对抗学习(Adversarial Learning ):一些精心设计的对抗样本可以使机器学习模型输出错误的结果,研究有什么办法攻击学习器。
对比学习(Contrastive Learning):是一种自监督学习的方法,通过学习目标之间的相似性来判断目标的类别。对比学习被称为自监督学习,是因为人们可以使用代理任务(Pretext task)来定义谁与谁相似。
回归和分类
监督学习分为两大类问题:回归和分类。
回归:预测连续值,例如某地区的房价。
分类:预测离散值,例如判断图片动物配种。
聚类
聚类:聚类属于无监督学习,是一种数据分组技术。可以把数据组的每个数据划分到特定组里,相似的数据处在同一簇,不相似数据处在不同簇。
和分类的区别:分类是一开始就知道要分多少种类,而聚类是不会事先预定类别。
模式识别和机器学习的区别
模式识别:根据样本的特征将样本划分到一定的类别中去,通常分为分类(已知类别)和聚类(创建新类别)。
模式识别和机器学习的区别:机器学习是从大量数据中自动分析获得规律,并利用规律对未知数据进行预测;模式识别根据样本的特征将样本划分到一定的类别中去,其过程包括特征提取与选择、训练学习和分类识别。
神经网络
什么是神经网络?
神经网络(Neural Network):又称为人工神经网络(Artificial Neural Network,ANN),模仿神经网络来模拟大脑。
神经网络的逻辑架构
神经网络的逻辑架构:输入层、中间层、输出层。
输入层:负责接收信号。
中间层:又称之为隐藏层,对数据的分解与处理。
输出层:最后的结果会被整合到输出层。
节点:图中的每个圆是一个节点,相当于模拟了大脑神经元。
激活函数:每个节点代表一种特定输出函数,通常称为激活函数。
权重:每两个节点之间的联接的加权值称之为权重。
运作方式:每个节点会获得输入值,通过激活函数计算得到输出值,输出值通过联接权重的加权传给下一个节点或者直接输出。