Abstract
高动态范围(HDR)去鬼算法旨在生成具有真实感细节的无鬼HDR图像。 受感受野局部性的限制,现有的基于CNN的方法在大运动和严重饱和度的情况下容易产生重影伪影和强度畸变。 本文提出了一种新的上下文感知视觉转换器(CA-VIT)用于高动态范围无鬼影成像。 CA-VIT被设计为一个双分支体系结构,可以联合捕获全局和局部依赖关系。 具体来说,全局分支采用基于窗口的变压器编码器来模拟远距离物体运动和强度变化,以解决重影问题。 对于局部分支,我们设计了一个局部上下文提取器(LCE)来捕获图像的短程特征,并利用通道关注机制在提取的特征中选择信息丰富的局部细节来补充全局分支。 通过将CA-VIT作为基本组件,我们进一步构建了HDR-Transformer这一层次化网络来重建高质量的无鬼影HDR图像。 在三个基准数据集上进行的大量实验表明,我们的方法在定性和定量方面都优于现有的方法,并大大减少了计算预算。 代码可在https://github.com/megvii-research/hdr-transformer获得。
1 Introduction
多帧高动态范围(HDR)成像的目的是通过合并多幅不同曝光度的低动态范围(LDR)图像来生成具有更宽动态范围和更真实细节的图像,如果它们完全对齐,则可以很好地融合到HDR图像[31,32,21,41,23,20]。 然而,在实际应用中,这种理想情况往往会受到摄像机运动和前景动态物体的破坏,在重建HDR结果中产生不利的重影伪影。 因此,为了获得高质量的无鬼HDR图像,人们提出了各种方法,通常称为HDR去鬼算法。
传统上,有几种方法提出在图像融合前通过对输入的LDR图像[2,10,14,42]进行对齐或剔除未对齐的像素[7,8,27,11,15]来去除重影伪影。 然而,精确的对齐是一个挑战,当有用的信息因不精确的像素拒绝而丢失时,整体HDR效果会降低。 因此,基于CNN的学习算法以数据驱动的方式通过挖掘深层特征来解决重影伪影。
现有的基于CNN的去重影方法主要可以分为两类。 在第一类中,使用单应性[9]或光流[1]对LDR图像进行预对准,然后使用CNN[13,29,28,37]执行多帧融合和HDR重建。 然而,单应性不能对齐前景中的动态目标,并且光流在存在遮挡和饱和时是不可靠的。 因此,第二类提出了带有隐式对准模块[39,19,4]或新的学习策略[25,30]的端-端网络来处理重影伪影,实现最先进的性能。 然而,当面对远距离物体移动和强度变化时,这种限制就会出现。 图 1显示了一个典型的场景,其中发生了大的运动和严重的饱和,在以前基于CNN的方法的结果中产生了意想不到的重影和失真伪影。 究其原因,在于卷积内在的局部性限制。 CNN需要堆叠深层以获得大的感受野,因此无法对长程依赖性进行建模(例如,由大运动引起的重影伪影)[24]。 此外,卷积与内容无关,因为在整个图像中共享相同的核,忽略了不同图像区域的长程强度变化[16]。 因此,探索具有远程建模能力的内容相关算法是进一步提高性能的要求。
视觉变压器(VIT)[6]由于其优越的远程建模能力,近年来受到越来越多的研究兴趣。 然而,我们的实验结果表明,两个主要问题阻碍了它在HDR去重影中的应用。 一方面,变压器缺乏CNN固有的归纳偏差,因此当在不充足的数据量上训练时不能很好地概括[6,16],尽管事实上用于HDR去重影的可用数据集有限,因为收集大量真实的标记样本成本高得令人望而却步。 另一方面,帧内和帧间的相邻像素关系对于恢复多帧间的局部细节是至关重要的,而纯变压器对于提取这种局部上下文是无效的。
为此,我们提出了一种新的上下文感知视觉转换器(CAVIT),该转换器采用双分支结构来同时捕获全局和局部依赖关系。 对于全局分支,我们采用基于窗口的多头变压器编码器来捕获远程上下文。 对于局部分支,我们设计了一个局部上下文提取器(LCE),通过卷积块提取局部特征映射,并通过信道关注机制在多帧中选择最有用的特征。 因此,拟议的CA-VIT使地方和全球背景以互补的方式发挥作用。 通过与CA-VIT相结合,我们提出了一种新的基于变换器的HDR-Transformer框架(简称HDR-Transformer)用于无鬼影HDR成像。
具体而言,所提出的HDR转换器主要由特征提取网络和HDR重构网络组成。 特征提取网络提取浅层特征,并通过空间注意力模块进行粗融合。 早期卷积层可以稳定视觉变压器的训练过程,空间注意力模块有助于抑制不期望的失调。 HDR重构网络以提出的CA-VIT为基本构件,分层构成。 CA-VITS既能模拟长程重影伪影,又能模拟局部像素关系,从而帮助重建无重影的高质量HDR图像(图1中展示了一个例子),而不需要堆叠非常深的卷积块。 综上所述,本文的主要贡献可归纳如下:
-我们提出了一个新的视觉转换器,称为CA-VIT,它可以充分利用全局和局部图像上下文依赖关系,显示出显着的性能改进比以前的同行。
-我们提出了一个新的HDR转换器,能够消除重影伪影和重建高质量的HDR图像,以较低的成本。 据我们所知,这是第一个基于Transformer的HDR去重影框架。
-我们在三个有代表性的基准HDR数据集上进行了广泛的实验,证明了HDR-Transformer对现有最先进方法的有效性。
2 Related Work
2.1 HDR Deghosting Algorithms
我们将现有的HDR去重影算法归纳为三类,即运动抑制方法、图像配准方法和基于CNN的方法。
Motion rejection methods
提出了一种基于运动抑制的LDR图像全局配准方法,然后对检测到的不对齐像素进行抑制。 格罗希等人基于对齐颜色差异生成错误映射以拒绝不匹配的像素[8]。 佩切等人使用输入LDR图像的中值阈值位图检测运动区域[27]。 雅各布斯等人使用加权强度方差分析确定失调位置[11]。 张等人[41]和Khan等人[15]提出分别计算LDR输入图像的梯度域权重图和概率图。 此外,Oh等人提出了一种用于检测重影区域的秩最小化方法[26]。 这些方法经常产生令人不快的HDR结果,因为丢失了有用的信息,同时拒绝像素。
Motion registration methods
运动配准方法依赖于在合并前将非参考LDR图像与参考图像对齐。 Begoni等人提出利用光流来预测运动矢量[2]。 康等人根据曝光时间将LDR图像强度转移到亮度域,然后估计光流以说明运动[14]。 齐默等人通过首先将LDR图像与光流配准来重建HDR图像[42]。 森等人提出了一种基于贴片的能量最小化方法,同时优化对准和HDR重建[33]。 胡等人提出了在变换域上使用亮度和梯度一致性来优化图像对齐[10]。 运动配准方法比运动拒绝方法具有更强的鲁棒性。 然而,当大的运动发生时,这种方法会产生可见的重影伪影。
CNN-based methods
最近提出了几种基于CNN的方法。 卡兰塔里等人提出了第一种基于CNN的动态场景多帧HDR成像方法。 他们使用CNN将LDR图像与光流对齐后混合在一起[13]。 吴等人通过将HDR成像描述为一个图像转换问题,开发了第一个非基于流的框架[37],而不是使用显式对齐,Yan等人采用空间关注模块来解决重影伪影[39]。 普拉巴卡尔等人提出了一种利用双侧引导上采样器生成HDR图像的有效方法[28],并进一步探索了零镜头和少镜头学习用于HDR去重影[30]。 最近,牛等人提出了第一个基于GaN的多帧HDR成像框架[25]。 基于CNNS的方法显示了优越的能力,并实现了最先进的性能。 然而,当面对大运动和极端饱和度时,仍然可以观察到重影伪影。
2.2 Vision Transformers
Transformers在自然语言处理领域取得了巨大的成功[36,5],其中多头自关注机制被用来捕捉词令牌嵌入之间的长程相关性。 最近,Vit[6]表明,纯变压器可以直接应用于不重叠的图像块序列,并在图像分类任务中表现得很好。 刘等人开发了SWIN变压器,一种通过移位窗口方案捕获交叉窗口上下文的分层结构[18]。 陈等人建立了IPT,一个用于低级计算机视觉任务的预训练变压器模型[3]。 梁等人扩展了用于图像恢复的SWIN变换,提出了SWINIR,在图像超分辨率和去噪方面达到了最先进的性能[16]。 与基于CNN的方法不同,我们的方法受到[18,16]的启发,并建立在变形金刚之上。
3 Method
3.1 CA-ViT
与现有的视觉转换器采用纯转换器编码器不同,我们提出了一种双分支上下文感知视觉转换器(CA-VIT),它可以同时挖掘全局和局部图像信息。 正如图中所描绘的 2(a),CA-VIT由全局变压器编码器分支和局部上下文提取分支构成。
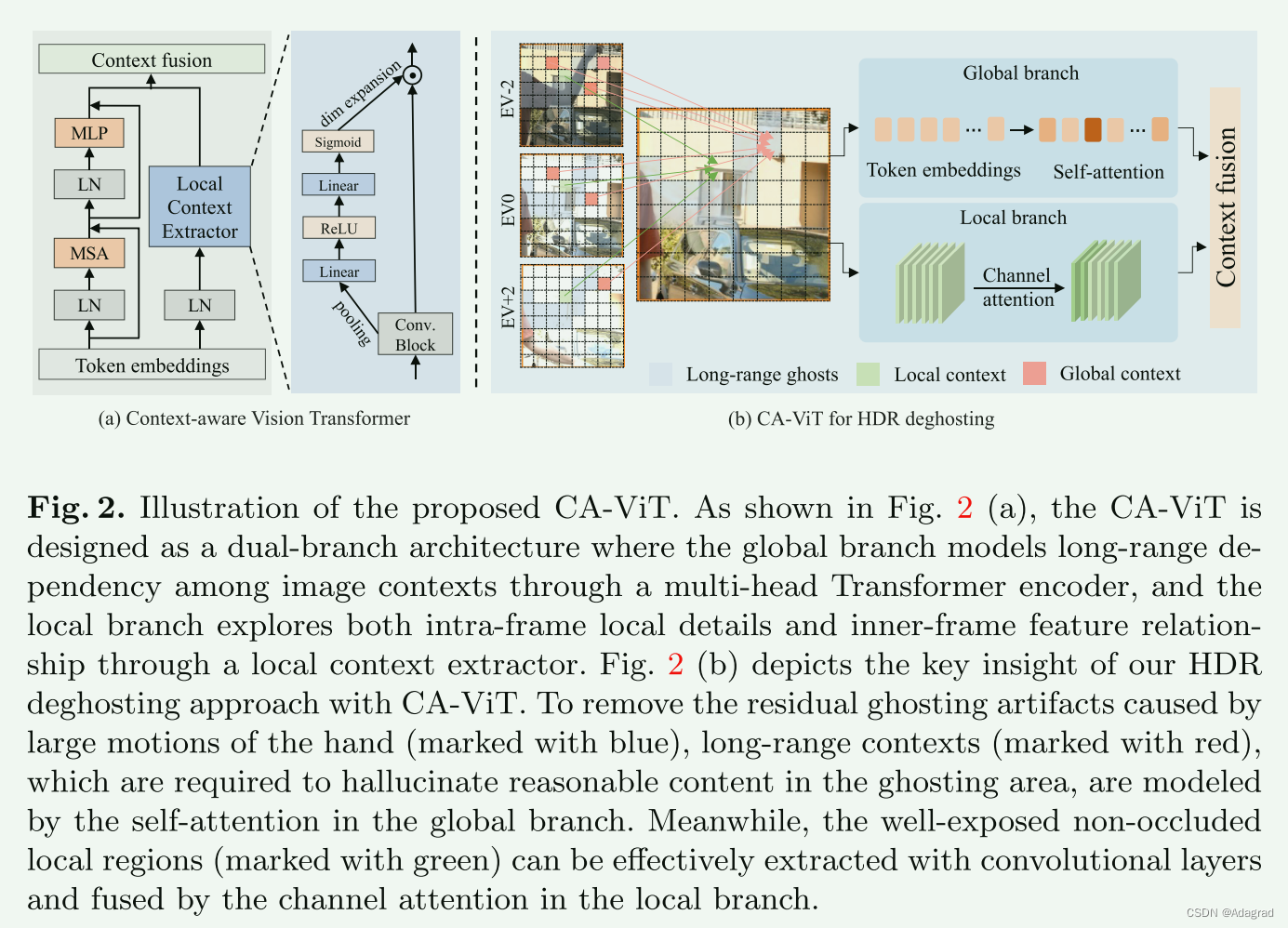
Global Transformer Encoder
对于全局分支,我们采用基于窗口的多头变压器编码器[6]来捕获远程信息。 变压器编码器由多头自关注(MSA)模块和带残差连接的多层感知器(MLP)组成。

Local Feature Extractor

最后,采用上下文融合层将全局上下文和局部上下文结合起来。 虽然可以使用其他变换函数(如线性层或卷积层)来实现上下文融合层,但在本文中,我们简单地通过元素添加来合并上下文,以减少附加参数的影响。

3.2 HDR Deghosting
深度HDR去鬼影的任务是通过深度神经网络重建无鬼影的HDR图像。在之前的大部分作品中[13,37,39],我们以3张LDR图像(即Ii, i = 1,2,3)作为输入,并以中间的帧I2作为参考图像。为了更好地利用输入数据,首先将LDR图像{Ii}通过gamma校正映射到HDR域,生成gamma校正后的图像{ˇ}:

与现有的基于CNN的方法相比,我们提出了HDR转换器来处理HDR去重影,而不是堆叠非常深的CNN层来获得一个大的感受野。 我们的主要见解是,通过专门设计的DualBranch CA-VIT,远程重影可以在全局分支中很好地建模,本地分支有助于恢复细粒度细节。 我们将在下一节描述所提出的HDR变压器的体系结构。
3.3 Overall Architecture of HDR-Transformer
如图所示 3、我们提出的HDR转换器的总体结构主要由两部分组成,即特征提取网络(图3(A))和HDR重构网络(图(B))。 给定三幅输入图像,首先通过空间注意力模块提取空间特征。 然后将提取的粗特征嵌入到基于变压器的HDR重建网络中,生成重建后的无鬼影HDR图像。
Feature Extraction Network

HDR Reconstruction Network


3.4 Loss Function

4 Experiments
4.1 Dataset and Implementation Details
Datasets
遵循前面的方法[37,39,40,25],我们在广泛使用的Kalantari等人的数据集[13]上训练我们的网络,该数据集由74个样本用于训练,15个样本用于测试。 Kalantari等人的数据集中的每个样本包括三个曝光值为-2、0、+2或-3、0、+3的LDR图像,以及一个真实HDR图像。 在训练过程中,我们首先从训练集中裁剪出大小为128×128的斑块,步幅为64。 然后我们应用旋转和翻转增强来增加训练大小。 我们在Kalantari等人的测试集上定量和定性地评价了我们的方法。 我们还对SEN等人进行评估。 [33]'s和Tursun等人[35]的数据集验证了我们方法的泛化能力。
Evaluation Metrics
我们使用PSNR和SSIM作为评价指标。 为了更精确地计算重建HDR图像与其对应的地面真值之间的PSNR-L、PSNR-μ、SSIM-L和SSIM-μS分数。 “-L”和“-μ"分别表示线性域值和调音域值。 假定HDR图像通常显示在LDR显示器上,则Tonemapped域中的度量更准确地反映重建HDR图像的质量。 此外,我们使用HDR-VDP-2[22]进行评估,这是专门为评估HDR图像的质量而开发的。
Implementation Details
我们的HDR-Transformer是由PyTorch实现的。 我们使用ADAM优化器,初始学习速率为2e-4,分别设置β1为0.9,β2为0.999和1e-8。 我们从零开始训练网络,批量大小为16,100个纪元使它能够收敛。 整个培训在四个NVIDIA 2080TI GPU上进行,花费大约两天时间。
4.2 Comparison with State-of-the-art Methods
Results on Kalantari et al.’s Dataset
我们首先将所提出的HDR-Transformer的结果与几种最先进的方法进行了比较,其中包括两种基于补丁匹配的方法(Sen et al.[33]和Hu et al.[10])和五种基于CNN的方法(Kalantari et al.[13],DeepHDR[37],AhdrNet[39],NhdrRNet[40]和HDR-Gan[25])。 我们还与一个小版本的Swinir[16]进行了比较,因为原始的Swinir[16]不能收敛于有限的数据集。 在基于深度学习的方法中,Kalantari等[13]采用光流对齐输入LDR图像,而DeepHDR[37]使用单应性对齐背景。 相比之下,左边的方法和我们的HDR变压器不需要任何预对准。 我们报告了定量和定性的比较结果,因为这个测试集包含地面真理HDR图像。
Quantitative results
表1列出了定量结果。 为了公平起见,本文借鉴了HDR-GAN[25]的前人工作结果,并对Kalantari等人的数据集的15个测试样本进行了平均。 从表1中可以得出几个结论。 首先,所有基于深度学习的算法都表现出明显的性能优势。 其次,由于上述原因,Swinir采用的纯变压器编码器性能不佳。 第三,所提出的HDR变压器在PSNR-L和PSNR-μ方面分别比最近发表的HDR-GAN[25]高0.6dB和0.4dB,证明了我们方法的有效性。
Qualitative results
为了公平的比较,所有定性结果都是使用作者提供的代码获得的,并使用相同的设置在Photomatix Pro中进行了调色。 图 4展示了一个包含饱和和大运动的棘手场景。 第一行显示输入的LDR图像,我们的Tonemaped HDR结果,以及相应的缩放LDR补丁从左到右。 第二行列出了比较的HDR结果,其中两个比较位置分别以红色和蓝色突出显示。 可以看到,红色盒状区域在三个输入LDR图像中遭受严重的强度变化,并导致长程饱和。 以往的方法消除了头部轻微运动引起的重影伪影,但不能产生对面部饱和度区域细节的幻觉,导致颜色失真和细节不一致。 蓝框贴片显示了由手引起的大的运动区域,基于贴片匹配的方法无法发现正确的区域,而基于CNN的方法无法处理远距离运动,导致重建HDR图像中的重影伪影。 相反,提出的HDR-Transformer重建无鬼的结果,同时在这些区域产生更多视觉愉悦的细节幻觉。
Results on the Datasets w/o Ground Truth
为了验证该方法的泛化能力,我们对Sen等人进行了评估。 [33]'s和Tursun等人[35]的数据集。 如图所示 5、由于两个数据集都没有真实感HDR图像,我们报告了定性结果。 就像在图看到的那样 5(a),当遭受长程饱和时,基于CNN的算法AHDRNet[39]和HDR-GAN[25]在饱和边界上产生不希望的畸变。 基于Transformer的方法Swinir[16]性能更好,但由于局部上下文建模效率低,仍然存在明显的失真。 相反,提出的HDR-Transformer生成更精确的边界(最好与相应的LDR补丁进行比较),证明了我们方法的上下文感知建模能力。 图 5(b)展示了一个钢琴光谱饱和的场景。 以前的方法丢失了高频细节,产生了模糊的结果,而我们的方法比它们产生了更多的幻觉细节。
Analysis of Computational Budgets
我们还将推理次数和模型参数与前人的工作进行了比较。 如表2所示,基于补丁匹配的方法[33,10]需要超过60秒来融合1.5MP的LDR序列。 在基于CNN的方法中,Kalantari等人[13]由于光流预处理耗时较长,因此比剩下的非流方法花费更多的时间。 deepHDR[37]和nhdrrnet[40]消耗的推理时间较少,但需要大量的参数。 AHDRNet[39]和HDR-GAN[25]利用其精心设计的体系结构,在性能和效率上取得了更好的平衡。 相比之下,HDR-Transformer仅用一半的计算预算就胜过了目前最先进的方法HDR-GAN[25]。
4.3 Ablation Study
5 Conclusions
本文提出了一种双分支上下文感知视觉转换器(CA-VIT),克服了VITS中局部性的不足。 我们对标准VITS进行了扩展,引入了局部特征提取器,从而可以同时对全局和局部图像上下文进行建模。 此外,我们还介绍了HDR-Transformer,这是一个用于无GhostFree高动态范围成像的特定任务框架。 HDR-Transformer结合了Transformer和CNNs的优点,其中Transformer编码器和局部上下文提取器分别用于建模长程重影伪影和短程像素关系。 大量的实验表明,所提出的方法达到了最先进的性能。