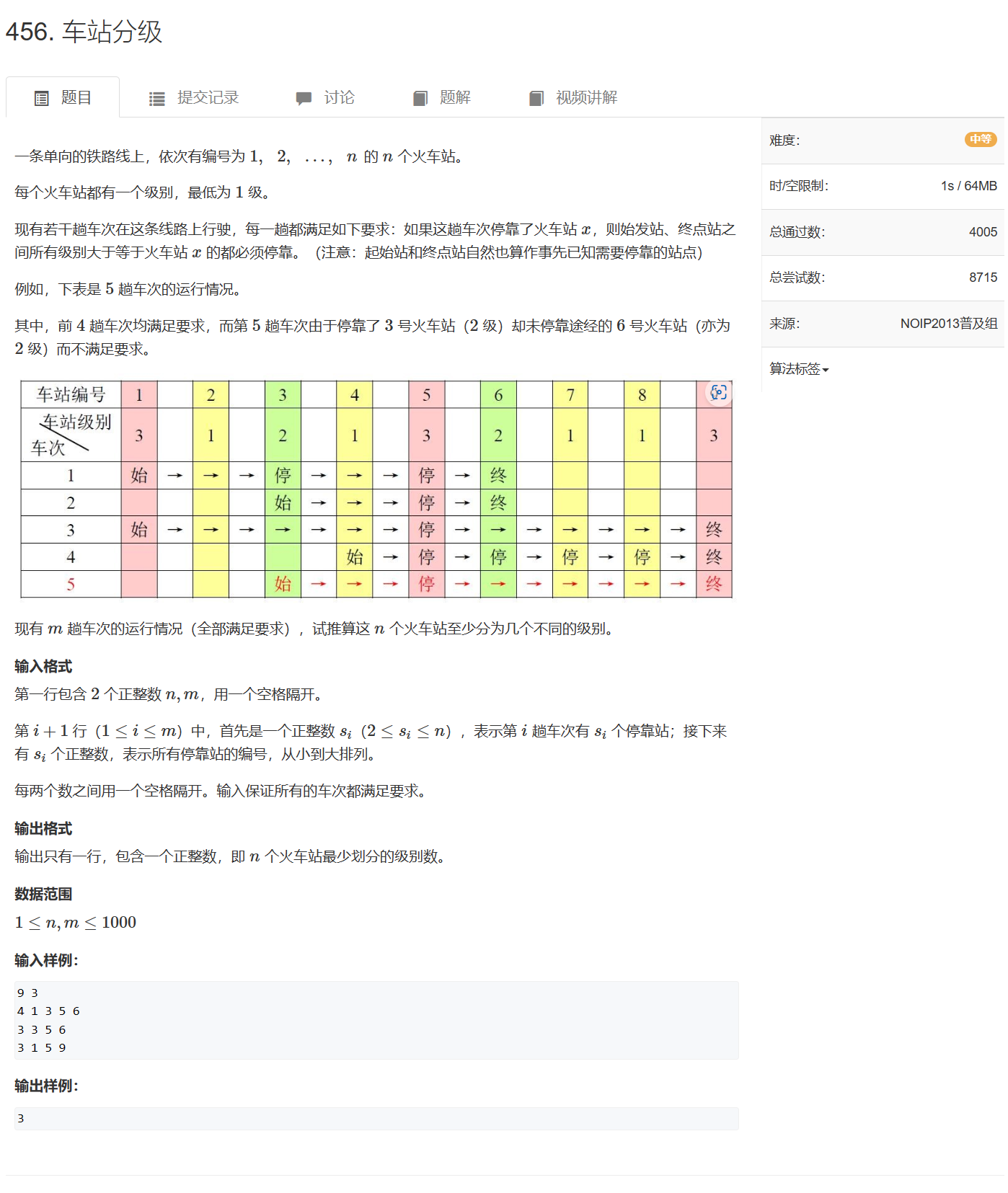
一、3DAL
1.论文概述
由于论文的出发点是做一个离线的自动标注算法。所以没有太多的实时性和算力限制,模型可以做的大一点,融合的信息多一点(时序信息,离线没有因果关系,所以前后帧数据都可以用)。个人感觉整体思路和二阶段目标检测算法差不多,都是Coarse-to-Fine(由粗到细)的思想。
2.算法框架

第一步:输入点云序列,经过一个离线的目标检测算法(MVF++)得到每一帧的检测结果,同时通过目标跟踪(卡尔曼滤波)得到每个目标的整个轨迹序列。这一步得到的检测框较为粗糙。
第二步:已知目标检测框的轨迹序列和原始点云序列,将他们全部转换到世界坐标系下,同时我们把每个物体的点序列(检测框内的点)和框序列提取出来。这里点序列提取时,会把点提取范围扩大一点(也就是把框放大一点,提取更多有用特征)。这样我们得到一个物体的序列点和序列框,用于后续的box细化。
第三步:一个物体多帧点云和框都转到世界坐标系下之后,静态的物体点云会更加稠密完整,而动态的物体则会由于运行,点云会形成拖影。同时静止的物体我们希望在序列中只生成一个框,这样可以防止其抖动。所以论文中采用动静分离的方式来做refine。如果一个物体的连续轨迹大于7帧,我们才进行下面的操作,如果小于7帧,直接把检测结果当作最终标注结果。我们根据两个启发式特征(box中心的方差和box序列中开始结束位置偏差)送入一个线性分类器,来判断是静止物体还是运动物体。
第四步:动静态分别细化,根据物体序列点和box特征,对box的大小位置进行细化。下面细说。
3.一二阶段网络模型
MVF++模型改进

a.添加了一个语义分割的分支,用于判断每个点是否在框内。增强了点特征的区分能力。
b.使用anchor-free的方式
c.加大原始MVF++模型的大小,把普通的卷积块换为ResNet残差块。
整个模型提取完点特征之后,加上类似于pointpillar的结构来检测物体。
埋个坑,这里的反体素化操作是怎么进行的?
静态物体自动标注
模型从不同帧中合并对象的点云,这时合并完是在世界坐标系下,选取一个score最大的框参数作为初始化box参数,然后把点云都转到box坐标系下(box中心为远点,车头为x正方向),这样有助于refine参数的学习。然后通过pointnet进行点的语义分割,判断哪些是前景点,对背景点进行过滤,然后再预测一个box refine参数,这个细化后的box,可以根据车辆的ego参数,转换到其他不同帧中去。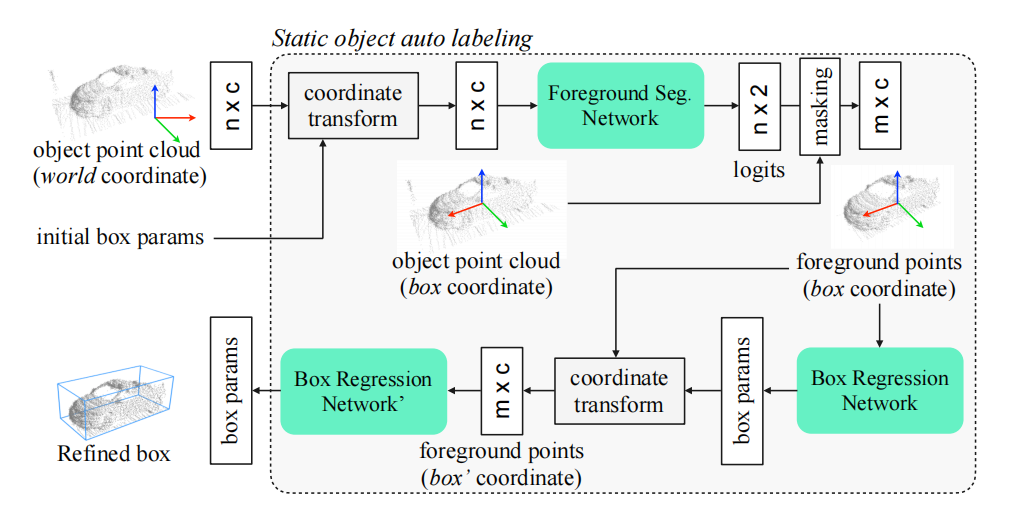
动态物体自动标注
对于一些列的box和box内的点,模型以滑动窗口的形式运行,并为当前框输出一个refine参数。
对于点云分支,提取当前帧物体的点以及前后各N(超参,论文为2)帧的点,每帧采样1024个点,并对他们添加一个时间维度的编码,所以传进去的是n * (c + 1),这些都需要转换到当前box的坐标系下,送入pointnet进行前景点分类,然后再编码得到一个C维的点编码特征。
对于box分支,提取前后多帧的box信息,这个帧数要比点云的多,是为了形成更长的轨迹序列。然后把他们转到当前box坐标系下,用pointnet编码得到C维的box编码特征。
把点编码特征和box编码特征concate,然后进行当前box的一个refine。
——代码分析](https://img-blog.csdnimg.cn/a2654000554446809b853fc9669d2a98.png#pic_center)