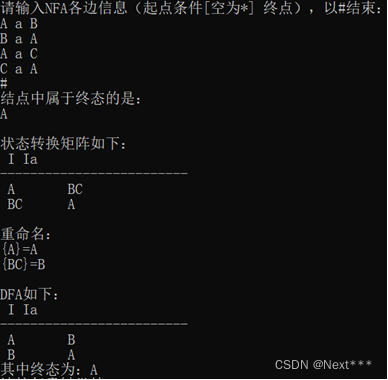
在上一个知识点中,我们剖析了关系型数据库、数仓湖与图数据库的差异。在本文,我们会着重介绍一个重要的概念——图思维方式(Graph-thinking)。
关于思维方式
每个人应该如何思考,他/她是如何思考的,这是一个没有标准答案(或者说很难形成共识)的问题。
有的人会说大多数人是线性思考的;也有人说我们是非线性思考的;
有人说聚焦型思考;有人说发散型思考;亦或两者、多者兼而有之。
如果我们把这个问题提炼成一个数学问题,并用数学的语言来描述它的话,
人类在本质上是用图的方式来思考的。
我们身处的这个世界是高维的、关联的、不断延展的,我们从来到这个世界到离开它的一刻,一直在与这个世界互动——我们每时每刻接触的所有的实体(一个个人、一件件事、一条条新闻或旧闻、一个个知识点、一本本书,甚至一缕缕情绪),这些实体被存储在我们的大脑(记忆)中。
人脑很像是一台设计精密的计算机,当我们需要从它里面抽取任何一条信息、一个知识点的时候就可以快速地定位并获取它。
而当我们发散思维的时候,是从一个知识点或多个知识点出发,沿着知识点之间关联的路径、网络遍历、过滤、搜索,去抽丝剥茧得到了一条条路径或一张张小网,上面是相互交织的信息的网络。
很多读者对于知识图谱(Knowledge Graph)的概念应该并不陌生,这一概念最早形成与互联网搜索引擎相关,换言之,互联网(WWW)本身就是一张巨大的网络。
知识图谱所做的工作就是去编织(采集数据、清洗数据、结构化数据...)这张网络,并允许用户在这张巨网中找到他需要的关联关系并呈现出来。
Web2.0的时代的互联网搜索引擎在用户交互维度实际上是低维的,如果你想要搜到超过2个(含)以上事物或知识点间的关联关系,那是几乎不可能的,例如在某Web搜索引擎上面去查”成吉思汗 牛顿“, 显然,你的预期是查找两个实体间的关联关系,类似于一种因果查询,或者是一种高维查询,但是,Web搜索引擎只会僵死的进行所谓的倒排索引,如果一篇文章中恰好有两个名字,链接会被无脑的排序后返回——Web搜索引擎对于单一知识本身仅仅是权重排序,但是对于多知识点间的关联关系无能为力。


如果我们希望像一个(一群)博学家一样可以给出如上图般的成吉思汗与牛顿间的横跨东西方400年的关联关系脉络,我们才真正的把人类知识的宝库关联化、脉络化、高维化、因果化。我们才可以在此基础上不断的发散、关联、深度探索。
上帝赋予了人类思维无远弗届的能力。
什么是“无远弗届”?就是思绪触达的地方再远都可以,这其实是一种超深度的图关联、图遍历、图搜索的能力。
当我们需要对于任何一个知识点进行详细描述的时候,我们可以赋予它很多属性和标签(注:标签即可以以属性的形式附着于当前知识点存在,也可以以额外的节点的方式与当前知识点及其它知识点关联而存在),知识点之间关联的关系同样也可以带有属性,通过这些属性我们对每一个知识点、每一条关系都有更深入地理解。例如,从小到大我们填写了很多家庭关系表,爸爸、妈妈、兄弟姐妹、祖籍、年龄、性别、单位、联系方式、教育程度等。在我们填这些表的时候,我们实际上调用的是一张“家庭关系子图”,主要节点有爸爸张三、妈妈李四、哥哥张小五、姐姐张小六等,每个节点都会有一些属性,年龄、电话号码,当然还有一个不言而喻的节点是我自己——张小七(小七也有自己的属性,例如籍贯、性别等),它会指向所有的近亲们,关系名称为爸爸、妈妈…… 显然这张图可以以一种迭代的方式延展,如果聚焦在爸爸节点上,他的近亲关联图谱又包含他的父母、兄妹等,以此类推。
这些实体与关系所组成的网络,我们称之为图(Graph)。当这种网络图中的点、边带有一些属性,可以帮助我们方便地利用属性来进行信息的筛选过滤、聚合或传导计算的时候,这种图称之为属性图(Property Graph)。
带有属性的图可以用来表达世间一切事物,无论它们是关联的还是离散的。当事物是关联的时候,它们形成了一张网络;而当它们离散开来的时候,就是这些事物(节点)罗列的一张表,像是关系型数据库的表中的一行行的数据(这里要表达的要点是:图是高维的,高维可以向下兼容并表述低维空间的内容,反之则不成立。或者说用低维的关系型数据库来表达高维的图极其困难,通常是事倍而功半甚至无功而返。在知识点1中我们已经简要介绍过关系型数据库在处理一些复杂的场景中会存在严重的效率问题,在后面的知识点中我们会专门展开讨论这类问题)。
图的这种表达方式和人类大脑神经元网络存储与认知事物有极大的相通性。我们总是不断地在关联、发散、再关联、再发散。当我们需要定位并搜索某个人或事物的时候,找到它并不代表着搜索的结束,而常常是一连串搜索的开始。例如我们进行举一反三式的发散思维的时候,我们相当于在图或网络上面进行某种实时过滤或动态遍历搜索。当我们说一个人上知天文下知地理的时候,当我们在“旁征博引”的时候,我们似乎让思绪从一张图上跳到了另一张图上。而我们的大脑存储了很多张图,这些图或联动或互动,根据我们的需要随时来提供服务。
如果在图数据库上可以实现人脑同样的运作方式,那么有什么理由不能相信图数据库就是终极的数据库呢?当然,前提是我们得在这一点上达成共识:人脑就是终极的数据库。我们甚至可以说,在强人工智能实现之前,让图数据库先成为终极的数据库或许是一条必经之路。
图数据库(与图计算)是一种典型的增强智能(Augmented Intelligence),它区别于人工智能(Artificial Intelligence)的最本质的地方,也是图的三大优点:白盒化(可解释)、高算力(高效、深度、准确)、灵活(数据建模与业务满足能力)。注:因篇幅所限,我们在此并不展开论述,关于人工智能、机器学习(深度学习)所存在的黑盒化、低效等问题,后续的知识点介绍中我们会逐步展开。
我们学到的每一个知识点、掌握的每一个技能、接触的每个人与事物都不是孤立的,这些与日俱增的知识点或实体构建起来了庞大的知识网络,让我们随时可以从中抽取、归纳、整理、编织、推导、关联。
人类历史上所有的智者、文豪、天才、贩夫走卒、路人甲乙,他(她)们的每一次惊世骇俗的灵光乍现或平常之极的循规蹈矩都是在用图的思维在实践。惊世骇俗或灵光乍现只是因为在图思维的道路上延展得更深、更广、更快;循规蹈矩只是在图上面走的太浅、太容易被别人看懂,太容易形成共识和被预测,这就会被定义为“循规蹈矩”甚至缺少创新 。同样的,我们常说的被降维打击,在本质上就是因为循规蹈矩或只能进行浅层的计算与思考而被深层算力所碾压,仅此而已。
所谓浅层计算,在数据库技术层面,指的是只能进行面向元数据的操作(例如聚合、筛选),而关系型数据库的舒适区恰恰就是在这个非常浅的层面。而深度的计算指的是需要对(分门别类的)元数据进行关联查询,例如典型的多表关联操作,这类操作远离了关系型数据库的舒适区——因为让关系型数据库进行这种复杂、关联查询,其效率会随着查询深度的增加而指数级降低。不必怀疑关系型数据库及其查询语言SQL是否会消亡,消亡只是个时间问题。等全社会都形成共识的时候才认识到,无疑已经太晚了——这也是因为只能进行浅层思维的必然结果。
在工业界,特别是银行业中经常说到一句话:比同业早发现、比同业早行动。通常来指在发现风险、预防风险以及发现商机、捕捉商机的时候应该具备的内化的能力。在本质上指的就是可以比别家算得更快、更深、更准。图思维方式毫无疑问是赋能这种能力的内在动因,而图数据库(图计算)则是这种内因外化时的一种具体的技术、产品形态。
我们再来看一个《三字经》中的例子:“有古文大小篆,隶草继不可乱”,这句话的意思其实描述的是书法演变的一个链条,即:从大篆到小篆,再到隶书、草书,中国书法史的沿革与脉络清晰可见,见下图所示:

如果我们从三字经中的这两句话发散开来,每一种书法的时代特征(肇始、鼎盛、衰落、中兴、延续)以及它们各自的来龙去脉,各自的代表人物、作品,这是一张可以无限延展的网络,但是当我们聚焦并把延展的幅度(比如≤2步)限定得很小的时候,我们可以得到如下的一张小图谱——相信任何对知识有诉求的读者都会从里面发现一些新的思路——所谓新思路,无非就是找到了新的知识路径打开的方式:

在本质上,每一张网络都是一张图。每一个博古通今的人的脑子里面都装满了图,善于利用图去思考、去发散、去归纳总结、去融会贯通。如果一张图不能解决问题,那就再加一张!

用关系表描述世界,需要很高的技巧和训练,而且很僵化,缺乏效率。用图的方式描述世界,简单,自然,自由,极具效率。
最后,我们来总结一下本知识点,用上图中的两句话来概括:
- 用关系表描述世界,需要很高的技巧和训练,而且很僵化,缺乏效率。
- 用图的方式描述世界,简单,自然,自由,极具效率。
关于效率的探讨,我们留到后面的知识点中逐个破解。
对这一讲的内容希望系统化学习的读者,欢迎阅读阅读机械工业出版社2022年8月出版的《图数据库原理、架构与应用》一书,该书是华语世界第一部《图数据库》领域原创专著,相信书中很多实战中总结出来的内容对于读者深入了解图数据库概念、原理、架构设计与应用开发会有相当大的助益。

See you until our next knowledge point, with love from Ultipa.