文章目录
- 如何利用pytorch创建一个简单的网络模型?
- Step1. 感知机,多层感知机(MLP)的基本结构
- Step2. 超平面 ω T ⋅ x + b = 0 \omega^{T}·x+b=0 ωT⋅x+b=0 or ω T ⋅ x = b \omega^{T}·x=b ωT⋅x=b
- 感知机函数
- Step3. 利用感知机进行决策分类的训练过程 -【Matlab代码】
- 从线性回归到贯序模型
- nn.Linear(_, _)
- 模型训练
- 贯序模型例程 -【Pytorch完整代码】
如何利用pytorch创建一个简单的网络模型?
Step1. 感知机,多层感知机(MLP)的基本结构
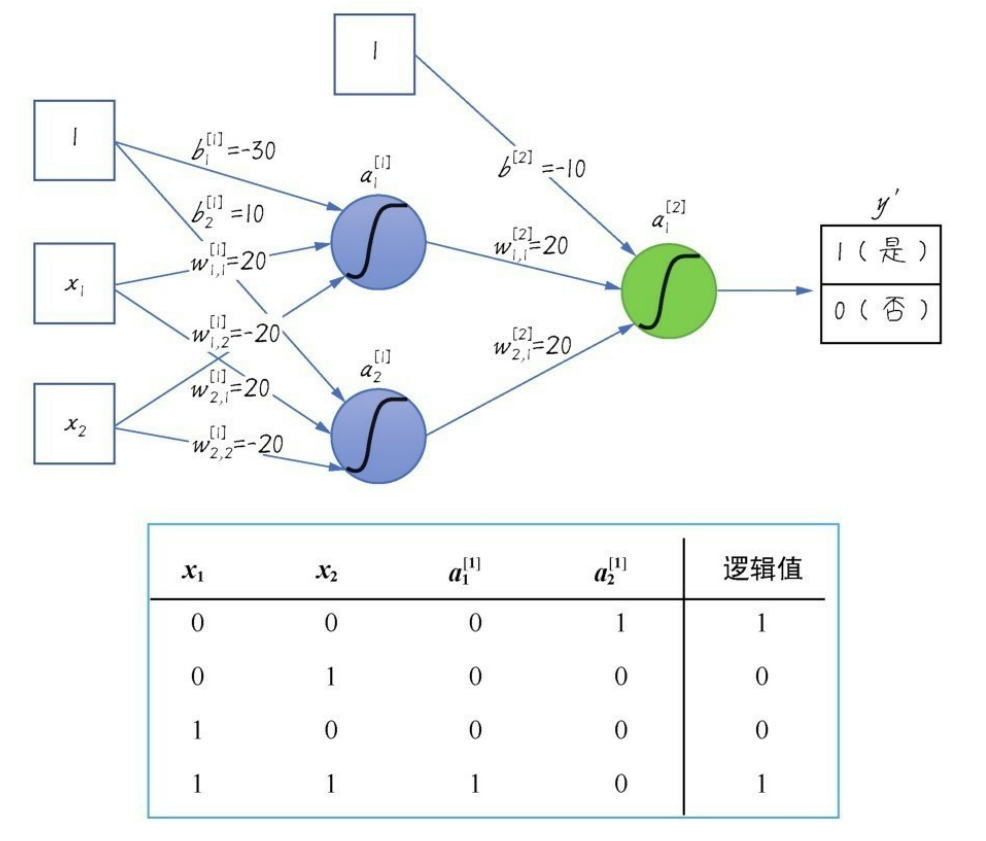
感知机(Perceptron)是神经网络中的基本单元,神经网络的雏形,也被称作神经元(原理就是仿照生物上的神经元)、单层神经网络。
通过设置不同的权重,并加上一个激活函数(判决门限),就构成了一个单层感知机的基本网络结构,可以实现与或非三种基本逻辑:
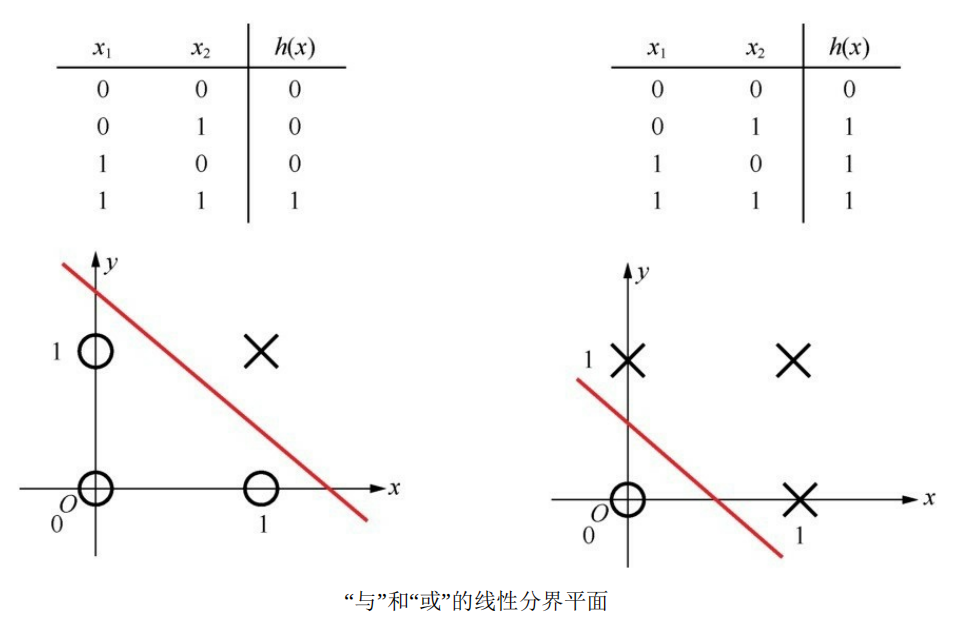

但是单层感知机的功能还是具有局限性,因为它毕竟只是一种二元线性分类模型(其输入为实例的特征向量,输出为实例的类别,取1和0【sigmoid激活判决】或+1和-1【sign激活判决】 ),像同或、异或这种稍微复杂一点的逻辑,就无法用单层感知机拟合出结果:
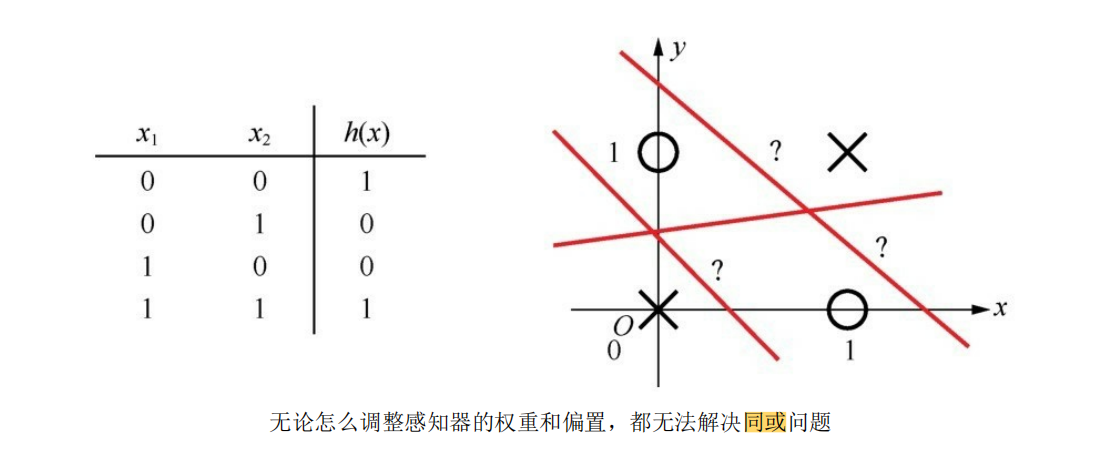
所以通过扩展感知机的层数,引入更多层的神经元(多层感知机MLP的由来),从而带来更多可以训练的参数,得到一种非线性模型,以达到拟合出预期的效果:
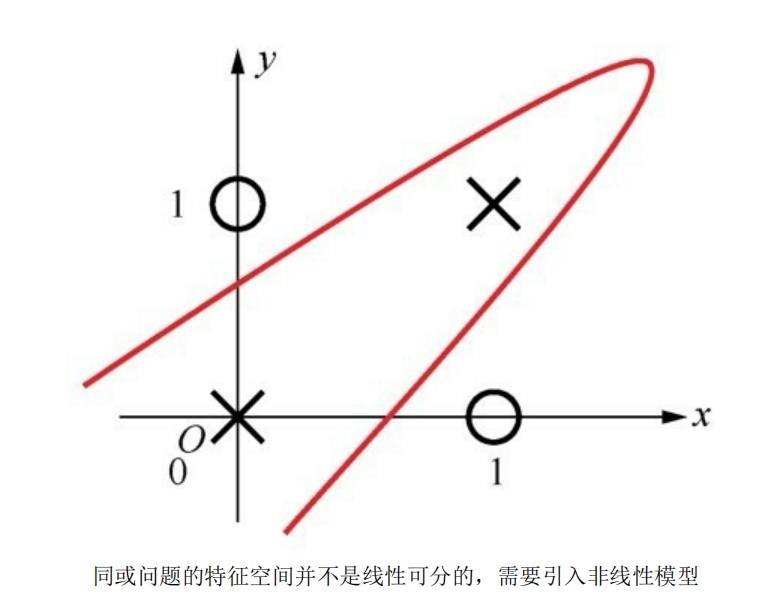
加入一层隐层网络之后,同或数据集就变得可以拟合了:
a 1 [ 1 ] = s i g m o i d ( ω 1 , 1 [ 1 ] ⋅ x 1 + ω 2 , 1 [ 1 ] ⋅ x 2 + b 1 [ 1 ] ) a_1^{[1]}=sigmoid(\omega_{1,1}^{[1]}·x_1+\omega_{2,1}^{[1]}·x_2+b_1^{[1]}) a1[1]=sigmoid(ω1,1[1]⋅x1+ω2,1[1]⋅x2+b1[1])
a 2 [ 1 ] = s i g m o i d ( ω 2 , 1 [ 1 ] ⋅ x 1 + ω 2 , 2 [ 1 ] ⋅ x 2 + b 2 [ 1 ] ) a_2^{[1]}=sigmoid(\omega_{2,1}^{[1]}·x_1+\omega_{2,2}^{[1]}·x_2+b_2^{[1]}) a2[1]=sigmoid(ω2,1[1]⋅x1+ω2,2[1]⋅x2+b2[1])
a 1 [ 2 ] = s i g m o i d ( ω 1 , 1 [ 2 ] ⋅ a 1 [ 1 ] + ω 2 , 1 [ 2 ] ⋅ a 2 [ 1 ] + b [ 2 ] ) a_1^{[2]}=sigmoid(\omega_{1,1}^{[2]}·a_1^{[1]}+\omega_{2,1}^{[2]}·a_2^{[1]}+b^{[2]}) a1[2]=sigmoid(ω1,1[2]⋅a1[1]+ω2,1[2]⋅a2[1]+b[2])【逻辑值】
上标
[
i
]
^{[i]}
[i]代表第几层;
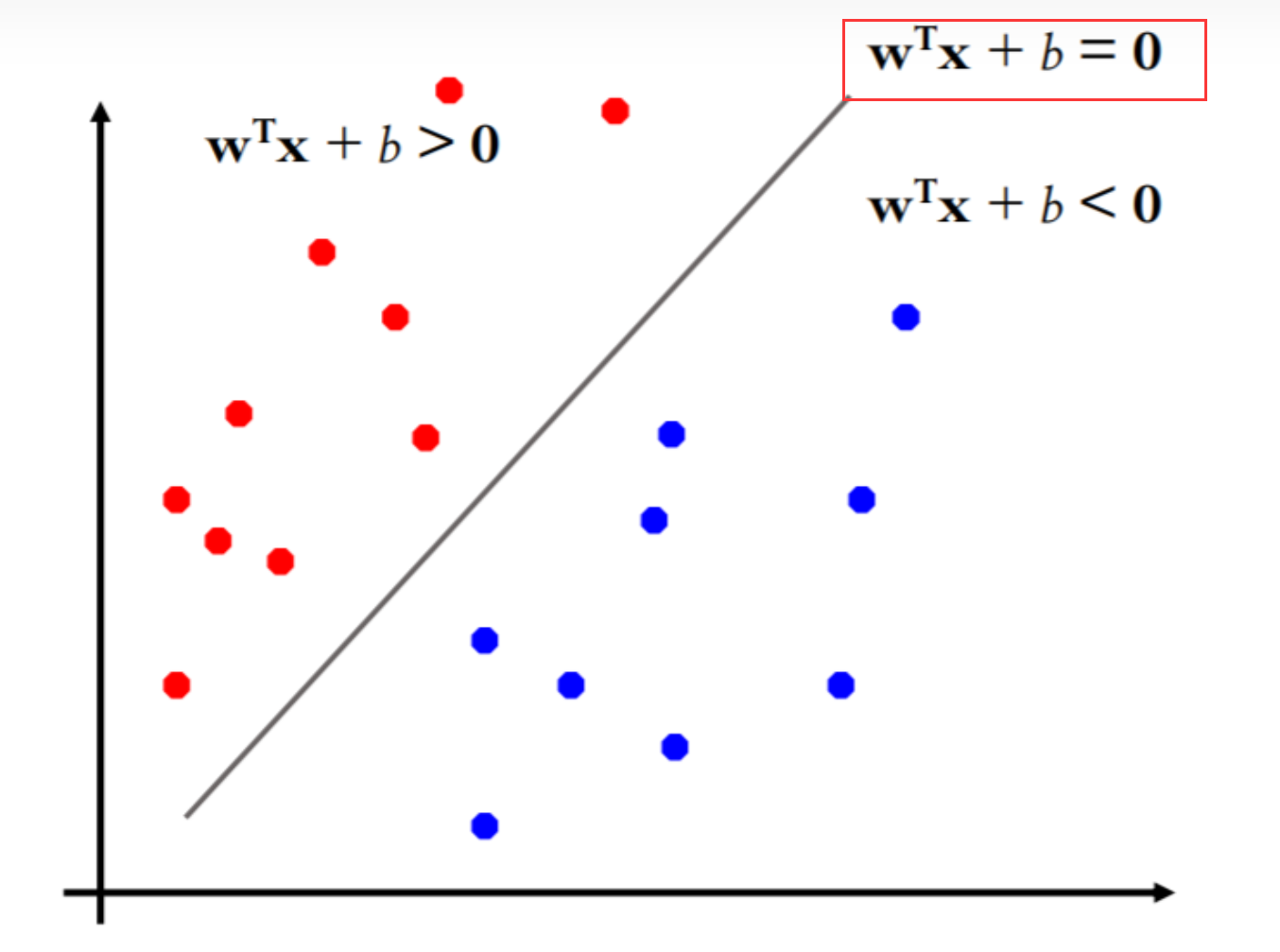
Step2. 超平面 ω T ⋅ x + b = 0 \omega^{T}·x+b=0 ωT⋅x+b=0 or ω T ⋅ x = b \omega^{T}·x=b ωT⋅x=b
初学者第一次见到
ω
T
⋅
x
+
b
=
0
\omega^{T}·x+b=0
ωT⋅x+b=0这个表达式时,会觉得它非常像线性函数,
ω
T
⋅
x
+
b
=
0
\omega^{T}·x+b=0
ωT⋅x+b=0为什么是一条斜线呢?实际上这只是为了在二维平面更好表示其线性分类效果;
在三维空间中,分类效果是这样:
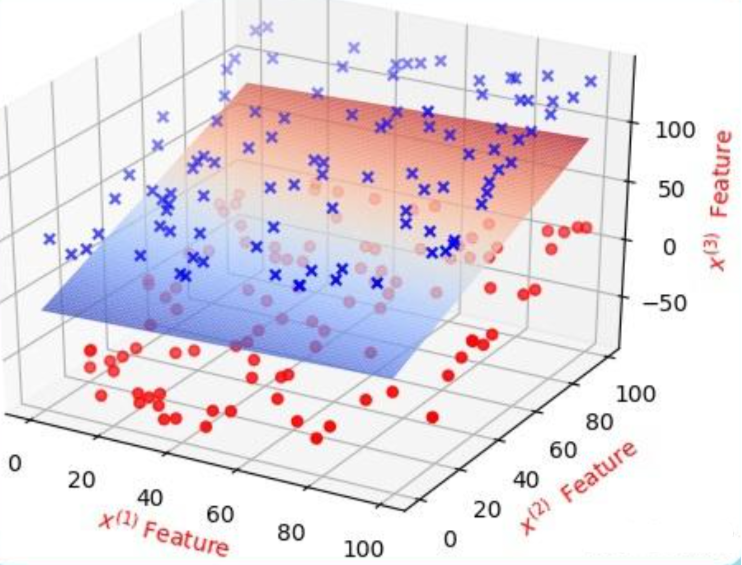
投影在 XOZ/YOZ 轴平面就是二维平面中所看到的效果。
在高等数学中我们学习过三维平面的一般表达式: A x + B y + C z + D = 0 Ax+By+Cz+D=0 Ax+By+Cz+D=0,
( A , B , C ) (A, B, C) (A,B,C)为平面的法向量,亦可写为点法式: A ( x − x 0 ) + B ( y − y 0 ) + C ( z − z 0 ) = 0 A(x-x_0)+B(y-y_0)+C(z-z_0)=0 A(x−x0)+B(y−y0)+C(z−z0)=0,
( x 0 , y 0 , z 0 ) (x_0, y_0, z_0) (x0,y0,z0)是平面上的一个点,将点法式拆开: A x + B y + C z = A x 0 + B y 0 + C z 0 Ax+By+Cz=Ax_0+By_0+Cz_0 Ax+By+Cz=Ax0+By0+Cz0,
这里的 A x 0 + B y 0 + C z 0 Ax_0+By_0+Cz_0 Ax0+By0+Cz0就是一般式中的 D D D.
当扩展至N维超平面时,式子就变成了: A ( x 1 − x 0 ) + B ( x 2 − x 0 ) + C ( x 3 − x 0 ) + . . . + N ( x n − x 0 ) = 0 A(x_1-x_0)+B(x_2-x_0)+C(x_3-x_0)+...+N(x_n-x_0)=0 A(x1−x0)+B(x2−x0)+C(x3−x0)+...+N(xn−x0)=0,
即 A x 1 + B x 2 + C x 3 + . . . N x n = A x 0 + B x 0 + C x 0 + . . . N x 0 Ax_1+Bx_2+Cx_3+...Nx_n=Ax_0+Bx_0+Cx_0+...Nx_0 Ax1+Bx2+Cx3+...Nxn=Ax0+Bx0+Cx0+...Nx0,
改写成向量相乘的形式:
令行向量 ω T = [ ω 1 , ω 2 , . . . , ω n ] = [ A , B , . . . , N ] \omega^T = [\omega_1, \omega_2,...,\omega_n]=[A, B,..., N] ωT=[ω1,ω2,...,ωn]=[A,B,...,N],
列向量 x = [ x 1 , x 2 , . . . , x n ] ′ x = [x_1, x_2, ... ,x_n]' x=[x1,x2,...,xn]′, b = A x 0 + B x 0 + C x 0 + . . . N x 0 b = Ax_0+Bx_0+Cx_0+...Nx_0 b=Ax0+Bx0+Cx0+...Nx0
则N维超平面的定义式: ω T ⋅ x = b \omega^{T}·x=b ωT⋅x=b 就产生了, b b b为超平面的常数项截距, ω T \omega^{T} ωT是超平面的法向量。
感知机函数
Step1中我们见过了感知机加激活函数得到与门的效果:
感知机函数可以表示为:
S
i
g
m
o
i
d
(
ω
T
x
+
b
)
Sigmoid(\omega^{T}x+b)
Sigmoid(ωTx+b)
S i g m o i d ( ω T ⋅ x + b ) = { 1 , ω T x + b ≥ 0 0 , ω T x + b < 0 Sigmoid(\omega^{T}·x+b) = \begin{cases} 1, \qquad \omega^{T}x+b≥0\\ 0,\qquad \omega^{T}x+b<0\end{cases} Sigmoid(ωT⋅x+b)={1,ωTx+b≥00,ωTx+b<0
或
S i g n ( ω T ⋅ x + b ) = { + 1 , ω T x + b ≥ 0 − 1 , ω T x + b < 0 Sign(\omega^{T}·x+b) = \begin{cases} +1, \qquad \omega^{T}x+b≥0\\ -1,\qquad \omega^{T}x+b<0\end{cases} Sign(ωT⋅x+b)={+1,ωTx+b≥0−1,ωTx+b<0
我们现在采用 S i g n Sign Sign 符号函数作为激活函数,利用超平面 ω T x + b = 0 \omega^{T}x+b=0 ωTx+b=0 进行决策分类任务,并定义输出标签 y = + 1 y=+1 y=+1 时为“是”, y = − 1 y=-1 y=−1 时为“否”;
则分类出现错误时必定会有 y ⋅ ( ω T x + b ) < 0 y·(\omega^{T}x+b)<0 y⋅(ωTx+b)<0.
因此,我们定义损失函数: L ( ω , b ) = − ∑ i = 1 n y i ⋅ ( ω i T x + b ) \mathcal{L}(\omega,b)=-\sum_{i=1}^{n}y_i·(\omega^{T}_ix+b) L(ω,b)=−∑i=1nyi⋅(ωiTx+b);
实际上损失函数的定义也并非这么直截了当就得出,因为还要保证损失函数连续可导,才能对其求偏导进行 a r g m i n ( ω , b ) argmin(\omega, b) argmin(ω,b);极小化损失函数的过程不是一次使得所有误分类点的梯度下降,而是一次随机选取一个误分类点使其梯度下降,而损失函数中 y i ⋅ ( ω i T x + b ) y_i·(\omega^{T}_ix+b) yi⋅(ωiTx+b)的由来,其实就是选取了误分类点到超平面距离公式中的分子项,分母项是个L2范数只起到了缩放作用,不影响损失函数的优化,所以可以忽略不计。
具体推导过程可以参考:感知机w·x+b=0怎么理解?数学推导是什么样的?
我们的目标就是想让损失函数尽可能地小,并选取使得损失函数最小的 w w w和 b b b.
利用经典的随机梯度下降(SGD)算法对损失函数进行优化训练:
{ ∂ L ∂ ω = L ( ω , b ) = − ∑ i = 1 n y i ⋅ x ∂ L ∂ b = L ( ω , b ) = − ∑ i = 1 n y i \begin{cases}\frac{\partial{L}}{\partial{\omega}}=\mathcal{L}(\omega,b)=-\sum_{i=1}^{n}y_i·x\\\frac{\partial{L}}{\partial{b}}=\mathcal{L}(\omega,b)=-\sum_{i=1}^{n}y_i\end{cases} {∂ω∂L=L(ω,b)=−∑i=1nyi⋅x∂b∂L=L(ω,b)=−∑i=1nyi
{ ω = ω + α ∂ L ∂ ω b = b + α ∂ L ∂ b \begin{cases}\omega = \omega + \alpha\frac{\partial{L}}{\partial{\omega}}\\ b = b + \alpha\frac{\partial{L}}{\partial{b}}\end{cases} {ω=ω+α∂ω∂Lb=b+α∂b∂L
利用感知机进行线性分类的训练过程如上,这也是支持向量机(SVM)算法的雏形。
Step3. 利用感知机进行决策分类的训练过程 -【Matlab代码】
clc,clear,close all;
%% 定义变量
n = 50; % 正负样本的个数,总样本数为2n
r = 0.5; % 学习率
m = 2; % 样本的维数
i_max = 100; % 最大迭代次数
%% 生成样本(以二维为例)
pix = linspace(-pi,pi,n);
randx = 2*pix.*rand(1,n) - pi;
x1 = [cos(randx) + 2*rand(1,n); 3+sin(randx) + 2*rand(1,n)];
x2 = [3+cos(randx) + 2*rand(1,n); sin(randx) + 2*rand(1,n)];
x = [x1'; x2']; % 一共2n个点
y = [ones(n,1); -ones(n,1)]; %添加标签
figure(1)
hold on;
plot(x1(1,:),x1(2,:),'rx');
plot(x2(1,:),x2(2,:),'go');
%% 训练感知机
x = [ones(2*n,1) x]; % 增加一个常数偏置项 [1, x1;x2]
w = zeros(1,m+1); % 初始化权值 [w0, w1, w2]
flag = true; % 退出循环的标志,为true时退出循环
for i=1:i_max
for j=1:2*n
if sign(x(j,:)*w') ~= y(j) % 超平面加激活函数:sign(w'x+w0)
disp(num2str(sign(x(j,:)*w')))
disp(y(j))
flag = false;
w = w + r*y(j)*x(j,:); % 利用SGD算法更新参数
% begin
pause(0.3);
cla('reset');
axis([-1,6,-1,6]);
hold on
plot(x1(1,:),x1(2,:),'rx');
plot(x2(1,:),x2(2,:),'go');
x_test = linspace(0,5,20);
y_test = -w(2)/w(3).*x_test-w(1)/w(3);
plot(x_test,y_test,'m-.');
% end
M=getframe(gcf);
nn=frame2im(M);
[nn,cm]=rgb2ind(nn,256);
if i==1
imwrite(nn,cm,'out.gif','gif','LoopCount',inf,'DelayTime',0.1);
else
imwrite(nn,cm,'out.gif','gif','WriteMode','append','DelayTime',0.5)
end
end
end
if flag
disp(num2str(sign(x(j,:)*w')))
disp(y(j))
break;
end
end
disp(num2str(sign(x(j,:)*w')))
disp(y(j))
%% 画分割线
cla('reset');
hold on
axis([-1,6,-1,6]);
plot(x1(1,:),x1(2,:),'rx');
plot(x2(1,:),x2(2,:),'go');
x_test = linspace(0,5,20);
y_test = -w(2)/w(3).*x_test-w(1)/w(3);
plot(x_test,y_test,'linewidth',2);
legend('标签为正的样本','标签为负的样本','分类超平面');
M=getframe(gcf);
nn=frame2im(M);
[nn,cm]=rgb2ind(nn,256);
imwrite(nn,cm,'out.gif','gif','WriteMode','append','DelayTime',0.5)
程序中的超平面就是一条二维直线: ω 1 + ω 2 x 1 + ω 3 x 2 = 0 \omega_1+\omega_2x_1+\omega_3x_2=0 ω1+ω2x1+ω3x2=0,
训练出的超平面纵坐标 y t e s t = x 2 = − ω 1 / ω 3 − ω 2 x 1 / ω 3 y_{test}=x_2=-\omega_1/\omega_3-\omega_2x_1/\omega_3 ytest=x2=−ω1/ω3−ω2x1/ω3.

打印观察 S i g n ( ω T ⋅ x + b ) Sign(\omega^{T}·x+b) Sign(ωT⋅x+b)和标签 y y y的值:
disp(num2str(sign(x(j,:)*w')))
disp(y(j))
0
1
1
-1
-1
1
1
-1
-1
1
1
-1
-1
1
1
-1
-1
1
1
-1
-1
1
1
-1
-1
1
1
-1
-1
1
1
-1
-1
-1
可以看到当 S i g n ( ω T ⋅ x + b ) = = y Sign(\omega^{T}·x+b)==y Sign(ωT⋅x+b)==y的时候终止迭代循环,得到正确分类结果。
从线性回归到贯序模型
除了感知机,ML入门时我们还会使用线性回归和逻辑回归这类经典统计分析方法。线性回归就是想要通过数据,训练出一个符合数据变化规律的超平面(二维中的超平面就是一条直线,三维中的超平面是一个平面)进行未来数据的预测。
正是因为实际问题中的数据可能是复杂多变的,所以仅靠线性的超平面不一定能得到最好的拟合效果,所以可以通过添加其他的网络结构,添加非线性的隐藏层来实现具有更复杂拟合能力的网络结构。

而所谓的贯序模型就是将自定义的不同层网络(可以是线性层,激活函数层,卷积层、池化层、循环层、注意力层等等)串成一个模型。
# 添加激活层后的贯序模型
seq_model = nn.Sequential(OrderedDict([
('input_linear', nn.Linear(1, 12)),
('hidden_activation', nn.Tanh()),
('output_linear', nn.Linear(12, 1))
]))
该模型的网络结构包括:
输入层:第一层是一个线性层 (nn.Linear(1, 12)),它将接受一个维度为1的输入。
隐藏层:包含一个激活函数层 (nn.Tanh())。该隐藏层不改变维度,仅应用激活函数。
输出层:包含一个线性层 (nn.Linear(12, 1)),将隐藏层的输出维度(12)投影到一个维度为1的输出。
因此,该模型总共有三层:输入层、隐藏层和输出层。输入层的维度为1,输出层的维度为1。
nn.Linear(_, _)
nn.Linear 是 PyTorch 中的一个类,也可以理解为一个函数,用于定义一个线性变换(也称为全连接层或仿射变换),将输入特征映射到输出特征。它是神经网络模块 nn 提供的一个常用函数之一。
nn.Linear(in_features, out_features)中的第一个参数为in_features: 输入特征的数量(维度)。这个参数决定了输入的大小,通常也就是数据集中的特征数,即输入张量的最后一维大小;
nn.Linear(in_features, out_features)中的第二个参数为out_features: 输出特征的数量(维度)。这个参数决定了输出的大小,即输出张量的最后一维大小。
bias: 是否在变换中使用偏置项(偏置向量)。默认为 True,表示会使用偏置项;设置为 False 则不使用偏置项。
前向传播计算: 在神经网络的前向传播过程中,nn.Linear 定义的线性变换会对输入特征进行矩阵乘积运算,然后加上偏置项。具体计算公式如下:
output = input × weight ⊤ + bias \text{output} = \text{input} \times \text{weight}^{\top} + \text{bias} output=input×weight⊤+bias
其中,in_features是需要严格按照数据集中需要训练的特征数确定的,如波士顿房价数据集中:
0-505就是数据集的batch_size,batch_size表示一次选多少行数据进行训练,而crim, age, tax…这类的特征一共14个特征数量,就是nn.Linear中的in_features了,当然大小也是根据你需要哪几个特征参与训练确定的。
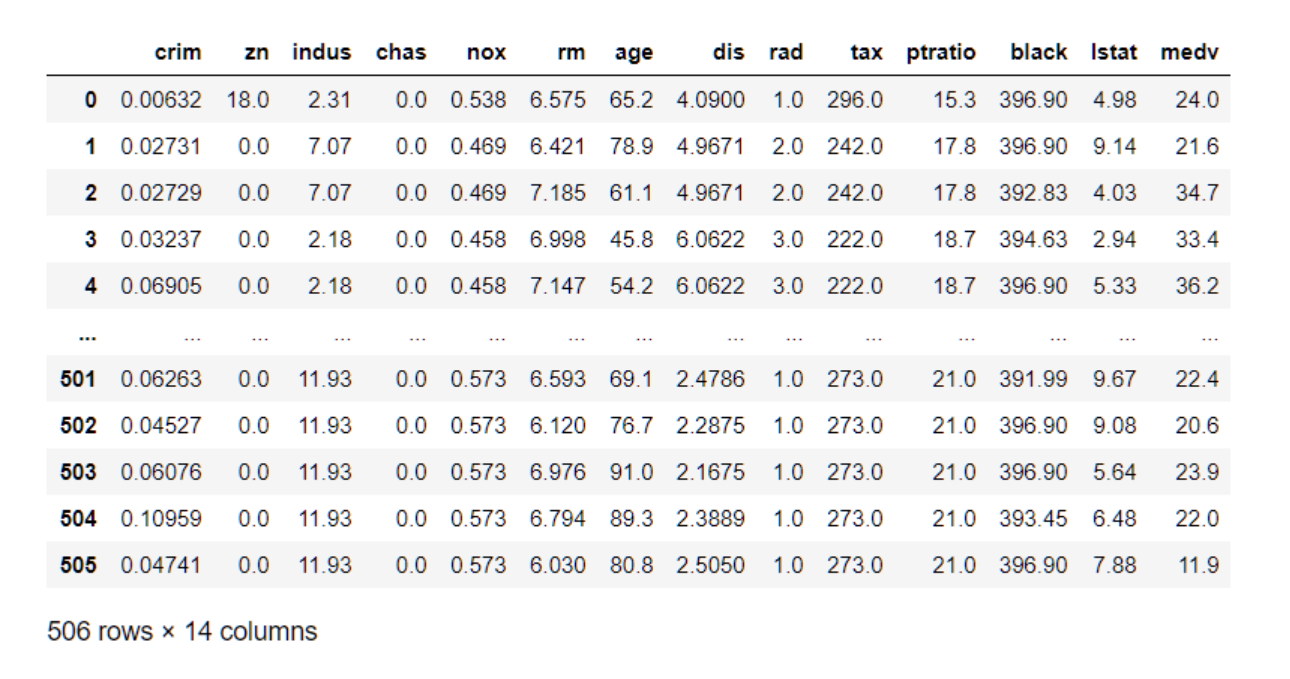
nn,Linear线性层计算的输入和输出格式:
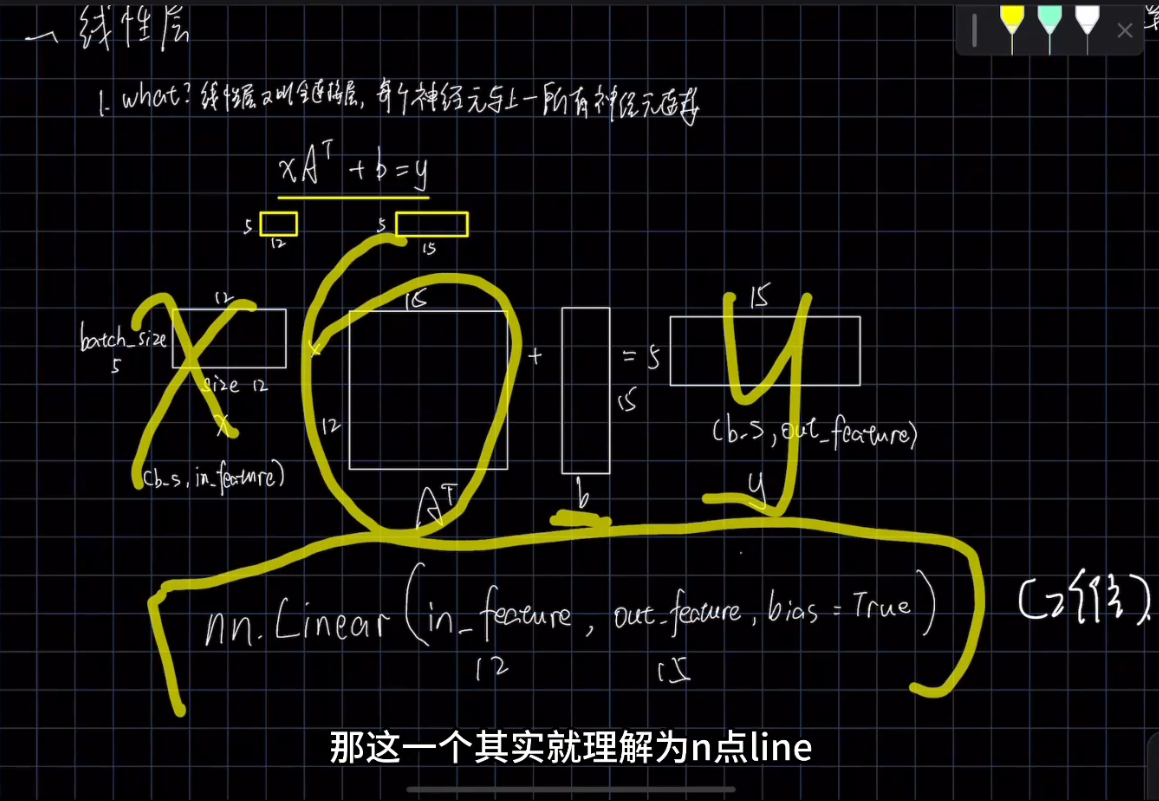
相比in_features, out_features 就灵活多变一些。如果 out_features 设置得太大,模型可能会过于复杂,导致过拟合问题。相反,如果设置得太小,模型可能无法捕捉足够的特征,导致欠拟合问题。选择适当的输出特征数量是在训练集和验证集上达到良好性能的关键之一。
nn.Linear 在神经网络中非常常见,它可以用于构建模型的一层或多层,实现从输入到输出的特征变换。通过多层的堆叠和非线性激活函数的引入,可以构建出更复杂的神经网络模型,适用于各种任务。
模型训练
在pytorch中我们通过定义一个training_loop来指定模型训练时的迭代次数,所选优化方法,调用创建的网络模型,以及选取的损失函数、训练集/验证集:
def training_loop(n_epochs, optimizer, model, loss_fn, t_u_train, t_u_val,
t_c_train, t_c_val):
for epoch in range(1, n_epochs + 1):
t_p_train = model(t_u_train)
loss_train = loss_fn(t_p_train, t_c_train)
t_p_val = model(t_u_val)
loss_val = loss_fn(t_p_val, t_c_val)
optimizer.zero_grad() # 清除旧梯度
loss_train.backward() # 后向传播计算新梯度
optimizer.step() # 根据梯度进行SGD优化
if epoch == 1 or epoch % 500 == 0:
print(f"Epoch {epoch}, Training loss {loss_train.item():.4f},"
f" Validation loss {loss_val.item():.4f}")
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c) ** 2
return squared_diffs.mean()
linear_model = nn.Linear(1, 1)
optimizer = optim.SGD(linear_model.parameters(), lr=1e-2)
# 尝试线性模型训练
training_loop(
n_epochs=3000,
optimizer=optimizer,
model=linear_model,
# loss_fn=loss_fn,
loss_fn=nn.MSELoss(),
t_u_train=t_un_train,
t_u_val=t_un_val,
t_c_train=t_c_train,
t_c_val=t_c_val)
贯序模型例程 -【Pytorch完整代码】
import torch
import torch.optim as optim
import torch.nn as nn
from collections import OrderedDict
from matplotlib import pyplot as plt
torch.set_printoptions(edgeitems=2, linewidth=75)
# 数据集准备
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c).unsqueeze(1)
t_u = torch.tensor(t_u).unsqueeze(1)
n_samples = t_u.shape[0] # 获取数据集的样本数量(数据集中元素的数量)
n_val = int(0.2 * n_samples) # 计算验证集的样本数量。这里使用了0.2作为验证集的比例,将数据集中的20%作为验证集
# 生成一个长度为n_samples的随机排列的索引数组。这里使用torch.rand-perm函数生成一个随机排列的整数数组,用于打乱原始数据集的索引顺序
shuffled_indices = torch.randperm(n_samples)
train_indices = shuffled_indices[:-n_val]
val_indices = shuffled_indices[-n_val:]
t_u_train = t_u[train_indices]
t_c_train = t_c[train_indices]
t_u_val = t_u[val_indices]
t_c_val = t_c[val_indices]
t_un_train = 0.1 * t_u_train
t_un_val = 0.1 * t_u_val
linear_model = nn.Linear(1, 1)
linear_model(t_un_val)
def training_loop(n_epochs, optimizer, model, loss_fn, t_u_train, t_u_val,
t_c_train, t_c_val):
for epoch in range(1, n_epochs + 1):
t_p_train = model(t_u_train)
loss_train = loss_fn(t_p_train, t_c_train)
t_p_val = model(t_u_val)
loss_val = loss_fn(t_p_val, t_c_val)
optimizer.zero_grad() # 清除旧梯度
loss_train.backward() # 后向传播计算新梯度
optimizer.step() # 根据梯度进行SGD优化
if epoch == 1 or epoch % 500 == 0:
print(f"Epoch {epoch}, Training loss {loss_train.item():.4f},"
f" Validation loss {loss_val.item():.4f}")
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c) ** 2
return squared_diffs.mean()
linear_model = nn.Linear(1, 1)
optimizer = optim.SGD(linear_model.parameters(), lr=1e-2)
# 尝试线性模型训练
training_loop(
n_epochs=3000,
optimizer=optimizer,
model=linear_model,
# loss_fn=loss_fn,
loss_fn=nn.MSELoss(),
t_u_train=t_un_train,
t_u_val=t_un_val,
t_c_train=t_c_train,
t_c_val=t_c_val)
print()
print(linear_model.weight)
print(linear_model.bias)
# 添加激活层后的贯序模型
seq_model = nn.Sequential(OrderedDict([
('input_linear', nn.Linear(1, 12)),
('hidden_activation', nn.Tanh()),
('output_linear', nn.Linear(12, 1))
]))
print(seq_model)
print([param.shape for param in seq_model.parameters()])
for name, param in seq_model.named_parameters():
print(name, param.shape)
optimizer = optim.SGD(seq_model.parameters(), lr=1e-3)
training_loop(
n_epochs=5000,
optimizer=optimizer,
model=seq_model, # 使用贯序模型重新训练
loss_fn=nn.MSELoss(),
t_u_train=t_un_train,
t_u_val=t_un_val,
t_c_train=t_c_train,
t_c_val=t_c_val)
# 打印模型参数训练结果:
# print('output', seq_model(t_un_val))
# print('answer', t_c_val)
# print('hidden', seq_model.hidden_linear.weight.grad)
t_range = torch.arange(20., 90.).unsqueeze(1)
fig = plt.figure(dpi=100)
plt.xlabel("Fahrenheit")
plt.ylabel("Celsius")
plt.plot(t_u.numpy(), t_c.numpy(), 'o')
plt.plot(t_range.numpy(), seq_model(0.1 * t_range).detach().numpy(), 'c-')
plt.plot(t_u.numpy(), seq_model(0.1 * t_u).detach().numpy(), 'kx')
plt.show()
打印结果:
Epoch 1, Training loss 287.7947, Validation loss 243.3686
Epoch 500, Training loss 6.3782, Validation loss 5.3946
Epoch 1000, Training loss 2.9283, Validation loss 6.1271
Epoch 1500, Training loss 2.4918, Validation loss 6.4090
Epoch 2000, Training loss 2.4366, Validation loss 6.5120
Epoch 2500, Training loss 2.4296, Validation loss 6.5489
Epoch 3000, Training loss 2.4288, Validation loss 6.5621
Parameter containing:
tensor([[5.4817]], requires_grad=True)
Parameter containing:
tensor([-17.4273], requires_grad=True)
Sequential(
(hidden_linear): Linear(in_features=1, out_features=12, bias=True)
(hidden_activation): Tanh()
(output_linear): Linear(in_features=12, out_features=1, bias=True)
)
[torch.Size([12, 1]), torch.Size([12]), torch.Size([1, 12]), torch.Size([1])]
hidden_linear.weight torch.Size([12, 1])
hidden_linear.bias torch.Size([12])
output_linear.weight torch.Size([1, 12])
output_linear.bias torch.Size([1])
Epoch 1, Training loss 200.8066, Validation loss 149.6482
Epoch 500, Training loss 8.0419, Validation loss 6.9692
Epoch 1000, Training loss 2.8967, Validation loss 9.0610
Epoch 1500, Training loss 1.7860, Validation loss 8.2857
Epoch 2000, Training loss 1.4266, Validation loss 7.6947
Epoch 2500, Training loss 1.3101, Validation loss 7.3714
Epoch 3000, Training loss 1.2710, Validation loss 7.2340
Epoch 3500, Training loss 1.2550, Validation loss 7.2035
Epoch 4000, Training loss 1.2451, Validation loss 7.2175
Epoch 4500, Training loss 1.2367, Validation loss 7.2404
Epoch 5000, Training loss 1.2289, Validation loss 7.2637
这个例子中虽然采用的输入层和输出层都是线性层nn.Linear,但是最终拟合出的却是曲线,而非二维的超平面(一条直线),这就是因为隐藏层我们选用了tanh函数,是非线性的,也因此提升了网络的拟合效果:
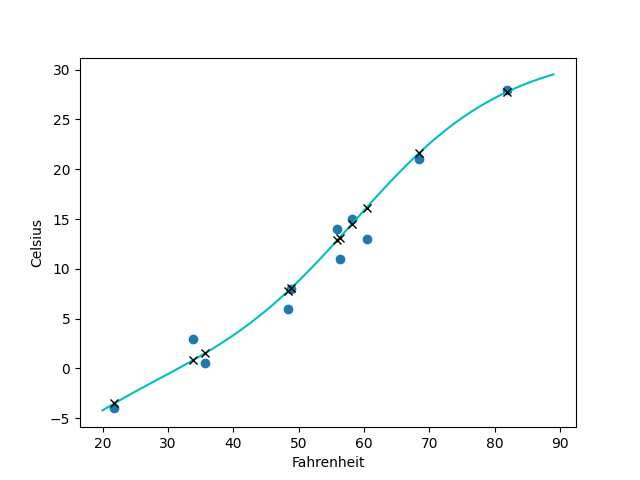
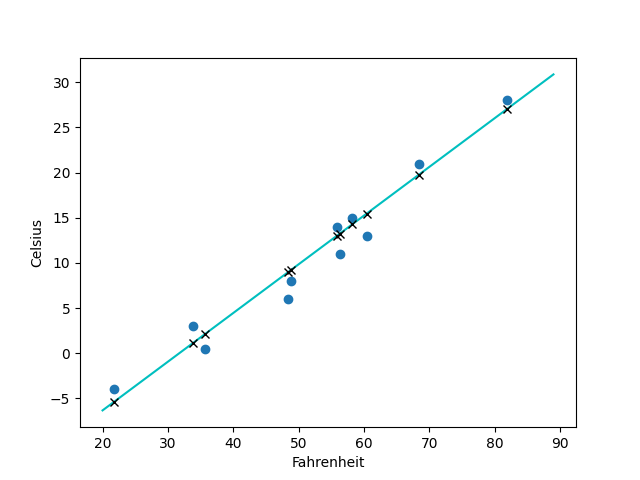
如果我们将nn.Tanh()改为nn.Relu()激活函数,拟合出来的就是一条直线了:
参考文献:
[1] Pytorch官方 - Deep Learning With Pytorch
[2] 《零基础学机器学习》
[3] 感知机 - 谢晋- 算法与数学之美
[4] 感知机w·x+b=0怎么理解?数学推导是什么样的?
[5] 啥都断更的小c-从0开始深度学习:什么是线性层?pytorch中nn.linear怎么用?
[6] 机器学习| 算法笔记-线性回归(Linear Regression)




![pwm接喇叭搞整点报时[keyestudio的8002模块]](https://img-blog.csdnimg.cn/4695518cd3084e38bc1d1942a303fd06.jpeg)