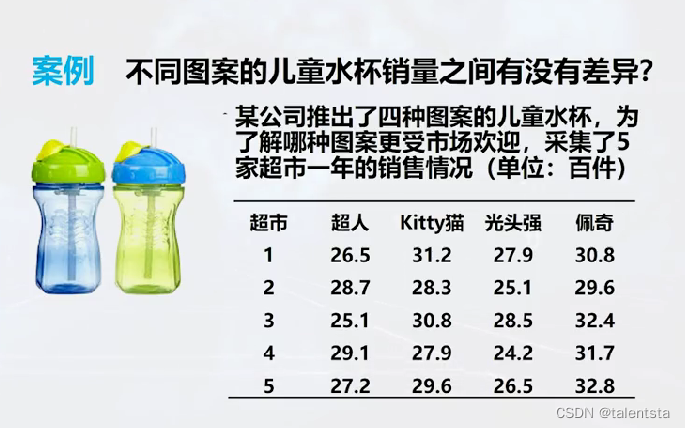
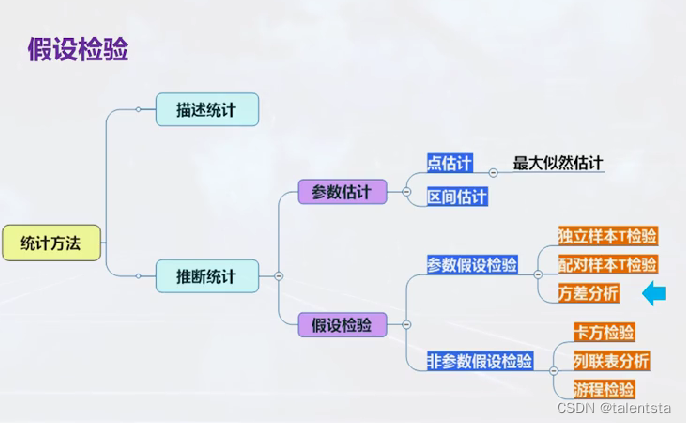
此时我们是取的四种不同图案的儿童水杯的销量作为样本进行分析,单因素方差分析可以用于比较多个独立的正态总体均值之间是否存在显著差异,是独立样本T检验的推广版,也属于参数假设检验。

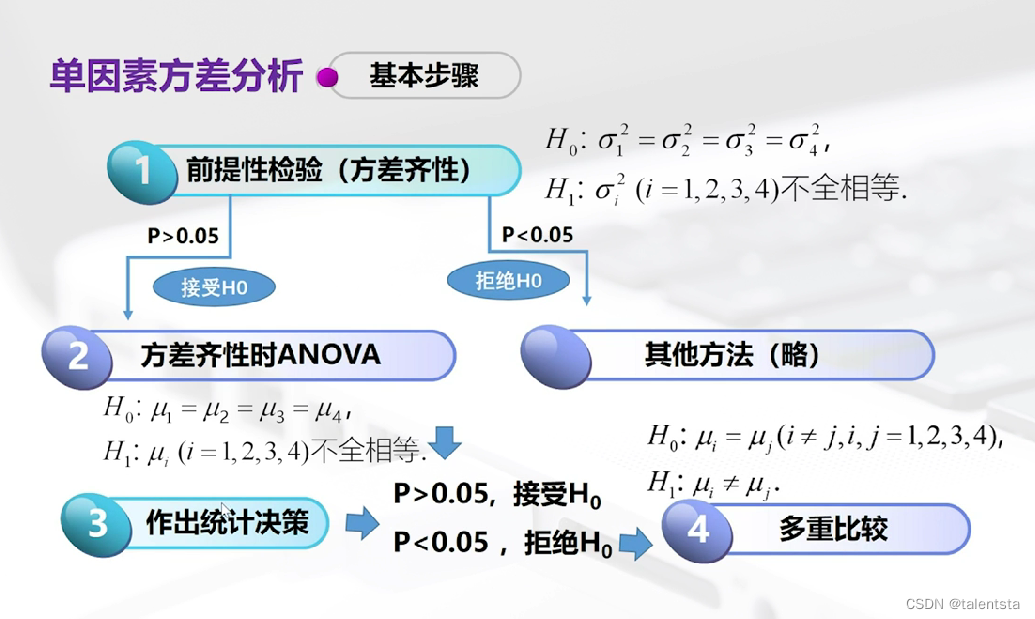
进行假设检验时未说明方差是否齐性时都要先进行方差齐性检验,通过方差检验后再进行下一步分析,假如直接接受原假设时便直接认为要检验的个体之间无显著性差异,拒绝原假设时是指要检验的个体之间不全相等,此时我们经常会有的一个疑问就是其中哪两个个体之间互不相等,所以此时就要开始更深一步的分析进行多重比较。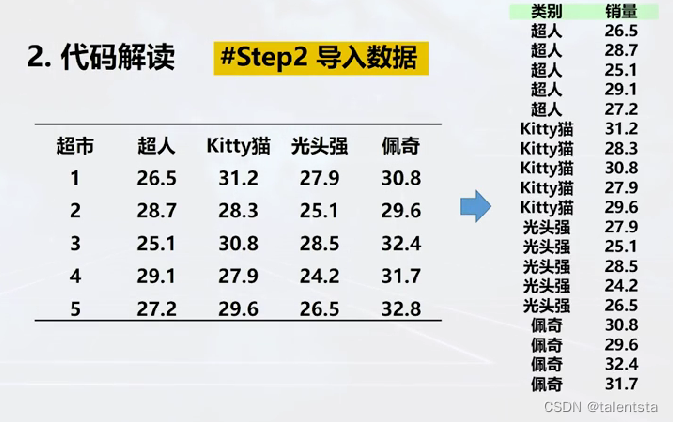
这里我们进行四种不同图案的方差齐性检验时要将数据的形式进行转化成如图所示的形式。
这里的销量数据似乎是按类别进行分组的。将不同类别的数据分开传入levene()函数进行检验,有以下考虑:
- 莱文氏检验是检验两个或多个样本间方差差异的方法。直接对全样本的销量进行检验无法反映类别间的差异。
- 将数据按类别分组,可以检验不同类别的销量方差是否存在差异。这通常是研究分类变量对依变量的影响时需要关注的问题。
- 在许多统计学检验中,需要先检验方差的齐性,以满足方差分析、t检验等的基本假设。
- 如果不同类别间销量的方差不齐,则需要进行调整或选择其他稳健的非参数检验方法。
- 分组传入数据可以得到每个类别的销量分布情况,更方便进行多重比较和进一步分析。
- 利用pandas分组功能可以方便提取每个类别的数据进行分析。
所以进行分组检验可以得出更富有针对性的结论,为后续选择合适的统计分析方法提供依据。

'''step1 调用包'''
import pandas as pd
import numpy as np
#下一行代码用于方差齐性Levend检验
from scipy import stats
#下两行代码用于方差分析
#https://blog.csdn.net/qq_41867980/article/details/90517277?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
#下一行代码用于多重比较
from statsmodels.stats.multicomp import pairwise_tukeyhsd
'''step2 导入数据'''
df = pd.read_excel('data_ANOVA.xlsx')
'''step3 前提性检验:levene检验'''
res_v = stats.levene(df['销量'][df['类别'] == '超人'],
df['销量'][df['类别'] == 'Kitty猫'],
df['销量'][df['类别'] == '光头强'],
df['销量'][df['类别'] == '佩奇'])
print('方差齐性检验P值:',np.round(res_v.pvalue,3))
# 用Scipy中的下列函数也可做ANOVA
#stats.f_oneway(df['销量'][df['类别'] == '超人'],
# df['销量'][df['类别'] == 'Kitty猫'],
# df['销量'][df['类别'] == '光头强'],
# df['销量'][df['类别'] == '佩奇'])
'''Step4 单因素方差分析'''
formula = '销量~类别'
anova_results = anova_lm(ols(formula,df).fit())
print('\n方差分析结果(ANOVA表):\n',anova_results)
'''Step5 多重比较'''
# 逐对比较差异,原假设:二者之间无显著差异
res_post = pairwise_tukeyhsd(df['销量'],
df['类别'],alpha=0.05)
print('\n多重比较结果:\n',res_post)
这里将不同类别的销量数据传入levene()时,是将每个类别的数据放在一列,形成了多列的输入。
这种做法的主要考虑可能有:
- levene()函数的参数输入要求是多组数据形成的列向量。将不同类别的数据分别放在一列,符合函数的参数要求。
- 将同一类别的数据放在一列,可以更直观地反映每个类别内部的数据分布情况。
- 将不同类别分开传入,levene()会自动逐组进行方差检验,无需再循环调用。代码更简洁。
- 相比把所有数据放在同一列,分组传入可以明确数据之间的分组关系,便于理解。
- 分组处理数据也有利于后续进行多重比较等更复杂的分析。
- pandas的分组提取功能使得获取分组数据非常简单方便。
- 一列一组数据结构也易于可视化,直观展示每个类别的分布差异。
所以,这种分组传入的方法比较简洁高效,符合函数需求,也有利于进行更深入的分析,是进行莱文氏检验的合理数据处理方式。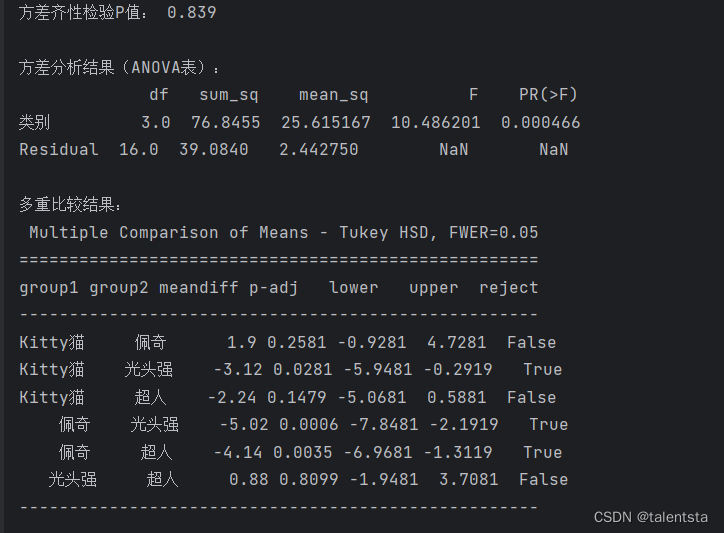
此时我们根据结果来看,此时的方差齐性检验的p值远大于0.05,所以此时接受原假设认为方差齐性,此时再进行进一步的方差分析时,看到此时的p值便远小于0.05,此时拒绝方差分析的原假设认为此时的均值不完全相等,四种图案的水杯销量不完全相同,此时再进行两两比较时看到最后一列是否拒绝时,以Kitty猫 和光头强为例,原假设是假设他们之间销量相同,此时拒绝之后就是认为他们之间销量不同,认为这两种图案的水杯的销售量存在明显差异。