写在前面
本文是K8S系列第三篇,主要面向对K8S新手同学,阅读本文需要读者对K8S的基本概念,比如Pod、Deployment、Service、Namespace等基础概念有所了解。尚且不熟悉的同学推荐先阅读本系列的第一篇文章《K8S系列一:概念入门》[1]。
本文旨在讲述如何基于K8S集群部署一个web服务,包括如何更优雅地获取配置信息、如何保存日志以便排查问题。本文将重点介绍以下的K8S对象(API Resources,可能翻译成“资源”更好?不过笔者更喜欢API对象的称呼,如果有特别不妥,后面再换回来):
- Pod的容器 - Container
- Pod的存储 - Volume
- Pod的配置 - ConfigMap和Secret
- Pod的网络 - Service
I. 单服务部署概要
在前文中提到过,传统的服务部署方式一般是:
(1).首先准备好“完整的程序文件包”,其内容包括脚本文件、可执行程序、依赖库、配置文件等。
(2).接着把这个“完整的程序文件包”分发到物理机器的某个固定位置,比如/opt/、/usr/local/services/等。
(3).最后通过脚本文件或者直接命令启动程序入口的可执行程序,程序就会运行起来。
当然,运行程序还有可能需要网络顺畅,比如需要下载数据;还需要物理机上磁盘有足够空间,用以存储日志和中间结果等。
从上面的过程中摘取核心要点,不难发现,一个服务的部署需要满足几个要素:

- 环境。一个完整的服务可能是由可执行程序组成的(这也是一种“微服务”架构),每一个可执行程序对应了Pod内部的Container;显然,在这块k8s的做法更具备优势,因为不同程序的依赖库和版本不同,如果在同一个环境中往往需要解决版本冲突问题,而放到不同Container之后,冲突问题就不存在了。
- 存储。私以为在一个Pod中多Container之间存储共享的方式是不方便的,但这个也是由于环境隔离造成的,总体来说利大于弊。k8s的解决办法是引入了Volume资源对象,而Container通过挂载Volume方式来共享存储资源。这种也是解决Container没办法持久化存储的最有效办法。
- 配置。其实配置文件完全可以和可执行程序一起打包/挂载到镜像的手段来完成。但是k8s也提供了一种比较好的做法,即通过ConfigMap或Secret管理配置内容,再通过挂载到Pod的具体Container内部暴露给Container内的服务。
- 网络。k8s集群有自己的一套网络机制,通过Service、Ingress甚至ISTIO组件来做k8s集群内部、内外通信。
而k8s把以上几个要素都考虑到了。这里,我们需要达成统一的观点:对于k8s而言,我们平时经常说的一个“服务”实际上对应是一个Pod。k8s中提出的措施机制是:Container(环境)、Volume(存储)、ConfigMap和Secret(配置)、Service(网络)。本章将详细展开每一个API对象的使用办法、以及实际使用的小tip。下图可以表述它们之间的关系:

本文介将围绕下面这个Pod展开:
apiVersion: v1
kind: Pod
metadata:
name: demo
namespace: test
spec:
containers:
- name: main
image: polinux/stress
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
volumeMounts:
- name: redis-storage
mountPath: /data/redis
volumes:
- name: redis-storage
emptyDir: {}
II. Container
其实,Container并不是k8s的API对象,但是Container可以说是Pod非常重要的元素,因此单独拎出来介绍。此外,我们常用的容器一般是docker,本节也会以docker为例。
首先,来看下Container基础的用法。上面名为“demo”的Pod的yaml文件中,与Container相关的参数几乎占了一半,把相关的拎出来并给出注释:
containers:
- name: main # 容器名称
image: polinux/stress # 容器的镜像地址
resources: # 容器所需的机器资源
limits:
memory: "200Mi"
requests:
memory: "100Mi"
command: ["stress"] # 容器的入口command
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"] # 容器的入口command的参数
volumeMounts: # 容器的挂载点
- name: redis-storage
mountPath: /data/redis
容器的名称、镜像地址没什么可说的。‘container.resources’这块只要记住’container.resources.requests’<=‘container.resources.limits’,容器实际占用一定是[‘container.resources.requests’, ‘container.resources.limits’],前者是容器对机器的资源要求的下限,后者是容器占用机器资源的上限。而’container.command’和’container.args’则是容器入口命令,本文不做展开。'container.volumeMounts’是容器的挂载点,这个非常关键!k8s外部的存储盘、配置文件都是通过这个挂载到容器内的,这块的具体使用在下一节会提到。
接着,再来看点相对不基础,但是很常用的知识。
1. 如何拉取需要密钥的镜像?
通过Secret配置!官方有非常详细的指导手册《从私有仓库拉取镜像》[2],总结来说是:
- 首先,把拉取镜像的鉴权信息保存成k8s的Secret对象;
- 接着,在Pod的yaml文件中的imagePullSecrets指定到上面的Secret即可;
2. 拉取镜像的策略?
这个非常坑!笔者曾经遇到过一次,修改了镜像内容后没有修改tag直接push回镜像仓库,回到k8s集群重启pod对象,但是镜像没有更新。后来才知道需要指定imagePullPolicy为Always。不过根据《k8s-in-action》[3]书籍中所述:
You need to be aware that the default imagePullPolicy depends on the
image tag. If a container refers to the latest tag (either explicitly
or by not specifying the tag at all), imagePullPolicy defaults to
Always, but if the container refers to any other tag, the policy
defaults to IfNotPresent.
你需要注意imagePullPolicy的默认值视镜像的tag不同。如果容器镜像的tag是latest(显示指定或者缺省),imagePullPolicy的默认值是Always;否则,imagePullPolicy的默认值是IfNotPresent。
总之为了保险起见,笔者建议指定imagePullPolicy为Always。
3. 如何登陆镜像排查问题?
- 线上经常遇到服务出现问题之类的,因此避免不了登录容器排查问题。情况分为几种: 服务还在。这种情况处理起来比较简单,使用kubectl -n
${namespace} exec -it ${pod-name} -c ${container-name}
/bin/bash就能以交互式bash进入容器操作;使用kubectl -n ${namespace} exec ${pod-name}
-c ${container-name} – ${command} 则可以不进入容器做一些简单的操作,比如查看日志。当然,直接用kubectl -n ${namespace} logs
${pod-name} -c ${container-name} 也能不用登录容器查看日志。 - 服务挂了。这种情况相对比较麻烦,登录容器肯定是不可能的了,但是仍旧可以查看日志,用法是加一个-p或者–previous=true,具体命令为kubectl
-n ${namespace} logs -c ${pod-name} -c ${container-name}。不过,只有因为异常退出的容器才能使用该命令,如果是被Terminated的容器则无法查看。可以参考How
to see logs of terminated pods[4]的讨论。
更好的建议是,对于部署到k8s上的服务,最好有集中的日志管理系统来统一管理服务日志,比如Elasticsearch[5]。
4. 容器分类?
-
k8s支持一个Pod内包括多个Container,并且,k8s把Container也分了类型:
InitContainer。初始化容器,这个最为特别,它是通过’initContainers’而非’containers’指定的,k8s会确保’initContainers’下的容器首先启动,结束后再启动’containers’下的容器。 -
StandardContainer。标准容器,即我们常见常用的容器,无特别之处,不提。
-
SidecarContainer。边车容器,u1s1,sidecarContainer和mainContainer没有什么不同,仅是从业务角度来说,这个容器内做的事情与主业务无关、往往辅助类事情。据说,在k8s
1.8版本之后新增了’container.lifecycle.type’来和标准容器进行区分[6]。 -
EphemeralContainer。临时容器,笔者还没有用过这类容器,因此特性并不清楚。
在真正使用中,initContainer可以做些前提准备工作,比如下载数据;sidecarContainer则做些辅助工作,比如收集日志。
4. 多容器的使用?
在前文中提到过,虽然由于不同Container的文件系统隔离关系,它们无法互相访问彼此的数据(但是k8s仍然给出了解决办法,具体措施在下一节),但是其他各个方面,譬如网络、IPC等,同个Pod内各个Container之间就如同部署在同一台“物理机”上。
那么,k8s究竟做了什么使得同个Pod内的Container之间能够共享网络、IPC等,而不同Pod的Container之间完全隔离呢?这个是unix提供的namespace和cgroup技术。前者欢迎阅读文章《Multi-Container Pods in Kubernetes》[7];后者也可以自行Google了解,对于docker的虚拟化会有更深的了解。
(unix提供的namespace和cgroup技术笔者也不十分了解,暂且在这里挖个坑,后面填。)
III. Volume
Volume是k8s中十分基础且重要,但也很容易被忽视的一个API对象,就像我们在部署服务时经常忽视磁盘一样,因为实在太基础且越来越便宜。但是如果不做好Volume的功课,简单把它等同于磁盘mount的话,k8s的Volume是会服务部署带来不少困扰的。
Volume的语法格式其实也相对比较简单,把"demo"的yaml文件中和Volume有关的拎出来:
volumes:
- name: redis-storage
emptyDir: {}
嗯,Volume的语法基本是由’name’和具体类型组成的。请注意:'volumes’单单做了Volume的声明,真正使用的话,还是要在’container.volumeMounts’通过Volume的’name’挂载到Container中。
1.Volume分类?
k8s的Volume提供了非常丰富的类型,可以涵盖大部分应用场景。关于Volume类型的介绍,网上的博文非常多,而且都写的非常棒,本文就不再赘述,推荐几篇:《Volumes》[8]、《 Kubernetes 存储卷》[9]、《[Kubernetes] Volume Overview》[10]。这里对常用到的做个简单总结:
| 类型 | 使用办法 | |
|---|---|---|
| emptyDir | 同Pod | 临时空文件夹,随着Pod的销毁而销毁 |
| nfs | 同NFS | 类似hostPath |
| configMap/secret | ? | 依赖于ConfigMap/Secret。Pod销毁数据还在ConfigMap/Secret中 |
2. hostPath有坑?
2.1. 慎重选择hostPath的type
第一个坑是k8s为hostPath提供了多种挂载的type,从官网[8]可以看到目前提供的类型:

坑就出现在第一个取值为空的type上,或许读者会问“这个功能不是挺好的么,不对挂载盘做检查,使用起来非常自由,哪里坑了?”
分享笔者一次遇到的问题:通过hostPath和type为空的方式挂载了本地的一个压缩包文件${tar},但是事先出了意外导致{tar}没有放到正确的位置,最后Pod正常启动但是程序响应异常了。排查后知道是压缩包文件没放上去,企图重新放压缩包文件,再重启Pod,但是失败了!原因是:当type为空且k8s发现挂载的路径/文件不存在,它会创建一个同名的目录!!!(当然上传压缩包文件的程序写的也不够鲁邦)
2.2. 小心hostPath把本地磁盘打满
Pod会通过’container.resources.limit’来约束容器内程序对CPU和内存等资源的占用,但是目前并没有约束对磁盘的占用。 特别在一台机器上会被分配到多个Pod,一定小心多个Pod把本地磁盘占满的情况。而磁盘满的话,k8s会把这个worker node上的Pod都驱逐掉,分配到其他woker node上;如果k8s集群的node资源紧张,那么这些Pod的服务就一直起不来了。
分享笔者项目中遇到的问题:有几次发现线上多个服务突然不工作了,定位发现是一台机器磁盘满了,再进一步定义发现多个Pod都在往同一个数据盘存日志,日积月累就把磁盘打满了;还有好几次k8s整个集群不能工作,结果也是把机器上的系统盘等打满了。
虽然“磁盘满”这个问题听上去是新手小白才会犯的错误,但是实际在管理一个庞大集群的时候,是非常容易遇到的。
3.configMap/secret热加载/同步?
通过Volume挂载ConfigMap和Secret,在实际场景中非常常见。譬如把服务所需的配置文件记录在ConfigMap或者Secret中,通过挂载就变成容器内的一个配置文件。
但是使用中需要注意热加载,或者说是同步的问题:即**修改了ConfigMap和Secret的内容,已经挂载到Container的配置文件内容会同步修改么?**答案是:不会。为此笔者做了几次实验,除非重建Pod否则并不会做同步,并且k8s似乎也没有提供热加载/同步的机制。
IV. ConfigMap和Secret
ConfigMap和Secret是k8s中经常被使用到的API对象,他俩本质都是存储kv键值对的,只是前者存储的数据是明文的;后者存储的是base64加密后的数据。ConfigMap比Secret更简单,纯粹的kv键值对,借用官方《ConfigMaps》[11]中的例子,一个ConfigMap的yaml文件长下面这个样子:
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
# 简单的键值对
player_initial_lives: "3"
ui_properties_file_name: "user-interface.properties"
# 如果期望作为配置文件
game.properties: |
enemy.types=aliens,monsters
player.maximum-lives=5
user-interface.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
而Secret更复杂些,因为它的初衷是用于存储一些敏感的数据,如密钥、密码等。Secret分为多种类型,在官方文档《Secrets》[12]中有详细介绍,本文不再赘述:

这里插一句题外话:base64加密的级别实在太弱了,直接用base64 decode命令base64 -d ${data-string}就看到了(捂脸)。
再借用官方[12]的例子,一个Secret的yaml文件长下面这个样子:
apiVersion: v1
kind: Secret
metadata:
name: secret-sa-sample
annotations:
kubernetes.io/service-account.name: "sa-name"
type: kubernetes.io/service-account-token
data:
# You can include additional key value pairs as you do with Opaque Secrets
extra: YmFyCg==
ConfigMap和Secret的yaml文件内容极其相似,真正的数据都在’data’项目下;而且它俩在使用上也极为相似,总结来说可以分为:
- 配置文件。正如上一节最后提到的用法,通过Volume挂载到Container中。而且ConfigMap/Secret的挂载非常有趣,k8s不是简单把ConfigMap/Secret作为文件挂载进去,而是对于’data’下的每个kv键值对,以key作为文件名,value作为文件内容得到一个文件,挂载到Container内指定的路径。
- 环境变量。这也是实际场景中常见的用法之一,通过’container.envFrom’进行指定,既可以只指定几个键值对,也可以ConfigMap/Secret所有的键值对都加载进来。这里有一个事情需要注意:通过环境变量加载Secret到Container之后,在Container内部看到的value值是经过base64 decode后的数据。至于上面配置文件,笔者没有试验过,有清楚的朋友欢迎留言告知。此外,配置文件挂载的方式不支持热加载/同步,环境变量加载的方式同样也不支持热加载/同步。
V. Service
前文[1]已经解释过k8s中Service的意思:k8s的Service并不是传统意义上的“服务”,而更像是网关层,是若干个Pod的流量入口、流量均衡器。
第一点. 可以看到,配置好Container环境、Volume数据盘、ConfigMap/Secret配置文件或者环境变量之后,一个服务已经可以独立跑起来了!但是真正部署好服务之后会发现,在k8s集群外部似乎访问不了部署到k8s集群中的服务?(请注意,k8s的网络模型有underlay和overlay两种,本文默认k8s使用overlay。k8s的网络模型笔者也没完全搞懂,这里继续挖个坑。)如下图,笔者在k8s上部署了一个开放8080端口的服务,发现通过IP根本访问不通!

第二点. 在实际场景中为了提供高可用服务,往往会在不同的机器上部署多个服务实例。在k8s中如果一个Pod部署多份(名字一定不同,比如kubia-1,kubia-2这种),那么这多份Pod一定得对外有统一的访问当时,即IP和Port,并且有流量负载均衡策略,把流量分配到多份Pod上。
以上这些,就是k8s的Service要做的事情:屏蔽服务细节,对外暴露统一的服务接口,真正做到了“(微)服务”。总的来说,Service带来的优势有:
- Service提供了几种类型/机制,分别对集群内可访问和对集群外可访问的服务接口;
- Service通过label来绑定若干Pod,使得这若干的Pod能够对外暴露统一的服务接口。最重要的是,即使Pod重启后其IP改变了,也不会影响Service。
可以说,Service是k8s非常重要的一个API对象,一定要掌握其使用办法!笔者阅读过很多博文,总是越看越糊涂,最后是阅读了《k8s-in-action》[5]后豁然开朗,强烈推荐!这里,笔者会详细Service的几种访问机制、排查Service不工作的手段。因为这些都是实际场景中部署和运维服务必备的。
在此之前,先来看一个Service的yaml文件(来自官网《Service》[13]):
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
内容非常简单,重点需要关注的有2点:
- ‘selector’:这个是Service用以绑定Pod的关键语法。这里的’app:
MyApp’被称为label,label可以有多个。‘selector’则会去同一个namespace下寻找匹配label的Pod做绑定。而Pod的lable则是在’metadata.labels’定义的,用户可以随便写,甚至可以写’foo:
bar’。 - ‘ports’:端口映射。其中’port’是Service对外(k8s集群内/外)暴露的端口,而’targetPort’则是匹配绑定了的Pod的端口,不要弄反了。看了下图会更清晰些:

5.1 Service的类型
常用的Service有三种类型/机制(也有说法还有headless等其他类型,这里不展开):ClusterIP、NodePort和LoadBalancer。第一点需要记住的是:ClusterIP只能提供对k8s集群内部可访问的IP和Port,NodePort和LoadBalancer则能够提供k8s集群外可访问的IP和Port。第二点需要记住的是:这三种类型/机制的关系不是互相排斥,而是层层递进。也就是说,NodePort机制包含ClusterIP,LoadBlanacer包含NodePort和CluterIP。相信看了下图会更明白:

借用《k8s-in-action》[3]的插图来解释这三种类型/机制:
- CluterIP
ClusterIP是Service默认的类型/机制。如上面的yaml文件,并没有指定type,那执行kubectl create -f service-demo.yaml之后就会是一个CluterIP类型的Service。CluterIP类型的Service会提供一个’CLUSTER-IP’和’PORT(S)',能够允许k8s内部相同namespace下的任何Pod访问。
在k8s集群中,用kubectl查看ClusterIP会得到如下图:

- NodePort
如果希望直接通过Service对集群外部提供访问方式,那么NodePort是一种勉强不错的方法,并且所有的k8s集群都能支持这种机制。创建时,需要指定’type: NodePort’。在k8s集群中,用kubectl查看NodePort你会得到:

会发现NodePort和ClusterIP似乎没有太大的不同,仅仅是在’PORT(S)'中多了一个数字30839。于是你尝试telnet ${CLUSTER-IP} 80,发现不行;你又尝试telnet ${CLUSTER-IP} 30839,哎还是不行。恼羞成怒:怎么回事,NodePort不能用啊,垃圾?!
因此,我们需要了解NodePort究竟做了什么使得集群外部能够访问。笔者认为,下图非常有助于理解(图片来自于《k8s-in-action》[3]):

NodePort实际是在Pod所在的物理机器上开了一个端口,让外部流量从这个端口先导流到自己的’port’,再导入’targetPort’(也就是Pod的端口)。
所以,在使用NodePort类型的时候,请记住正确的访问方式是telnet ${Pod所在的NODE} ${PORT(S)非定义的端口号}。这就意味着,你还需要查看绑定的Pod所在的物理机IP,可以使用kubectl get pod -o wide -l ${lable}:

那么,使用telnet 9.235.138.15 30839原则上应该是可以访问通的,我们来试试:

果然可以!
再回过头来看,NodePort的’CLUSTER-IP’其实是供k8s集群内访问的IP,这就是ClusterIP的机制,也就证明了NodePort类型/机制是包括ClusterIP的。
- LoadBalancer
NodePort类型/机制仅仅提供了对k8s集群外访问的方式,很快就会发现这种方法违背了Service的流量负载均衡的策略,因为通过Pod所在机器IP访问的流量,只能够导入到该机器上的Pod,其他机器上就不行了。因此就有了LoadBalancer。**LoadBalancer的做法是在NodePort基础上增加一个EXTERNAL-IP,集群外部调用该IP+自定义的port就能够访问Pod。**相信下图会更有助于对LoadBalancer的理解(图片来自于《k8s-in-action》[3]):

但是,并不是所有的k8s集群都能够支持LoadBalancer,笔者目前使用的k8s集群就不支持,在’EXTERNAL-IP’这一列一直处于状态:

5.2 Service问题排查
一般来说,创建好一个Service之后,只要绑定了正常可服务的Pod就应该能够通过Service提供的访问方式访问到Pod了(k8s集群内或外)。具体绑定方式在上文中已经提到过,这里再强调一遍:通过label来关联Service和Pod。
但实际场景中,遇到访问不通的问题时有发生(这里指的是telnet不通的情况),本小节就介绍下怎么排查这个问题,以及Service和Pod究竟是怎么通过label绑定的。
首先需要了解k8s另一个API对象Endpoint,端点切片。Endpoint是随着Service的生成而被动生成的。此外,虽然从使用上来看,Service和Pod是通过label绑定的,但是实际上Service和Pod是通过Endpoint来做关联的。因此Endpoint是查看Service是否真正绑定到Pod上的有力工具!
一个正常的、可用的Service和Pod的状态应该如下图:
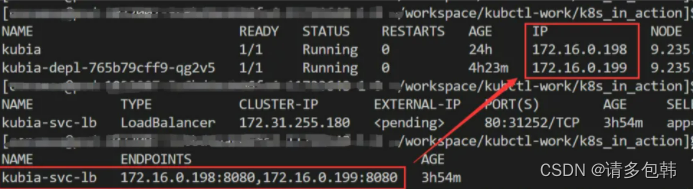
会看到Endpoint其实是一个如倒排表的结构,存储了Service名称和其绑定的一系列PodIP+Port。
但是,如果仅仅创建了一个Service而没有Pod的话,再查看Endpoint会发现其内容为:

再比如,Service和Pod都被创建了,但是Pod由于种种原因没有正常服务,这个时候EndPoint内容是空:

因此,实际应用中操作Service,一定记得把Endpoint用起来!
最后,k8s内部的网络策略/机制,包括DNS策略/机制,非常值得深挖和学习,笔者在这里继续挖个坑。
写在后面
本文是K8S系列文章第三篇,旨在前两篇入门介绍(概念入门和实践入门)基础上,介绍在实际应用中部署服务常见的用法和注意事项。如果文章中有纰漏,非常欢迎留言或者私信指出;有理解错误的地方,更是欢迎留言或者私信告知。
非常欢迎大家留言或者私信交流更多K8S的问题。