目录
1. 线程池相比于线程有什么优点
2. 线程池的参数有哪些
3. 线程工厂有什么用
4. 说一下线程的优先级
5. 说一下线程池的执行流程
6. 线程池的拒绝策略有哪些
7. 如何实现自定义拒绝策略
8. 如何判断线程池中的任务是否执行完成
1. 线程池相比于线程有什么优点
有时候面试官也会这么问 : 让你介绍一下线程池,都是一样的回答方式。
在实际生活中,一般都是使用线程池,而不使用普通的线程,使用线程池有以下几个好处:
1. 降低资源消耗:线程池可以重复利用已经创建好的线程,避免了频繁创建和销毁线程带来的开销。其次呢,线程池可以有效地管理和控制线程的数量,避免线程过多而导致资源浪费。
2. 提高响应速度:线程池中的线程是预先创建好的,所以当任务来临时,它可以立即分配线程来进行处理,提高了任务的响应速度。
3. 提高系统稳定性:线程池可以限制并发时的线程数量,避免因为线程过多而导致资源耗尽或系统崩溃。它可以合理的控制系统的负载,以提高系统的稳定性。
4. 支持任务队列:线程池通常会使用任务队列来存储待执行的任务。当线程池中的线程都在执行任务时,新的任务可以被放入任务队列中排队等待执行,避免任务丢失或阻塞。
2. 线程池的参数有哪些
线程池 ThreadPoolExecutor 最多可以支持 7 个参数的设置(最少 5 个),底层源码:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
// maximumPoolSize 必须大于 0, 且必须大于 corePoolSize
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}7 个参数的含义如下 :
1. corePoolSize:表示线程池的常驻核心线程数
这个值如果设为 0, 则表示在没有任务的时候,销毁线程池;如果大于 0,即使没有任务也会保证线程池的线程数量等于这个值。(这个值如果设置的比较小,则会频繁的创建和销毁线程;如果设置的比较大,则浪费系统资源,实际工作中根据业务场景来调整)
2. maximumPoolSize:表示线程池在任务最多的时候,最大可以创建的线程数
官方规定这个值必须大于 0。也必须大于等于 corePoolSize,(此值只有在任务比较多的时候,且任务队列已经存满的时候,才会用到)
3. keepAliveTime:表示临时线程(最大线程数-核心线程数)的存活时间
当线程池空闲时并且超过了这个时间,就会销毁临时线程,直到线程池中的线程数量等于 corePoolSize 为止。
4. unit:表示临时线程的存活单位
5. workQueue:表示线程池执行的任务队列
当线程池的所有线程都在处理任务时,新加入的任务就会缓存到任务队列中,排队等待执行。
6.threadFactory:表示线程的创建工厂
可以用来设置线程名称,线程优先级,以及线程的类型(前后台线程)等内容。
7. RejectedExecutionHandler:表示指定线程池的拒绝策略
当线程池中的核心线程数都在执行任务,任务队列此也已经满了,并且线程池中的线程数已经达到设置的最大线程数了(不能创建新线程了),就会使用到拒绝策略,它是一种限流保护的机制。
3. 线程工厂有什么用
通过线程工厂可以设置线程池中可以创建的最大线程数,设置线程的名称,线程的优先级以及线程的类型等内容。
ThreadFactory threadFactory = new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
// 创建线程池中的线程
Thread thread = new Thread(r);
// 设置线程名称
thread.setName("Thread-" + r.hashCode());
// 设置线程的优先级 (1-10) 最大 10
thread.setPriority(Thread.MAX_PRIORITY);
// 设置线程的类型 (前台/后台线程)
thread.setDaemon(false);
// ....
return thread;
}
};4. 说一下线程的优先级
线程的优先级用整数表示,范围在 1-10 之间,并且数字越大表示的优先级越高,线程的默认优先级为 5。
设置线程优先级的作用:
线程优先级表示当前线程被调度的权重,也就是说线程的优先级越高,表示线程被被调度执行的可能性就越大,它会给线程调度器一个建议,具体是不是优先级越高的越先执行是不一定的。它这样设计的目的就是为了防止线程饿死。
在 Java 中,可以通过 Thread 类的 setPriority() 和 个体 getPriority() 来设置和获取线程的优先级
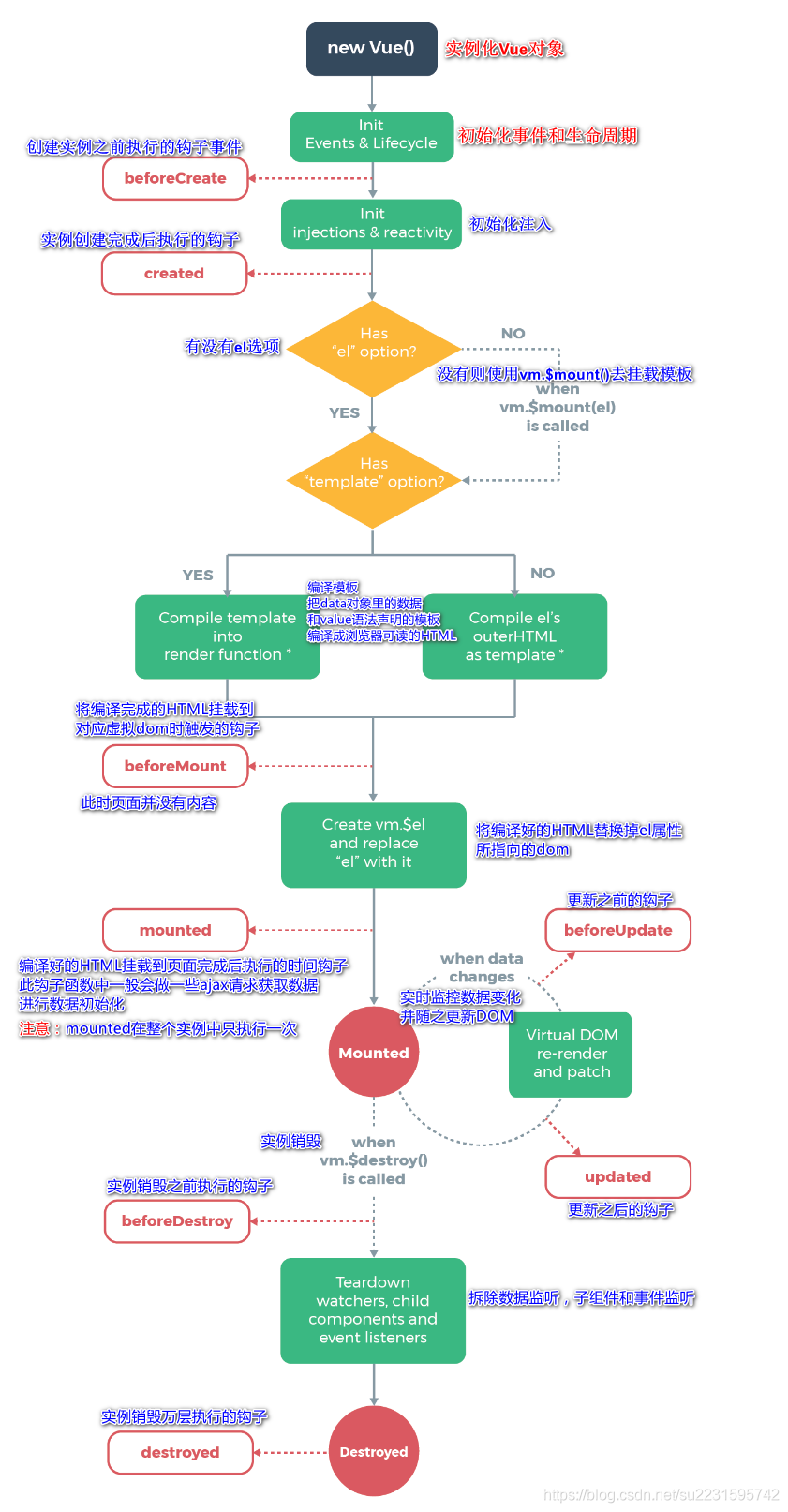
5. 说一下线程池的执行流程
线程池的执行流程通过下图进行梳理:

由于线程池是以懒加载的方式进行创建线程的,所以线程池创建第一个线程的时候,它普通的创建线程没有区别。
- 当任务来临时,它会先去判断一下实际线程数是否大于核心线程数,如果小于等于核心线程数,说明此时任务比较少,所以此时只需要创建一个新的线程来执行任务就完事了。
- 如果实际线程数大于核心线程数了,然后再去判断任务队列有没有满,如果队列没有满,那么就将新任务加入到任务队列中排队等待执行。
- 如果队列满了,那么再去判断实际线程数是否超过最大线程数,如果没有超过,那么创建一个新的线程来执行任务就完事了。
- 如果已经超过最大线程数了,那么就会执行拒绝策略。
【联系到快递公司】
- 当有新的快递来临了,我先看一下公司正式员工忙不忙的过来,如果有人空闲,那么安排空闲的人去干活。
- 如果公司的正式员工手头都忙不过来,此时检查一下快递仓库是否满了,如果没满,那么就放入快递仓库排队等待执行。
- 如果快递仓库也满了,老板此时还想挣这个钱,那么他会先计算出当前要招多少员工,才能保证利益最大化,如果当前公司总员工(正式+临时)还没有超过预算值,那么就招临时工来帮忙。
- 如果说招的临时工已经达到最大预算了,那么此时就会执行拒绝策略了,我不接单了。
6. 线程池的拒绝策略有哪些
拒绝策略一共有 5 种,线程池内置了 4 种和一种自定义拒绝策略,这四种拒绝策略分别是 :
1. AbortPolicy:终止策略,线程池会抛出异常并终止执行此任务;
在接不了订单的情况下,公司还有部门接单,那么领导就会开内部批斗大会,并终止快递流程。
2. CallerRunsPolciy:把任务交给添加此任务的(main)线程来执行;
在接不了订单的情况下,此时有一个卡车司机拉了一车快递来了,于是跟货车司机说:老弟啊,哥这也忙不过来了,你想不想挣个块钱发家致富,于是就将这个任务交给卡车司机来执行。
3. DiscardPolicy:忽略当前任务(最新的任务);
4. DiscardOldestPolicy:忽略任务队列中最早加入的任务,接收新任务(加入任务队列);
线程池默认的拒绝策略为 AbortPolicy 终止策略。
7. 如何实现自定义拒绝策略
代码示例:
// 创建 runnable 对象
// ...
ThreadPoolExecutor threadPool =
new ThreadPoolExecutor(1, 1,
100, TimeUnit.SECONDS, new LinkedBlockingQueue<>(1),
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r,ThreadPoolExecutor executor) {
// 执行自定义拒绝策略
// 1.记录日志,方便问题的追溯
// 2.通知相关人员来解决问题
System.out.println("执行自定义拒绝策略");
}
});
// 添加并执行 3 个任务
threadPool.execute(runnable);
threadPool.execute(runnable);
threadPool.execute(runnable);拒绝策略里面一般可以做两件事:
- 记录日志,以便问题的追溯;
- 通过相关人员来解决问题。
如果面试官此时还问:你在实际工作中/你的项目中,你使用的是哪一种拒绝策略?
如果不知道怎么回答,建议回答自定义拒绝策略,因为它比较灵活,它可以去设置我想去设置的一些代码,我在里面呢,首先我可以把错误记录下来,其次我可以给任务队列发一个邮件,或者发一个 MQ(消息不丢失)
8. 如何判断线程池中的任务是否执行完成
" 牛客上有人在面试用友的时候,被问到王者荣耀 5 个人都加载完成才进入游戏,用 Java 应该怎么实现,就和这个问题如出一辙 "
判断线程池中的任务是否执行完成,有三种方法:(线程池提供了两种,还可以借助计数器)
1. 使用 getCompletedTaskCount() 统计已经执行完的任务,使用 getTaskCount() 获取线程池的总任务,将二者进行对比,如果相等就说明线程池的任务执行完了,反之没有执行完。
2. 使用 FutureTask 等待所有任务执行完。(类似于 Thread 里面的 join)
3. 借助计数器 CountDownLatch 或 CyclicBarrier 来实现。
① getCompletedTaskCount() 方式
private static void isCompleteByTaskCount(ThreadPoolExecutor threadPool) {
while(threadPool.getCompletedTaskCount()
!= threadPool.getTaskCount()) {
// 如果 已完成任务数 != 总任务数, 就一直进行自旋
}
}这种方式的缺点:
- 如果已完成任务数 != 总任务数,那么就会一直自旋,过于消耗系统性能;
- 判断不够精准,因为线程池是公用的,如果这个时候有其他线程来添加了新的任务,那么总的任务数就变了,而我只想判断属于我的这几个任务知否执行完。
所以 getCompletedTaskCount() 并不是最优的实现方式。
② FutureTask 的方式
代码示例:
- 定义三个任务 (callable)
- 调用线程池提供的 submit 方法 (可执行回调任务/非回调任务)
- 调用任务的 get() 方法 (同步阻塞,类似于 thread.join())
public static void main(String[] args) throws ExecutionException,
InterruptedException {
// 创建固定大小的线程池
ExecutorService executor = Executors.newFixedThreadPool(3);
// 创建 3 个任务
FutureTask<Integer> task1 = new FutureTask<>(() -> {
System.out.println("task1 开始执行");
Thread.sleep(2000);
System.out.println("task1 执行结束");
return 1;
});
FutureTask<Integer> task2 = new FutureTask<>(() -> {
System.out.println("task2 开始执行");
Thread.sleep(2000);
System.out.println("task2 执行结束");
return 2;
});
FutureTask<Integer> task3 = new FutureTask<>(() -> {
System.out.println("task3 开始执行");
Thread.sleep(2000);
System.out.println("task3 执行结束");
return 3;
});
// 提交 3 个任务给线程池
executor.submit(task1);
executor.submit(task2);
executor.submit(task3);
// 等所有任务执行完毕并获取结果 (同步阻塞)
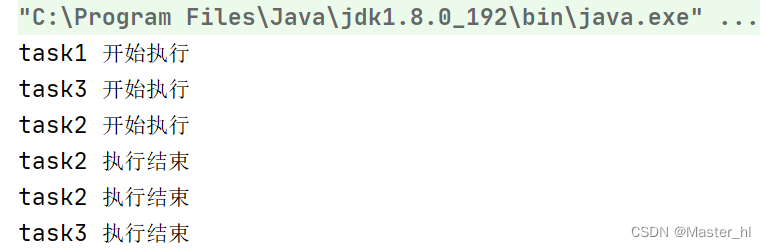
int ret1 = task1.get();
int ret2 = task1.get();
int ret3 = task1.get();
}执行结果 >>>
③ 使用 CountDownLatch 或 CyclicBarrier
这个问题,回答前两种方式其实已经够了,此处多介绍一个 CountDownLatch。
代码示例:
- 递归枚举出所有 HTML 文件
- 通过线程池解析 HTML 文件
- 解析完所有的 HTML 文件后再执行后续的业务逻辑
public void runByThread() throws InterruptedException {
ArrayList<File> files = new ArrayList<>();
enumFile(INPUT_PATH,files); // 递归枚举出所有 HTML 文件
ExecutorService executorService = Executors.newFixedThreadPool(4);
CountDownLatch latch = new CountDownLatch(files.size());
// 遍历文件,多线程解析文件
for(File f:files) {
executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println("开始解析: " + f.getAbsolutePath());
parseHTML(f); // 解析文件
latch.countDown(); // 调用一次这个方法表示一个线程已经执行完了
}
});
}
latch.await(); // 阻塞(死等) -> 直到所有的线程都调用了 countDown()
// 执行后续的业务逻辑
System.out.println("索引制作完毕!");
}那么上述三个步骤,4 个线程在执行解析文件的时候,很可能会存在这样一种情况:
这些文件都 submit 完了,但是还没有执行完,这是很有可能的。而想要执行后续的业务逻辑,那么就得保证这些文件全部被执行完了,所以此处 CountDownLatch 的作用就是为了保证这一点的
如何保证? 通过调用两个方法 :
- latch.await()
- latch.countDown()
第一个方法的作用是阻塞,它会一直进行死等,直到所有的线程都执行完了(全部都调用了 countDown() 方法),才结束阻塞。
第二个方法的作用是用来统计线程的执行情况,有一个线程执行完了,计数器就 + 1。