论文链接:https://arxiv.org/pdf/2304.03977.pdf
代码:https://github.com/tsb0601/EMP-SSL
其他学习链接:突破自监督学习效率极限!马毅、LeCun联合发布EMP-SSL:无需花哨trick,30个epoch即可实现SOTA
主要思想
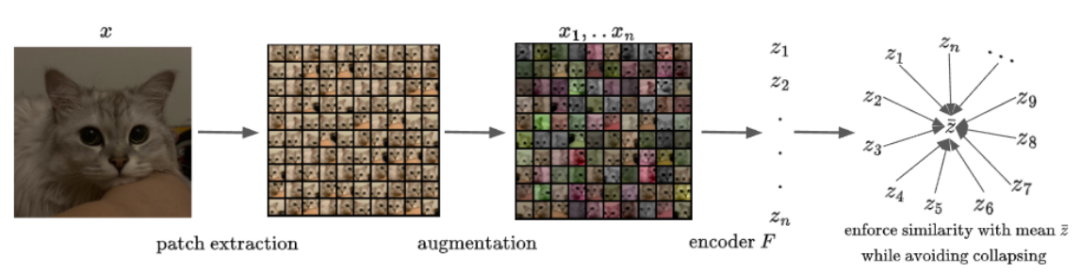
如图,一张图片裁剪成不同的 patch,对不同的 patch 做数据增强,分别输入 encoder,得到多个 embedding,对它们求均值,得到 作为这张图片的 embedding。最后,拉近每个 patch 的 embedding 和图片的 embedding(
)之间的余弦距离;再用 Total Coding Rate(TCR) 防止坍塌(即 encoder 对所有输入都输出相同的 embedding)

Total Coding Rate(TCR)
公式如下:
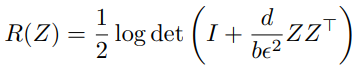
其中,det 表示求矩阵的行列式,d 是 feature vector 的 dimension,b 是 batch size
查了查该公式的含义:expand all features of Z as large as possible,即尽可能拉远矩阵中特征之间的距离。
源自 PPT 第 24 页:
https://s3.amazonaws.com/sf-web-assets-prod/wp-content/uploads/2021/06/15175515/Deep_Networks_from_First_Principles.pdf
至于为什么最大化该公式的值就可以拉远矩阵中特征之间的距离,这背后的数学原理真难啃啊 /(ㄒoㄒ)/~~
核心代码解读
数据处理
https://github.com/tsb0601/EMP-SSL/blob/main/dataset/aug.py#L116C1-L138C27
class ContrastiveLearningViewGenerator(object):
def __init__(self, num_patch = 4):
self.num_patch = num_patch
def __call__(self, x):
normalize = transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])
aug_transform = transforms.Compose([
transforms.RandomResizedCrop(32,scale=(0.25, 0.25), ratio=(1,1)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(0.4, 0.4, 0.4, 0.2)], p=0.8),
transforms.RandomGrayscale(p=0.2),
GBlur(p=0.1),
transforms.RandomApply([Solarization()], p=0.1),
transforms.ToTensor(),
normalize
])
augmented_x = [aug_transform(x) for i in range(self.num_patch)]
return augmented_x由此看出返回的 数据 为:长度为 num_patches 个 tensor 的列表。其中,每个 tensor 的 shape 为 (B, C, H, W)。
主函数
https://github.com/tsb0601/EMP-SSL/blob/main/main.py#L148C9-L162C63
for step, (data, label) in tqdm(enumerate(dataloader)):
net.zero_grad()
opt.zero_grad()
data = torch.cat(data, dim=0)
data = data.cuda()
z_proj = net(data)
z_list = z_proj.chunk(num_patches, dim=0)
z_avg = chunk_avg(z_proj, num_patches)
# Contractive Loss
loss_contract, _ = contractive_loss(z_list, z_avg)
loss_TCR = cal_TCR(z_proj, criterion, num_patches)这里要稍微注意一下几个变量的 shape:
- data 被 cat 完后:(num_patches * B,C,H,W)
- z_proj:(num_patches * B,C)
- z_list:(num_patches,B,C)
- z_avg:(B,C)
其中,chunk_avg 就是对来自同一张图片的不同 patch 的 embedding 求均值():
https://github.com/tsb0601/EMP-SSL/blob/main/main.py#L67
def chunk_avg(x,n_chunks=2,normalize=False):
x_list = x.chunk(n_chunks,dim=0)
x = torch.stack(x_list,dim=0)
if not normalize:
return x.mean(0)
else:
return F.normalize(x.mean(0),dim=1)loss
contractive_loss 就是计算每个 patch 的 embedding 和均值()的余弦距离:
https://github.com/tsb0601/EMP-SSL/blob/main/main.py#L76
class Similarity_Loss(nn.Module):
def __init__(self, ):
super().__init__()
pass
def forward(self, z_list, z_avg):
z_sim = 0
num_patch = len(z_list)
z_list = torch.stack(list(z_list), dim=0)
z_avg = z_list.mean(dim=0)
z_sim = 0
for i in range(num_patch):
z_sim += F.cosine_similarity(z_list[i], z_avg, dim=1).mean()
z_sim = z_sim/num_patch
z_sim_out = z_sim.clone().detach()
return -z_sim, z_sim_outTCR loss:最大化矩阵之间特征的距离,即拉远负样本(不是来自同一个样本的 patches)之间的距离
https://github.com/tsb0601/EMP-SSL/blob/main/main.py#L96
def cal_TCR(z, criterion, num_patches):
z_list = z.chunk(num_patches,dim=0)
loss = 0
for i in range(num_patches):
loss += criterion(z_list[i])
loss = loss/num_patches
return loss需要注意:函数输入的 z 是 z_proj,形状为(num_patches * B,C)。
所以,函数内部 z_list 的形状为(num_patches,B,C),即将数据分为了 num_patches 个组,每个组包含了来自不同图片里 patch 的 embedding。再分别对每个组求 TCR loss,最大化组内(不同图片的 patch)特征的距离。
所以,公式中的 指的是一组来自不同图片里 patch 的 embedding,形状为(B,C)。
每个组内求 TCR loss 的代码按照公式计算,如下:
https://github.com/tsb0601/EMP-SSL/blob/main/loss.py#L76
class TotalCodingRate(nn.Module):
def __init__(self, eps=0.01):
super(TotalCodingRate, self).__init__()
self.eps = eps
def compute_discrimn_loss(self, W):
"""Discriminative Loss."""
p, m = W.shape #[d, B]
I = torch.eye(p,device=W.device)
scalar = p / (m * self.eps)
logdet = torch.logdet(I + scalar * W.matmul(W.T))
return logdet / 2.
def forward(self,X):
return - self.compute_discrimn_loss(X.T)

![VSCODE[配置ssh免密远程登录]](https://img-blog.csdnimg.cn/e4cff4422f164e139e9d38aef7ed73ea.png)



![[HDLBits] Exams/m2014 q4a](https://img-blog.csdnimg.cn/img_convert/9ae35d2de0c7d4e4e49ccb3affdf36cc.png)