public static void main(String[] args) {
byte[] dest = new byte[2];
dest[0] = 0x15; //0001 0101
dest[1] = (byte) 0xfb;//1111 1011
System.out.println((dest[0] >> 4) & 0xff);//右移 应该是0000 0001 十进制结果显示1 结果也是1,正确
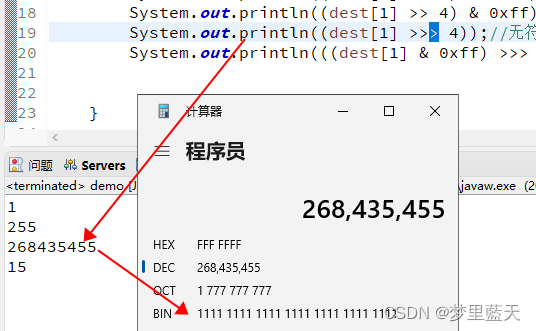
System.out.println((dest[1] >> 4) & 0xff);//右移 我们想要的是0000 1111 十进制结果显示15,但是结果是255,二进制1111 1111
System.out.println((dest[1] >>> 4) & 0xff);//无符号右移 我们想要的是0000 1111 十进制结果显示15,但是结果是255,二进制1111 1111
System.out.println(((dest[1] & 0xff) >>> 4) & 0xff);//无符号右移 我们想要的是0000 1111 十进制结果显示15,结果也是15 正确
}
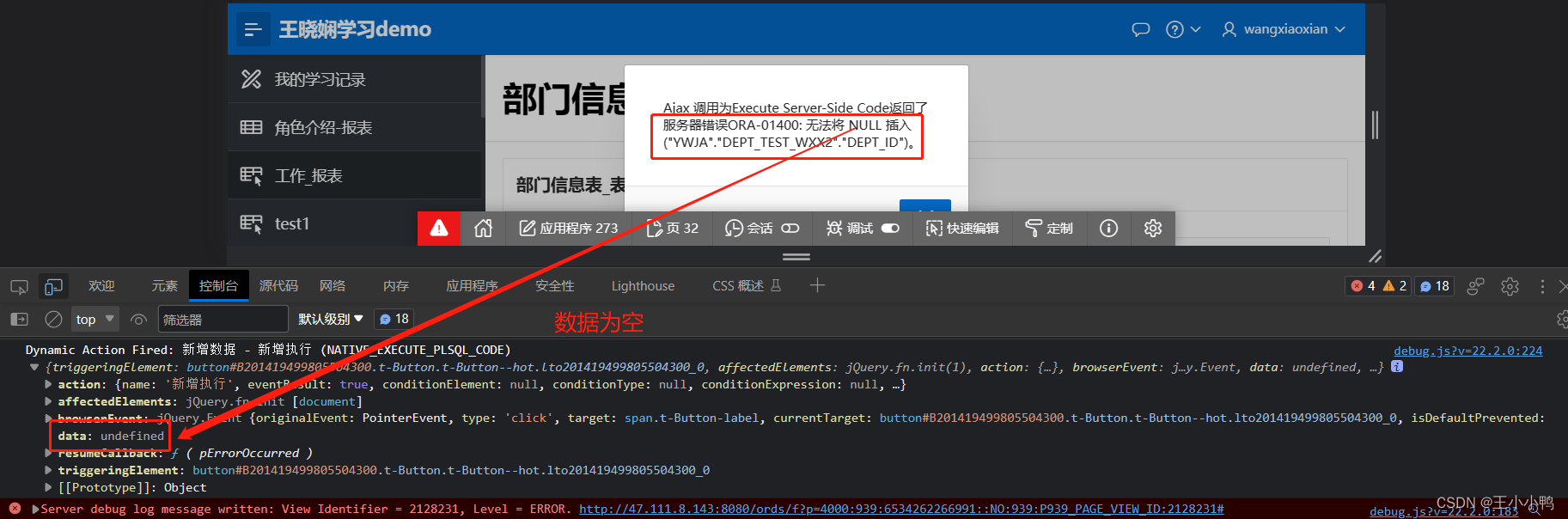
为什么右移与想要的结果不同,可以先看下《计算机组成与结构 - 数值的编码方式》,在Java,byte的表示的值为-2^7
到 2^7-1,所以超过127整数是其本身减与其相差最小的256的倍数,在这里 251-256 = -5,右移动指定的位数后,左边空出的位用原来的符号位填充,所有第二个输出是错误的。
为什么第三个输出的结果也是不正确的?
首先我们看下改文件编译后的字节码文件:
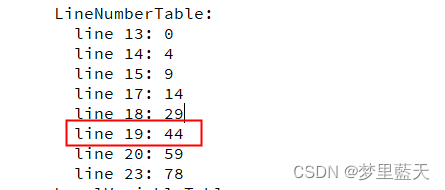
通过LineNumberTable对照可以看出,字节码文件的44-59之间是源文件19行的内容
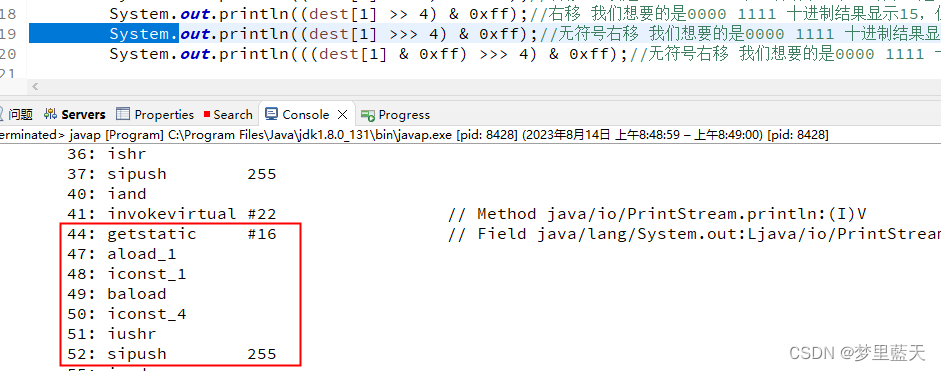
从48,50,51可以看出,指令的第一个字母都是i,而在字节码指令中,操作码助记符中都有特殊的字符来表明专门为哪种数据类型服务:i 代表对 int 类型的数据操作,l 代表 long,s 代表 short,b 代表 byte,c 代表 char,f 代表 float,d 代表 double,a 代表 reference。
在编译器编译时,都把要操作的类型转为了int类型,0xfb编译后二进制1111 1111 1111 1111 1111 1111 1111 1011,无符号位右移4位,变为 (0000) 1111 1111 1111 1111 1111 1111 1111,&上0xff,结果为1111 1111 十进制为255。
结论
有符号右移(>>):将二进制数向右移动指定的位数,左边空出的位用原来的符号位填充。例如,对于正数,右移后高位补0;对于负数,右移后低位补1。
无符号右移(>>>):将二进制数向右移动指定的位数,左边空出的位用0填充。无论原数是正数还是负数,右移后高位都补0。
对于byte类型的数据无符号位右移时,编译器会把byte类型强转为int类型,想要获得正确的结果在无符号位移前先&0xff