目录:
- Web自动化测试价值与体系
- 环境安装与使用
- 自动化用例录制
- 自动化测试用例结构分析
- web浏览器控制
- 常见控件定位方法
- 强制等待与隐式等待
- 常见控件交互方法
- 自动化测试定位策略
- 搜索功能自动化测试
- 用户端Web自动化测试
1.Web自动化测试价值与体系
功能测试场景:
UI 自动化测试场景:
什么时候可以做UI自动化测试?

- 业务流程不频繁改动
- UI 元素不频繁改动
- 需要频繁回归的场景
- 核心场景等
Web自动化测试相关技术:
- Selenium:支持多语言,行业内最火最主流
- Pytest/JUnit5:最好用最全面的单元测试框架
- Allure:测试报告
Web自动化测试学习路线

2.环境安装与使用
Selenium架构图:
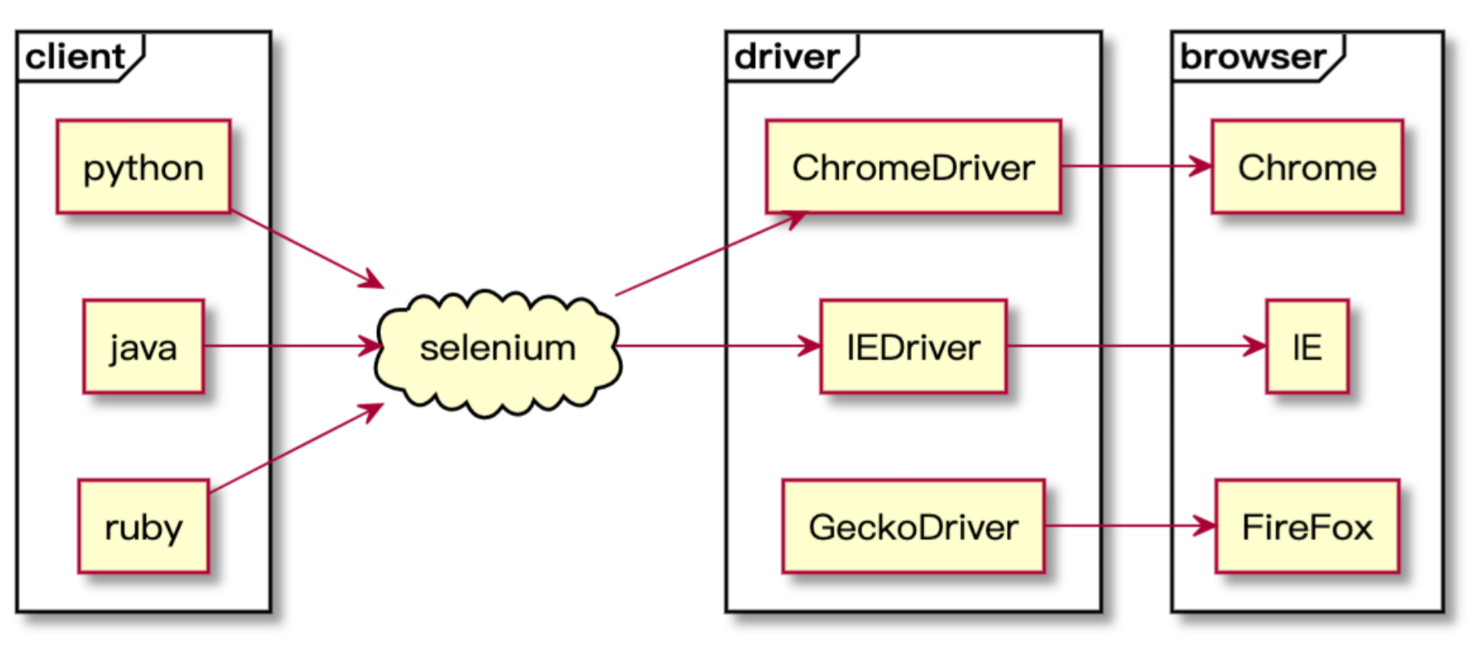
3.自动化用例录制
SeleniumIDE用例录制使用场景
- 刚开始入门UI自动化测试
- 团队代码基础较差
- 技术成长之后学习价值不高
SeleniumIDE的下载以及安装:
- 官网:https://www.selenium.dev/
- Chrome插件:https://chrome.google.com/webstore/detail/selenium-ide/mooikfkahbdckldjjndioackbalphokd
- Firefox插件:https://addons.mozilla.org/en-US/firefox/addon/selenium-ide/
- github release:https://github.com/SeleniumHQ/selenium-ide/releases
- 其它版本:https://addons.mozilla.org/en-GB/firefox/addon/selenium-ide/versions/ 注意:Chrome插件在国内无法下载,Firefox可以直接下载。
SeleniumIDE常用功能
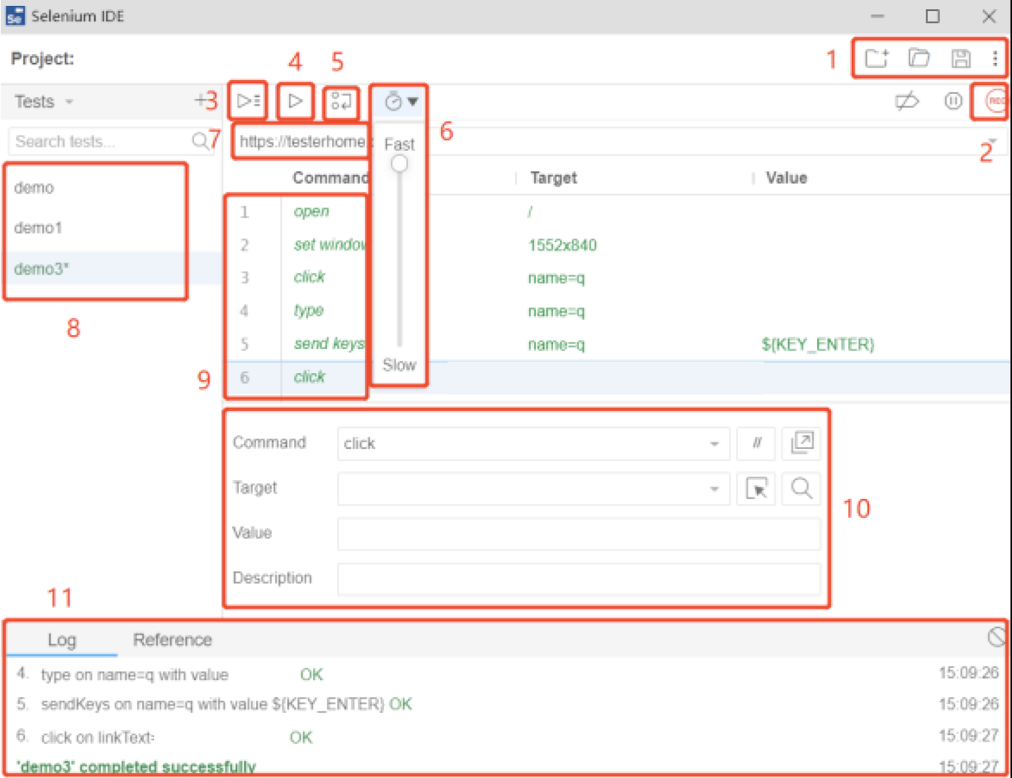
- 新建、保存、打开
- 开始和停止录制
- 运行8中的所有的实例
- 运行单个实例
- 调试模式
- 调整案例的运行速度
- 要录制的网址
- 实例列表
- 动作、目标、值
- 对单条命令的解释
- 运行日志
其他常用功能
- 用例管理
- 保存和回放
SeleniumIDE脚本导出
- Java
- Python
4.自动化测试用例结构分析
标准的用例结构
- 用例标题
- 前提条件
- 用例步骤
- 预期结果
- 实际结果
自动化测试用例结构:
| 用例标题 | 测试包、文件、类、方法名称 | 用例的唯一标识 |
| 前提条件 | setup、setup_class(Pytest); BeforeEach、BeforeAll(JUnit) | 测试用例前的准备动作,比如读取数据或者driver的初始化 |
| 用例步骤 | 测试方法内的代码逻辑 | 测试用例具体的步骤行为 |
| 预期结果 | assert 实际结果 = 预期结果 | 断言,印证用例是否执行成功 |
| 实际结果 | assert 实际结果 = 预期结果 | 断言,印证用例是否执行成功 |
| 后置动作 | teardown、teardown_class(Pytest); @AfterEach、@AfterAll(JUnit) | 脏数据清理、关闭driver进程 |
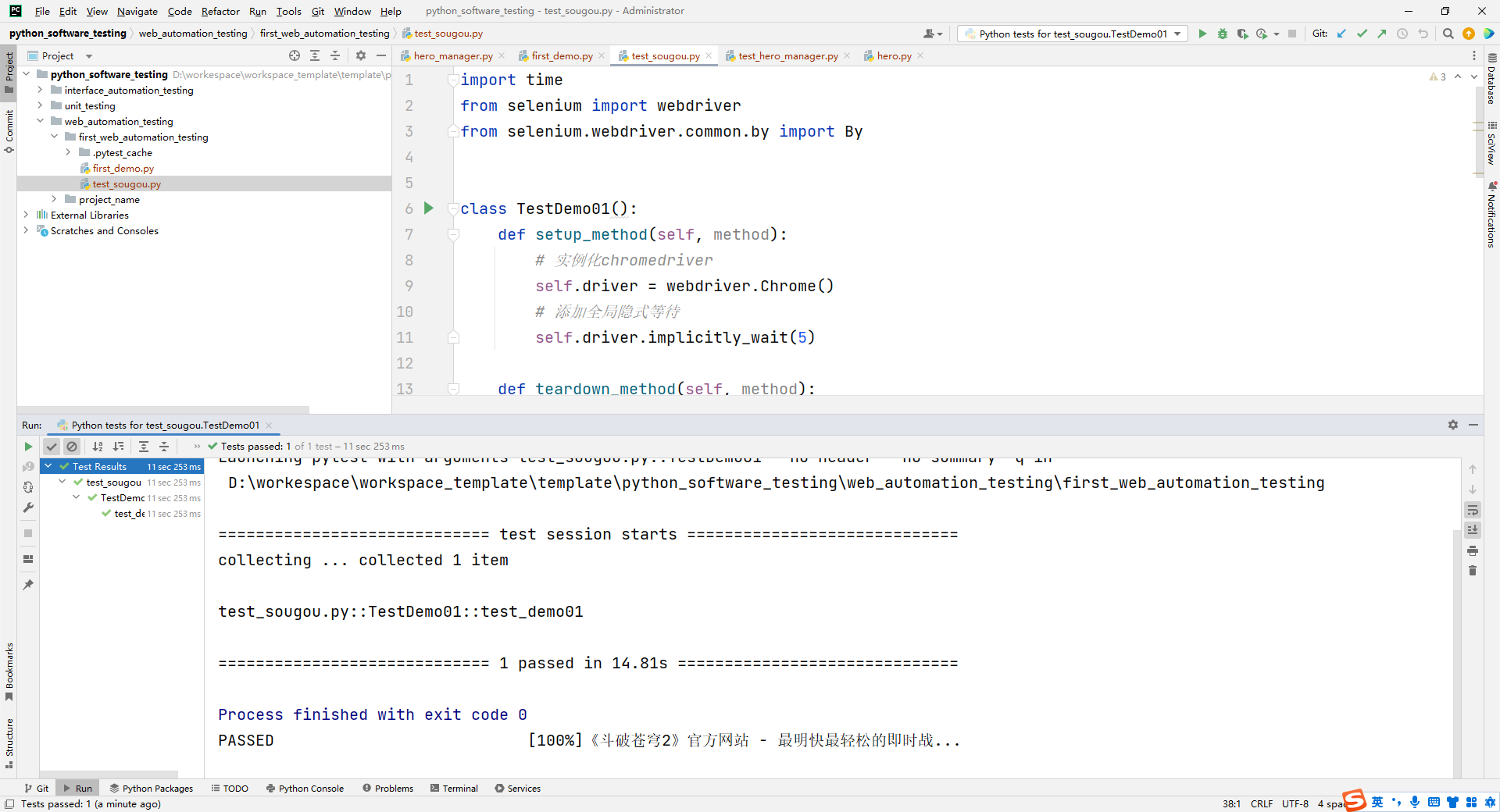
代码示例:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestDemo01():
def setup_method(self, method):
# 实例化chromedriver
self.driver = webdriver.Chrome()
# 添加全局隐式等待
self.driver.implicitly_wait(5)
def teardown_method(self, method):
# 关闭driver
self.driver.quit()
def test_demo01(self):
# 访问网站
self.driver.get("https://www.baidu.com/")
# 设置窗口
self.driver.set_window_size(1330, 718)
# 点击输入框
self.driver.find_element(By.ID, "kw").click()
# 输入框输入信息
self.driver.find_element(By.ID, "kw").send_keys("斗破苍穹")
# 点击搜索按钮
self.driver.find_element(By.ID, "su").click()
# 等待界面加载
time.sleep(5)
# 元素定位后获取文本信息
res = self.driver.find_element(By.XPATH, '//*[@id="1"]/div/div[1]/h3/a[1]').text
# 打印文本信息
print(res)
# 添加断言
assert "斗破苍穹" in res
# 查看界面展示
time.sleep(5)
运行结果:
5.web浏览器控制
| 操作 | 使用场景 | |
|---|---|---|
| get | 打开浏览器 | web自动化测试第一步 |
| refresh | 浏览器刷新 | 模拟浏览器刷新 |
| back | 浏览器退回 | 模拟退回步骤 |
| maximize_window | 最大化浏览器 | 模拟浏览器最大化 |
| minimize_window | 最小化浏览器 | 模拟浏览器最小化 |
代码示例:
from selenium import webdriver
import time
class TestBrowserControl:
def setup_method(self, method):
# 实例化chromedriver
self.driver = webdriver.Chrome()
# 添加全局隐式等待
self.driver.implicitly_wait(5)
def teardown_method(self, method):
# 关闭driver
self.driver.quit()
def test_open_web_page(self):
# 打开网站
self.driver.get('https://www.baidu.com/')
# 等待一秒
time.sleep(1)
def test_refresh_web_page(self):
# 打开网站
self.driver.get('https://www.baidu.com/')
# 等待一秒
time.sleep(1)
# 刷新网页
self.driver.refresh()
time.sleep(1)
def test_window_back(self):
# 打开网站
self.driver.get('https://www.baidu.com/')
# 等待2秒
time.sleep(2)
self.driver.get('https://www.sougou.com/')
# 等待2秒
time.sleep(2)
# 返回上一个界面
self.driver.back()
# 等待2秒
time.sleep(2)
def test_max_window(self):
# 打开网站
self.driver.get('https://www.baidu.com/')
# 等待一秒
time.sleep(1)
# 屏幕最大化
self.driver.maximize_window()
# 等待一秒
time.sleep(1)
def test_min_window(self):
# 打开网站
self.driver.get('https://www.baidu.com/')
# 等待一秒
time.sleep(1)
# 屏幕最小化
self.driver.minimize_window()
# 等待一秒
time.sleep(1)
浏览器操作总结
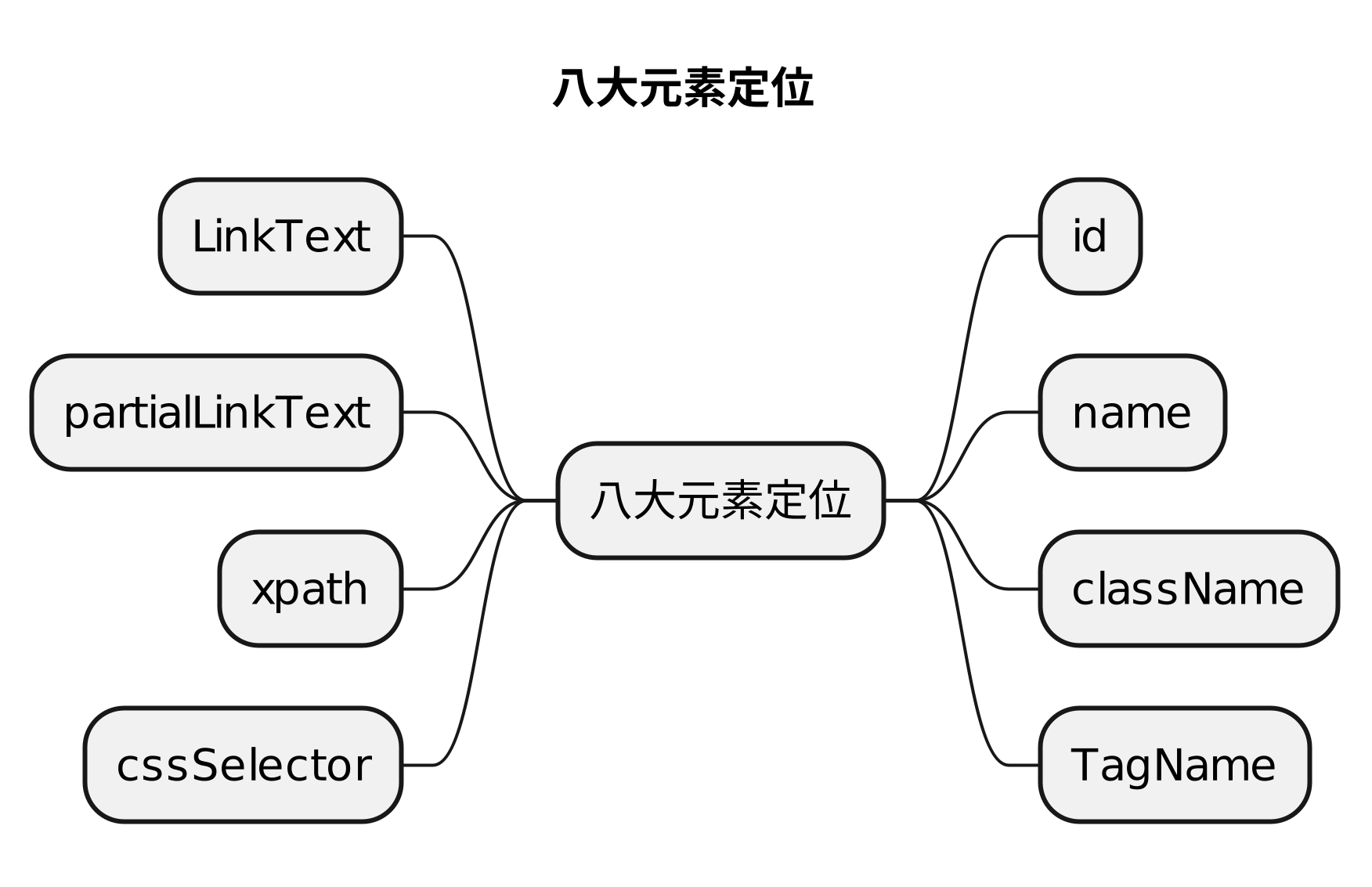
6.常见控件定位方法
| 方式 | 描述 |
|---|---|
| class name | class 属性对应的值 |
| css selector(重点) | css 表达式 |
| id(重点) | id 属性对应的值 |
| name(重点) | name 属性对应的值 |
| link text | 查找其可见文本与搜索值匹配的锚元素 |
| partial link text | 查找其可见文本包含搜索值的锚元素。如果多个元素匹配,则只会选择第一个元素。 |
| tag name | 标签名称 |
| xpath(重点) | xpath表达式 |
代码示例:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestElementLocation:
def setup_method(self, method):
# 实例化chromedriver
self.driver = webdriver.Chrome()
# 添加全局隐式等待
self.driver.implicitly_wait(5)
def teardown_method(self, method):
# 关闭driver
self.driver.quit()
# 通过id定位
def test_id(self):
# 打开网站
self.driver.get('https://www.baidu.com/')
# 等待一秒
time.sleep(1)
self.driver.find_element(By.ID, "s-usersetting-top").click()
# 等待两秒
time.sleep(2)
# name定位
def test_name(self):
# 打开网站
self.driver.get('https://www.baidu.com')
# 等待一秒
time.sleep(1)
self.driver.maximize_window()
time.sleep(1)
# 点击更多
self.driver.find_element(By.NAME, "tj_briicon").click()
# 等待两秒
time.sleep(2)
# css selector 定位
def test_css_selector(self):
# 打开网站
self.driver.get('https://www.baidu.com')
# 等待一秒
time.sleep(1)
self.driver.maximize_window()
time.sleep(1)
# 点击图片
self.driver.find_element(By.CSS_SELECTOR, "#s-top-left > a:nth-child(6)").click()
# 等待两秒
time.sleep(2)
# xpath定位
def test_xpath(self):
# 打开网站
self.driver.get('https://www.baidu.com')
# 等待一秒
time.sleep(1)
self.driver.maximize_window()
time.sleep(1)
# 点击图片
self.driver.find_element(By.XPATH, '//*[@id="s-top-left"]/a[6]').click()
# 等待两秒
time.sleep(2)
# link定位(1.一定是a标签 2.输入的元素为标签内的文本)
def test_link(self):
# 打开网站
self.driver.get('https://www.baidu.com')
# 等待一秒
time.sleep(1)
self.driver.maximize_window()
time.sleep(1)
# 点击图片
self.driver.find_element(By.LINK_TEXT, '图片').click()
# 等待两秒
time.sleep(2)
# class_name 定位
def test_class(self):
pass
# 使用tag_name定位元素
def test_tag_name(self):
pass
# 使用partial_link_text定位元素
def test_partial_link_text(self):
pass
元素定位总结
7.强制等待与隐式等待
为什么要添加等待?
- 避免页面未渲染完成后操作,导致的报错
代码示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestElementLocation:
def setup_method(self, method):
# 实例化chromedriver
self.driver = webdriver.Chrome()
# # 添加全局隐式等待
# self.driver.implicitly_wait(5)
def teardown_method(self, method):
# 关闭driver
self.driver.quit()
def test_wait_sleep(self):
self.driver.get("https://")
# 不加等待,可能会因为网速等原因产生报错
self.driver.find_element(By.XPATH, "//*[text()='个人中心']")直接等待
- 解决方案:在报错的元素操作之前添加等待
- 原理:强制等待,线程休眠一定时间
time.sleep(3)
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestElementLocation:
def setup_method(self, method):
# 实例化chromedriver
self.driver = webdriver.Chrome()
# # 添加全局隐式等待
# self.driver.implicitly_wait(5)
def teardown_method(self, method):
# 关闭driver
self.driver.quit()
def test_wait_sleep(self):
self.driver.get("https://")
# 不加等待,可能会因为网速等原因产生报错
self.driver.find_element(By.XPATH, "//*[text()='个人中心']")
def test_direct_wait(self):
self.driver.get("https://")
time.sleep(3)
# 不加等待,可能会因为网速等原因产生报错
self.driver.find_element(By.XPATH, "//*[text()='个人中心']")隐式等待
- 问题:难以确定元素加载的具体等待时间。
- 解决方案:针对于寻找元素的这个动作,使用隐式等待添加配置。
- 原理:设置一个等待时间,轮询查找(默认0.5秒)元素是否出现,如果没出现就抛出异常
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestElementLocation:
def setup_method(self, method):
# 实例化chromedriver
self.driver = webdriver.Chrome()
# # 添加全局隐式等待
# self.driver.implicitly_wait(5)
def teardown_method(self, method):
# 关闭driver
self.driver.quit()
def test_wait_sleep(self):
self.driver.get("https://")
# 不加等待,可能会因为网速等原因产生报错
self.driver.find_element(By.XPATH, "//*[text()='个人中心']")
def test_direct_wait(self):
self.driver.get("https://")
time.sleep(3)
# 不加等待,可能会因为网速等原因产生报错
self.driver.find_element(By.XPATH, "//*[text()='个人中心']")
def test_implicit_wait(self):
self.driver.get("https://")
self.driver.implicitly_wait(5)
# 不加等待,可能会因为网速等原因产生报错
self.driver.find_element(By.XPATH, "//*[text()='个人中心']")隐式等待无法解决的问题
- 元素可以找到,使用点击等操作,出现报错
- 原因:
- 页面元素加载是异步加载过程,通常html会先加载完成,js、css其后
- 元素存在与否是由HTML决定,元素的交互是由css或者js决定
- 隐式等待只关注元素能不能找到,不关注元素能否点击或者进行其他的交互
- 解决方案:使用显式等待
显式等待基本使用(初级):
- 示例:
WebDriverWait(driver实例, 最长等待时间, 轮询时间).until(结束条件) - 原理:在最长等待时间内,轮询,是否满足结束条件
- 注意:在初级时期,先关注使用
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
class TestElementLocation:
def setup_method(self, method):
# 实例化chromedriver
self.driver = webdriver.Chrome()
# # 添加全局隐式等待
# self.driver.implicitly_wait(5)
def teardown_method(self, method):
# 关闭driver
self.driver.quit()
def test_wait_sleep(self):
self.driver.get("https://")
# 不加等待,可能会因为网速等原因产生报错
self.driver.find_element(By.XPATH, "//*[text()='个人中心']")
def test_direct_wait(self):
self.driver.get("https://")
time.sleep(3)
# 不加等待,可能会因为网速等原因产生报错
self.driver.find_element(By.XPATH, "//*[text()='个人中心']")
def test_implicit_wait(self):
self.driver.get("https://")
self.driver.implicitly_wait(5)
# 不加等待,可能会因为网速等原因产生报错
self.driver.find_element(By.XPATH, "//*[text()='个人中心']")
def test_explicit_wait(self):
self.driver = webdriver.Chrome()
self.driver.get("https://")
WebDriverWait(self.driver, 10).until(expected_conditions.element_to_be_clickable((By.CSS_SELECTOR, '#success_btn')))
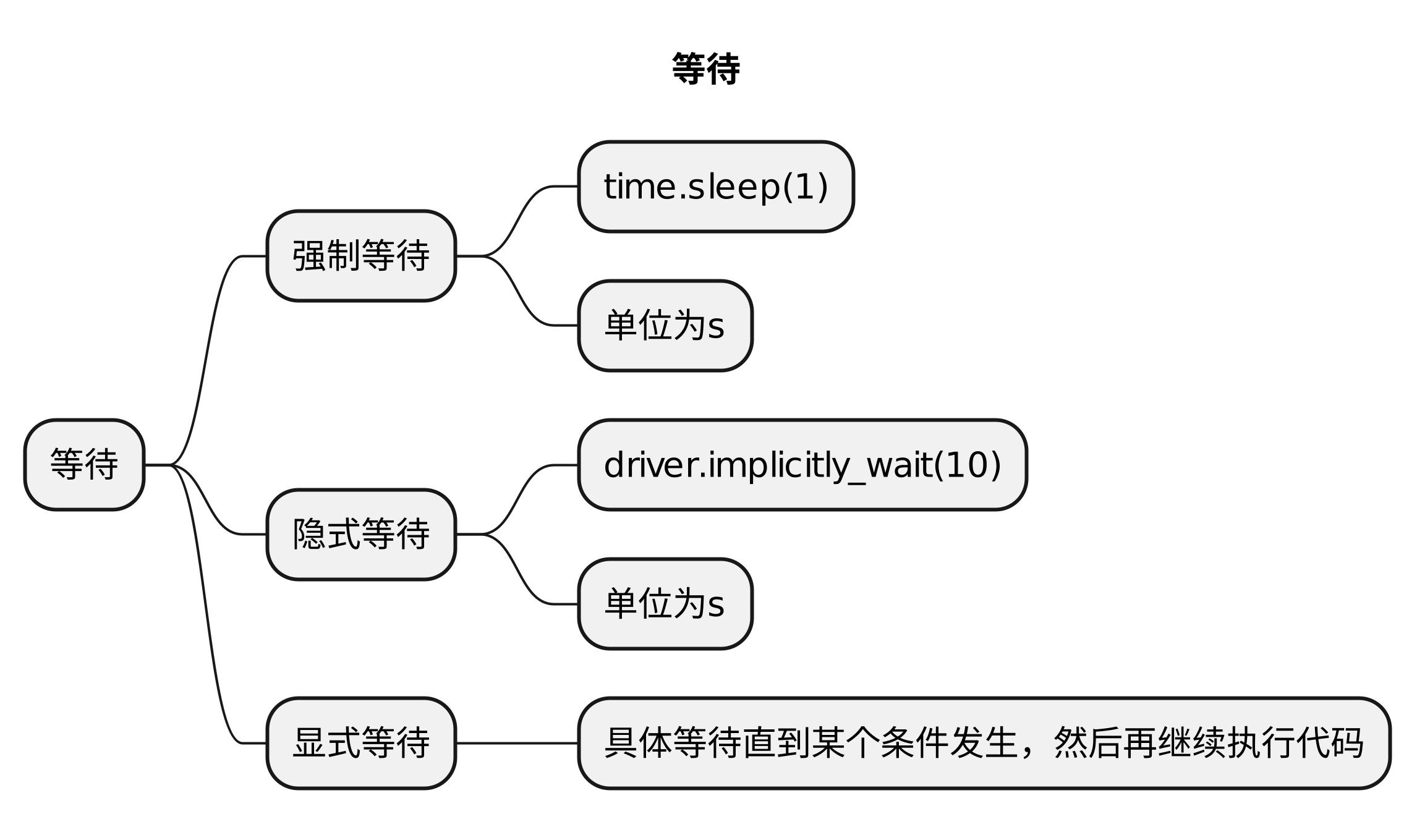
self.driver.find_element(By.CSS_SELECTOR, "#success_btn").click()总结
| 类型 | 使用方式 | 原理 | 适用场景 |
|---|---|---|---|
| 直接等待 | time.sleep(等待时间)) | 强制线程等待 | 调试代码,临时性添加 |
| 隐式等待 | driver.implicitly_wait(等待时间) | 在时间范围内,轮询查找元素 | 解决找不到元素问题,无法解决交互问题 |
| 显式等待 | WebDriverWait(driver实例, 最长等待时间, 轮询时间).until(结束条件) | 设定特定的等待条件,轮询操作 | 解决特定条件下的等待问题,比如点击等交互性行为 |
8.常见控件交互方法
点击,输入,清空
-
点击百度搜索框
-
输入”三国杀,启动!”
-
清空搜索框中信息
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestControl():
def setup_method(self, method):
# 实例化chromedriver
self.driver = webdriver.Chrome()
# 添加全局隐式等待
self.driver.implicitly_wait(5)
def teardown_method(self, method):
# 关闭driver
self.driver.quit()
def test_click_send_clear(self):
self.driver.get('https://www.baidu.com')
# 点击百度搜索框
self.driver.find_element(By.ID, "kw").click()
# 输入"三国杀,启动!"
self.driver.find_element(By.ID, "kw").send_keys("三国杀,启动!")
time.sleep(2)
# 清空搜索框中信息
self.driver.find_element(By.ID, "kw").clear()
time.sleep(2)
获取元素属性信息
- 原因:
- 定位到元素后,获取元素的文本信息,属性信息等
- 目的:
- 根据这些信息进行断言或者调试
获取元素属性信息的方法
- 获取元素文本
- 获取元素的属性(html的属性值)

代码示例:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestControl():
def setup_method(self, method):
# 实例化chromedriver
self.driver = webdriver.Chrome()
# 添加全局隐式等待
self.driver.implicitly_wait(5)
def teardown_method(self, method):
# 关闭driver
self.driver.quit()
def test_click_send_clear(self):
self.driver.get('https://www.baidu.com')
# 点击百度搜索框
self.driver.find_element(By.ID, "kw").click()
# 输入"三国杀,启动!"
self.driver.find_element(By.ID, "kw").send_keys("三国杀,启动!")
time.sleep(2)
# 清空搜索框中信息
self.driver.find_element(By.ID, "kw").clear()
time.sleep(2)
def test_get_element_attribute(self):
self.driver.get('https://')
# ** 元素的文本获取
result = self.driver.find_element(By.ID, 'locate_id').text
print(result)
# # ** 元素的标签获取
result = self.driver.find_element(By.ID, 'locate_id').tag_name
print(result)
# # ** 元素的属性获取
result = self.driver.find_element(By.ID, 'locate_id').get_attribute('name')
print(result)
result = self.driver.find_element(By.ID, 'locate_id').get_attribute('class')
print(result)
result = self.driver.find_element(By.ID, 'locate_id').get_attribute('style')
print(result)
result = self.driver.find_element(By.ID, 'locate_id').get_attribute('id')
print(result)
9.自动化测试定位策略
- 不知道应该使用哪种定位方式?
- 元素定位不到无法解决?
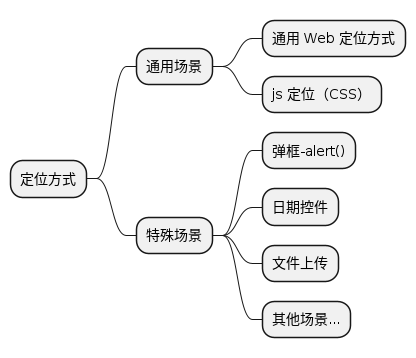
通用 Web 定位方式
| 定位策略 | 描述 |
|---|---|
| class name | 通过 class 属性定位元素 |
| css selector | 通过匹配 css selector 定位元素 |
| id | 通过 id 属性匹配元素 |
| name | 通过 name 属性定位元素 |
| link text | 通过 <a>text</a> 标签中间的 text 文本定位元素 |
| partial link text | 通过 <a>text</a> 标签中间的 text 文本的部分内容定位元素 |
| tag name | 通过 tag 名称定位元素 |
| xpath | 通过 xpath 表达式匹配元素 |
选择定位器通用原则
- 与研发约定的属性优先(class属性:
[name='locate']) - 身份属性 id,name(web 定位)
- 复杂场景使用组合定位:
- xpath,css
- 属性动态变化(id,text)
- 重复元素属性(id,text,class)
- 父子定位(子定位父)
- js定位
Web 弹框定位
- 场景
- web 页面 alert 弹框
- 解决:
- web 需要使用
driver.switchTo().alert()处理
- web 需要使用
下拉框/日期控件定位
-
场景:
<input>标签组合的下拉框无法定位<input>标签组合的日期控件无法定位
-
解决:
- 面对这些元素,我们可以引入 JS 注入技术来解决问题。
文件上传定位
- 场景:
- input 标签文件上传
- 解决:
- input 标签直接使用 send_keys()方法
10.搜索功能自动化测试
测试用例:
| 用例标题 | 前提条件 | 用例步骤 | 预期结果 | 实际结果 |
|---|---|---|---|---|
| 搜索功能 | 进入论坛首页 | 1. 点击搜索按钮 2. 输入搜索关键词 3. 点击搜索按钮 | 1. 搜索成功 2. 搜索结果列表包含关键字 |
代码示例:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestForum():
def setup_method(self, method):
# 实例化chromedriver
self.driver = webdriver.Chrome()
# 添加全局隐式等待
self.driver.implicitly_wait(5)
def teardown_method(self, method):
# 关闭driver
self.driver.quit()
# 动态元素的定位
def test_dynamic_id(self):
self.driver.get('https://')
self.driver.find_element(By.CSS_SELECTOR, "[placeholder='搜索']").send_keys("appium")
self.driver.find_element(By.CSS_SELECTOR, '.search-cta').click()
time.sleep(2)
web_element = self.driver.find_element(By.CSS_SELECTOR, ".topic-title")
print(web_element.text)
assert "appium" in web_element.text.lower()
例题:
1.以下关于css选择器语法说明正确的是
选项A:A:并集使用逗号:, 【正确答案】
选项B:B:并集使用空格:
选项C:C:并集使用大于号:>
选项D:D:并集使用加号:+
正确答案: 选项A:A:并集使用逗号:,
逗号表示并集,空格是子孙,大于号是父子,加号是相邻兄弟
2.下面关于selenium 说法,错误的是
选项A:A:selenium 根据网页元素的属性来定位元素
选项B:B:支持桌面应用软件的自动化测试 【正确答案】
选项C:C:支持移动端网页应用的自动化测试
选项D:D:支持web端页面的UI自动化测试
正确答案: 选项B:B:支持桌面应用软件的自动化测试
selenium 根据网页元素的属性来定位元素,支持移动端网页应用的自动化测试,支持web端页面的UI自动化测试不支持桌面应用软件的自动化测试
3.Selenium定位中link定位适用于哪个标签
选项A:A:<div>标签
选项B:B:<span>标签
选项C:C:<a>标签 【正确答案】
选项D:D:<input>标签
正确答案: 选项C:C:<a>标签
link定位只针对于<a>标签,其他标签均无法使用
4.关于selenium 下面说法正确的是
选项A:A:selenium 对web页面有良好的支持 【正确答案】
选项B:B:测试 Chrome/Firefox 浏览器,可以使用任意版本的 webdriver
选项C:C:只有windows和mac可以安装selenium
选项D:D:selenium 只支持 java 和 python 语言
正确答案: 选项A:A:selenium 对web页面有良好的支持
1、selenium 安装方式 pip install selenium,
2、测试浏览器需要下载对应浏览器版本的webdriver,
3、selenium 支持多平台windows,mac,linux,
4、selenium 支持多语言java,python, ruby等
5.下面关于动态元素说法不正确的是
选项A:A:元素的属性会动态变化
选项B:B:动态元素可以使用相对定位进行定位
选项C:C:动态元素可以使用xpath 的轴定位方式进行元素定位
选项D:D:动态元素必须使用绝对定位 【正确答案】
正确答案: 选项D:D:动态元素必须使用绝对定位
动态元素是元素的属性会动态变化,可以通过遍历的方式找到对应的的元素,动态元素可以使用xpath 的轴定位方式进行元素定位,动态元素不必须使用绝对定位,可以使用相对位置定位
6.web自动化中,通过下面哪种方法可以获取元素的属性信息
选项A:A:java语法:getAttribute('属性');python语法:get_attribute('属性') 【正确答案】
选项B:B:java语法:getElement('属性');python语法:get_element('属性')
选项C:C:java语法:getAttributes('属性');python语法:get_attributes('属性')
选项D:D:java语法:getElements('属性');python语法:get_elements('属性')
正确答案: 选项A:A:java语法:getAttribute('属性');python语法:get_attribute('属性')
java语法:getAttribute('属性');python语法:get_attribute('属性')可以获取元素属性信息,其他均无法拿到
7.xpath语法中,通过下标获取最后一个元素正确的是
选项A:A:[last()] 【正确答案】
选项B:B:[-1]
选项C:C:[first()]
选项D:D:[last]
正确答案: 选项A:A:[last()]
last()可以获取最后一个元素,下标里只能是正序,无法通过倒序-1获取
8.判断面上的元素是否成功展示,下面错误的说法
选项A:A:当未找到元素时,添加捕获异常的代码块
选项B:B:使用elements 获取一组元素,判断元素组的长度
选项C:C:使用显式等待来判断元素是否展示
选项D:D:使用隐式等待来判断元素是否展示 【正确答案】
正确答案: 选项D:D:使用隐式等待来判断元素是否展示
使用隐式等待无法准确的判断元素是否展示
9.如何定位页面上动态加载的元素,下面解决方法正确的是
选项A:A:使用查找元素的方法直接可以找到
选项B:B:触发动态事件,然后使用查找元素的方法
选项C:C:使用隐式等待,然后使用查找元素的方法
选项D:D:触发动态事件,同时启动隐式等待,然后使用查找元素的方法 【正确答案】
正确答案: 选项D:D:触发动态事件,同时启动隐式等待,然后使用查找元素的方法
定位页面上动态加载的元素,需要在触发动态事件,同时启动隐式等待,然后使用查找元素的方法
10.web自动化中,高级控件交互ActionChains模拟回车的关键字是?
选项A:A:SHIFT
选项B:B:ENTER 【正确答案】
选项C:C:CONTROL
选项D:D:ALT
正确答案: 选项B:B:ENTER
键盘中ENTER为回车键,所以ActionChains模拟回车就使用ENTER关键字
11.关于xpath定位元素说法正确的是
选项A:A:可以通过子元素定位父元素 【正确答案】
选项B:B:不可以通过父元素定位子元素
选项C:C:`.` 代表父结点
选项D:D:`*`代表父结点
正确答案: 选项A:A:可以通过子元素定位父元素
xpath可以通过子元素定位到父元素
12.web自动化过程中,frame可以通过什么来定位然后进行切换
选项A:A:index下标定位 【正确答案】
选项B:B:id定位(id属性存在) 【正确答案】
选项C:C:name定位(name属性存在) 【正确答案】
选项D:D:css或xpath定位 【正确答案】
正确答案: 选项A:A:index下标定位,选项B:B:id定位(id属性存在),选项C:C:name定位(name属性存在),选项D:D:css或xpath定位
多frame切换时,可以使用下标,id,name和WebElement对象来定位
13.下面关于 selenium 说法正确的是:
选项A:A:selenium 支持chrome,firefox等多浏览器 【正确答案】
选项B:B:selenium 支持多平台 【正确答案】
选项C:C:selenium 可以作为浏览器兼容性测试的工具 【正确答案】
选项D:D:selenium 支持分布式 【正确答案】
正确答案: 选项A:A:selenium 支持chrome,firefox等多浏览器,选项B:B:selenium 支持多平台,选项C:C:selenium 可以作为浏览器兼容性测试的工具,选项D:D:selenium 支持分布式selenium 多浏览器处理,支持chrome,firefox等多浏览器,支持多平台,可以作为浏览器兼容性测试的工具,selenium 支持分布式
14.适合做UI自动化测试的场景有哪些
选项A:A:业务流程不频繁改动 【正确答案】
选项B:B:UI 元素不频繁改动 【正确答案】
选项C:C:需要频繁回归的场景 【正确答案】
选项D:D:核心用例场景 【正确答案】
正确答案: 选项A:A:业务流程不频繁改动,选项B:B:UI 元素不频繁改动,选项C:C:需要频繁回归的场景,选项D:D:核心用例场景
ABCD均符合做UI自动化测试的场景
15.下面关于Selenium 定位正确的是
选项A:A:通过css 定位可以通过父元素找子元素 【正确答案】
选项B:B:通过css 定位可以通过子元素找父元素
选项C:C:通过xpath 定位可以通过父元素找子元素 【正确答案】
选项D:D:通过xpath 定位可以通过子元素找父元素 【正确答案】
正确答案: 选项D:D:通过xpath 定位可以通过子元素找父元素,选项A:A:通过css 定位可以通过父元素找子元素,选项C:C:通过xpath 定位可以通过父元素找子元素
通过xpath 定位可以通过父元素找子元素 通过xpath 定位可以通过子元素找父元素 通过css 定位可以通过父元素找子元素
16.用例在运行过程中经常会出现不稳定的情况,比如这次可以通过,下次就执行失败,如何去提升用例的稳定性?
选项A:A:多加强制等待
选项B:B:用例中使用隐式等待或显式等待 【正确答案】
选项C:C:不使用绝对定位 【正确答案】
选项D:D:以上都不正确得分:
正确答案: 选项B:B:用例中使用隐式等待或显式等待,选项C:C:不使用绝对定位
隐式等待,用例在运行过程中经常会出现不稳定的情况,比如这次可以通过,下次就执行失败,可以在创建完driver 之后设置 隐式等待,隐式等待是全局生效的。每次查找元素的时候都会动态的找到这个元素。使用相对定位可以提升用例稳定性
17.使用 css selector 定位时,当父标签中有很多相同的子标签时,通过索引找到所需要定位的元素,下面说法错误的是
选项A:A:父标签[父标签属性名=父标签属性值]>子标签:nth-child(索引序号)
选项B:B:父标签[父标签属性名=父标签属性值]>子标签:nth-child[索引序号] 【正确答案】
选项C:C:索引号从1开始
选项D:D:索引号从0开始 【正确答案】
正确答案: 选项B:B:父标签[父标签属性名=父标签属性值]>子标签:nth-child[索引序号],选项D:D:索引号从0开始表达式写法:父标签[父标签属性名=父标签属性值]>子标签:nth-child(索引序号) 索引号从1开始
18.webdriver 提供哪些常见类型的驱动程序
选项A:A:FireFoxDriver(geckodriver) 【正确答案】
选项B:B:InternetExploer Driver 【正确答案】
选项C:C:ChromeDriver 【正确答案】
选项D:D:Safari Driver 【正确答案】得分:
正确答案: 选项A:A:FireFoxDriver(geckodriver),选项B:B:InternetExploer Driver,选项C:C:ChromeDriver,选项D:D:Safari Driver
webdriver 提供的常见的驱动程序 有FireFoxDriver(geckodriver), InternetExploer Driver. ChromeDriver. Safari Driver等
19.selenium 可以模拟的操作,下面说法正确的
选项A:A:点击,输入操作 【正确答案】
选项B:B:滑动操作 【正确答案】
选项C:C:拖拽操作 【正确答案】
选项D:D:页面滚动操作 【正确答案】
正确答案: 选项D:D:页面滚动操作,选项A:A:点击,输入操作,选项B:B:滑动操作,选项C:C:拖拽操作元素操作,selenium 不可以模拟向页面发送鼠标滚轮操作
20.关于 selenium 组件下面说法正确的是
选项A:A:selenium 包括三大组件 【正确答案】
选项B:B:selenium IDE 用于录制回放脚本 【正确答案】
选项C:C:selenium Grid 实现分布并发执行用例 【正确答案】
选项D:D:selenium webdriver 负责自动化测试 【正确答案】
正确答案: 选项A:A:selenium 包括三大组件,选项B:B:selenium IDE 用于录制回放脚本,选项C:C:selenium Grid 实现分布并发执行用例,选项D:D:selenium webdriver 负责自动化测试selenium 包括三大组件- selenium IDE 用于录制回放脚本- selenium Grid 实现分布并发执行用例- selenium webdriver 负责自动化测试
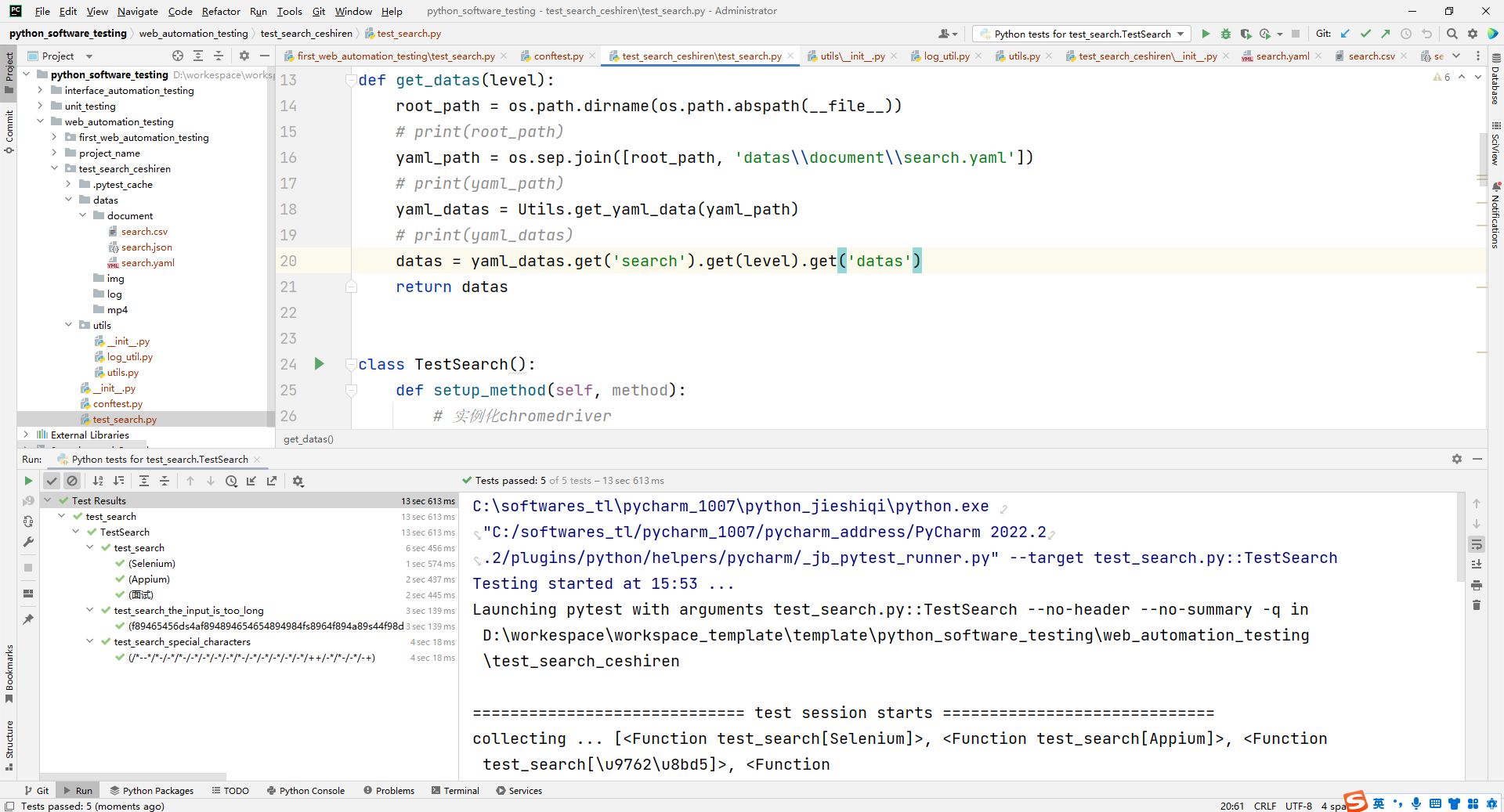
11.用户端Web自动化测试
需求:
- 要求实现搜索功能的Web自动化测试。
- Selenium 常用操作与用例编写。
- 使用隐式等待优化代码。
- 考虑特殊场景的验证。
- 输入内容过长。
- 特殊字符。
- 其他。
- 使用参数化优化代码。
场景描述
-
打开测试人论坛。
-
跳转到高级搜索页面
-
搜索输入框输入搜索关键字。关键字清单如下:
Selenium Appium 面试 -
打印搜索结果的第一个标题。
-
断言:第一个标题是否包含关键字。
代码示例:
test_search.py
import os
import time
import pytest
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from web_automation_testing.test_search_ceshiren.utils.utils import Utils
def get_datas(level):
root_path = os.path.dirname(os.path.abspath(__file__))
# print(root_path)
yaml_path = os.sep.join([root_path, 'datas\\document\\search.yaml'])
# print(yaml_path)
yaml_datas = Utils.get_yaml_data(yaml_path)
# print(yaml_datas)
datas = yaml_datas.get('search').get(level).get('datas')
return datas
class TestSearch():
def setup_method(self, method):
# 实例化chromedriver
self.driver = webdriver.Chrome()
# 添加全局隐式等待
self.driver.implicitly_wait(5)
def teardown_method(self, method):
# 关闭driver
self.driver.quit()
@pytest.mark.parametrize('param', get_datas("P0"))
def test_search(self, param):
self.driver.get('https://ceshiren.com/search')
input_field = self.driver.find_element(By.CSS_SELECTOR, "[placeholder='搜索']")
input_field.send_keys(param)
WebDriverWait(self.driver, 10).until(
expected_conditions.element_to_be_clickable((By.CSS_SELECTOR, '.search-cta')))
search_button = self.driver.find_element(By.CSS_SELECTOR, '.search-cta')
search_button.click()
title_first = self.driver.find_element(By.CSS_SELECTOR, '.topic-title')
print(title_first.text)
assert param.lower() in title_first.text.lower()
@pytest.mark.parametrize('param', get_datas("P1"))
def test_search_the_input_is_too_long(self, param):
self.driver.get('https://ceshiren.com/search')
input_field = self.driver.find_element(By.CSS_SELECTOR, "[placeholder='搜索']")
input_field.send_keys(param)
WebDriverWait(self.driver, 10).until(
expected_conditions.element_to_be_clickable((By.CSS_SELECTOR, '.search-cta')))
search_button = self.driver.find_element(By.CSS_SELECTOR, '.search-cta')
search_button.click()
time.sleep(2)
title_first = self.driver.find_element(By.CSS_SELECTOR, '.no-results-suggestion')
print(title_first.text)
assert "找不到您要找的内容?" in title_first.text
@pytest.mark.parametrize('param', get_datas("P2"))
def test_search_special_characters(self, param):
self.driver.get('https://ceshiren.com/search')
input_field = self.driver.find_element(By.CSS_SELECTOR, "[placeholder='搜索']")
input_field.send_keys(param)
WebDriverWait(self.driver, 10).until(
expected_conditions.element_to_be_clickable((By.CSS_SELECTOR, '.search-cta')))
search_button = self.driver.find_element(By.CSS_SELECTOR, '.search-cta')
search_button.click()
time.sleep(2)
title_first = self.driver.find_element(By.CSS_SELECTOR, '.no-results-suggestion')
print(title_first.text)
assert "找不到您要找的内容?" in title_first.text
conftest.py
def pytest_collection_modifyitems(session, config, items: list):
print(items)
for item in items:
item.name = item.name.encode('utf-8').decode('unicode-escape')
item._nodeid = item.nodeid.encode('utf-8').decode('unicode-escape')utils.py
import yaml
class Utils:
@classmethod
def get_yaml_data(cls, yaml_path):
'''
读取 yaml 文件数据
:param yaml_path: yaml 文件路径
:return: 读取到的数据
'''
with open(yaml_path, encoding="utf-8") as f:
datas = yaml.safe_load(f)
return datas
search.yaml
search:
P0:
datas:
- 'Selenium'
- 'Appium'
- '面试'
P1:
datas:
- 'f89465456ds4af894894654654894984fs8964f894a89s44f98d6sa4f84dsa98f4d9sa4fdsa4f5d6sa4f98d4f6a5s4df9684dsad89f4f4ds56f456sadf465as4df564asf65ds4af654dsa65f'
P2:
datas:
- '/*--*/*-/-*/*-/-*/-*/-*/-*/*-/-*/-*/-*/-*/-*/++/-*/*-/-*/-+'项目结构:
运行结果: