文章目录
- Informer介绍
- 1. Transformer存在的问题
- 2. Informer研究背景
- 3. Informer 整体架构
- 3.1 ProbSparse Self-attention
- 3.2 Self-attention Distilling
- 3.3 Generative Style Decoder
- 4. Informer的实验性能
- 5. 相关资料
Informer介绍
1. Transformer存在的问题
Informer实质是在Transformer的基础上进行改进,通过修改transformer的结构,提高transformer的速度。那么Transformer有什么样的缺点:
(1)self-attention的平方复杂度。self-attention的时间和空间复杂度是O(L^2),L为序列长度。
(2)对长输入进行堆叠(stack)时的内存瓶颈。多个encoder-decoder堆叠起来就会形成复杂的空间复杂度,这会限制模型接受较长的序列输入。
(3)预测长输出时速度骤降。对于Tansformer的输出,使用的是step-by-step推理得像RNN模型一样慢,并且动态解码还存在错误传递的问题。
2. Informer研究背景
论文的研究背景为:长序列预测问题。这些问题会出现在哪些地方呢:
● 股票预测(数据、规则都在变,模型都是无法预测的)
● 机器人动作的预测
● 人体行为识别(视频前后帧的关系)
● 气温的预测、疫情下的确诊人数
● 流水线每一时刻的材料消耗,预测下一时刻原材料需要多少…
那么以上需要时间线来进行实现的,无疑会想到使用Transformer来解决这些问题,Transformer的最大特点就是利用了attention进行时序信息传递。每次进行一次信息传递,我们需要执行两次矩阵乘积,也就是QKV的计算。并且我们需要思考一下,我们每次所执行的attention计算所保留下来的值是否是真的有效的吗?我们有没有必要去计算这么多attention?
那么对于现在的时间预测可以大致分为下面三种:
● 短序列预测
● 趋势预测
● 精准长序列预测

很多算法都是基于短序列进行预测的,先得知前一部分的数据,之后去预测短时间的情况。想要预测一个长序列,就不可以使用短预测,预测未来半年or一年,很难预测很准。长序列其实像是滑动窗口,不断地往后滑动,一步一步走,但是越滑越后的时候,他一直在使用预测好的值进行预测,长时间的序列预测是有难度的。
那么有哪些时间序列的经典算法:
● Prophnet:很实用的工具包,很适合预测趋势,但算的不精准。
● Arima:短序列预测还算精准,但是趋势预测不准。多标签。
以上两种一旦涉及到了长序列,都不可以使用。
● Informer中将主要致力于长序列问题的解决
可能在这里大家也会想到LSTM:但是这个模型在长序列预测中,如果序列越长,那速度肯定越慢,效果也越差。这个模型使用的为串行结构,效率很低,也会基于前面的特征来预测下一个特征,其损失函数的值也会越来越大。
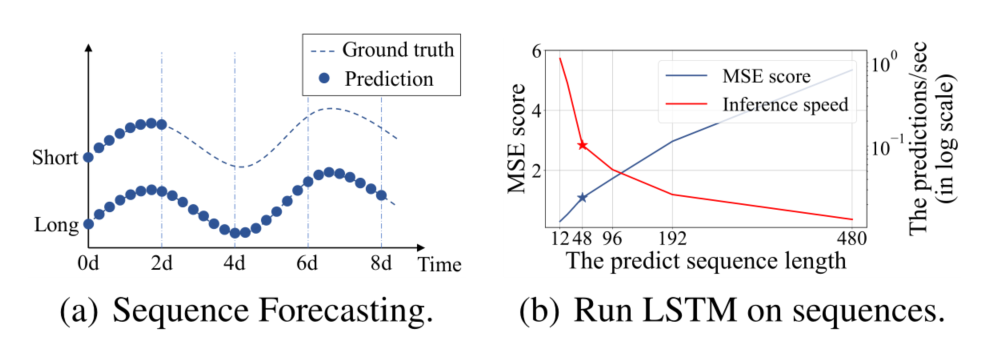
LSTM预测能力限制了LSTF的性能。例如,从长度=48开始,MSE上升得高得令人无法接受,推理速度迅速下降。
那么我们Transformer中也有提及到改进LSTM的方法,其优势和问题在于:
(1)万能模型,可直接套用,代码实现简单。
(2)并行的,比LSTM快,全局信息丰富,注意力机制效果好。
(3)长序列中attention需要每一个点跟其他点计算,如果序列太长,其效率很低。
(4)Decoder输出很麻烦,都要基于上一个预测结果来推断当前的预测结果,这对于一个长序列的预测中最好是不要出现这样的情况。
那么Informer就需要解决如下的问题:
| Transformer的缺点 | Informer的改进 |
|---|---|
| self-attention平方级的计算复杂度 | 提出ProbSparse Self-attention筛选出最重要的Q,降低计算复杂度 |
| 堆叠多层网络,内存占用瓶颈 | 提出Self-attention Distilling进行下采样操作,减少维度和网络参数的数量 |
| step-by-step解码预测,速度较慢 | 提出Generative Style Decoder,一步可以得到所有预测的 |
3. Informer 整体架构
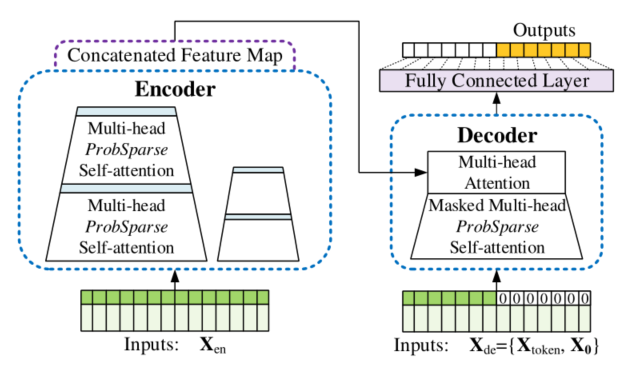
3.1 ProbSparse Self-attention
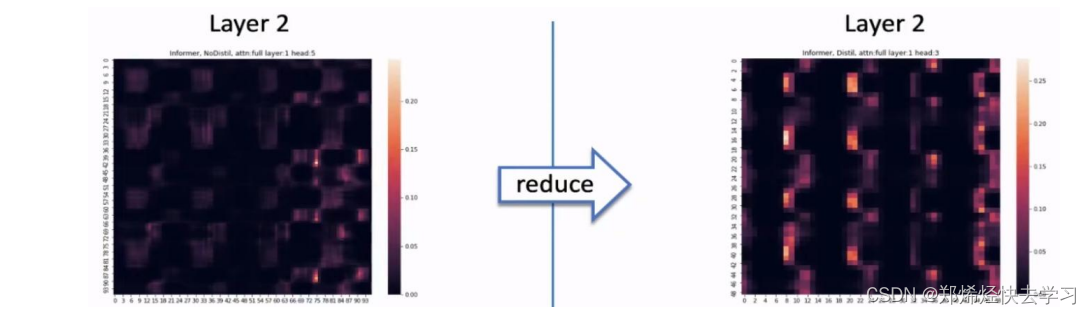
通过以下图数据可以看到,并不是每个QK的点积都是有效值,我们也不需要花很多时间在处理这些数据上:
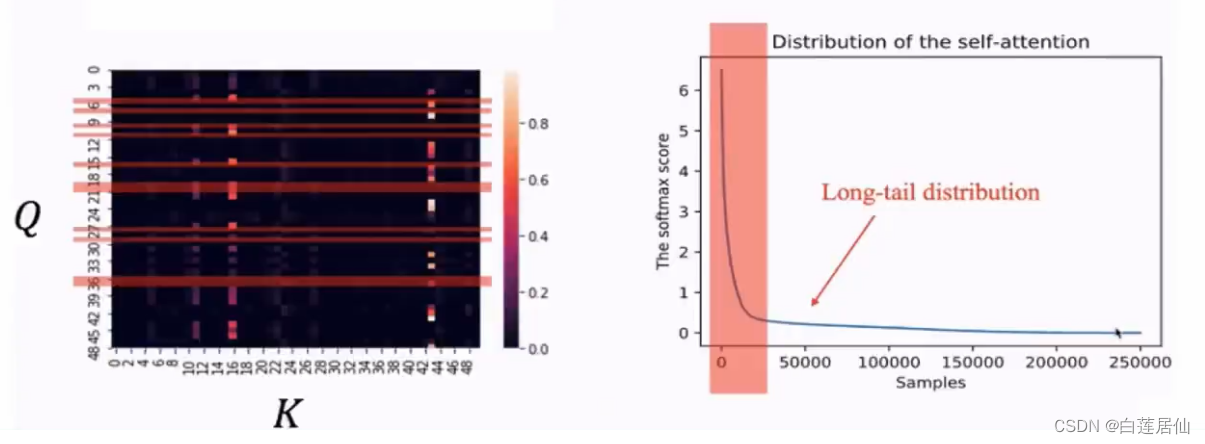
这个结果也是合理的,因为某个元素可能只和几个元素高度相关,和其他的元素并没有很显著的关联。如果我们要提高计算效率的话,我们需要关注那些有特点的那些值,那我们要怎么去关注那些有特点的值呢:
我们需要进行一次Query稀疏性的衡量:
作者从概率的角度看待自注意力,定义
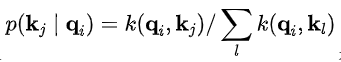
是概率的形式,即在给定第i个query的条件下key的分布。
作者认为,如果算出来的这个结果接近于均匀分布
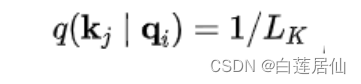
,那么就说明这个query是在偷懒,没办法选中那些重要的Key,如果反之,就说明这个Q为积极的,活跃的:
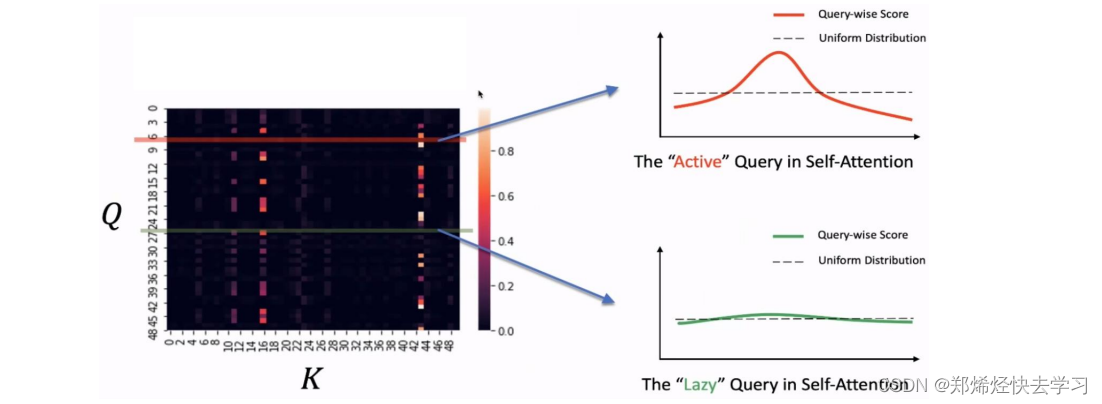
其计算公式如下:
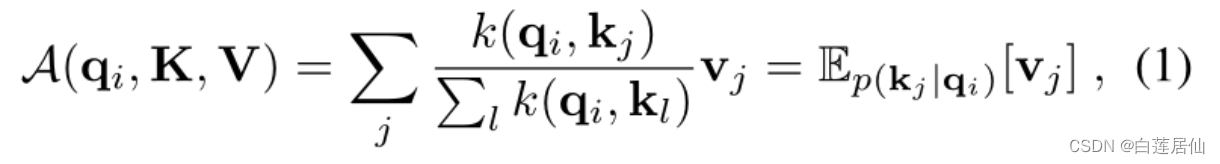
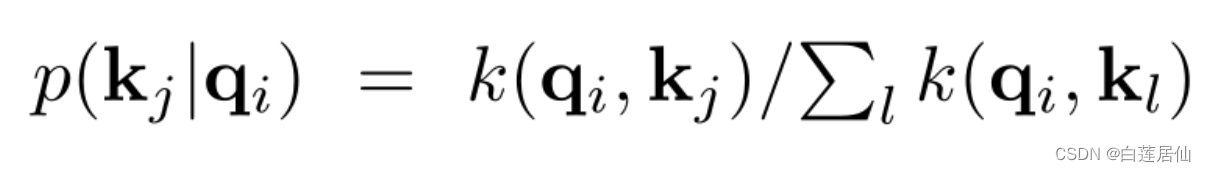
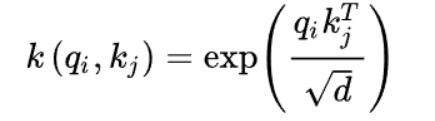
之后我们进行比较:
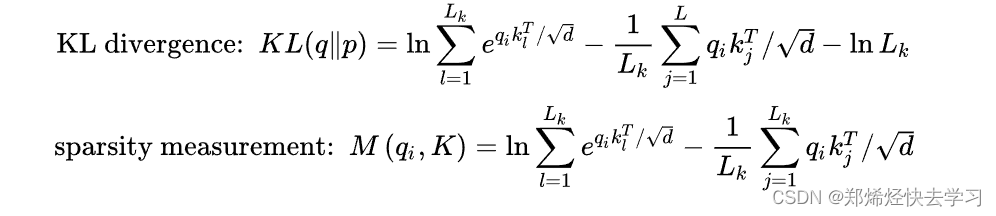
我们算出了其概率以及与均匀分布的差异,如果差异越大,那么这个Q就有机会去被关注、说明其起到了作用。那么其计算方法到底是怎么样进行的,我们要取哪些Q哪些K进行计算:
(1)输入序列长度为96,首先在K中进行采样,随机选取25个K。
(2)计算每个Q与25个K的点积,可以得到M(qi,K),现在一个Q一共有25个得分
(3)在25个得分中,选取最高分的那个Q与均值算差异。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7NwYUMzb-1691939172750)(https://cdn.jsdelivr.net/gh/Sql88/BlogImg@main/img/AgAACmAXn_S6vVNOPepOnbc96hbjQ4rH.png)]](https://img-blog.csdnimg.cn/92eef7386e9f489ca86a6852263050fa.png)
(4)这样我们输入的96个Q都有对应的差异得分,我们将差异从大到小排列,选出差异前25大的Q。
(5)那么传进去参数例如:[32,8,25,96],代表的意思为输入96个序列长度,32个batch,8个特征,25个Q进行处理。
(6)其他位置淘汰掉的Q使用均匀方差代替,不可以因为其不好用则不处理,需要进行更新,保证输入对着有输出。
以上的时间复杂度为O(L ln L):
ProbSparse Attention在为每个Q随机采样K时,每个head的采样结果是相同的,也就是采样的K是相同的。但是由于每一层self-attention都会对QKV做线性转换,这使得序列中同一个位置上不同的head对应的QK都不同,那么每一个head对于Q的差异都不同,这就使得每个head中的得到的前25个Q也是不同的。这样也等价于每个head都采取了不同的优化策略。
核心代码:
def _prob_QK(self, Q, K, sample_k, n_top): # n_top: c*ln(L_q)
# 维度[batch,头数,序列长度,自动计算值]
# Q [B, H, L, D]
B, H, L_K, E = K.shape # [32,8,96,64]
_, _, L_Q, _ = Q.shape # L_Q :96
# calculate the sampled Q_K
# 添加一个维度,相当于复制维度,当前维度为[batch,头数,序列长度,序列长度,自动计算值]
# K.unsqueeze(-3).shape: [32, 8, 1, 96, 64]
K_expand = K.unsqueeze(-3).expand(B, H, L_Q, L_K, E)
# 随机取样,取值范围0~96,取样维度为[序列长度,25]
index_sample = torch.randint(L_K, (L_Q, sample_k)) # real U = U_part(factor*ln(L_k))*L_q
# 96个Q与25个K做计算,维度为[batch,头数,Q个数,K个数,自动计算值]
K_sample = K_expand[:, :, torch.arange(L_Q).unsqueeze(1), index_sample, :]
# 矩阵重组,维度为[batch,头数,Q个数,K个数]
# 做点积
Q_K_sample = torch.matmul(Q.unsqueeze(-2), K_sample.transpose(-2, -1)).squeeze(-2)
# find the Top_k query with sparisty measurement
# 分别取到96个Q中每一个Q跟K关系最大的值
M = Q_K_sample.max(-1)[0] - torch.div(Q_K_sample.sum(-1), L_K)
# 在96个Q中选出前25个
M_top = M.topk(n_top, sorted=False)[1]
# use the reduced Q to calculate Q_K
# 取出Q特征,维度为[batch,头数,Q个数,自动计算值]
# Q_reduce.shape:[32, 8, 25, 64] 即从96中取出25个最有用的Q
Q_reduce = Q[torch.arange(B)[:, None, None],
torch.arange(H)[None, :, None],
M_top, :] # factor*ln(L_q)
# 25个Q与96个K做点积
Q_K = torch.matmul(Q_reduce, K.transpose(-2, -1)) # factor*ln(L_q)*L_k
return Q_K, M_top
3.2 Self-attention Distilling
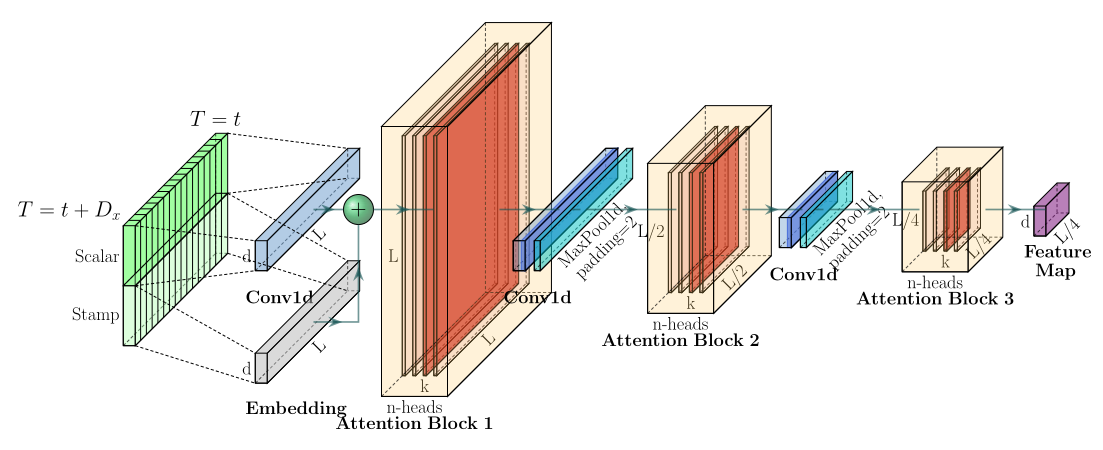
这一层类似于下采样。将我们输入的序列缩小为原来的二分之一。作者在这里提出了自注意力蒸馏的操作,具体是在相邻的的Attention Block之间加入卷积池化操作,来对特征进行降采样。为什么可以这么做,在上面的ProbSparse Attention中只选出了前25个Q做点积运算,形成Q-K对,其他Q-K对则置为0,所以当与value相乘时,会有很多冗余项。这样也可以突出其主要特征,也降低了长序列输入的空间复杂度,也不会损失很多信息,大大提高了效率。
另外,作者为了提高encoder的鲁棒性,还提出了一个strick。途中输入embedding经过了三个Attention Block,最终得到Feature Map。还可以再复制一份具有一半输入的embedding,让它让经过两个Attention Block,最终会得到和上面维度相同的Feature Map,然后把两个Feature Map拼接。作者认为这种方式对短周期的数据可能更有效一些。
3.3 Generative Style Decoder
对于Transformer其输出是先输出第一个,再基于第一个输出第二个,以此类推。这样子效率慢并且精度不高。看看总的架构图可以发现,decoder由两部分组成:第一部分为encoder的输出,第二部分为embedding后的decoder输入,即用0掩盖了后半部分的输入。
看看Embedding的操作:
● Scalar是采用conv1d将1维转换为512维向量。
● Local Time Stamp采用Transformer中的Positional Embedding。
● Gloabal Time Stamp则是上述处理后的时间戳经过Embedding。可以添加上我们的年月日时。
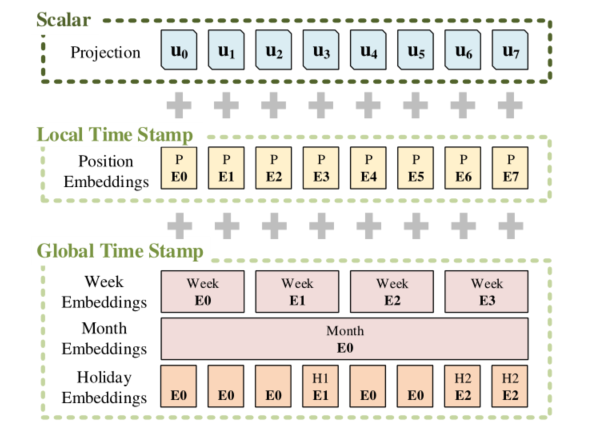
这种位置编码信息有比较丰富的返回,不仅有绝对位置编码,还包括了跟时间相关的各种编码。
最后,使用三者相加得到最后的输入(shape:[batch_size,seq_len,d_model])。
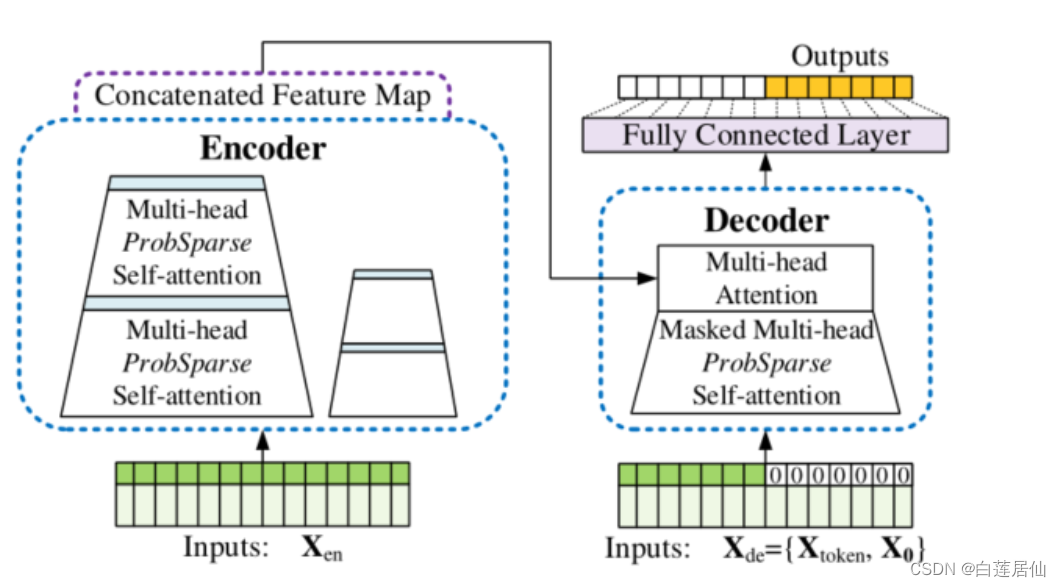
Decoder的最后一个部分是过一个linear layer将decoder的输出扩展到与vocabulary size一样的维度上,经过softmax后,选择概率最高的一个word作为预测结果。
那么假设我们有一个已经训练好的Transformer的神经网络,在预测时,传统的步骤是step by step的:
(1)给decoder输入encoder对整个句子embedding的结果和一个特殊的开始符号。decoder将产生预测,产生”I”。
(2)给decoder输入encoder的embedding结果和“I”,产生预测“am”
(3)给decoder输入encoder的embedding结果和“I am”,产生预测“a”
(4)给decoder输入encoder的embedding的结果和“I am a”,产生预测”student“。
(5)给decoder输入encoder的embedding的结果和“I am a student”,decoder应该生成句子结尾的标记,decoder应该输出“ ”。
(6)最后decoder生成了,翻译完成。
那么我们再看看Informer一步到位的预测:

提供一个start标志位:
● 要让Decoder输出预测结果,你得先告诉它从哪开始输出。
● 先给一个引导,比如要输出20-30号的预测结果,Decoder中需先给出。
● 前面一个序列的结果,例如10-20号的标签值。
其实我们可以理解为一段有效的标签值带着一群预测值进行学习,效率更高。可以说是生成式推理,作者在这里没有选择一个特定的标记来做开始序列,而是选择了一段长的序列,比如目标序列之前一段已知序列。举例来说如果我们要预测7天的,我们可以把之前5天的信息作为开始序列,那么我们上述的式子
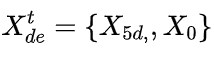
这种方法可以一步到位生成目标序列,不需要再使用动态解码。
对于Decoder输入:
源码中的decoder输入长度为72,其中前48是真实值,后24是预测值。第一步是做自身的ProbAttention,注意要加上Mask(避免未卜先知)。先计算完自身的Attention。再算与encoder的Attention即可。
4. Informer的实验性能
4个数据集(5例)的单变量长序列时间序列预测结果。

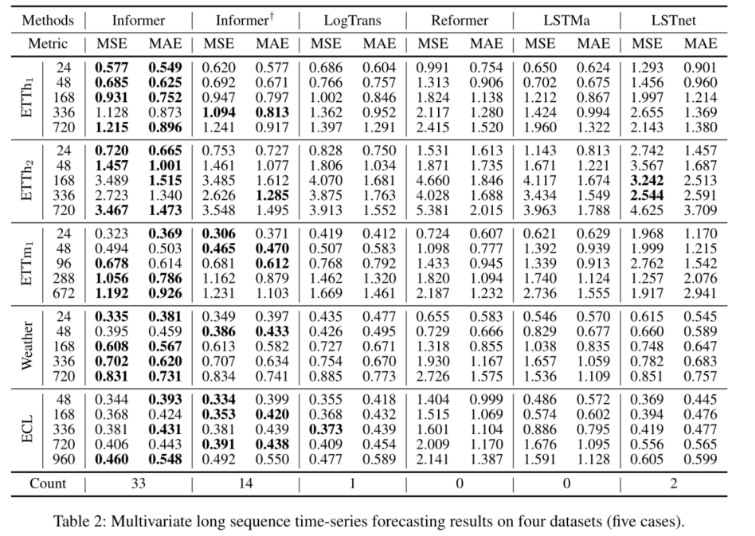
4个数据集(5例)的多变量长序列时间序列预测结果。
5. 相关资料
- Informer源码阅读及理论详解
- Informer源码
- Informer代码详解
- Transformer模型详解