网络流
- 设源点为 s s s,汇点为 t t t,每条边 e e e 的流量上限为 c ( e ) c(e) c(e),流量为 f ( e ) f(e) f(e)。
- 割 指对于某一顶点集合 P ⊂ V P \subset V P⊂V,从 P P P 出发指向 P P P 外部的那些原图中的边的集合,记作割 ( P , V / P ) (P, V /\ P) (P,V/ P)。这些边的容量被称为割的容量。若 s ∈ P , t ∈ V / P s\in P, t\in V /\ P s∈P,t∈V/ P,则称此时的割为 s − t s-t s−t 割。
- 对于任意的
s
−
t
s-t
s−t 流
F
F
F 和任意的
s
−
t
s-t
s−t 割
(
P
,
V
/
P
)
(P,V/\ P)
(P,V/ P) 割,由每个点的流量平衡条件得:
F 的流量 = P 出边总流量 − P 入边总流量 ≤ 割的容量 F 的流量 = P出边总流量 - P 入边总流量 \le 割的容量 F的流量=P出边总流量−P入边总流量≤割的容量 - 对于在残量网络中不断增广得到的流
F
F
F,设其对应的残量网络中从
s
s
s 出发可到达的顶点集为
S
S
S,则对于
S
S
S 指向
V
/
S
V/\ S
V/ S 的边
e
e
e 有
f
(
e
)
=
c
(
e
)
f(e) = c(e)
f(e)=c(e),而对
V
/
S
V/\ S
V/ S 指向
S
S
S 的边有
f
(
e
)
=
0
f(e) = 0
f(e)=0,则:
F 的流量 = S 出边总流量 − S 入边总流量 = S 出边总流量 = 割的容量 F 的流量 = S 出边总流量 - S入边总流量 = S出边总流量 = 割的容量 F的流量=S出边总流量−S入边总流量=S出边总流量=割的容量 - 因而 F F F 为最大流,同时 ( S , V / S ) (S,V/\ S) (S,V/ S) 为最小割,即最大流等于最小割。
Dinic 算法
- 主要思想即每次寻找最短的增广路,构造分层图,并沿着它多路增广。
- 每次多路增广完成后最短增广路长度至少增加 1,构造分层图次数为 O ( n ) \mathcal O(n) O(n),在同一分层图中,每条增广路都会被至少一条边限制流量(我们称之为瓶颈),显然任意两条增广路的瓶颈均不相同,因而增广路总数为 O ( m ) \mathcal O(m) O(m),加上当前弧优化,我们就能避免对无用边多次检查,寻找单条增广路的时间复杂度为 O ( n ) \mathcal O(n) O(n),总时间复杂度 O ( n 2 m ) \mathcal O(n^2m) O(n2m)。
- 这只是一个粗略的上界,实际的复杂度分析要结合具体的图模型,例如若最大流上限较小(设为 F F F),时间复杂度 O ( F ( n + m ) ) \mathcal O(F(n+m)) O(F(n+m))。
const int N = 1e4 + 5;
const int M = 2e5 + 5;
int nxt[M], to[M], cap[M], adj[N], que[N], cur[N], lev[N];
int n, m, src, des, qr, T = 1;
inline void linkArc(int x, int y, int w)
{
nxt[++T] = adj[x]; adj[x] = T; to[T] = y; cap[T] = w;
nxt[++T] = adj[y]; adj[y] = T; to[T] = x; cap[T] = 0;
}
inline bool Bfs()
{
for (int x = 1; x <= n; ++x)
cur[x] = adj[x], lev[x] = -1;
// 初始化具体的范围视建图而定,这里点的范围为 [1,n]
que[qr = 1] = src;
lev[src] = 0;
for (int i = 1; i <= qr; ++i)
{
int x = que[i], y;
for (int e = adj[x]; e; e = nxt[e])
if (cap[e] > 0 && lev[y = to[e]] == -1)
{
lev[y] = lev[x] + 1;
que[++qr] = y;
if (y == des)
return true;
}
}
return false;
}
inline ll Dinic(int x, ll flow)
{
if (x == des)
return flow;
int y, delta; ll res = 0;
for (int &e = cur[x]; e; e = nxt[e])
if (cap[e] > 0 && lev[y = to[e]] > lev[x])
{
delta = Dinic(y, Min(flow - res, (ll)cap[e]));
if (delta)
{
cap[e] -= delta;
cap[e ^ 1] += delta;
res += delta;
if (res == flow)
break ;
//此时 break 保证下次 cur[x] 仍有机会增广
}
}
if (res != flow)
lev[x] = -1;
return res;
}
inline ll maxFlow()
{
ll res = 0;
while (Bfs())
res += Dinic(src, Maxn);
return res;
}
- 单位网络 在该网络中,所有边的流量均为 1,除源汇点以外的所有点,都满足入边或者出边最多只有一条。
- 结论 对于包含二分图最大匹配在内的单位网络, Dinic \text{Dinic} Dinic 算法求解最大流的时间复杂度为 O ( m n ) \mathcal O(m\sqrt n) O(mn)。
证明 对于单位网络,每条边最多被考虑一次,一轮增广的时间复杂度为 O ( m ) \mathcal O(m) O(m)。
假设我们已经完成了前 n \sqrt n n 轮增广,还需找到 d d d 条增广路才能找到最大流,每条增广路的长度至少为 n \sqrt n n。这些增广路不会在源点和汇点以外的点相交,因而至少经过了 d n d\sqrt n dn 个点, d ≤ n d \le \sqrt n d≤n,则至多还需增广 n \sqrt n n 轮,总时间复杂度 O ( m n ) \mathcal O(m\sqrt n) O(mn)。
经典模型
- 二者选其一的最小割 有
n
n
n 个物品和两个集合
A
,
B
A,B
A,B,若第
i
i
i 个物品没有放入
A
A
A 集合花费
a
i
a_i
ai,没有放入
B
B
B 集合花费
b
i
b_i
bi,还有若干个限制条件,若
u
i
u_i
ui 和
v
i
v_i
vi 不在一个集合则花费
w
i
w_i
wi。
- 源点 s s s 向第 i i i 个点连一条容量为 a i a_i ai 的边,第 i i i 个点向汇点 t t t 连一条容量为 b i b_i bi 的边,在 u i u_i ui 和 v i v_i vi 之间连容量为 w i w_i wi 的双向边,最小割即最小花费。
- 最大权闭合子图 给定一张有向图,每个点都有一个权值(可为负),选择一个权值和最大的子图,使得子图中每个点的后继都在子图中。
- 若点权为正,则 s s s 向该点连一条容量为点权的边。
- 若点权为负,则该点向 t t t 连一条容量为点权的相反数的边。
- 原图上所有边的容量设为 + ∞ +\infty +∞。
- 则答案为正点权之和减去最小割。
- 分糖果问题
n
n
n 个糖果
m
m
m 个小孩,小孩
i
i
i 对糖果
j
j
j 有偏爱度
a
i
,
j
=
1
/
2
a_{i,j} = 1/2
ai,j=1/2,设
c
i
,
j
=
0
/
1
c_{i,j} = 0/1
ci,j=0/1 表示小孩
i
i
i 是否分得了糖果
j
j
j,小孩
i
i
i 觉得高兴当且仅当
∑
j
=
1
n
c
i
,
j
a
i
,
j
≥
b
i
\sum\limits_{j = 1}^{n} c_{i,j} a_{i,j}\ge b_i
j=1∑nci,jai,j≥bi,判断是否存在方案使所有小孩都高兴。
- 偏爱度 a i , j = 1 / 2 a_{i,j} = 1/2 ai,j=1/2 不好建图,转换思路先分配所有 a i , j = 2 a_{i,j} = 2 ai,j=2 的糖果。
- s s s 向所有糖果连一条容量为 1 的边,小孩 i i i 向 t t t 连一条容量为 ⌊ b i 2 ⌋ \lfloor \frac{b_i}{2} \rfloor ⌊2bi⌋ 的边。
- 对于所有满足 a i , j = 2 a_{i,j} = 2 ai,j=2 的边,令糖果 j j j 向小孩 i i i 连一条容量为 1 的边。
- 求得最大流 a n s ans ans,则存在方案当且仅当 a n s + n ≥ ∑ j = 1 m b i ans + n\ge \sum \limits_{j = 1}^{m}b_i ans+n≥j=1∑mbi。
- 动态流问题 宽为
w
w
w 的河上有
n
n
n 块石头,第
i
i
i 块坐标
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi),同一时刻最大承受人数为
c
i
c_i
ci,现有
m
m
m 个游客想要渡河,每人每次最远跳
d
d
d 米 ,单次耗时 1 秒,求全部渡河的最少时间(
n
,
m
≤
50
n,m \le 50
n,m≤50)。
- 答案取值范围较小可暴力枚举,将每一时刻的石头都视作一点,在石头上跳跃可视作从第 t t t 时刻的石头 i i i 跳向第 t + 1 t + 1 t+1 时刻的石头 j j j,每次将时刻加一,建出新的点和边后跑最大流,直至总流量大于等于 m m m。
费用流
- 在最大流的前提下使该网络总花费最小。
SSP 算法
-
每次寻找单位费用最小的增广路进行增广,直至图中不存在增广路为止。
-
设流量为 i i i 的时候最小费用为 f i f_i fi,假设初始网络上没有负圈, f 0 = 0 f_0 = 0 f0=0。
-
假设用 SSP \text{SSP} SSP 算法求出的 f i f_i fi 是最小费用,我们在 f i f_i fi 的基础上,找到一条最短的增广路,从而求出 f i + 1 f_{i + 1} fi+1,此时 f i + 1 − f i f_{i + 1} - f_i fi+1−fi 就是这条最短增广路的长度。
-
假设存在更小的 f i + 1 f_{i + 1} fi+1,设其为 f i + 1 ′ f_{i+1}' fi+1′,则 f i + 1 ′ − f i f'_{i + 1} - f_i fi+1′−fi 一定对应一个经过至少一个负圈的增广路。若残量网络中存在至少一个负圈,则可在不增加 s s s 流出的流量的情况下使费用减小,与 f i f_i fi 是最小费用矛盾。
-
综上, SSP \text{SSP} SSP 算法可以正确求出无负圈网络的最小费用最大流,设最大流为 F F F,总时间复杂度 O ( F n m ) \mathcal O(Fnm) O(Fnm)。
const int N = 5e3 + 5;
const int M = 1e5 + 5;
int nxt[M], to[M], cap[M], que[M], cst[M], adj[N], dis[N];
bool vis[N]; int n, m, src, des, ans, T = 1, qr;
inline void linkArc(int x, int y, int w, int z)
{
nxt[++T] = adj[x]; adj[x] = T; to[T] = y; cap[T] = w; cst[T] = z;
nxt[++T] = adj[y]; adj[y] = T; to[T] = x; cap[T] = 0; cst[T] = -z;
}
inline bool SPFA()
{
for (int x = 1; x <= n; ++x)
dis[x] = Maxn, vis[x] = false;
// 初始化具体的范围视建图而定,这里点的范围为 [1,n]
dis[que[qr = 1] = src] = 0;
for (int i = 1, x, y; i <= qr; ++i)
{
vis[x = que[i]] = false;
for (int e = adj[x]; e; e = nxt[e])
if (cap[e] > 0 && dis[y = to[e]] > dis[x] + cst[e])
{
dis[y] = dis[x] + cst[e];
if (!vis[y])
vis[que[++qr] = y] = true;
}
}
return dis[des] < Maxn;
}
inline int Dinic(int x, int flow)
{
if (x == des)
{
ans += flow * dis[des];
return flow;
}
vis[x] = true;
int y, delta, res = 0;
for (int e = adj[x]; e; e = nxt[e])
if (!vis[y = to[e]] && cap[e] > 0 && dis[y] == dis[x] + cst[e])
// vis 数组防止 dfs 在总费用为 0 的环上死循环
{
delta = Dinic(y, Min(flow - res, cap[e]));
if (delta)
{
cap[e] -= delta;
cap[e ^ 1] += delta;
res += delta;
if (res == flow)
break ;
}
}
return res;
}
inline int MCMF()
{
ans = 0;
int res = 0;
while (SPFA())
res += Dinic(src, Maxn);
return res;
}
经典模型
- 餐巾计划问题 一家餐厅在接下来的
T
T
T 天内需用餐巾,第
i
i
i 天需要
r
i
r_i
ri 块干净餐巾,餐厅可任意购买单价为
p
p
p 的干净餐巾,或者将脏餐巾送往快洗部(单块餐巾需洗
m
m
m 天,花费
f
f
f)或慢洗部(单块餐巾需洗
n
n
n 天,花费
s
s
s),求这
T
T
T 天内的最小花费。
- 主要的难点在于需将干净餐巾和脏餐巾区分开,第 i i i 天分设点 i , i ′ i,i' i,i′,流向这两点的流量分别表示第 i i i 天的干净餐巾和脏餐巾。
- s s s 向 i i i 连一条容量为 + ∞ +\infty +∞ 、费用为 p p p 的边, i i i 向 t t t 连一条容量为 r i r_i ri、费用为 0 的边。
- s s s 向 i ′ i' i′ 连一条容量为 r i r_i ri、费用为 0 的边, i ′ i' i′ 向 i + m i + m i+m 连一条容量为 + ∞ +\infty +∞,费用为 f f f 的边,向 i + n i + n i+n 连一条容量为 + ∞ +\infty +∞,费用为 s s s 的边,向 ( i + 1 ) ′ (i + 1)' (i+1)′ 连一条容量为 + ∞ +\infty +∞,费用为 0 0 0 的边。
- 显然该建图能使到 t t t 的边满流,则最小费用即为所求。
- 费用流转二分图最大匹配 若除去费用的建图为二分图且费用不为 0 的边均在二分图一侧,可将有费用的边从小到大排序,按照这一顺序跑匈牙利算法,容易证明最大匹配即对应最小费用,可将时间复杂度降至 O ( n m ) \mathcal O(nm) O(nm)。
二分图最大匹配
- 记图
G
=
(
V
,
E
)
G = (V,E)
G=(V,E)。
- 匹配 G G G 中两两没有公共端点的边集合 M ⊆ E M \subseteq E M⊆E。
- 边覆盖 G G G 中的任意顶点都至少是 F F F 中某条边的边集合 F ⊆ E F \subseteq E F⊆E。
- 独立集 G G G 中两两互不相连的顶点集 S ⊆ V S \subseteq V S⊆V。
- 点覆盖 G G G 中任意边都有至少一个端点属于 P P P 的顶点集合 P ⊆ V P \subseteq V P⊆V。
- 结论1 对于不存在孤立点的图, ∣ 最大匹配 ∣ + ∣ 最小边覆盖 ∣ = ∣ V ∣ |最大匹配|+|最小边覆盖| = |V| ∣最大匹配∣+∣最小边覆盖∣=∣V∣。
证明 设最大匹配数为 x x x,则其覆盖的点数为 2 x 2x 2x,剩余点两两之间没有边。则最少需要增加 ∣ V ∣ − 2 x |V| - 2x ∣V∣−2x 条边才能将所有点覆盖,则最小边覆盖数为 x + ∣ V ∣ − 2 x = ∣ V ∣ − x x + |V| - 2x = |V| - x x+∣V∣−2x=∣V∣−x。
- 结论2 ∣ 最大独立集 ∣ + ∣ 最小点覆盖 ∣ = ∣ V ∣ |最大独立集| + |最小点覆盖| = |V| ∣最大独立集∣+∣最小点覆盖∣=∣V∣。
证明 只需证明独立集和点覆盖一一对应且互为关于 V V V 的补集即可。取一个点覆盖关于 V V V 的补集,若其不是一个独立集,则存在两点有公共边,不难发现这与点覆盖的定义矛盾。
- 结论3 在二分图中, ∣ 最大匹配 ∣ = ∣ 最小点覆盖 ∣ |最大匹配|=|最小点覆盖| ∣最大匹配∣=∣最小点覆盖∣。
证明 设最大匹配数为 x x x,即让匹配中的每条边都和其一个端点关联。 x x x 个点是足够的,否则若存在一条边未被覆盖,加入这条边能得到一个更大的匹配。 x x x 个点是必需的,因为匹配的 x x x 条边两两无公共点。
-
结论4 在有向无环图中, ∣ 最小点不相交路径覆盖 ∣ + ∣ 最大匹配 ∣ = ∣ V ∣ |最小点不相交路径覆盖|+|最大匹配|=|V| ∣最小点不相交路径覆盖∣+∣最大匹配∣=∣V∣。这里的最大匹配指的是,将原图每个点拆成入点和出点两点,对于有向边 x → y x \to y x→y,将 x x x 的入点向 y y y 的出点连边,在该二分图上求得的最大匹配。
- 若需求 ∣ 最小点可相交路径覆盖 ∣ |最小点可相交路径覆盖| ∣最小点可相交路径覆盖∣,可以每个点为起点 BFS 求出传递闭包,传递闭包上建图即可,传递闭包中图的边数可能达到 O ( ∣ V ∣ 2 ) \mathcal O(|V|^2) O(∣V∣2),时间复杂度 O ( ∣ V ∣ ∣ E ∣ + ∣ V ∣ 2.5 ) \mathcal O(|V||E|+|V|^{2.5}) O(∣V∣∣E∣+∣V∣2.5),空间复杂度 O ( ∣ V ∣ 2 ) \mathcal O(|V|^2) O(∣V∣2),输出方案记录每个入点的匹配点即可,时间复杂度 ( ∣ V ∣ ) \mathcal (|V|) (∣V∣)。
- 若 ∣ E ∣ |E| ∣E∣ 较小,也可以不求传递闭包,将有向边的容量设为 + ∞ +\infty +∞,并将所有的出点向对应的入点连一条容量为 + ∞ +\infty +∞ 的边,即可实现传递闭包的效果,直接跑网络流即可,因为最大流上限为 ∣ V ∣ |V| ∣V∣,时间复杂度 O ( ∣ V ∣ ( ∣ V ∣ + ∣ E ∣ ) ) \mathcal O(|V|(|V|+|E|)) O(∣V∣(∣V∣+∣E∣)),空间复杂度 O ( ∣ V ∣ + ∣ E ∣ ) \mathcal O(|V|+|E|) O(∣V∣+∣E∣),实际上严格优于前述做法。该做法的输出方案较为麻烦,具体来说,我们根据所有匹配边建出一张图,若一个点的出边比入边多则它可以作为一条链的起点,暴力往下跳即可,实现时将本质相同的边压缩成一条可将空间复杂度降至 O ( ∣ V ∣ + ∣ E ∣ ) \mathcal O(|V|+|E|) O(∣V∣+∣E∣),时间复杂度 O ( ∣ V ∣ 2 ) \mathcal O(|V|^2) O(∣V∣2),参考代码如下:
// C 为二分图一侧的点数,src = 2 * C + 1 // 注意孤立点以及删去一条链可能会产生新的起点的情况 for (int x = 1; x <= C; ++x) for (int e = adj[x]; e; e = nxt[e]) if (to[e] > C && to[e] < src && to[e] - C != x && cap[e ^ 1] > 0) { re[x].emplace_back(std::make_pair(to[e] - C, cap[e ^ 1])); ++lre[x]; sre[x] += cap[e ^ 1]; ind[to[e] - C] += cap[e ^ 1]; } tis = 0; for (int t = 1; t <= C; ++t) { for (int x = 1; x <= C; ++x) while (sre[x] > ind[x]) { ++tis; int u = x; ans[u] = tis; while (sre[u]) { pir &v = re[u][lre[u] - 1]; int vid = v.first; if (--v.second == 0) re[u].pop_back(), --lre[u]; --sre[u]; u = vid; ans[u] = tis; --ind[u]; } } }
证明 只需证明二分图中匹配与原图中的路径覆盖一一对应且总和为 ∣ V ∣ |V| ∣V∣。对于每个没有匹配边的出点,我们都能构造一条路径,若其对应的入点存在匹配边,则将该匹配边加入该路径同时继续考虑该匹配边的出点直至其对应的入点不存在匹配边。得到的所有路径恰能覆盖所有点,且没有匹配边的出点和入点恰好能两两配对分别构成所有路径的起点和终点。
- Dilworth定理 对于任意有限偏序集,其最大反链中的元素个数必等于最小链划分中链的个数。
- 有限偏序集的最小链划分即其哈斯图对应的有向无环图的 ∣ 最小点可相交路径覆盖 ∣ |最小点可相交路径覆盖| ∣最小点可相交路径覆盖∣,用上述方法求解即可。
证明 设 m m m 为最大反链的元素个数, ∣ X ∣ = n |X| = n ∣X∣=n,只要证明偏序集 X X X 可被划分成 m m m 个链即可。
考虑用归纳法证明,当 n = 1 n = 1 n=1 时显然成立,下面证明 n > 1 n > 1 n>1 时的情形,设该有限偏序集中所有极小点构成的集合为 L L L,所有极大点构成的集合为 G G G,分两种情况讨论:
若存在最大反链 A A A,使得 A ≠ L A \not = L A=L 且 A ≠ G A \not = G A=G。构造:
A + = { x ∣ x ∈ X ∧ ∃ a ∈ A , a ≤ x } A − = { x ∣ x ∈ X ∧ ∃ a ∈ A , x ≤ a } A^+=\{x|x\in X \wedge \exist a\in A,a\le x\} \\ A^-=\{x|x\in X \wedge \exist a\in A,x \le a\} \\ A+={x∣x∈X∧∃a∈A,a≤x}A−={x∣x∈X∧∃a∈A,x≤a}
则容易得到 ∣ A + ∣ < ∣ X ∣ |A^+|<|X| ∣A+∣<∣X∣、 ∣ A − ∣ < ∣ X ∣ |A^-|<|X| ∣A−∣<∣X∣ 且 A + ∪ A − = X , A + ∩ A − = A A^+\cup A^- =X,A^{+}\cap A^-=A A+∪A−=X,A+∩A−=A,由归纳假设可将 A + A^{+} A+ 和 A − A^{-} A− 的 m m m 链划分拼接起来即可得到 X X X 的 m m m 链划分。若只存在反链 A = L A = L A=L 或 A = G A = G A=G,取极小元 x x x 和极大元 y y y 满足 x ≤ y x\le y x≤y( x , y x,y x,y 可相等),则由归纳假设 X − { x , y } X -\{x,y\} X−{x,y} 最大反链的元素个数为 m − 1 m - 1 m−1,存在 m − 1 m - 1 m−1 链划分,增加链 x ≤ y x\le y x≤y 可得到 X X X 的 m m m 链划分。
- Dilworth定理的对偶形式 最长链中元素个数必等于最小反链划分中反链的个数。
证明 设最长链的长度为 m m m,最小反链划分的数目为 M M M。
- 由于在任意一个反链中选取超过一个元素都违反链的定义,容易得到 m ≤ M m \le M m≤M。
- 考虑每次删去当前偏序集中的所有极小点,恰好删除 m m m 次能够将所有点删除,设第 i i i 次删点构成的极小点集合为 A i A_i Ai,则 A 1 , A 2 , … , A m A_1,A_2,\dots,A_m A1,A2,…,Am 构成一个反链划分,故有 M ≤ m M \le m M≤m。
综上所述, m = M m = M m=M,原命题得证。
匈牙利算法
- 从每个点出发尝试找到一条增广路,时间复杂度 O ( n m ) \mathcal O(nm) O(nm)。
inline bool Hungary(int x)
{
int y;
for (arc *e = adj[x]; e; e = e->nxt)
if (!mateR[y = e->to])
return mateR[y] = x, true;
for (arc *e = adj[x]; e; e = e->nxt)
{
if (vis[y = e->to] == tis)
continue ;
vis[y] = tis;
if (Hungary(mateR[y]))
return mateR[y] = x, true;
}
return false;
}
inline int maxMatch()
{
int cnt = 0;
for (int i = 1; i <= n; ++i)
{
++tis;
if (Hungary(i))
++cnt;
}
return cnt;
}
二分图最大权匹配
Kuhn-Munkres算法
- 该算法用于 O ( n 3 ) \mathcal O(n^3) O(n3) 求二分图的最大权完美匹配,若二分图左右部的点数不相同,需将点数补至相同,并将所有不存在的边的权设为 0。
- 若题目对是否是完备匹配有要求,需将不存在的边设为 − ∞ -\infty −∞(具体值需保证一旦选这种边就比所有不选这种边的方案更劣),此时也能处理原图边权有负数的情况。
- 可行顶标 对于二分图 < X , E , Y > <X,E,Y> <X,E,Y>,对于 x ∈ X x \in X x∈X 分配权值 labx ( x ) \text{labx}(x) labx(x),对于 y ∈ Y y\in Y y∈Y 分配权值 laby ( y ) \text{laby}(y) laby(y),对于所有边 ( x , y ) ∈ E (x,y)\in E (x,y)∈E 满足 w ( x , y ) ≤ labx ( x ) + laby ( y ) w(x,y) \le \text{labx}(x) + \text{laby}(y) w(x,y)≤labx(x)+laby(y)。
- 相等子图 在一组可行顶标下原图的生成子图,包含所有点但只满足包含 labx ( x ) + laby ( y ) = w ( x , y ) \text{labx}(x) + \text{laby}(y) = w(x,y) labx(x)+laby(y)=w(x,y) 的边 ( x , y ) (x,y) (x,y)。
- 定理 对于某组可行顶标,若其相等子图内存在完美匹配,该匹配为原图的最大权完美匹配。
证明 设可行顶标下相等子图中的完美匹配为 M ′ M' M′,对于原二分图任意一组完美匹配 M M M,其边权和
val ( M ) = ∑ ( x , y ) ∈ M w ( x , y ) ≤ ∑ x ∈ X labx ( x ) + ∑ y ∈ Y laby ( y ) = val ( M ′ ) \text{val}(M) = \sum \limits_{(x,y)\in M}w(x,y) \le \sum\limits_{x\in X}\text{labx}(x) + \sum \limits_{y \in Y} \text{laby}(y) = \text{val}(M') val(M)=(x,y)∈M∑w(x,y)≤x∈X∑labx(x)+y∈Y∑laby(y)=val(M′)
故若 M ′ M' M′ 存在, M ′ M' M′ 即为最大权完美匹配。
- 下面的算法过程将证明一定能够通过调整顶标,使得相等子图内存在完美匹配。
- 初始可行顶标 labx ( x ) = max y ∈ Y { w ( x , y ) } , laby ( y ) = 0 \text{labx}(x) = \max\limits_{y\in Y}\{w(x,y)\}, \text{laby}(y) = 0 labx(x)=y∈Ymax{w(x,y)},laby(y)=0,在相等子图内找一个未匹配的点,尝试寻找增广路,若能找到直接增广,否则将形成一棵交错树。
- 交错树是由从一个未匹配点出发沿着 非匹配边-匹配边 交替的所有路径构成的树,将树中顶点与
X
X
X 的交集记为
S
S
S,与
Y
Y
Y 的交集记为
T
T
T,令
S
′
=
X
−
S
,
T
′
=
Y
−
T
S' = X - S, T' = Y - T
S′=X−S,T′=Y−T(
S
/
S
′
,
T
/
T
′
S/S',T/T'
S/S′,T/T′ 程序中分别用
visx
(
x
)
\text{visx}(x)
visx(x) 和
visy
(
y
)
\text{visy}(y)
visy(y) 标示),如下图所示。
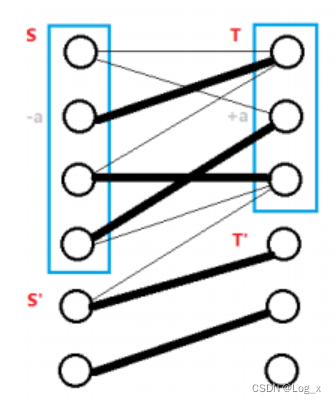
- 在相等子图中:
- S − T ′ S-T' S−T′ 的边不存在,若其为匹配边违反交错树的定义,若其为非匹配边则会形成增广路或者使交错树扩大。
- S ′ − T S'-T S′−T 的边一定是非匹配边,否则将使交错树扩大。
- 将
S
S
S 中的顶标
−
a
-a
−a,将
T
T
T 中的顶标
+
a
+a
+a,可以发现:
- S − T S-T S−T 和 S ′ − T ′ S'-T' S′−T′ 在相等子图中的边均无变化。
- S − T ′ S-T' S−T′ 的边对应顶标和减少,可能作为非匹配边加入相等子图,由上述性质,增加的边将形成增广路或使交错树扩大。
- S ′ − T S'-T S′−T 的边对应顶标和增加,不可能加入相等子图。
- 设
slacky
(
y
)
=
min
x
∈
S
{
labx
(
x
)
+
laby
(
y
)
−
w
(
x
,
y
)
}
\text{slacky}(y) = \min\limits_{x\in S}\{\text{labx}(x) + \text{laby}(y) - w(x,y)\}
slacky(y)=x∈Smin{labx(x)+laby(y)−w(x,y)}(当且仅当
y
∈
T
′
y \in T'
y∈T′ 该值才有意义),则令
a
=
min
y
∈
T
′
{
slacky
(
y
)
}
a = \min\limits_{y\in T'}\{\text{slacky}(y)\}
a=y∈T′min{slacky(y)},每次修改顶标时,必定会有至少一条产生增广路或使交错树扩大的非匹配边加入相等子图。
- 在遍历交错树的过程中,记 pre ( y ) = x ( x ∈ X , y ∈ Y ) \text{pre}(y) = x(x\in X, y\in Y) pre(y)=x(x∈X,y∈Y) 表示交错树上 x , y x,y x,y 通过非匹配边相连,若产生了增广路,根据 pre \text{pre} pre 更新匹配边即可完成增广。
- 若使交错树扩大, 更新 slacky \text{slacky} slacky,在交错树增加的结点中重复上述过程直至完成增广,由于左右部点数相同,这一过程一定能够结束。
- 遍历交错树的部分通过 BFS \text{BFS} BFS 实现。总共需要完成 n n n 次增广,每次增广中 BFS \text{BFS} BFS 的总时间复杂度为 O ( n 2 ) \mathcal O(n^2) O(n2),更新顶标的次数为 O ( n ) \mathcal O(n) O(n)(每次更新都会使 T T T 扩大),每次更新后维护 slacky \text{slacky} slacky 并确定 a a a 的时间复杂度也为 O ( n ) \mathcal O(n) O(n),故总的时间复杂度为 O ( n 3 ) \mathcal O(n^3) O(n3)。
typedef long long ll;
const int N = 405;
const int Maxn = 2e9;
int que[N], w[N][N], slacky[N];
int labx[N], laby[N], matex[N], matey[N], pre[N];
bool visx[N], visy[N];
int nl, nr, qr, n, m; ll ans;
inline bool Augment(int y)
{
if (matey[y])
{
que[++qr] = matey[y];
visx[matey[y]] = visy[y] = true;
return false;
}
else
{
while (y)
{
int x = pre[y];
matey[y] = x;
std::swap(matex[x], y);
}
return true;
}
}
inline void bfsHungary(int src)
{
for (int i = 1; i <= n; ++i)
{
pre[i] = 0;
visx[i] = visy[i] = false;
slacky[i] = Maxn;
}
visx[que[qr = 1] = src] = true;
while (1)
{
for (int i = 1, x; i <= qr; ++i)
{
x = que[i];
for (int y = 1; y <= n; ++y)
if (!visy[y])
{
int delta = labx[x] + laby[y] - w[x][y];
if (delta > slacky[y])
continue ;
pre[y] = x;
if (delta > 0)
slacky[y] = delta;
else if (Augment(y))
return ;
}
}
int nxt, delta = Maxn;
for (int y = 1; y <= n; ++y)
if (!visy[y] && slacky[y] < delta)
delta = slacky[y], nxt = y;
for (int i = 1; i <= n; ++i)
{
if (visx[i])
labx[i] -= delta;
if (visy[i])
laby[i] += delta;
else
slacky[i] -= delta;
}
qr = 0;
if (Augment(nxt))
return ;
}
}
int main()
{
read(nl); read(nr); read(m);
n = Max(nl, nr);
int x, y, z;
while (m--)
{
read(x); read(y); read(z);
CkMax(w[x][y], z);
CkMax(labx[x], z);
}
for (int i = 1; i <= n; ++i)
bfsHungary(i);
for (int i = 1; i <= n; ++i)
ans += w[i][matex[i]];
put(ans), putchar('\n');
for (int i = 1; i <= nl; ++i)
put(w[i][matex[i]] ? matex[i] : 0), putchar(' ');
}
二分图稳定匹配
问题描述
- 对于任意的 x ∈ X x \in X x∈X,存在一个由 Y Y Y 内所有结点构成的偏爱列表 p r f X [ x ] prf_X[x] prfX[x],列表中结点排名越靠前对 x x x 适配度越高,记 r k X [ x ] [ y ] rk_X[x][y] rkX[x][y] 表示 y y y 在 p r f X [ x ] prf_X[x] prfX[x] 中的排名。
- 对于任意的 y ∈ Y y\in Y y∈Y,同样定义 p r f Y [ y ] prf_Y[y] prfY[y] 和 r k Y [ y ] [ x ] rk_Y[y][x] rkY[y][x]。
- 对于二分图
<
X
,
Y
,
E
>
<X,Y,E>
<X,Y,E>,某一匹配是稳定的(Stable Matching)当且仅当(记
x
x
x 的匹配结点为
m
a
t
X
[
x
]
mat_X[x]
matX[x],
y
y
y 的匹配结点为
m
a
t
Y
[
y
]
mat_Y[y]
matY[y]):
- 不存在
x
,
y
x,y
x,y 满足
x
≠
m
a
t
Y
[
y
]
x \not = mat_Y[y]
x=matY[y],且:
- r k X [ y ] < r k X [ m a t X [ x ] ] rk_X[y] < rk_X[mat_X[x]] rkX[y]<rkX[matX[x]]
- r k Y [ x ] < r k Y [ m a t Y [ y ] ] rk_Y[x] < rk_Y[mat_Y[y]] rkY[x]<rkY[matY[y]]
- 不存在
x
,
y
x,y
x,y 满足
x
≠
m
a
t
Y
[
y
]
x \not = mat_Y[y]
x=matY[y],且:
Gale-Shapley 算法
- 描述该算法的 python 代码如下:
rkx = rky = matx = maty = dict()
for x in prfx.keys():
for i in range(len(prfx[x])):
rkx[(x, prfx[x][i])] = i
for y in prfy.keys():
for i in range(len(prfy[y])):
rky[(y, prfy[y][i])] = i
for x in prfx.keys():
prfx[x].reverse()
list = [x for x in prfx.keys()]
while len(list) > 0:
x = list.pop()
while len(prfx[x]) > 0:
y = prfx[x].pop()
if y not in maty:
maty[y] = x
matx[x] = y
break
elif rky[(y, x)] < rky[(y, maty[y])]:
del matx[maty[y]]
list.append(maty[y])
maty[y] = x
matx[x] = y
break
- 关于该算法的正确性:
- 如果 ∣ X ∣ = ∣ Y ∣ |X| = |Y| ∣X∣=∣Y∣,最后总能找到一个匹配,且 p r f X [ x ] prf_X[x] prfX[x] 中的元素不会重复遍历,时间复杂度 O ( ∣ X ∣ ∣ Y ∣ ) \mathcal O(|X||Y|) O(∣X∣∣Y∣)。
- 考虑任何不在现有匹配中的
(
x
,
y
)
(x,y)
(x,y):
- 若 x x x 从未尝试与 y y y 匹配,则说明 r k X [ x ] [ m a t X [ x ] ] < r k X [ x ] [ y ] rk_X[x][mat_X[x]] < rk_X[x][y] rkX[x][matX[x]]<rkX[x][y]。
- 若 x x x 尝试过与 y y y 匹配,则说明 r k Y [ y ] [ m a t Y [ y ] ] < r k Y [ y ] [ x ] rk_Y[y][mat_Y[y]] < rk_Y[y][x] rkY[y][matY[y]]<rkY[y][x]。
- 故该匹配是稳定的。
- 定义1 配对 ( x , y ) (x,y) (x,y) 是有效的当且仅当存在一个稳定匹配使之包含 ( x , y ) (x,y) (x,y)。
- 定义2 记 y x y_x yx 表示在列表 p r f X [ x ] prf_X[x] prfX[x] 中最靠前的 y y y,一个匹配为 X X X-最优匹配当且仅当若 ( x , y x ) (x,y_x) (x,yx) 是有效的,则该匹配一定包含 ( x , y x ) (x,y_x) (x,yx)。
- 结论 Gale-Shapley 算法产生的匹配 M M M 一定为 X X X-最优匹配。
证明 记 y = y x y = y_x y=yx,假设 ( x , y ) (x,y) (x,y) 是有效的且 M M M 不包含 ( x , y ) (x,y) (x,y)。
设 M M M 中与 y y y 匹配的是 x ′ x' x′,由算法流程 r k Y [ y ] [ x ′ ] < r k Y [ y ] [ x ] rk_Y[y][x']<rk_Y[y][x] rkY[y][x′]<rkY[y][x](要么 x x x 匹配后被 x ′ x' x′ 替代,要么 x ′ x' x′ 先匹配后无法被 x x x 替代)。
由有效配对的定义,一定存在稳定匹配 M ′ M' M′ 包含 ( x , y ) (x,y) (x,y)。
记 M ′ M' M′ 中与 x ′ x' x′ 匹配的是 y ′ y' y′,能够得到匹配 M M M 的条件是 r k X [ x ′ ] [ y ] < r k X [ x ′ ] [ y ′ ] rk_X[x'][y] < rk_X[x'][y'] rkX[x′][y]<rkX[x′][y′],则由于 ( x ′ , y ) (x',y) (x′,y) 的存在, M ′ M' M′ 是不稳定的,与假设矛盾。
图的着色
点着色
- 设图 G G G 的点色数为 χ ( G ) \chi(G) χ(G),则显然有 χ ( G ) ≤ Δ ( G ) + 1 \chi(G) \le \Delta(G)+1 χ(G)≤Δ(G)+1。
- Brooks 定理 若 G G G 不为完全图或奇环,则 χ ( G ) ≤ Δ ( G ) \chi(G) \le \Delta(G) χ(G)≤Δ(G)。
证明 设 ∣ V ( G ) ∣ = n |V(G)|=n ∣V(G)∣=n,考虑数学归纳法。
首先, n ≤ 3 n\le 3 n≤3 时,命题显然成立。
根据归纳法,假设对于 n − 1 n - 1 n−1 的命题成立。
不妨只考虑 Δ ( G ) \Delta(G) Δ(G)-正则图,因为对于非正则图来说,可以看作在正则图里删去一些边构成的,而这一过程并不会影响结论。
对于任意不是完全图也不是奇圈的正则图 G G G,任取其中一点 v v v,考虑子图 H = G − v H = G - v H=G−v,由归纳假设知 χ ( H ) ≤ Δ ( H ) ≤ Δ ( G ) \chi(H)\le \Delta(H) \le \Delta(G) χ(H)≤Δ(H)≤Δ(G),接下来我们只需证明在 H H H 中插入 v v v 不会影响结论即可。
若 Δ ( H ) < Δ ( G ) \Delta(H) < \Delta(G) Δ(H)<Δ(G),无需再做证明,我们只考虑 Δ ( H ) = Δ ( G ) \Delta(H) = \Delta(G) Δ(H)=Δ(G) 的情况。
令 Δ = Δ ( G ) \Delta = \Delta(G) Δ=Δ(G),设 H H H 染的 C C C 种颜色分别为 c 1 , c 2 , … , c Δ c_1, c_2, \dots, c_{\Delta} c1,c2,…,cΔ, v v v 的 Δ \Delta Δ 个邻接点为 v 1 , v 2 , … , v Δ v_1, v_2, \dots, v_{\Delta} v1,v2,…,vΔ。若 v v v 的邻接点个数不足 Δ \Delta Δ 个或存在任意两点颜色相同,同样无需再做证明。
设所有在 H H H 中染成 c i c_i ci 或 c j c_j cj 的点以及它们之间的所有边构成子图 H i , j H_{i,j} Hi,j。不妨假设任意 2 个不同的点 v i , v j v_i,v_j vi,vj 一定在 H i , j H_{i,j} Hi,j 的同一个连通分量中,否则若在两个连通分量中的话,可以交换其中一个连通分量所有点的颜色,从而使 v i , v j v_i,v_j vi,vj 颜色相同,即能有多余的颜色对 v v v 进行染色,无需再做证明。
这里的交换颜色指的是若图中只有两种颜色 a , b a,b a,b,那么把图中原来染成颜色 a a a 的点全部染成颜色 b b b,把图中原来染成颜色 b b b 的点全部染成颜色 a a a。
我们设上述连通分量为 C i , j C_{i,j} Ci,j,取出 C i , j C_{i,j} Ci,j 中一条路径记作 P i , j P_{i,j} Pi,j,则恒有 C i , j = P i , j C_{i,j} = P_{i,j} Ci,j=Pi,j。因为 v i v_i vi 在 H H H 中的度为 Δ − 1 \Delta-1 Δ−1,所以 v i v_i vi 在 H H H 中的邻接点颜色一定两两不同,否则可以给 v i v_i vi 染别的颜色,从而和 v v v 的其他邻接点颜色重复,所以 v i v_i vi 在 C i , j C_{i,j} Ci,j 中邻接点数量为 1。若 C i , j ≠ P i , j C_{i,j} \not = P_{i,j} Ci,j=Pi,j,设在 C i , j C_{i,j} Ci,j 中从 v i v_i vi 开始沿着 P i , j P_{i,j} Pi,j 遇到的第一个度数大于 2 的点为 u u u,注意到 u u u 的邻接点最多只用了 Δ − 2 \Delta - 2 Δ−2 种颜色,所以 u u u 可以重新染色,从而使 v i , v j v_i,v_j vi,vj 不连通。
沿用这一技术,我们可以证明对于 3 个不同的点 v i , v j , v k v_i,v_j,v_k vi,vj,vk, V ( C i , j ) ∩ V ( C j , k ) = { v j } V(C_{i,j})\cap V(C_{j,k}) = \{v_j\} V(Ci,j)∩V(Cj,k)={vj}。假设存在 w ∈ V ( C i , j ) ∩ V ( C j , k ) w \in V(C_{i,j})\cap V(C_{j,k}) w∈V(Ci,j)∩V(Cj,k),若 w ≠ v j w \not = v_j w=vj,则 w w w 必被染色为 c j c_j cj,且恰有两个被染色为 c i c_i ci 的邻接点和两个被染色为 c j c_j cj 的邻接点,注意到 w w w 的邻接点最多只用了 Δ − 2 \Delta - 2 Δ−2 种颜色,所以 w w w 同样可以重新染色。
若 v v v 的邻接点两两相邻,则必有 Δ = n \Delta = n Δ=n,即 G G G 为完全图。否则不妨设 v 1 , v 2 v_1,v_2 v1,v2 不相邻,在 C 1 , 2 C_{1,2} C1,2 取 v 1 v_1 v1 的邻接点 w w w,交换 C 1 , 3 C_{1,3} C1,3 中的颜色,则 w ∈ V ( C 1 , 2 ) ∩ V ( C 2 , 3 ) w \in V(C_{1,2})\cap V(C_{2,3}) w∈V(C1,2)∩V(C2,3),与上述结论矛盾。
至此命题证明完毕。
斯坦纳树
- 以以下题面为例,主要把握其思想:
- 给定连通图 G G G 中的 n n n 个点与 k k k 个关键点,求能包含 k k k 个关键点的生成树的最小边权, k ≪ n k \ll n k≪n。
- 设
f
x
,
S
f_{x,S}
fx,S 表示以
x
x
x 为根且包含关键点集合
S
S
S 的生成树的最小边权,在外层从小到大枚举
S
S
S,转移分为两类:
- f x , S = min { f x , S , f x , S − T + f x , T } f_{x,S} = \min\{f_{x,S}, f_{x,S-T}+f_{x,T}\} fx,S=min{fx,S,fx,S−T+fx,T}
- 松弛,可通过 Dijkstra 或 SPFA 实现, f x , S = min { f x , S , f y , S + w ( x , y ) } f_{x,S} = \min\{f_{x,S},f_{y,S} + w(x,y)\} fx,S=min{fx,S,fy,S+w(x,y)}
- 总时间复杂度 O ( 2 k ( n + m ) log ( n + m ) + 3 k n ) \mathcal O(2^k(n +m)\log(n + m)+3^kn) O(2k(n+m)log(n+m)+3kn)。
竞赛图
- 定义 将 n n n 个点的无向完全图任意定向即可得到竞赛图。
- 性质1 竞赛图缩点后呈链状,即求出竞赛图缩点后的拓扑序后,任意两个强连通分量之间的连边一定都是从拓扑序小的连向拓扑序大的。
证明 对强连通分量个数归纳,若新增的强连通分量拓扑序最大,则所有连向其的边同向。
- 性质2 竞赛图中每个强连通分量中存在哈密顿回路。
证明 对点数 n ( n ≥ 3 ) n(n\ge3) n(n≥3) 归纳,若新增的点连向原有 n n n 个点的所有边均同向,则这 n + 1 n + 1 n+1 个点不构成强连通分量,否则总可以找到 n n n 个点中的两个点,使得它们在哈密顿回路上相邻且连向新增点的方向相反。
- 性质3 竞赛图中存在一条哈密顿路径。
证明 因为属于不同强连通分量间的点均有连边,由 性质2 取每个强连通分量中的哈密顿回路相连即可。
- 性质4 对于点数为 n n n 的强连通竞赛图, ∀ 3 ≤ l ≤ n \forall3\le l\le n ∀3≤l≤n,其一定存在长度为 l l l 的简单环。
证明 考虑对点数 n n n 归纳,由 性质1,删除第 n n n 个点后原图变为若干个强连通分量的链状图,由归纳条件,每个强连通分量均可以构造出不超过点数的简单环,且第 n n n 个点一定有指向拓扑序最小的强连通分量的边,拓扑序最大的强连通分量一定有指向 n n n 的边,不难得到构造长度不超过 n n n 的简单环的方案。
- 性质5 在竞赛图中若点 u u u 的出度大于等于点 v v v 的出度,则 u u u 一定可以到达 v v v。
证明 考虑证明其逆否命题,由 性质1,仅需证明 u u u 所在强连通分量拓扑序大于 v v v 所在强连通分量拓扑序的情况,此时显然 v v v 的出度大于 u u u 的出度。
- 兰道定理 将竞赛图的出度序列排序后得到 s 1 , s 2 , … , s n s_1,s_2,\dots,s_n s1,s2,…,sn,该序列合法当且仅当 ∀ 2 ≤ k ≤ n , ∑ i = 1 k s i ≥ ( k 2 ) \forall 2 \le k\le n,\sum\limits_{i = 1}^{k}s_i\ge\binom{k}{2} ∀2≤k≤n,i=1∑ksi≥(2k) 且 ∑ i = 1 n s i = ( n 2 ) \sum\limits_{i = 1}^{n}s_i = \binom{n}{2} i=1∑nsi=(2n)。
证明 其必要性显然,因为任取点数为 k k k 的导出子图都满足该条件。考虑证明其充分性,构造一个所有边均是大点连向小点的竞赛图,则其 s i ′ = i − 1 s_i'=i-1 si′=i−1,上述不等式可变形为 ∑ i = 1 k s i ≥ ∑ i = 1 k s i ′ \sum\limits_{i = 1}^{k}s_i\ge \sum\limits_{i = 1}^{k}s_i' i=1∑ksi≥i=1∑ksi′,现在尝试通过不断调整该图,使得每个不等式均能取等号,每次操作如下:
- 找到第一个 x x x 使得 s x > s x ′ s_x > s_x' sx>sx′。
- 在 x x x 后找到第一个 z z z 使得 s z < s z ′ s_z < s_z' sz<sz′
- 因而有 s z ′ > s z ≥ s x > s x ′ s_z'>s_z\ge s_x > s_x' sz′>sz≥sx>sx′,即 s z ′ − s x ′ ≥ 2 s_z' - s_x'\ge 2 sz′−sx′≥2,此时必存在点 y y y,使得边 z → y z \to y z→y 和 y → x y \to x y→x 存在,将这两条边反向,则 s z ′ s'_z sz′ 减少 1, s x ′ s_x' sx′ 增加 1, s y ′ s_y' sy′ 不变,原不等式仍成立。
强连通竞赛图计数
- 设
f
n
f_n
fn 表示
n
n
n 个点的强连通竞赛图个数,考虑通过容斥原理计算
f
n
f_n
fn,枚举拓扑序最靠前的强连通分量的大小,则剩余点连向该强连通分量的边的方向固定,而剩余点内部的连边是任意的,则对于
n
≥
1
n \ge 1
n≥1,有:
f n = 2 ( n 2 ) − ∑ i = 1 n − 1 ( n i ) f i 2 ( n − i 2 ) 2 ( n 2 ) n ! = ∑ i = 1 n f i i ! 2 ( n − i 2 ) ( n − i ) ! \begin{aligned} f_n = 2^{\binom{n}{2}}- \sum\limits_{i=1}^{n - 1}\binom{n}{i}f_{i} 2^{\binom{n - i}{2}} \\ \dfrac{2^{\binom{n}{2}}}{n!} = \sum \limits_{i = 1}^{n}\dfrac{f_i}{i!} \dfrac{2^{\binom{n - i}{2}}}{(n - i)!} \end{aligned} fn=2(2n)−i=1∑n−1(in)fi2(2n−i)n!2(2n)=i=1∑ni!fi(n−i)!2(2n−i) - 设
F
(
x
)
=
∑
n
≥
1
f
n
n
!
x
n
F(x) = \sum\limits_{n\ge 1}\dfrac{f_n}{n!} x^n
F(x)=n≥1∑n!fnxn,
G
(
x
)
=
∑
n
≥
0
2
(
n
2
)
n
!
x
n
G(x) = \sum \limits_{n \ge 0}\dfrac{2^{\binom{n}{2}}}{n!}x^n
G(x)=n≥0∑n!2(2n)xn,则上式可表达为:
G = F G + 1 F = 1 − 1 G \begin{aligned} G = FG + 1 \\ F = 1 - \dfrac{1}{G} \\ \end{aligned} G=FG+1F=1−G1 - 通过多项式求逆计算出 F F F 即可。