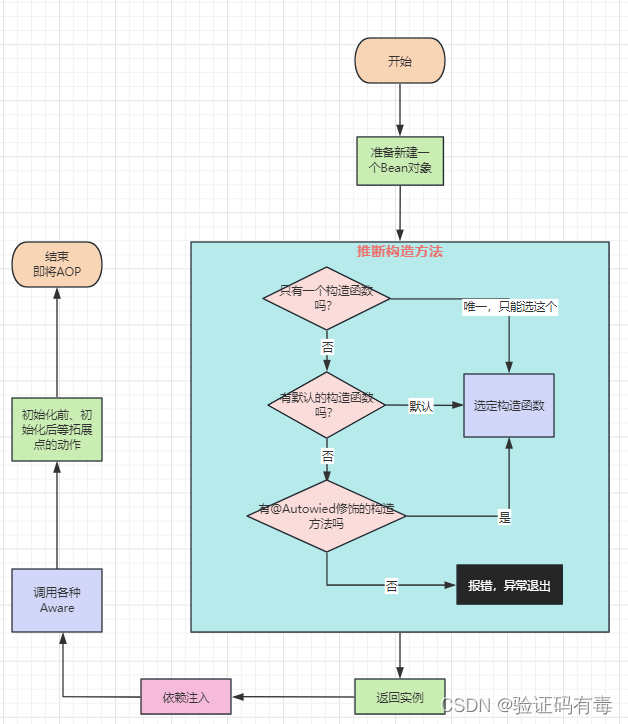
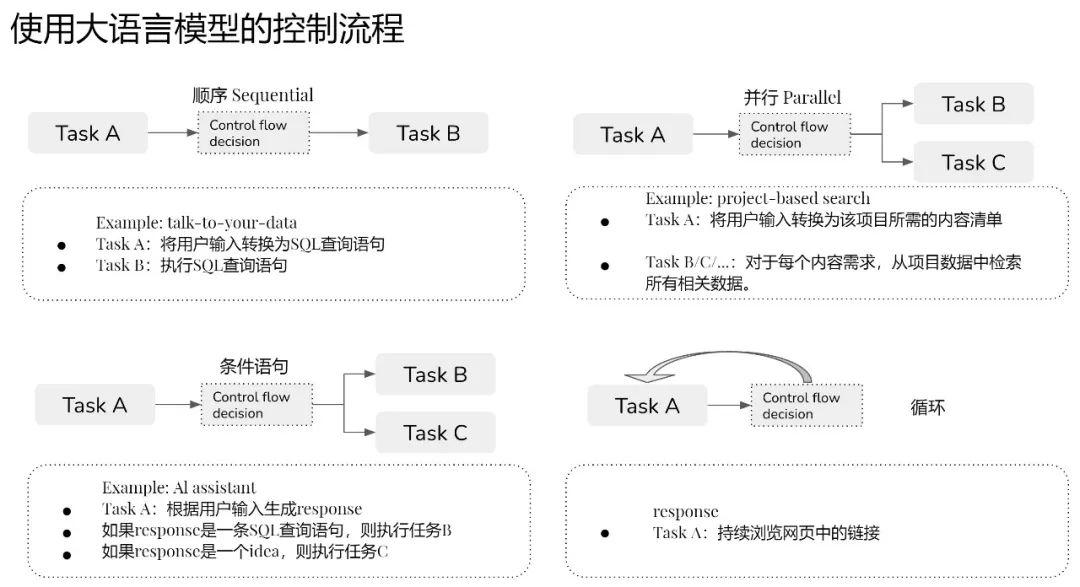
定制化比较严重,按需更改
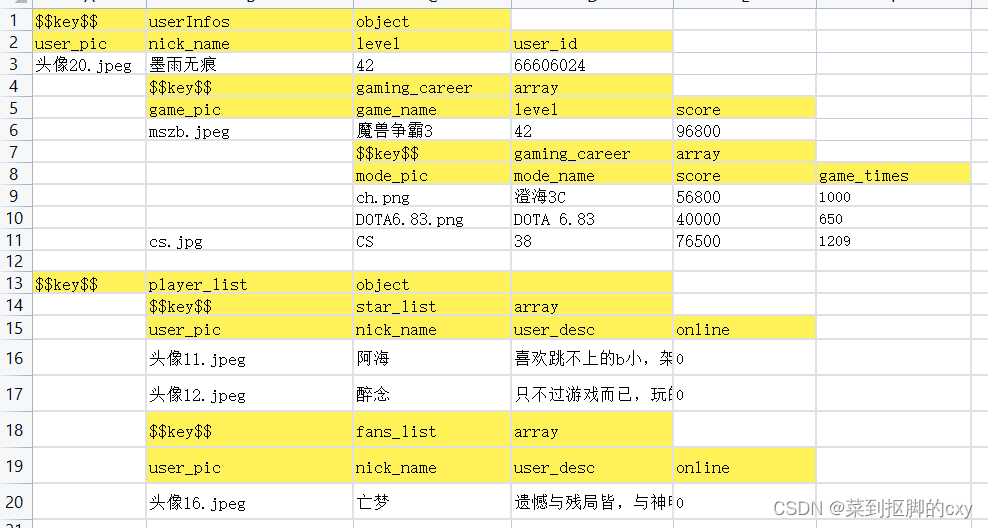
excel文件如下
代码
# -*- coding: utf-8 -*-
import oss2
import shutil
import sys
import xlwt
import xlrd
import json
from datetime import datetime, timedelta
file1 = "C:\\Users\\cxy\\Desktop\\generate.xls"
#打开表1
wb1 = xlrd.open_workbook(filename=file1)
# 表1的sheet
sheet = wb1.sheet_by_index(1)
# 表1的sheet的总行数
rowNum = sheet.nrows
# 表1的sheet的总列数
colNum = sheet.ncols
json_data = {}
def getCellValue(row,col):
# if row == 8:
# print(1)
value = sheet.cell_value(row,col)
if str(value).endswith(".0"):
return str(value).split(".0")[0]
# if type(value) == float:
# value = '%.2f' % sheet.cell_value(8,8)
return value
def getRowValue(row):
return sheet.row_values(row)
def getColValue(col,start_rowx=0, end_rowx=None):
return sheet.col_values(col, start_rowx, end_rowx)
def isKeyRow(row):
return any(s == '$$key$$' for s in sheet.row_values(row))
import re
def name_convert_to_camel(name: str) -> str:
"""下划线转驼峰(小驼峰)"""
return re.sub(r'(_[a-z])', lambda x: x.group(1)[1].upper(), name)
def arr_str_to_arr(value: str) -> str:
"""数组字符串变成数组类型"""
value = str(value)
if re.match('^\[', value) and re.search('\]$', value):
arr = value.strip("[]").split(",")
temp = []
for v in arr:
temp.append({"name":add_oss_host(v)})
return temp
return add_oss_host(value)
def add_oss_host(value: str) -> str:
content = str(value)
if content.endswith(".png") or content.endswith(".jpeg") or content.endswith(".mp4") or content.endswith(".jpg"):
return "/s" + content
else:
return content
def resolveData(cur_level,start_row,end_row,data):
col_values = sheet.col_values(cur_level, start_row, end_row)
cur_level_key_row = [i+start_row for i in range(0,len(col_values)) if col_values[i] == '$$key$$']
# cur_level_key_row.append(rowNum)
for index, row_index in enumerate(cur_level_key_row):
key_row = getRowValue(row_index)
key = key_row[cur_level+1]
if str(key).endswith(".0"):
key = str(key).split(".0")[0]
type = key_row[cur_level+2]
if isKeyRow(row_index+1):
# 第一行就遇到key
if type == 'array':
print("第"+(row_index+1)+"行格式不对")
break
else:
temp = {}
data[key] = temp
if row_index+1<rowNum and isKeyRow(row_index+1):
resolveData(
cur_level + 1,
row_index + 1,
rowNum if (index + 1) >= len(cur_level_key_row) else cur_level_key_row[index + 1],
temp)
continue
column_row = getRowValue(row_index+1)
column_name_arr = []
for col_index in range(cur_level,colNum):
column_name = column_row[col_index]
if column_name == '':
break
column_name_arr.append(name_convert_to_camel(column_name))
if type == 'object':
temp = {}
data[key] = temp
for i in range(0,len(column_name_arr)):
temp[column_name_arr[i]] = arr_str_to_arr(getCellValue(row_index+2, i + cur_level) )
if row_index+3<rowNum and isKeyRow(row_index+3):
resolveData(
cur_level + 1,
row_index + 3,
rowNum if (index + 1) >= len(cur_level_key_row) else cur_level_key_row[index + 1],
temp)
else:
# [0, 18, 28]
tempArr = []
data[key] = tempArr
arr_data_start = cur_level_key_row[index]+2
arr_data_end = rowNum # 默认,下面会改
next_key_index_temp = rowNum
if (index + 1) < len(cur_level_key_row):
next_key_index_temp = cur_level_key_row[index + 1]
if cur_level == 0:
arr_data_end = next_key_index_temp
else:
for i_temp in range(arr_data_start, next_key_index_temp):
if i_temp == rowNum-1:
break
if (getCellValue(i_temp, cur_level-1) == '' and getCellValue(i_temp+1, cur_level-1) != '') or (isKeyRow(i_temp+1) and getCellValue(i_temp+1, cur_level) == '$$key$$'):
arr_data_end = i_temp+1
break
for chi_row_index in range(arr_data_start, arr_data_end):
colValue = getCellValue(chi_row_index, cur_level)
if colValue == '':
continue
temp = {}
tempArr.append(temp)
for i in range(0,len(column_name_arr)):
temp[column_name_arr[i]] = arr_str_to_arr(getCellValue(chi_row_index, i + cur_level) )
if chi_row_index + 1 < rowNum and isKeyRow(chi_row_index + 1):
parentColValues = getColValue(cur_level, chi_row_index + 1, rowNum)
not_empty_index = next((j for j, v in enumerate(parentColValues) if v), len(parentColValues))
resolveData(
cur_level + 1,
chi_row_index + 1,
chi_row_index + not_empty_index + 1,
temp)
cur_level = 0
start_row = 0
end_row = rowNum
json_data = {}
resolveData(cur_level,start_row,end_row,json_data)
print(json.dumps(json_data, ensure_ascii=False))
target = "C:\\Users\\cxy\\Desktop\\generate_target.json"
with open(target, "w", encoding='utf-8') as f:
json.dump(json_data, f, indent=4, ensure_ascii=False)结果
{
"userInfos": {
"userPic": "https://oss.shop.sxmu.com/test/dzpt/头像20.jpeg",
"nickName": "墨雨无痕",
"level": "42",
"userId": "66606024",
"gaming_career": [
{
"gamePic": "https://oss.shop.sxmu.com/test/dzpt/mszb.jpeg",
"gameName": "魔兽争霸3",
"level": "42",
"score": "96800",
"gaming_career": [
{
"modePic": "https://oss.shop.sxmu.com/test/dzpt/ch.png",
"modeName": "澄海3C",
"score": "56800",
"gameTimes": "1000"
},
{
"modePic": "https://oss.shop.sxmu.com/test/dzpt/DOTA6.83.png",
"modeName": "DOTA 6.83",
"score": "40000",
"gameTimes": "650"
}
]
},
{
"gamePic": "https://oss.shop.sxmu.com/test/dzpt/cs.jpg",
"gameName": "CS",
"level": "38",
"score": "76500"
}
]
},
"player_list": {
"star_list": [
{
"userPic": "https://oss.shop.sxmu.com/test/dzpt/头像11.jpeg",
"nickName": "阿海",
"userDesc": "喜欢跳不上的b小,架不住的a1,最爱的沙鹰,放不开也抓不住。",
"online": "0"
},
{
"userPic": "https://oss.shop.sxmu.com/test/dzpt/头像12.jpeg",
"nickName": "醉念",
"userDesc": "只不过游戏而已,玩的再牛逼又如何",
"online": "0"
}
],
"fans_list": [
{
"userPic": "https://oss.shop.sxmu.com/test/dzpt/头像16.jpeg",
"nickName": "亡梦",
"userDesc": "遗憾与残局皆,与神明画过押。",
"online": "0"
}
]
}
}