CLF-Net: Contrastive Learning for Infrared and Visible Image Fusion Network
(LF-Net:红外与可见光图像融合网络的对比学习)
(总结:就是更像谁就选谁)
本文提出了一种基于对比学习的红外和可见光图像融合网络CLF-Net。将一种新的噪声对比度估计框架引入到图像融合中,以最大化融合图像与源图像之间的互信息。首先,构造无监督对比学习框架以促进选择性地保留不同源图像的局部区域中的最相似特征的融合图像。其次,基于图像的深度表示,设计了一种鲁棒的对比度损失,并结合结构性相似性损失,有效地指导网络进行特征的提取和重构。具体地,基于融合图像和源图像之间的深度表示相似性和结构相似性,损失函数可以指导特征提取网络自适应地获得红外图像的显著目标和可见光图像的背景纹理。然后,以最适当的方式重构特征。此外,我们的方法是一个无监督的端到端模型。所有方法都在公共数据集上进行了测试。
介绍
(对于红外和可见光表述略)
我们提出了一个新的想法,该想法是由当前自我监督学习任务中的对比学习方法[34]所启发的。具体而言,Ma等人将融合过程中的期望信息定义为红外图像中的显著目标和可见光图像中的背景纹理的组合。从我们的观点来看,该方法可以更简单地表述如下:我们期望融合图像中的突出目标看起来更像红外图像中的目标,而背景区域看起来更像可见光图像中的目标。研究人员如何定义“like”这个词?答案是对比。通过比较融合图像和源图像之间的相似性和差异性,人们可以容易地选择满足他们期望的融合图像。为此,提出了一种基于对比学习的红外与可见光图像融合网络(CLF-Net)。1)首先,我们构建了一个自适应对比学习框架。在该框架中,我们关注深度表示而非图像本身,并且通过比较点积中的差来最大限度地保留相关的局部特征(即,余弦相似度)。2)其次,在上述框架下,我们设计了一个鲁棒的对比损失,结合结构相似性损失来指导网络进行特征提取和重构。具体地,基于在相同空间位置中的融合图像和源图像之间的表示相似性和结构相似性,损失函数可用于自适应地引导特征提取网络以获得红外图像的显著目标和可见光图像的背景纹理。3)另外,由于对比度损失和结构相似性损失都是自适应的,所以我们的方法是一个不受监督的学习过程。还要注意,对比学习框架仅参与网络的训练过程。因此,我们的CLF-Net是一个端到端模型。
贡献
1)我们将新的噪声对比估计(contrastive estimation (NCE))框架引入到图像融合任务中,以最大化融合图像和源图像之间的互信息(mutual information (MI))。
2)我们构建无监督对比学习框架以促进选择性地保留来自不同源图像的最相似特征的融合图像。设计鲁棒的对比度损失来引导网络工作以基于深度表示自适应地提取和重构特征。
3)大量实验表明,与现有的最先进的方法相比,该方法在定性和定量分析方面具有更好的性能。
相关工作
Deep-Learning-Based Fusion Methods
略
Contrastive Learning for Computer Vision
对比学习由于其优异的性能在计算机视觉领域引起了越来越多的关注。对比学习的概念在很久以前就被提出了,但是近年来,使用这种方法在计算机视觉领域取得了显著的成就。对比学习的核心问题是如何构造正负样本集。Hjelm 等人提出了Deep InfoMax,它基于图像中的局部特征构造了比较性的个学习任务。He等人提出了一种有效的比较学习结构动量对比(MoCo),其使用动量编码器来编码单个正样本和多个负样本,并且利用动量更新编码器参数。Chen等人提出了一种通用框架,其通过在输入图像上进行两个随机数据增强来最大化相同图像的两个数据增强投影的相似性并最小化与其他图像的相似性,以实现相同对象在不同视角或干扰下的恒定视觉表示。然后,He和Hinton的两个团队相互学习,并相继提出了MoCo v2 和SimCLR v2,这两个版本主要是对数据增强方法和骨干网络的改进。随后,Caron等人采用了不同的方法;不是以在优化方向上增加否定情况的数量为目标,而是对所有种类的样本进行聚类,然后对所有种类的类聚类进行比较。Grill等人提出了一种新的自监督图像表示学习方法,该方法不使用负样本,并且使一个编码器停止梯度,该梯度仅对另一个编码器的参数执行动量更新。Chen和He将BYOL背后的概念与对Siamese网络的研究相结合,发现停止梯度是避免网络崩溃的关键,并提出了SimSiam网络。
随着对比学习理论的不断发展,该方法已被广泛应用于许多图像任务中。对于条件图像生成的任务,Kang和Park 提出了ContraGAN,其基于新颖的条件对比度损失,其可以学习数据到类和数据到数据的关系。对于图像到图像转换的任务,Park等人提出了对比学习,其中通过对比学习的框架来最大化源域和目标域中的对应图像patches之间的MI,以完成针对不成对图像到图像转换的图像到图像转换。
我们所知,很少有研究对比学习的应用程序在任务红外和可见光图像融合。受对比学习的启发,Luo等人采用对比差异损失来避免平凡解,并提高自动编码器的解纠缠能力。对比度差异损失可以最大化源图像的公共特征和私有特征之间的区别。然而,IFSepR没有构建阳性样本对和NCE框架,这是与我们的方法的主要区别。因此,受NCE框架的启发,提出了一种新的图像融合算法CLF-Net。结果还表明,使用该网络可以有效地提高图像融合性能。
方法
Network Architecture
CLF-Net的体系结构如图1所示,由两部分组成:特征提取网络和特征重构网络。
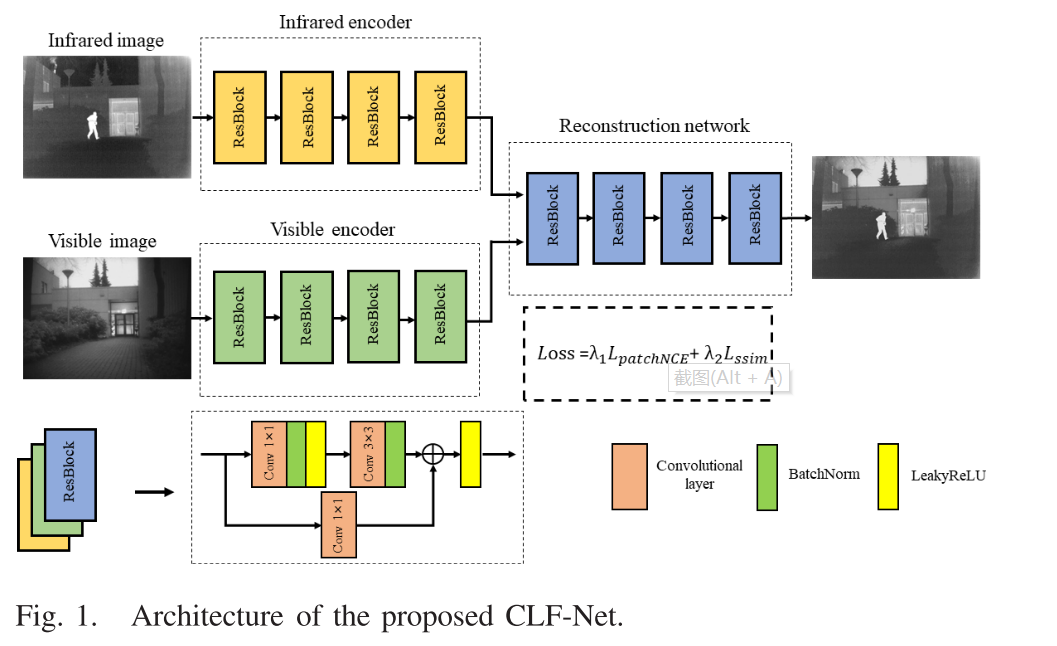
1) Feature Extraction Network:
它由两个特定的编码器组成。两个编码器都是基于ResBlock构建的,以减轻众所周知的梯度消失或爆发的问题。如图1所示,特征提取网络由四个ResBlocks组成,其可以加强提取的信息。每个ResBlock的残差映射由两个卷积层组成,这两个卷积层用于提取特征。这两层的核大小分别为1 × 1和3 × 3。由核大小为1 × 1的卷积层组成的恒等映射用于调整输入和输出维数并保持它们的一致性。对于红外图像和可见光图像,特征提取网络的结构(即,红外编码器和可见光编码器)是一致的,但是这些网络的参数是彼此独立的。
2) Feature Reconstruction Network:
它直接由四个ResBlock组成。来自两个不同的编码器的深度特征被直接级联并重构为融合图像。在特征重建网络的末端,我们已经用tanh代替了激活函数泄漏校正线性单元(LeakyReLU),以确保融合图像和源图像之间的变化范围是一致的。
在ResBlock的所有卷积层中,对于特征提取、融合和重构的整个过程,步长被设置为1,当内核大小为3 × 3时填充被设置为0,当内核大小为1 × 1时填充被设置为1。因此,在 CLF-Net中没有下采样过程,这也意味着没有信息丢失。
NCE Framework
NCE是参数化统计模型的一种新的估计原则。核心思想是通过学习原始数据分布样本和所选噪声分布之间的差异来确定原始数据的一些特征。
Network Architecture
CLF-Net的体系结构如图1所示,由两部分组成:特征提取网络和特征重构网络。
1) Feature Extraction Network:
它由两个特定的编码器组成。两个编码器都是基于ResBlock 来构造的,以减轻众所周知的消失或爆发梯度的问题。如图1所示,特征提取网络由四个ResBlocks组成,其可以加强提取的信息。每个ResBlock的残差映射由两个卷积层组成,这两个卷积层用于提取特征。这两层的核大小分别为1 × 1和3 × 3。由核大小为1 × 1的卷积层组成的恒等映射用于调整输入和输出维数并保持它们的一致性。对于红外图像和可见光图像,特征提取网络的结构(即,红外编码器和可见光编码器)是一致的,但是这些网络的参数是彼此独立的。
2) Feature Reconstruction Network:
它直接由四个ResBlock组成。来自两个不同的编码器的深度特征被直接级联并重构为融合图像。在特征重建网络的末端,我们已经用tanh代替了激活函数泄漏校正线性单元(LeakyReLU),以确保融合图像和源图像之间的变化范围是一致的。
在ResBlock的所有卷积层中,对于特征提取、融合和重构的整个过程,步长被设置为1,当内核大小为3 × 3时填充被设置为0,当内核大小为1 × 1时填充被设置为1。因此,在CLF-Net中没有下采样过程,这也意味着没有信息丢失。
NCE Framework
NCE是参数化统计模型的一种新的估计原则。核心思想是通过学习原始数据分布样本和所选噪声分布之间的差异来确定原始数据的一些特征。该过程有效地将模型估计问题简化为二分问题,并且极大地降低了计算复杂度。
基于NCE的思想,引入 MI的概念,提出了一种新的对比损失函数形式,称为InfoNCE 。具体来说,我们假设有一个编码查询和一组编码样本{
k
−
k^−
k−1,
k
−
k^−
k−2,…,
k
−
k^−
k−N},包括一个正样本和N个负样本。查询、正例和N个负例分别被映射到K维向量q、
k
+
k^+
k+ ∈
R
K
R^K
RK和
k
−
k^−
k− ∈
R
N
×
K
R^{N ×K}
RN×K,其中
k
−
k^−
k−n∈
R
K
R^K
RK表示第n个负例。当q与正例
k
+
k^+
k+相似,而与所有其他负例
k
−
k^-
k−不相似时, InfoNCE损失的值将很小。通过l2规范化查询和其它示例之间的点积来测量相似性。然后将该结果按温度τ缩放,作为logits通过。InfoNCE损失定义如下: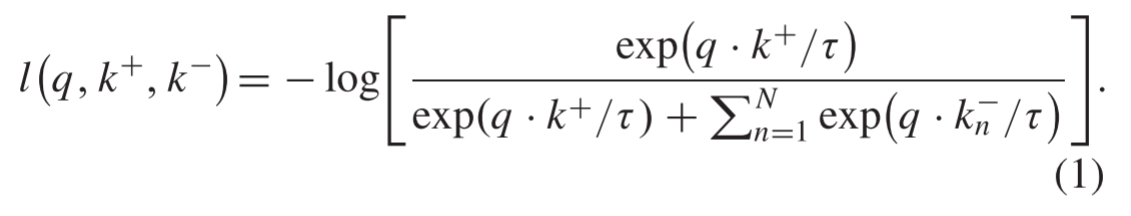
Adaptive Patchwise Contrastive Learning
在一般的对比学习方法中,数据增广常用于为阳性样本建立一个阳性对,而n − 1个阴性对是通过使用同一训练批次中的个所有n − 1个其他图像与阳性样本的个增广图像建立的。然后,最大化正对之间的相似性,并且最小化负对之间的相似性,以完全提取未标记数据集的一般特征。然而,一些研究表明,负对越多,对比学习效果越好。这需要个丰富的训练数据集的支持。显然,对于图像融合任务,缺乏足够的训练数据集一直是需要解决的紧迫问题。结合图像融合任务的特征,我们基于Park等人的工作构建无监督的逐块对比学习框架。
由于图像融合任务更多地关注红外图像的显著目标和可见光图像的背景纹理信息,因此我们从图像的局部特征开始,以基于图像块来构造对比学习任务。
具体地,如图2所示,我们随机采样融合图像的块以及红外图像和可见光图像在相同位置的正块(即,绿色、红色和蓝色框)。接下来,从红外图像和可见光图像的其它位置选择N个随机负片片(即,黄色和橙色框)。然后,重用红外和可见光编码器,加入双层多层感知器(MLP)网络,将源图像和融合图像中任意空间位置的块编码为个特征向量。例如,将融合图像和源图像中的正块编码为特征向量query、pir和pvi。最后,计算查询和pir之间的相似性或者查询和pvi之间的相似性,并且将保留最相似的一个以计算InfoNCE损失。
值得注意的是,用于计算InfoNCE损失的正样本和负样本都是从由相同编码器编码的源图像和融合图像中采样的。对于阴性样本的选择策略,我们将在扩展实验上得出比率。
Loss Function
在本节中,我们讨论结合SSIM和patchNCE的loss 函数的计算,其用于引导CNN网络通过无监督学习找到最合适的参数。SSIM损失主要集中于图像本身的结构特征,而patchNCE损失主要集中于图像的深层特征。
SSIM结合图像亮度、对比度和结构来测量图像质量。对于任意两幅图像,SSIM的描述如下:
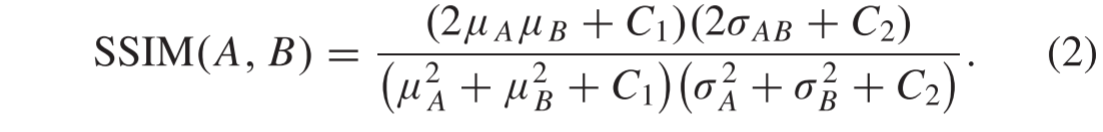
我们设C1 = 1 ×
1
0
−
4
10^{−4}
10−4和C2 = 9 ×
1
0
−
4
10^{−4}
10−4,这个值与[39]中的值相同。根据上述参数的设置,我们将SSIM损耗设置如下:
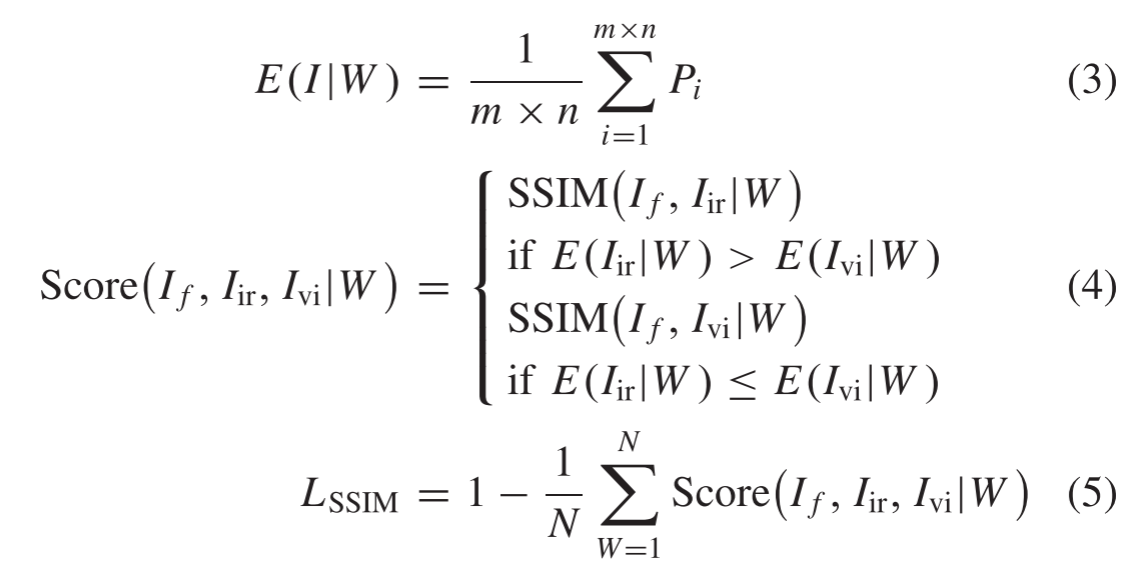
其中W表示从左上到右下的滑动窗口,跨距为1,Pi表示像素i的值,m和n表示滑动窗口的大小,N表示单个图像中的滑动窗口的数量。在我们的工作中,窗口的尺寸是16 × 16。
以上,我们讨论了SSIM损失函数。一方面,基于像素的平均强度在局部窗口,SSIM损失不仅可以保留凸目标红外图像的但也保持明亮的地区和一些明显的纹理在可见图像。另一方面,SSIM损失可以使用图像结构的浅特征来确保输入和输出的结构一致性。对于特征提取网络,我们期望红外编码器能保留更多的显著目标特征,可见光编码器能保留更多的细节纹理特征,这是红外和可见光图像之间最明显的互补特征。因此,我们引入了一种新的对比损失样本,其直接使用编码的深度表示来促使编码器保留足够的互补信息。
具体地,基于上述自适应逐块对比学习框架,我们可以如下构造对比损失。首先,由于在我们的图像融合任务中使用的两个编码器Eir和Evi可以提取有效特征堆栈,所以我们可以利用它们。同时,我们通过一个小的神经网络投影头H,它是一个两层的MLP。红外图像和可见光图像分别由相应的编码器编码,融合图像由两个编码器编码;因此,可以获得四个特征序列。
我们表示s∈{1,……S},S是空间位置采样的数量从过去的图像功能层。对于任何特定的空间位置在图像特征层面上,我们把补丁功能作为
z
s
z^s
zs∈
R
C
R^C
RC和其余的在相同特征水平的称为
z
S
/
s
z^{S/ s}
zS/s∈
R
(
s
−
1
)
×
C
R^{(s−1)×C}
R(s−1)×C, C是通道的数量。如图2所示,可以得到任意特定空间位置的patchNCE损失,如(7)所示,然后可以得到对比度损失,如(8)所示。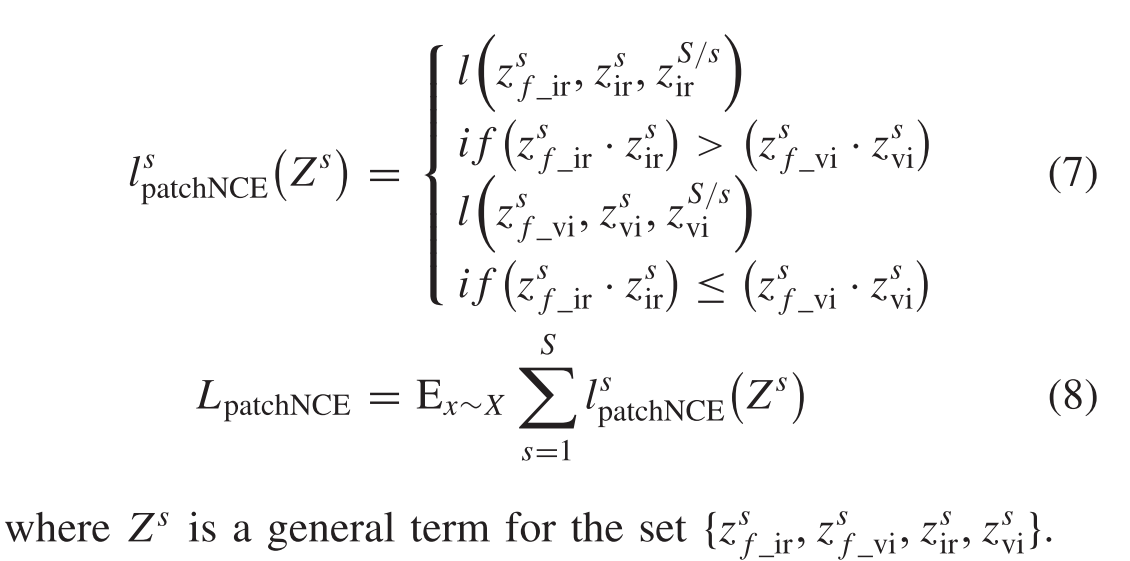
上面,我们讨论了对比损失函数的计算。该损失函数更关注由编码器提取的深度表示。随着训练过程的进行,patchNCE损失可以有效地调整以保留源图像中与融合图像最相似的部分。
基于上述两个损失函数,总损失函数可定义为
一般来说,SSIM损失维护结构考虑tency之间的输入和输出,而patchNCE损失保持一致性的输入和输出的特性。两个损失函数互为补充和指导网络达到令人满意的结果。