古希腊神话中,一位名叫赫尔墨斯的神,会充当人神之间的信使,穿着带有双翼的飞鞋,行走在神明与人类之间。
根据《荷马史诗》的记载:“在天神中,赫尔墨斯是最喜欢引导凡人前行的。”这句话用来形容OpenAI与AI的关系,虽不中亦不远矣。
上一周,OpenAI打造的ChatGPT出尽风头,成为国内外AI领域的头号热门话题。关于ChatGPT的对话能力,大家可能已经通过很多文章感受过了。简单总结,就是对答如流,无所不能,可替程序员写代码,可替商务人士出方案,还能替作家编故事。一度让久违的 “谷歌已死”“XX职业又要被AI取代了”之类的AI威胁论说辞,开始大量出现了。
关于ChatGPT的神奇之处,看多了也有点审美疲劳了,冷静下来思考一下:
为什么同样是AIGC,问答、对话这类NLP领域应用更容易引起轰动,激发人们对通用人工智能的希望?
为什么同样是预训练模型,相比BERT、GPT3等前辈,ChatGPT的对话能力产生了质的飞跃?
为什么同样是做AI,OpenAI要死磕NLP,从GPT1到 ChatGPT不断迭代?

OpenAI的CEO、联合创始人 Sam Altman曾说过一句话:“Trust the exponential,Flat looking backwards,vertical looking forwards”,相信指数的力量,平行地向后看,垂直地向前看。ChatGPT出现代表着,AI似乎已经站到了指数级飞跃的关键点上。但起飞的ChatGPT,并不是一蹴而就的。
从GPT到ChatGPT,恰好代表了OpenAI在大模型领域切实走过的历程,从中可以看到,OpenAI在AI大模型竞争中,已经探索出了一条属于自己的道路,就如同赫尔墨斯一样,成为引领AI技术前进的使者。
如果OpenAI是传递AI前沿进展的赫尔墨斯,ChatGPT就是那双带着双翼的金丝鞋。我们既要关注ChatGPT这双鞋究竟有多神奇,更有必要搞懂,OpenAI选择的这条大模型道路有何玄机。
今天,中国科技企业与研究机构都在积极投布局大模型,求术不如问道,我们不妨从GPT这一系列模型的演变历程,望向OpenAI关于AI与大模型的战略思考与发展脉络。
从GPT-1到ChatGPT,
超神模型的演化足迹
OpenAI在博客中写道,ChatGPT 是从 GPT3.5 系列中的模型进行微调而诞生的。
正如名称中所暗示的那样,GPT- 3.5是OpenAI设计的一系列NLP模型中的第四个,此前还出现了GPT - 1、GPT - 2 和 GPT - 3。
在 GPT 出现之前,NLP 模型主要是基于针对特定任务的大量标注数据进行训练。这会导致一些限制:
大规模高质量的标注数据不易获得;
模型仅限于所接受的训练,泛化能力不足;
无法执行开箱即用的任务,限制了模型的落地应用。
为了克服这些问题,OpenAI走上了预训练大模型的道路。从GPT1到ChatGPT,就是一个预训练模型越来越大、效果越来越强的过程。当然,OpenAI的实现方式并不只是“大力出奇迹”那么简单。
第一代:从有监督到无监督GPT-1。2018年,OpenAI推出了第一代生成式预训练模型GPT-1,此前,NLP任务需要通过大规模数据集来进行有监督的学习,需要成本高昂的数据标注工作,GPT-1的关键特征是:半监督学习。先用无监督学习的预训练,在 8 个 GPU 上花费 了1 个月的时间,从大量未标注数据中增强AI系统的语言能力,获得大量知识,然后进行有监督的微调,与大型数据集集成来提高系统在NLP任务中的性能。
GPT-1的效果明显,只需要极少的微调,就可以增强NLP模型的能力,减少对资源和数据的需求。同时,GPT-1也存在明显的问题,一是数据局限性,GPT-1 是在互联网上的书籍和文本上训练的,对世界的认识不够完整和准确;二是泛化性依然不足,在一些任务上性能表现就会下降。
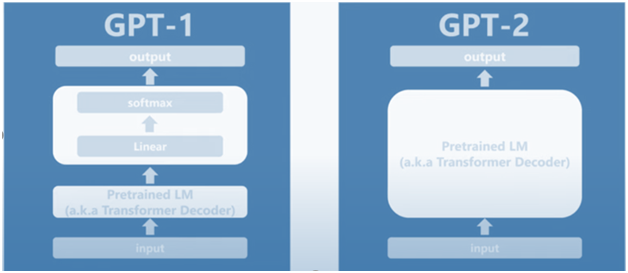
第二代:更大更高更强的GPT-2。2019年推出的GPT-2,与GPT-1并没有本质上的不同(注意这一点),架构相同,使用了更大的数据集WebText,大约有40 GB的文本数据、800万个文档,并为模型添加了更多参数(达到惊人的 15 亿个参数),来提高模型的准确性,可以说是加强版或臃肿版的GPT-1。
GPT-2的出现,进一步证明了无监督学习的价值,以及预训练模型在下游NLP任务中的广泛成功,已经开始达到图灵测试的要求,有研究表示,GPT-2生成的文本几乎与《纽约时报》的真实文章(83%)一样令人信服。
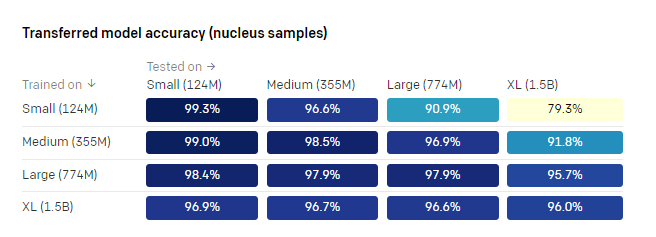
(GPT-2表现)
第三代:跨越式进步的GPT-3。2020年,GPT-3的这次迭代,出现了重大的飞跃,成为与GPT-2迥然不同的物种。
首先,GPT-3的体量空前庞大,拥有超过 1750 亿个参数,是GPT-2的 117 倍;其次,GPT-3不需要微调,它可以识别到数据中隐藏的含义,并运用此前训练获得的知识,来执行下游任务。这意味着,哪怕从来没有接触过的示例,GPT-3就能理解并提供不错的表现。因此,GPT-3也在商业应用上表现出了极高的稳定性和实用性,通过云上的 API访问来实现商业化。这种入得了实验室、下得了车间的能力,使得GPT-3成为2020年AI领域最惊艳的模型之一。
当然,GPT-3也并不完美。正如联合创始人 Sam Altman所说,GPT-3的水平仍处于早期阶段,有时候也会犯非常愚蠢的错误,我们距离真正的人工智能世界还有很长的距离。另外,GPT-3 API 的很多基础模型非常庞大,需要大量的专业知识和性能优异的机器,这使得中小企业或个人开发者使用起来比较困难。
第四代:基于理解而生成的ChatGPT。终于在2022年,OpenAI的预训练语言模型之路,又出现了颠覆式的迭代,产生了技术路线上的又一次方向性变化:基于人工标注数据+强化学习的推理和生成。
前面提到,一开始预训练模型的出现,是为了减少监督学习对高质量标注数据的依赖。而ChatGPT在GPT -3.5大规模语言模型的基础上,又开始依托大量人工标注数据(据说OpenAI找了40个博士来标数据),这怎么又走回监督学习的“老路”了呢?
原因是,GPT 3.5虽然很强,但无法理解人类指令的含义(比如写一段博文、改一段代码),无法判断输入,自然也就很难给出高质量的输出答案。所以OpenAI通过专业的标注人员(据说是40个博士)来写词条,给出相应指令/问题的高质量答案,在基于这些数据来调整GPT -3.5的参数,从而让GPT -3.5具备了理解人类指令的能力。
在人工标注训练数据的基础上,再使用强化学习来增强预训练模型的能力。强化学习,简单理解就是做对了奖励、做错了惩罚,不断根据系统的打分来更新参数,从而产生越来越高质量的回答。所以这几天很多人在互动中发现,ChatGPT会承认错误、会修改自己的答复,这正是因为它具备从人类的反馈中强化学习并重新思考的能力。
因为ChatGPT具备了理解能力,所以才被看作是通向通用人工智能AGI的路径。
当然,ChatGPT也并不是完美进化体。OpenAI的官网明确提示,ChatGPT“可能偶尔会生成不正确的信息”,并且“对2021年之后的世界和事件的了解有限”。一些比较难的知识,比如“红楼梦讲了什么”,ChatGPT会一本正经地胡说八道。
从GPT模型的演进和迭代中,可以看到OpenAI是不断朝着自然语言理解这一目标前进,用更大的模型、更先进的架构,最终为通用人工智能找到了一条路径。
从GPT-1到ChatGPT的纵向演变,会看到OpenAI对大模型的独特理解与技术脉络——通过模型预训练提升NLP指标,抵达强人工智能。NLP领域究竟特殊在哪里,值得OpenAI如此执着?
OpenAI的大模型差异化之路
前文中不难看出,OpenAI对于文本生成模型的执着,因为做够得久、投入够多,所以能够做得更好,是非常有长期战略定力的。
与之相比,和GPT-1同年推出的预训练模型,还有谷歌发布的BERT,但后者在火爆一段时间之后影响力明显减弱;而NLP问答领域一向由Meta引领,Meta AI 的 OPT 模型和GPT-3 达到了同等的参数量,但效果就不如OpenAI。同期选手中,OpenAI对于语言模型的用心显然是更多的。
一方面是资源投入,无论是越来越大的模型,需要消耗庞大的算力资源,ChatGPT所需要的高质量标注数据,依靠博士级别的专业人士来完成,比起将数据标注任务分发给众包平台,显然会消耗更多的人力和财力。
另一方面,是技术投入,大规模预训练、增强学习等技术都用在提升NLP对话系统在开放通用领域上的理解和推理能力。NLP是认知智能,要提升就必须解决知识依赖,而知识又是非常离散且难以表示的,要解决带标数据不足、常识知识不足等问题,是非常具有技术挑战的。多年前IBM的Frederick Jelinek就说过:“每当我开除一个语言学家,语音识别系统的性能就会改善一些。”颇有种“解决不了问题,就解决提出问题的人”的既视感。所以也可以说,OpenAI选择了一条更难走的路,去解决真正困难的问题。

此外,聚焦NLP领域也意味着OpenAI会承担隐形的机会成本。
今年AIGC(AI生成内容)在资本市场和应用市场都有很大的进展,与AI作画、音视频生成、AlphaFold2所解决的蛋白质结构预测等生成任务相比,NLP任务都是直接用词汇和符号来表达概念,此类模型通过“API+云服务”来完成商业化服务,无论是云资源的消耗量还是接口调用服务收费,所获得的收益也是远不及图像音视频或科学计算的。拿同样的精力做十个八个Dalle模型,肯定能赚得更多。
科技博主王咏刚在博客中分享了一个故事,称与OpenAI的两位联合创始人交流,发现这二人甚至不知道AIGC是什么意思!
说到这里,或许可以得出结论,OpenAI作为一个旨在“实现安全的通用人工智能(AGI)”的公司,就是在不计投入、不计商业回报,专心致志地通过过预训练大模型来提升NLP任务的各项指标,从而接近AGI的愿景。
为什么OpenAI能够走出这条引领潮流的大模型差异化之路呢?
一方面是NLP的特殊之处。
NLP 不是魔术,但是,其结果有时几乎就是魔术一般神奇。通用人工智能必须具备认知智能,这也是目前制约人工智能取得更大突破和更广泛应用的关键瓶颈,而NLP正是认知智能的核心。Geoffrey Hinton、Yann LeCun都曾说过类似的观点,深度学习的下一个大的进展,应该是让神经网络真正理解文档的内容。
也就是说,当AI能理解自然语言了,AGI可能就实现了。
另外,OpenAI的运行模式也起到了关键的影响。
突破性创新早期需要大量的投入,大模型的开发需要大量的基础设施投入,而ChatGPT的对话系统短期内很难靠调用量的规模化来摊平研发成本。因此,OpenAI是一个非营利性研究机构,没有迫切的商业化压力,因此可以更专注于NLP领域的基础研究,这是商业型AI公司所很难实现的。

2011年,自然语言领域的泰斗肯尼斯·丘吉(Kenneth Church)发表了一篇长文《钟摆摆得太远》(A Pendulum Swung Too Far),其中提到:我们这一代学者赶上了经验主义的黄金时代,把唾手可得的低枝果实采摘下来,留给下一代的都是“难啃的硬骨头”。
深度学习是经验主义的一个新高峰,而这个领域的低枝果实也总有摘完的一天,近年来有大量AI科学家发出警告,深度学习面临很多局限性,单纯用深度学习很难解决一些复杂任务,或许不用太久,基础性突破就会成为AI产业的重要支撑。
GPT的演进也说明了,AI的突破需要循序渐进、从小到大地一步步实现,今天,每家AI企业和研究机构都在做大模型,相比CV计算机视觉、数字人、元宇宙等AI应用,NLP要显得暗淡很多。而如果一窝蜂去摘容易的果实,最终会制约AI深入产业的脚步。
ChatGPT的出现提醒我们,唯有啃下基础领域的硬骨头,才能真正为AI带来质变。