未建立索引
当数据表没有设计相关索引时,查询会扫描全表。
create table test_temp
(
test_id int auto_increment
primary key,
field_1 varchar(20) null,
field_2 varchar(20) null,
field_3 bigint null,
create_date date null
);
explain
select * from test_temp where field_1 = 'testing0';

建议
查询频繁是数据表字段增加合适的索引。
查询结果集是原表中的大部分数据
当数据库查询命中索引时,数据库会首先利用索引列的值定位到对应的数据节点。这个数据节点上记录了对应数据行的行标识符(Row Identifier)。然而,如果查询需要获取该行其他列的数据,就需要进行回表操作。
在回表操作中,数据库会使用行标识符再次访问数据节点或磁盘上的实际数据行,以获取完整的数据。这个过程被称为回表。回表操作可能会增加额外的磁盘访问和数据检索的开销,因此,在某些情况下,当MySQL判断回表所需的资源大于直接扫描全表时,它可能选择不走索引,而是执行全表扫描。
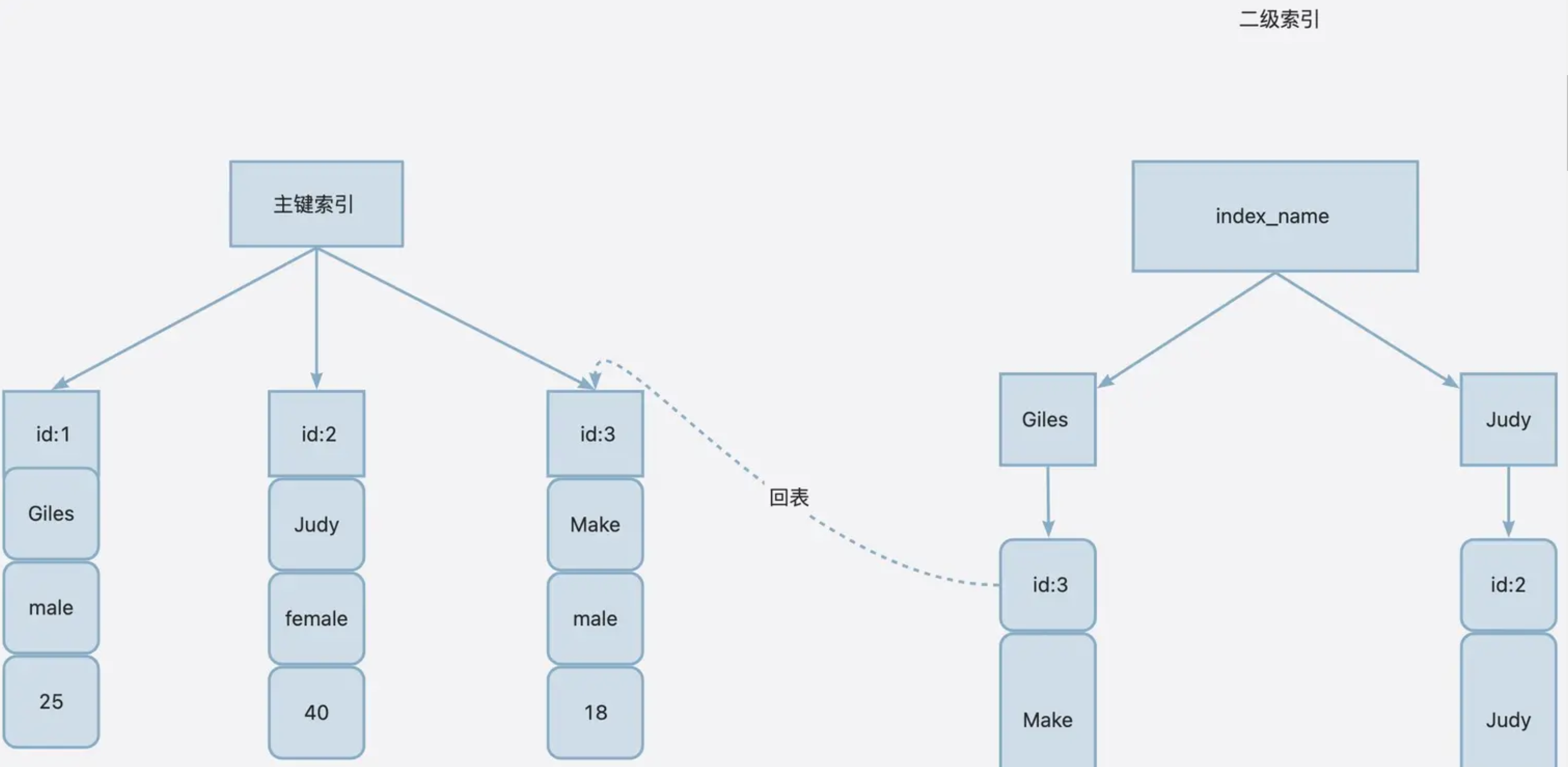
建议
- 索引覆盖:酌情考虑创建包含查询所需列的索引,查询结果集全部被索引覆盖,无需回表。
- 调整查询语句:查询必要的列、使用Join语句优化查询语句,减少回表次数。
- 当表数据量较大时,需考虑其他存储服务。
使用函数、隐式转换
使用函数


隐式转换
数据准备:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for products
-- ----------------------------
DROP TABLE IF EXISTS `products`;
CREATE TABLE `products` (
`id` int NOT NULL,
`name` varchar(255) NOT NULL,
`price` decimal(10,2) NOT NULL,
`description` text,
`created_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
`updated_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`type` tinyint NOT NULL COMMENT '商品类型',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- ----------------------------
-- Records of products
-- ----------------------------
BEGIN;
INSERT INTO `products` VALUES (1, 'Product A', 10.99, 'This is the description for Product A', '2023-08-11 03:47:06', '2023-08-11 03:49:24', 1);
INSERT INTO `products` VALUES (2, 'Product B', 19.99, 'This is the description for Product B', '2023-08-11 03:47:07', '2023-08-11 03:49:24', 2);
INSERT INTO `products` VALUES (3, 'Product C', 5.99, 'This is the description for Product C', '2023-08-11 03:47:07', '2023-08-11 03:49:25', 3);
INSERT INTO `products` VALUES (4, 'Product D', 8.49, 'This is the description for Product D', '2023-08-11 03:47:07', '2023-08-11 03:49:24', 2);
INSERT INTO `products` VALUES (5, 'Product E', 15.99, 'This is the description for Product E', '2023-08-11 03:47:07', '2023-08-11 03:49:25', 2);
INSERT INTO `products` VALUES (6, 'Product F', 12.99, 'This is the description for Product F', '2023-08-11 03:47:08', '2023-08-11 03:49:24', 2);
INSERT INTO `products` VALUES (7, 'Product G', 7.99, 'This is the description for Product G', '2023-08-11 03:47:08', '2023-08-11 03:49:24', 2);
INSERT INTO `products` VALUES (8, 'Product H', 9.99, 'This is the description for Product H', '2023-08-11 03:47:08', '2023-08-11 03:49:24', 2);
INSERT INTO `products` VALUES (9, 'Product I', 14.99, 'This is the description for Product I', '2023-08-11 03:47:09', '2023-08-11 03:49:24', 2);
INSERT INTO `products` VALUES (10, 'Product J', 11.99, 'This is the description for Product J', '2023-08-11 03:47:09', '2023-08-11 03:49:24', 2);
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;
增加索引
ALTER TABLE products
ADD INDEX idx_type (type);
复现:
explain
select * from products where type in ('1','2');
由于type是tinyint类型,因此,以上SQL等效为:
SELECT * FROM products WHERE type in CAST('1' AS tinyint,'2' as tinyint);

由于使用了CAST()函数,会导致不走索引的现象。
还有一种情况是:在关联查询时,驱动表关联字段两者排序规则不一致时也会导致不走索引。
in/not in <>条件导致不走索引
in、not in、<>不走索引的原因是相似的,以下基于in语句分析。
in条件导致不走索引的情况:
in条件过多
explain
select * from products where type in (1,2,3,4,5,6,7);
如果 IN 条件中包含太多的值,超出了数据库管理系统的限制,它可能会选择不使用索引。
建议
当in条件中的数据是连续时,可以使用between and代替in。
分而治之,将一次查询分为多次查询,最后取并集。
使用UNION语句,类似方案一,只不过该方案是在SQL层面完成。
SELECT column1, column2, ...
FROM your_table
WHERE column IN (value1, value2, ..., valueN)
UNION
SELECT column1, column2, ...
FROM your_table
WHERE column IN (valueN+1, valueN+2, ..., valueM)
统计信息不准确
SHOW ENGINE INNODB STATUS;
该命令会查询出MySQL Inndb存储引擎的操作情况,信息包含Innodb各种统计信息:
- Inserts:已插入的行数。
- Updates:已更新的行数。
- Deletes:已删除的行数。
- Reads:已读取的行数。
innodb表的统计信息并不是实时统计更新,如果统计信息和实际的索引信息差异很大,就会导致优化器计算各个索引成本后,做出非预期的选择。出现这种现象的场景是:当有大量数据在短时间内落库时,Innodb还没更新统计相关信息,此时来了一个查询,MySQL会基于历史数据做出错误的判断:当前表数据量少,不走索引更高效。
建议
基于此问题的解决方案是:手动更新相关统计数据。
请参考:
www.modb.pro/db/46678
like语句
like语句无法命中索引的情况:
前导通配符:%value
通配符在字符串的中间:value%value
通配符"_"出现在开头
建议
尽量避免在模式的开头使用前导通配符 %
如果无法避免第一种,根据实际业务和查询语句考虑使用后缀索引
将通配符 % 放在模式的末尾,以便进行前缀匹配。
如果需要在模式的中间使用通配符 %,可以考虑使用全文搜索引擎或其他更适合模式匹配的技术。
对于固定长度的模式匹配,可以考虑使用其他操作符,如 = 或 <>



![GPU Microarch 学习笔记 [1]](https://img-blog.csdnimg.cn/9ef406ed96d04780bae1afc478a5b869.png)