Spark-SQL连接Hive
Apache Hive是Hadoop上的SQL引擎,Spark SQL编译时可选择是否包含Hive支持。包含Hive支持的版本支持Hive表访问、UDF及HQL。生产环境推荐编译时引入Hive支持。
内嵌Hive
直接使用无需配置,但生产环境极少采用。
外部Hive
需完成以下配置:
将hive-site.xml拷贝至conf目录
修改数据库连接地址(如jdbc:mysql://node01:3306/myhive )
拷贝MySQL驱动到jars目录
拷贝core-site.xml和hdfs-site.xml到conf目录
重启spark-shell
Spark Beeline
基于HiveServer2实现的Thrift服务,兼容HiveServer2协议:
配置hive-site.xml和MySQL驱动
启动Thrift Server
使用beeline连接:beeline -u jdbc:hive2://node01:10000 -n root
Spark-SQL CLI
类似Hive命令行工具:
拷贝MySQL驱动到jars目录
放置hive-site.xml到conf目录
执行bin/spark-sql启动
代码操作Hive
需添加依赖:
关键代码步骤:
设置HADOOP_USER_NAME解决权限问题
配置spark.sql.warehouse.dir指定仓库路径
通过SparkSession执行建库、查库等DDL操作
数据加载与保存
提供通用API支持多种数据格式,默认使用Parquet格式。
通用操作
加载数据:spark.read.format("格式").load("路径")
保存数据:df.write.format("格式").mode("模式").save("路径")
支持格式:csv/json/orc/parquet/textFile/jdbc
Parquet
默认数据源,支持嵌套数据存储
直接使用load/save方法操作
可配置spark.sql.sources.default修改默认格式
JSON
自动推断结构,要求每行为完整JSON
加载:spark.read.json("path")
创建临时表后执行SQL查询
MySQL
依赖mysql-connector-java
两种连接方式:
通过options配置参数
使用Properties对象设置连接属性
支持Append/Overwrite等保存模式
CSV
配置选项:sep(分隔符)、header(表头)、inferSchema(自动推断类型)
文件内容课堂总结
news2026/2/14 5:03:32
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2336654.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
探索亮数据Web Unlocker API:让谷歌学术网页科研数据 “触手可及”
本文目录 一、引言二、Web Unlocker API 功能亮点三、Web Unlocker API 实战1.配置网页解锁器2.定位相关数据3.编写代码 四、Web Scraper API技术亮点 五、SERP API技术亮点 六、总结 一、引言
网页数据宛如一座蕴藏着无限价值的宝库,无论是企业洞察市场动态、制定…

【本地MinIO图床远程访问】Cpolar TCP隧道+PicGo插件,让MinIO图床一键触达
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除! 文章目录 前言MinIO本地安装与配置cpolar 内网穿透PicGo 安装MinIO远程访问总结互动致谢参考目录…

Policy Gradient思想、REINFORCE算法,以及贪吃蛇小游戏(一)
文章目录 Policy Gradient思想论文REINFORCE算法论文Policy Gradient思想和REINFORCE算法的关系用一句人话解释什么是REINFORCE算法策略这个东西实在是太抽象了,它可以是一个什么我们能实际感受到的东西?你说的这个我理解了,但这个东西,我怎么优化?在一堆函数中,找到最优…
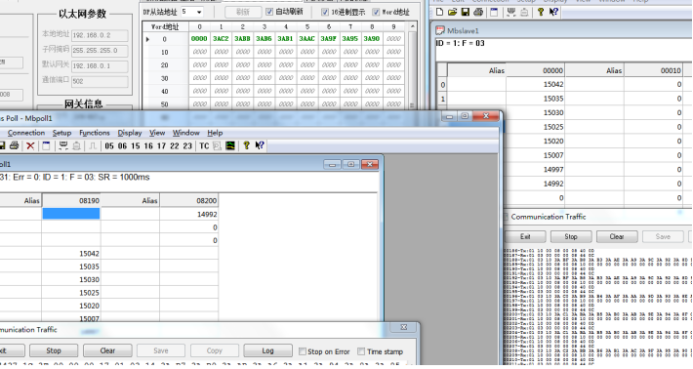
Profibus DP主站转modbusTCP网关与dp从站通讯案例
Profibus DP主站转modbusTCP网关与dp从站通讯案例
在当前工业自动化的浪潮中,不同协议之间的通讯转换成为了提升生产效率和实现设备互联的关键。Profibus DP作为一种广泛应用的现场总线技术,与Modbus TCP的结合,为工业自动化系统的集成带来了…
快速部署大模型 Openwebui + Ollama + deepSeek-R1模型
背景
本文主要快速部署一个带有web可交互界面的大模型的应用,主要用于开发测试节点,其中涉及到的三个组件为 open-webui Ollama deepSeek开放平台
首先 Ollama 是一个开源的本地化大模型部署工具,提供与OpenAI兼容的Api接口,可以快速的运…

H.265硬件视频编码器xk265代码阅读 - 帧内预测
源代码地址: https://github.com/openasic-org/xk265 帧内预测具体逻辑包含在代码xk265\rtl\rec\rec_intra\intra_pred.v 文件中。 module intra_pred() 看起来是每次计算某个4x4块的预测像素值。 以下代码用来算每个pred_angle的具体数值,每个mode_i对应…
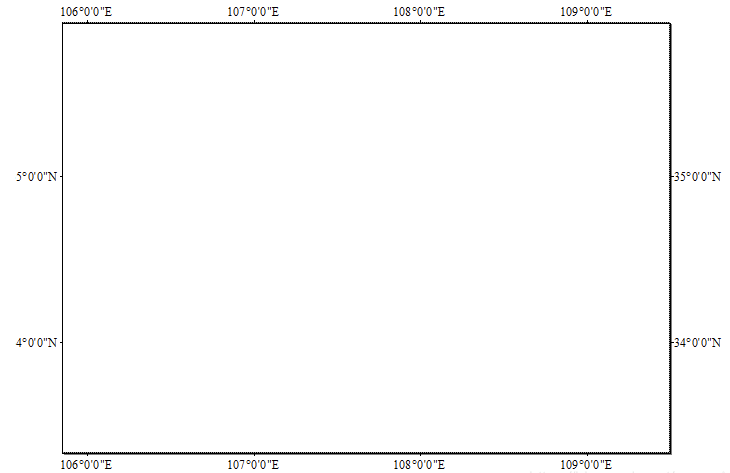
Arcgis经纬线标注设置(英文、刻度显示)
在arcgis软件中绘制地图边框,添加经纬度度时常常面临经纬度出现中文,如下图所示: 解决方法,设置一下Arcgis的语言 点击高级--确认 这样Arcgis就转为英文版了,此时在来看经纬线刻度的标注,自动变成英文
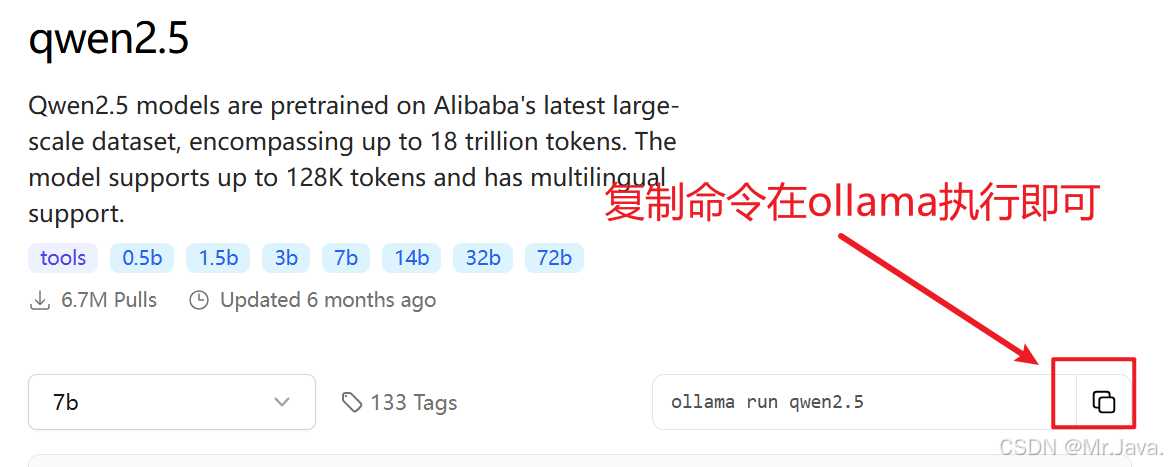
Windows安装Ollama并指定安装路径(默认C盘)
手打不易,如果转摘,请注明出处!
注明原文:http://blog.csdn.net/q258523454/article/details/147289192 一、下载Ollama 访问Ollama官网 打开浏览器,访问Ollama的官方网站:https://ollama.ai/。 在官网首页…
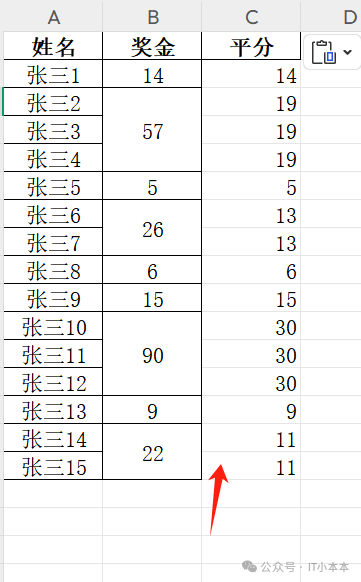
Python自动化处理奖金分摊:基于连续空值的智能分配算法升级
Python自动化处理奖金分摊:基于连续空值的智能分配算法升级
原创 IT小本本 IT小本本 2025年04月04日 02:00 北京 引言
在企业薪酬管理中,团队奖金分配常涉及复杂的分摊规则。传统手工分摊不仅效率低下,还容易因人为疏漏导致分配不公。
本文…

AI工具箱源码+成品网站源码+springboot+vue
大家好,今天给大家分享一个靠AI广告赚钱的项目:AI工具箱成品网站源码,源码支持二开,但不允许转售!!
本人专门为小型企业和个人提供的解决方案。 不懂技术的也可以直接部署工具箱网站,成为站长&…
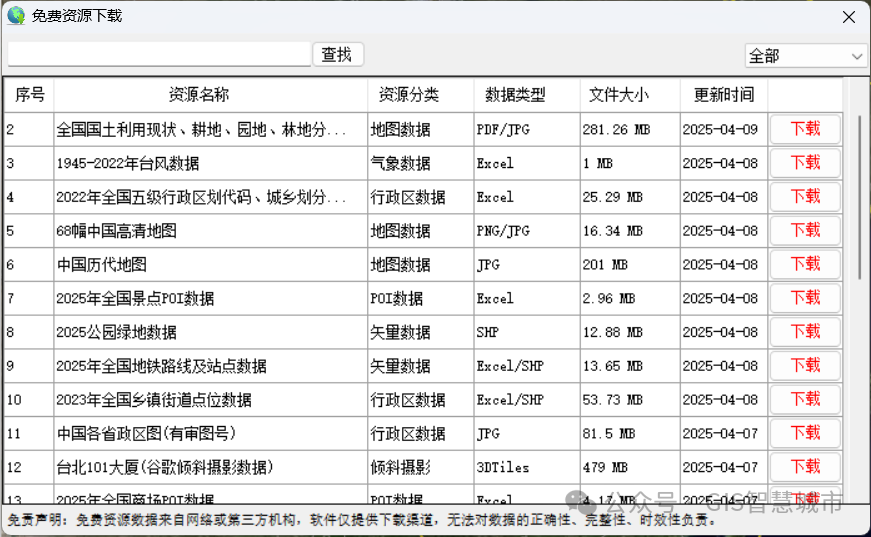
如何下载免费地图数据?
按照以下步骤下载免费地图数据。
1、安装GIS地图下载器
从GeoSaaS(.COM)官网下载“GIS地图下载器”软件:,安装完成后桌面上出现”GIS地图下载器“图标。 双击桌面图标打开”GIS地图下载器“ 2、下载地图数据
点击主界面底部的“…
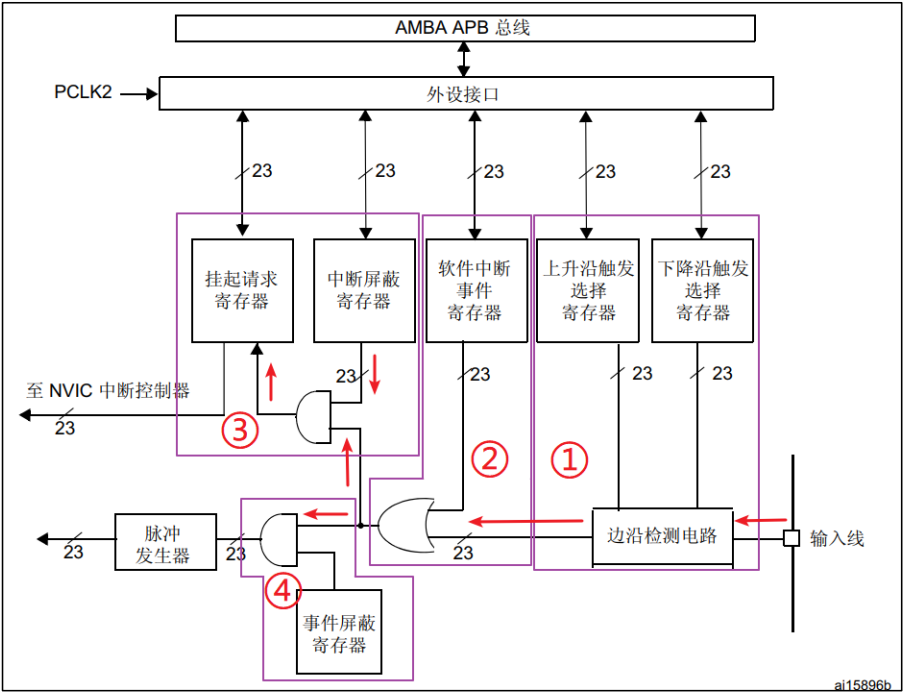
IO 口作为外部中断输入
外部中断 1. NVIC2. EXTI 1. NVIC NVIC即嵌套向量中断控制器,它是内核的器件,M3/M4/M7 内核都是支持 256 个中断,其中包含了 16 个系统中断和 240 个外部中断,并且具有 256 级的可编程中断设置。然而芯片厂商一般不会把内核的这些…
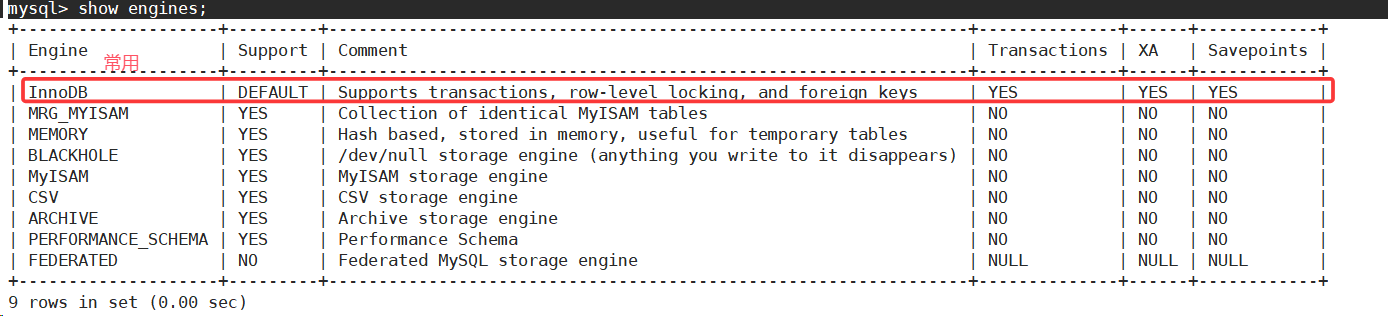
《MySQL基础:了解MySQL周边概念》
1.登录选项的认识 -h:指明登录部署了mysql服务的主机,默认为127.0.0.1-P:指明要访问的端口号,默认为3306-u:指明登录用户-p:指明登录密码 2.什么是数据库
2.1认识数据库 第一点理解。 mysql是数据库的客户…
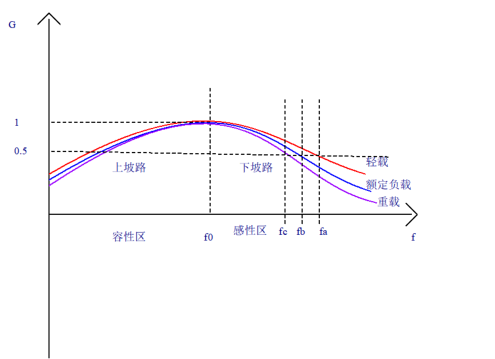
RCL谐振电压增益曲线
谐振电路如何通过调频实现稳压?
为什么要做谐振?
在谐振状态实现ZVS导通,小电流关断
电压增益GVo/Vin,相当于产出投入比
当ff0时,G1时,输出电压输入电压
当G<1时,输出电压<输入电压 …
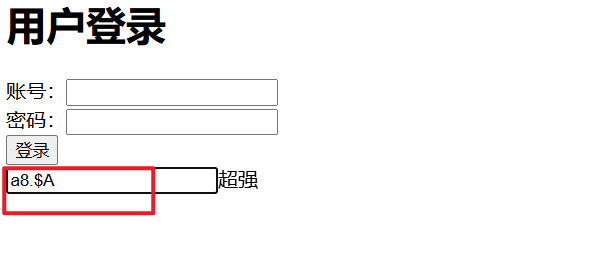
JavaScript:表单及正则表达式验证
今天我要介绍的是在JavaScript中关于表单验证内容的知识点介绍:
关于表单验证,我接下来则直接将内容以及效果显示出来并作注解,这样可以清晰看见这个表达验证的妙用:
<form id"ff" action"https://www.baidu.…

一、Appium环境安装
找了一圈操作手机的工具或软件,踩了好多坑,最后决定用这个工具(影刀RPA手机用的也是这个),目前最新的版本是v2.17.1,是基于nodejs环境的,有两种方式,我只试了第一种方式,第二种方式应该是比较简…

【c++深入系列】:new和delete运算符详解
🔥 本文专栏:c 🌸作者主页:努力努力再努力wz 💪 今日博客励志语录: “生活不会向你许诺什么,尤其不会向你许诺成功。它只会给你挣扎、痛苦和煎熬的过程。但只要你坚持下去,终有一天&…

正弦波有效值和平均值(学习笔记)
一个周期的正弦波在坐标轴上围的面积有多大?
一般正弦波以 y Asin(wx)表示,其中A为振幅,W为角速度。周期T 2π/w;
确定积分区间是x 0,到x 2π。
计算绝对值积分: 变量代还:wx θ,dx dθ…

第八天 开始Unity Shader的学习之Blinn-Phong光照模型
Unity Shader的学习笔记
第八天 开始Unity Shader的学习之Blinn-Phong光照模型 文章目录 Unity Shader的学习笔记前言一、Blinn-Phong光照模型①计算高光反射部分效果展示 二、召唤神龙:使用Unity内置的函数总结 前言
今天我们编写另一种高光反射的实现方法 – Blinn光照模型…

豆瓣图书数据采集与可视化分析
文章目录 一、适用题目二、豆瓣图书数据采集1. 图书分类采集2. 爬取不同分类的图书数据3. 各个分类数据整合 三、豆瓣图书数据清洗四、数据分析五、数据可视化1. 数据可视化大屏展示 源码获取看下方名片 一、适用题目
基于Python的豆瓣图书数据采集与分析基于Python的豆瓣图书…